Solía tener miedo al almacenamiento en caché. Realmente no quería escalar y descubrir qué era, inmediatamente me imaginé algunas cosas de la empresa luto del compartimento del motor que solo el ganador de la olimpiada matemática podría resolver. Resultó que esto no es así. El almacenamiento en caché resultó ser muy simple, comprensible e increíblemente fácil de implementar en cualquier proyecto.
En esta publicación, intentaré explicar sobre el almacenamiento en caché tan simple como ahora entiendo. Aprenderá cómo implementar el almacenamiento en caché en 1 minuto, cómo almacenar en caché por clave, establecer la vida útil de la memoria caché y muchas otras cosas que debe saber si se le indicó que almacenara algo en su proyecto de trabajo y no desea confundirse cara
¿Por qué digo "encomendado"? Debido a que el almacenamiento en caché, por regla general, tiene sentido aplicar en proyectos grandes y altamente cargados, con decenas de miles de solicitudes por minuto. En tales proyectos, para no sobrecargar la base de datos, generalmente almacenan en caché las llamadas al repositorio. Especialmente si se sabe que los datos de algún sistema maestro se actualizan con cierta frecuencia. Nosotros mismos no escribimos tales proyectos, trabajamos en ellos. Si el proyecto es pequeño y no amenaza las sobrecargas, entonces, por supuesto, es mejor no almacenar en caché nada; siempre los datos actualizados siempre son mejores que los actualizados periódicamente.
Por lo general, en las publicaciones de capacitación, el orador primero se arrastra debajo del capó, comienza a profundizar en las entrañas de la tecnología, lo que molesta mucho al lector, y solo entonces, cuando hojeó una buena mitad del artículo y no entendió nada, cuenta cómo funciona. Todo será diferente con nosotros. Primero, lo hacemos funcionar, y preferiblemente, con el menor esfuerzo, y luego, si está interesado, puede mirar debajo del capó de la caché, mirar dentro del contenedor y ajustar el almacenamiento en caché. Pero incluso si no lo hace (y esto comienza con el punto 6), su almacenamiento en caché funcionará así.
Crearemos un proyecto en el que analizaremos todos los aspectos del almacenamiento en caché que prometí. Al final, como de costumbre, habrá un enlace al proyecto en sí.
0. Crear un proyecto
Crearemos un proyecto muy simple en el que podamos tomar la entidad de la base de datos. Agregué Lombok, Spring Cache, Spring Data JPA y H2 al proyecto. Aunque, solo se puede prescindir de Spring Cache.
plugins { id 'org.springframework.boot' version '2.1.7.RELEASE' id 'io.spring.dependency-management' version '1.0.8.RELEASE' id 'java' } group = 'ru.xpendence' version = '0.0.1-SNAPSHOT' sourceCompatibility = '1.8' configurations { compileOnly { extendsFrom annotationProcessor } } repositories { mavenCentral() } dependencies { implementation 'org.springframework.boot:spring-boot-starter-cache' implementation 'org.springframework.boot:spring-boot-starter-data-jpa' compileOnly 'org.projectlombok:lombok' runtimeOnly 'com.h2database:h2' annotationProcessor 'org.projectlombok:lombok' testImplementation 'org.springframework.boot:spring-boot-starter-test' }
Tendremos solo una entidad, llamémosla Usuario.
@Entity @Table(name = "users") @Data @NoArgsConstructor @ToString public class User implements Serializable { @Id @GeneratedValue(strategy = GenerationType.IDENTITY) private Long id; @Column(name = "name") private String name; @Column(name = "email") private String email; public User(String name, String email) { this.name = name; this.email = email; } }
Agregue el repositorio y el servicio:
public interface UserRepository extends JpaRepository<User, Long> { } @Slf4j @Service public class UserServiceImpl implements UserService { private final UserRepository repository; public UserServiceImpl(UserRepository repository) { this.repository = repository; } @Override public User create(User user) { return repository.save(user); } @Override public User get(Long id) { log.info("getting user by id: {}", id); return repository.findById(id) .orElseThrow(() -> new EntityNotFoundException("User not found by id " + id)); } }
Cuando ingresamos el método de servicio get (), lo escribimos en el registro.
Conéctese al proyecto Spring Cache.
@SpringBootApplication @EnableCaching
El proyecto esta listo.
1. Almacenamiento en caché del resultado devuelto
¿Qué hace Spring Cache? Spring Cache simplemente almacena en caché el resultado de retorno para parámetros de entrada específicos. Vamos a verlo Pondremos la anotación @Cacheable sobre el método de servicio get () para almacenar en caché los datos devueltos. Damos a esta anotación el nombre de "usuarios" (analizaremos más a fondo por qué esto se hace por separado).
@Override @Cacheable("users") public User get(Long id) { log.info("getting user by id: {}", id); return repository.findById(id) .orElseThrow(() -> new EntityNotFoundException("User not found by id " + id)); }
Para comprobar cómo funciona esto, escribiremos una prueba simple.
@RunWith(SpringRunner.class) @SpringBootTest public abstract class AbstractTest { }
@Slf4j public class UserServiceTest extends AbstractTest { @Autowired private UserService service; @Test public void get() { User user1 = service.create(new User("Vasya", "vasya@mail.ru")); User user2 = service.create(new User("Kolya", "kolya@mail.ru")); getAndPrint(user1.getId()); getAndPrint(user2.getId()); getAndPrint(user1.getId()); getAndPrint(user2.getId()); } private void getAndPrint(Long id) { log.info("user found: {}", service.get(id)); } }
Una pequeña digresión, por qué suelo escribir AbstractTest y heredar todas las pruebas.Si la clase tiene su propia anotación @SpringBootTest, el contexto se vuelve a generar para dicha clase cada vez. Dado que el contexto puede aumentar durante 5 segundos, o tal vez 40 segundos, esto en cualquier caso inhibe en gran medida el proceso de prueba. Al mismo tiempo, generalmente no hay diferencia en el contexto, y cuando ejecuta cada grupo de pruebas dentro de la misma clase, no es necesario reiniciar el contexto. Si ponemos solo una anotación, por ejemplo, sobre una clase abstracta, como en nuestro caso, esto nos permite plantear el contexto solo una vez.
Por lo tanto, prefiero reducir el número de contextos planteados durante la prueba / ensamblaje, si es posible.
¿Qué hace nuestra prueba? Crea dos usuarios y luego los saca de la base de datos 2 veces. Como recordamos, colocamos la anotación @Cacheable, que almacenará en caché los valores devueltos. Después de recibir el objeto del método get (), enviamos el objeto al registro. Además, registramos información sobre cada visita de la aplicación al método get ().
Ejecute la prueba Esto es lo que tenemos en la consola.
getting user by id: 1 user found: User(id=1, name=Vasya, email=vasya@mail.ru) getting user by id: 2 user found: User(id=2, name=Kolya, email=kolya@mail.ru) user found: User(id=1, name=Vasya, email=vasya@mail.ru) user found: User(id=2, name=Kolya, email=kolya@mail.ru)
Como vemos, las dos primeras veces fuimos al método get () y obtuvimos al usuario de la base de datos. En todos los demás casos, no hubo una llamada real al método, la aplicación tomó datos en caché por clave (en este caso, esto es id).
2. Declaración de clave de almacenamiento en caché
Hay situaciones en las que varios parámetros llegan al método en caché. En este caso, puede ser necesario determinar el parámetro por el cual ocurrirá el almacenamiento en caché. Agregamos un ejemplo a un método que guardará una entidad ensamblada por parámetros en la base de datos, pero si ya existe una entidad con el mismo nombre, no la guardaremos. Para hacer esto, definiremos el parámetro de nombre como la clave para el almacenamiento en caché. Se verá así:
@Override @Cacheable(value = "users", key = "#name") public User create(String name, String email) { log.info("creating user with parameters: {}, {}", name, email); return repository.save(new User(name, email)); }
Escribamos la prueba correspondiente:
@Test public void create() { createAndPrint("Ivan", "ivan@mail.ru"); createAndPrint("Ivan", "ivan1122@mail.ru"); createAndPrint("Sergey", "ivan@mail.ru"); log.info("all entries are below:"); service.getAll().forEach(u -> log.info("{}", u.toString())); } private void createAndPrint(String name, String email) { log.info("created user: {}", service.create(name, email)); }
Intentaremos crear tres usuarios, para dos de los cuales el nombre será el mismo.
createAndPrint("Ivan", "ivan@mail.ru"); createAndPrint("Ivan", "ivan1122@mail.ru");
y para dos de los cuales el correo electrónico coincidirá
createAndPrint("Ivan", "ivan@mail.ru"); createAndPrint("Sergey", "ivan@mail.ru");
En el método de creación, registramos cada hecho que se llama al método, y también registramos todas las entidades que este método nos devolvió. El resultado será así:
creating user with parameters: Ivan, ivan@mail.ru created user: User(id=1, name=Ivan, email=ivan@mail.ru) created user: User(id=1, name=Ivan, email=ivan@mail.ru) creating user with parameters: Sergey, ivan@mail.ru created user: User(id=2, name=Sergey, email=ivan@mail.ru) all entries are below: User(id=1, name=Ivan, email=ivan@mail.ru) User(id=2, name=Sergey, email=ivan@mail.ru)
Vemos que, de hecho, la aplicación llamó al método 3 veces, y entró en él solo dos veces. Una vez que una clave coincide con un método, y simplemente devuelve un valor en caché.
3. Almacenamiento en caché forzado. @CachePut
Hay situaciones en las que queremos almacenar en caché el valor de retorno para alguna entidad, pero al mismo tiempo, necesitamos actualizar la memoria caché. Para tales necesidades, existe la anotación @CachePut. Pasa la aplicación al método, mientras actualiza la memoria caché para el valor de retorno, incluso si ya está en caché.
Agregue un par de métodos en los que salvaremos al usuario. Marcamos uno de ellos con la habitual anotación @Cacheable, el segundo con @CachePut.
@Override @Cacheable(value = "users", key = "#user.name") public User createOrReturnCached(User user) { log.info("creating user: {}", user); return repository.save(user); } @Override @CachePut(value = "users", key = "#user.name") public User createAndRefreshCache(User user) { log.info("creating user: {}", user); return repository.save(user); }
El primer método simplemente devolverá los valores almacenados en caché, el segundo forzará la actualización de la memoria caché. El almacenamiento en caché se realizará con la clave # user.name. Escribiremos la prueba correspondiente.
@Test public void createAndRefresh() { User user1 = service.createOrReturnCached(new User("Vasya", "vasya@mail.ru")); log.info("created user1: {}", user1); User user2 = service.createOrReturnCached(new User("Vasya", "misha@mail.ru")); log.info("created user2: {}", user2); User user3 = service.createAndRefreshCache(new User("Vasya", "kolya@mail.ru")); log.info("created user3: {}", user3); User user4 = service.createOrReturnCached(new User("Vasya", "petya@mail.ru")); log.info("created user4: {}", user4); }
De acuerdo con la lógica que ya se ha descrito, la primera vez que un usuario con el nombre "Vasya" se guarda a través del método createOrReturnCached (), recibiremos una entidad en caché y la aplicación no entrará en el método en sí. Si llamamos al método createAndRefreshCache (), la entidad en caché para la clave llamada "Vasya" se sobrescribirá en la memoria caché. Ejecutemos la prueba y veamos qué se mostrará en la consola.
creating user: User(id=null, name=Vasya, email=vasya@mail.ru) created user1: User(id=1, name=Vasya, email=vasya@mail.ru) created user2: User(id=1, name=Vasya, email=vasya@mail.ru) creating user: User(id=null, name=Vasya, email=kolya@mail.ru) created user3: User(id=2, name=Vasya, email=kolya@mail.ru) created user4: User(id=2, name=Vasya, email=kolya@mail.ru)
Vemos que user1 ha escrito con éxito en la base de datos y en la memoria caché. Cuando intentamos grabar al usuario con el mismo nombre nuevamente, obtenemos el resultado en caché de la primera llamada (usuario2, para el cual la identificación es la misma que usuario1, lo que nos dice que el usuario no fue escrito, y esto es solo un caché). A continuación, escribimos al tercer usuario a través del segundo método, que, incluso con el resultado en caché, todavía llamó al método y escribió un nuevo resultado en el caché. Este es el usuario3. Como podemos ver, él ya tiene una nueva identificación. Después de lo cual, llamamos al primer método, que toma la nueva caché agregada por el usuario3.
4. Eliminación del caché. @CacheEvict
A veces se hace necesario actualizar algunos datos en la memoria caché. Por ejemplo, una entidad ya se ha eliminado de la base de datos, pero aún se puede acceder desde la memoria caché. Para mantener la consistencia de los datos, necesitamos al menos no almacenar los datos eliminados en la memoria caché.
Agregue un par de métodos más al servicio.
@Override public void delete(Long id) { log.info("deleting user by id: {}", id); repository.deleteById(id); } @Override @CacheEvict("users") public void deleteAndEvict(Long id) { log.info("deleting user by id: {}", id); repository.deleteById(id); }
El primero simplemente eliminará al usuario, el segundo también lo eliminará, pero lo marcaremos con la anotación @CacheEvict. Agregue una prueba que creará dos usuarios, después de lo cual se eliminará uno mediante un método simple y el segundo mediante un método anotado. Después de eso, conseguiremos estos usuarios a través del método get ().
@Test public void delete() { User user1 = service.create(new User("Vasya", "vasya@mail.ru")); log.info("{}", service.get(user1.getId())); User user2 = service.create(new User("Vasya", "vasya@mail.ru")); log.info("{}", service.get(user2.getId())); service.delete(user1.getId()); service.deleteAndEvict(user2.getId()); log.info("{}", service.get(user1.getId())); log.info("{}", service.get(user2.getId())); }
Es lógico que dado que nuestro usuario ya está en caché, la eliminación no nos impedirá obtenerlo, ya que está en caché. Veamos los registros.
getting user by id: 1 User(id=1, name=Vasya, email=vasya@mail.ru) getting user by id: 2 User(id=2, name=Vasya, email=vasya@mail.ru) deleting user by id: 1 deleting user by id: 2 User(id=1, name=Vasya, email=vasya@mail.ru) getting user by id: 2 javax.persistence.EntityNotFoundException: User not found by id 2
Vemos que la aplicación fue segura en ambas ocasiones al método get () y Spring almacenó en caché estas entidades. A continuación, los eliminamos a través de diferentes métodos. Eliminamos el primero de la forma habitual, y el valor almacenado en caché se mantuvo, por lo que cuando intentamos obtener el usuario con la ID 1, lo logramos. Cuando intentamos obtener el usuario 2, el método devolvió una EntityNotFoundException; no había dicho usuario en la memoria caché.
5. Configuración de agrupamiento. @Caching
A veces, un solo método requiere varias configuraciones de almacenamiento en caché. La anotación @Caching se utiliza para estos fines. Puede verse más o menos así:
@Caching( cacheable = { @Cacheable("users"), @Cacheable("contacts") }, put = { @CachePut("tables"), @CachePut("chairs"), @CachePut(value = "meals", key = "#user.email") }, evict = { @CacheEvict(value = "services", key = "#user.name") } ) void cacheExample(User user) { }
Esta es la única forma de agrupar anotaciones. Si intentas apilar algo como
@CacheEvict("users") @CacheEvict("meals") @CacheEvict("contacts") @CacheEvict("tables") void cacheExample(User user) { }
entonces IDEA le dirá que este no es el caso.
6. Configuración flexible. Cachemanager
Finalmente, descubrimos el caché, y dejó de ser algo incomprensible y aterrador para nosotros. Ahora veamos debajo del capó y veamos cómo podemos configurar el almacenamiento en caché en general.
Para tales tareas, hay un CacheManager. Existe donde sea que esté Spring Cache. Cuando agregamos la anotación @EnableCache, Spring creará automáticamente dicho administrador de caché. Podemos verificar esto si ajustamos automáticamente el ApplicationContext y lo abrimos en el punto de interrupción. Entre otros contenedores, habrá un bean cacheManager.
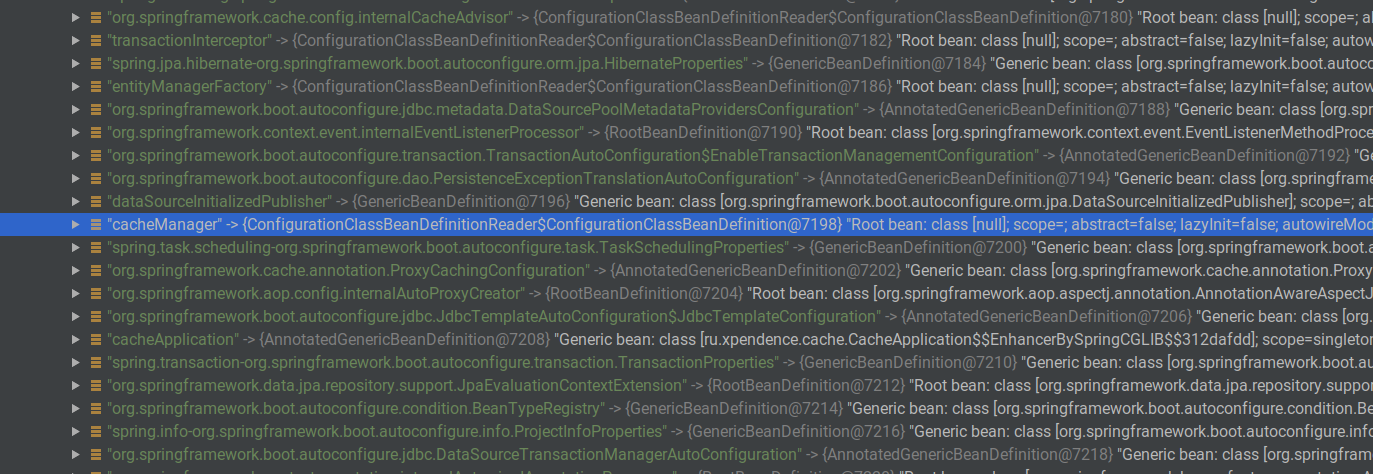
Detuve la aplicación en el momento en que dos usuarios ya habían sido creados y puestos en el caché. Si llamamos al bean que necesitamos a través de Evaluate Expression, veremos que realmente existe dicho bean, que tiene un ConcurentMapCache con la clave "users" y el valor ConcurrentHashMap, que ya contiene usuarios en caché.

Nosotros, a su vez, podemos crear nuestro administrador de caché, con Habr y programadores, y luego ajustarlo a nuestro gusto.
@Bean("habrCacheManager") public CacheManager cacheManager() { return null; }
Solo queda elegir qué administrador de caché usaremos, porque hay muchos de ellos. No enumeraré todos los administradores de caché, será suficiente saber que existen:
- SimpleCacheManager es el administrador de caché más simple, conveniente para aprender y probar.
- ConcurrentMapCacheManager - Inicializa perezosamente las instancias devueltas para cada solicitud. También se recomienda para probar y aprender a trabajar con el caché, así como para algunas acciones simples como la nuestra. Para un trabajo serio con el caché, se recomienda la implementación a continuación.
- JCacheCacheManager , EhCacheCacheManager , CaffeineCacheManager son administradores de caché serios "socios socios" que son personalizables de manera flexible y realizan tareas de una amplia gama de acciones.
Como parte de mi humilde publicación, no describiré los administradores de caché de los últimos tres. En su lugar, veremos varios aspectos de la configuración de un administrador de caché utilizando el ConcurrentMapCacheManager como ejemplo.
Entonces, recrearemos nuestro administrador de caché.
@Bean("habrCacheManager") public CacheManager cacheManager() { return new ConcurrentMapCacheManager(); }
Nuestro administrador de caché está listo.
7. Configuración de caché. Tiempo de vida, tamaño máximo, etc.
Para hacer esto, necesitamos una biblioteca Google Guava bastante popular. Tomé el último.
compile group: 'com.google.guava', name: 'guava', version: '28.1-jre'
Al crear el administrador de caché, redefinimos el método createConcurrentMapCache, en el que llamaremos a CacheBuilder desde Guava. En el proceso, se nos pedirá que configuremos el administrador de caché inicializando los siguientes métodos:
- maximumSize: el tamaño máximo de los valores que puede contener el caché. Con este parámetro, puede encontrar un intento de encontrar un compromiso entre la carga en la base de datos y la RAM JVM.
- refreshAfterWrite: tiempo después de escribir el valor en el caché, después del cual se actualizará automáticamente.
- expireAfterAccess: la duración del valor después de la última llamada.
- expireAfterWrite: duración del valor después de escribir en la memoria caché. Este es el parámetro que definiremos.
y otros
Definimos en el administrador la vida útil del registro. Para no esperar mucho, configure 1 segundo.
@Bean("habrCacheManager") public CacheManager cacheManager() { return new ConcurrentMapCacheManager() { @Override protected Cache createConcurrentMapCache(String name) { return new ConcurrentMapCache( name, CacheBuilder.newBuilder() .expireAfterWrite(1, TimeUnit.SECONDS) .build().asMap(), false); } }; }
Escribimos una prueba correspondiente a este caso.
@Test public void checkSettings() throws InterruptedException { User user1 = service.createOrReturnCached(new User("Vasya", "vasya@mail.ru")); log.info("{}", service.get(user1.getId())); User user2 = service.createOrReturnCached(new User("Vasya", "vasya@mail.ru")); log.info("{}", service.get(user2.getId())); Thread.sleep(1000L); User user3 = service.createOrReturnCached(new User("Vasya", "vasya@mail.ru")); log.info("{}", service.get(user3.getId())); }
Guardamos varios valores en la base de datos, y si los datos se almacenan en caché, no guardamos nada. Primero, guardamos dos valores, luego esperamos 1 segundo hasta que el caché se agote, después de lo cual guardamos otro valor.
creating user: User(id=null, name=Vasya, email=vasya@mail.ru) getting user by id: 1 User(id=1, name=Vasya, email=vasya@mail.ru) User(id=1, name=Vasya, email=vasya@mail.ru) creating user: User(id=null, name=Vasya, email=vasya@mail.ru) getting user by id: 2 User(id=2, name=Vasya, email=vasya@mail.ru)
Los registros muestran que primero creamos un usuario, luego probamos otro, pero como los datos se almacenaron en caché, los obtuvimos del caché (en ambos casos, al guardar y al obtener de la base de datos). Luego, el caché se estropeó, ya que un registro nos informa sobre el ahorro real y la recepción real del usuario.
8. Para resumir
Tarde o temprano, el desarrollador se enfrenta a la necesidad de implementar el almacenamiento en caché en el proyecto. Espero que este artículo te ayude a entender el tema y a mirar los problemas de almacenamiento en caché con mayor audacia.
Github del proyecto aquí:
https://github.com/promoscow/cache