En un
artículo anterior, hablamos sobre tratar de usar Watcher y presentamos un informe de prueba. Periódicamente realizamos tales pruebas para equilibrar y otras funciones críticas de una gran nube corporativa u operadora.
La alta complejidad del problema que se está resolviendo puede requerir varios artículos para describir nuestro proyecto. Hoy publicamos el segundo artículo de la serie sobre el equilibrio de máquinas virtuales en la nube.
Alguna terminología
VmWare ha introducido la utilidad DRS (Distributed Resource Scheduler) para equilibrar la carga de su entorno de virtualización.
Como escribe
searchvmware.techtarget.com/definition/VMware-DRS“VMware DRS (Distributed Resource Scheduler) es una utilidad que equilibra la carga informática con los recursos disponibles en un entorno virtual. La utilidad es parte de un paquete de virtualización llamado VMware Infrastructure.
Con VMware DRS, los usuarios definen las reglas para distribuir recursos físicos entre máquinas virtuales (VM). La utilidad se puede configurar para control manual o automático. Los grupos de recursos de VMware se pueden agregar, eliminar o reorganizar fácilmente. Si lo desea, los grupos de recursos pueden aislarse entre diferentes unidades de negocios. Si la carga de trabajo de una o más máquinas virtuales cambia drásticamente, VMware DRS redistribuye las máquinas virtuales entre servidores físicos. Si se reduce la carga de trabajo general, algunos servidores físicos pueden estar temporalmente fuera de servicio y la carga de trabajo consolidada ".¿Por qué necesito equilibrio?
En nuestra opinión, DRS es una característica indispensable de la nube, aunque esto no significa que DRS deba usarse en cualquier momento y en cualquier lugar. Dependiendo del propósito y las necesidades de la nube, puede haber diferentes requisitos para DRS y métodos de equilibrio. Quizás hay situaciones en las que no es necesario equilibrar en absoluto. O incluso dañino.
Para comprender mejor dónde y para qué clientes DRS son necesarios, considere sus metas y objetivos. Las nubes se pueden dividir en públicas y privadas. Estas son las principales diferencias entre estas nubes y los objetivos del cliente.
Sacamos las siguientes conclusiones para nosotros mismos:
Para nubes privadas proporcionadas a grandes clientes corporativos, DRS puede aplicarse sujeto a restricciones:
- seguridad de la información y reglas de afinidad contable para el equilibrio;
- disponibilidad de una cantidad suficiente de recursos en caso de accidente;
- los datos de la máquina virtual residen en un sistema de almacenamiento centralizado o distribuido;
- diversidad de tiempo de los procedimientos de administración, respaldo y equilibrio;
- balancear solo dentro del conjunto de hosts del cliente;
- equilibrar solo con un fuerte desequilibrio, la migración más eficiente y segura de máquinas virtuales (después de todo, la migración puede fallar);
- equilibrar máquinas virtuales relativamente "silenciosas" (la migración de máquinas virtuales "ruidosas" puede llevar mucho tiempo);
- equilibrio teniendo en cuenta el "costo": la carga en el sistema de almacenamiento y la red (con arquitecturas personalizadas para grandes clientes);
- equilibrio teniendo en cuenta el comportamiento individual de cada VM;
- El equilibrio es deseable después de las horas (noche, fines de semana, días festivos).
Para las nubes públicas que brindan servicios a pequeños clientes, DRS se puede usar con mucha más frecuencia, con características avanzadas:
- falta de restricciones de seguridad de la información y reglas de afinidad;
- equilibrio dentro de la nube;
- balanceo en cualquier momento razonable;
- equilibrar cualquier VM;
- equilibrar máquinas virtuales "ruidosas" (para no interferir con el resto);
- los datos de la máquina virtual a menudo se encuentran en unidades locales;
- que representa el almacenamiento promedio y el rendimiento de la red (la arquitectura de la nube está unificada);
- equilibrio de acuerdo con reglas generalizadas y estadísticas disponibles del comportamiento del centro de datos.
Complejidad del problema
La dificultad del equilibrio es que DRS debe trabajar con muchos factores inciertos:
- comportamiento del usuario de cada uno de los sistemas de información del cliente;
- algoritmos para la operación de servidores de sistemas de información;
- Comportamiento del servidor DBMS
- carga en recursos informáticos, almacenamiento, red;
- interacción del servidor entre ellos en la lucha por los recursos en la nube.
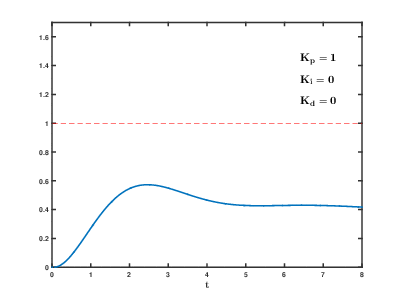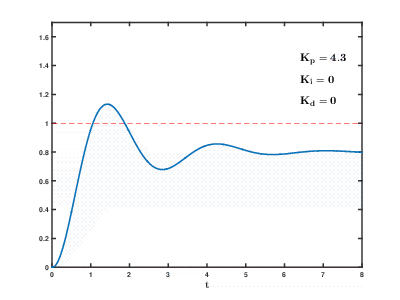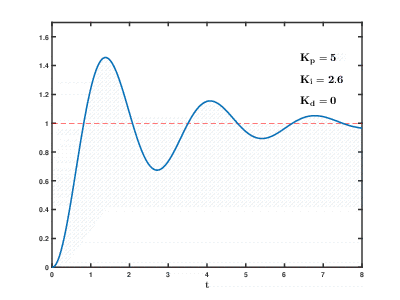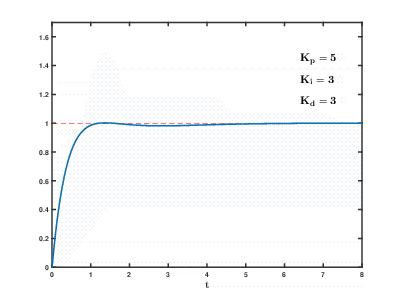
La carga de una gran cantidad de servidores de aplicaciones virtuales y bases de datos en los recursos de la nube ocurre con el tiempo, las consecuencias pueden ocurrir y superponerse con efectos impredecibles después de tiempos impredecibles. Incluso para controlar procesos relativamente simples (por ejemplo, para controlar un motor, un sistema de calentamiento de agua en el hogar), los sistemas de control automático necesitan usar complejos algoritmos de retroalimentación
diferenciales proporcionales integrales .

Nuestra tarea es mucho más complicada en muchos órdenes de magnitud, y existe el riesgo de que el sistema no pueda equilibrar la carga a los valores establecidos en un tiempo razonable, incluso si no ocurren influencias externas de los usuarios.
Historia de nuestros desarrollos.
Para resolver este problema, decidimos no comenzar desde cero, sino basarnos en la experiencia existente, y comenzamos a interactuar con especialistas que tienen experiencia en este campo. Afortunadamente, nuestra comprensión de los problemas coincidió por completo.
Etapa 1
Utilizamos un sistema basado en tecnología de redes neuronales e intentamos optimizar nuestros recursos sobre la base.
El interés de esta etapa era probar la nueva tecnología, y su importancia era aplicar un enfoque no estándar para resolver el problema, donde, en igualdad de condiciones, los enfoques estándar prácticamente se han agotado.
Comenzamos el sistema, y realmente fuimos balanceando. La escala de nuestra nube no nos permitió obtener resultados optimistas anunciados por los desarrolladores, pero estaba claro que el equilibrio estaba funcionando.
Además, teníamos limitaciones bastante serias:
- Para entrenar una red neuronal, las máquinas virtuales deben ejecutarse sin cambios significativos durante semanas o meses.
- El algoritmo está diseñado para la optimización basada en el análisis de datos "históricos" anteriores.
- Para entrenar una red neuronal, se requiere una cantidad suficientemente grande de datos y recursos informáticos.
- La optimización y el equilibrio se pueden hacer relativamente raramente, una vez cada pocas horas, lo que claramente no es suficiente.
Etapa 2
Como no estábamos contentos con el estado de cosas, decidimos modificar el sistema, y para que esto respondiera la
pregunta principal : ¿para quién lo estamos haciendo?
Primero para clientes corporativos. Por lo tanto, necesitamos un sistema que funcione de manera eficiente, con esas restricciones corporativas que solo simplifican la implementación.
La segunda pregunta es ¿qué significa la palabra "operacional"? Como resultado de un breve debate, decidimos que era posible aprovechar el tiempo de respuesta de 5-10 minutos para que los saltos a corto plazo no introdujeran el sistema en la resonancia.
La tercera pregunta es ¿qué tamaño del número equilibrado de servidores elegir?
Este problema se decidió por sí mismo. Por lo general, los clientes no hacen que los agregados de servidores sean muy grandes, y esto es consistente con las recomendaciones del artículo para limitar los agregados a 30-40 servidores.
Además, al segmentar el grupo de servidores, simplificamos la tarea del algoritmo de equilibrio.
La cuarta pregunta es ¿cuánto nos conviene una red neuronal con su largo proceso de aprendizaje y su raro equilibrio? Decidimos abandonarlo en favor de algoritmos operativos más simples para obtener el resultado en segundos.
 Aquí
Aquí puede encontrar una descripción del sistema que utiliza dichos algoritmos y sus deficiencias
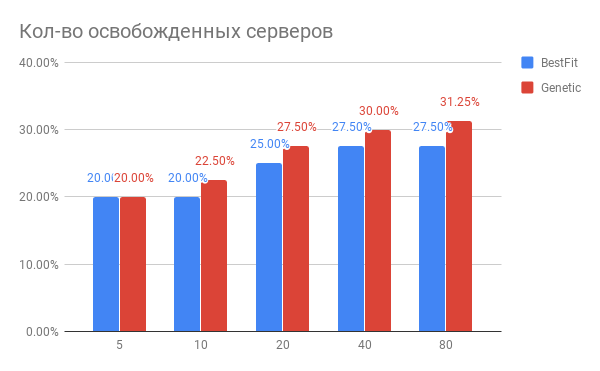
.Implementamos y lanzamos este sistema y recibimos resultados alentadores: ahora analiza regularmente la carga en la nube y ofrece recomendaciones sobre el movimiento de máquinas virtuales, que en gran medida son correctas. Incluso ahora está claro que podemos lograr una liberación del 10-15% de recursos para nuevas máquinas virtuales con una mejora en la calidad de las existentes.

Cuando la RAM o la CPU detectan un desequilibrio, el sistema le da comandos al programador de Tionics para realizar la migración en vivo de las máquinas virtuales requeridas. Como se puede ver en el sistema de monitoreo, la máquina virtual se movió de un host (superior) a otro (inferior) y liberó memoria en el host superior (resaltado en círculos amarillos), ocupándolo, respectivamente, en el host inferior (resaltado en círculos blancos).
Ahora estamos tratando de evaluar con mayor precisión la efectividad del algoritmo actual y estamos tratando de encontrar posibles errores en él.
Etapa 3
Parece que puede calmarse con esto, esperar una efectividad comprobada y cerrar el tema.
Pero las siguientes oportunidades de optimización obvias nos empujan a llevar a cabo una nueva fase.
- Las estadísticas, por ejemplo, aquí y aquí muestran que los sistemas de dos y cuatro procesadores en su rendimiento son significativamente más bajos que los de un solo procesador. Esto significa que todos los usuarios reciben retornos significativamente más bajos de CPU, RAM, SSD, LAN, FC comprados en sistemas multiprocesador en comparación con los de un solo procesador.
- Los propios planificadores de recursos pueden trabajar con errores graves, este es uno de los artículos sobre este tema.
- Las tecnologías ofrecidas por Intel y AMD para monitorear RAM y caché le permiten estudiar el comportamiento de las máquinas virtuales y ubicarlas de tal manera que los vecinos ruidosos no interfieran con las máquinas virtuales silenciosas.
- Expandir el conjunto de parámetros (red, almacenamiento, prioridad de máquina virtual, costo de migración, su disponibilidad para la migración).
Total
El resultado de nuestro trabajo para mejorar los algoritmos de equilibrio fue una conclusión inequívoca de que, debido a los algoritmos modernos, es posible lograr una optimización significativa de los recursos (25-30%) de los centros de datos y mejorar la calidad del servicio al cliente.
El algoritmo basado en redes neuronales es, por supuesto, una solución interesante que necesita un mayor desarrollo, y debido a las restricciones existentes, no es adecuado para resolver tales problemas en volúmenes característicos de nubes privadas. Al mismo tiempo, en nubes públicas de tamaño significativo, el algoritmo mostró buenos resultados.
En los siguientes artículos le informaremos más sobre las capacidades de los procesadores, programadores y el equilibrio de alto nivel.