
Soy un líder de equipo y mi tarea es asegurar el trabajo productivo del equipo. Esto no es fácil, ya que no existe una receta preparada para el éxito. Por supuesto, existen metodologías reconocidas:
Agile ,
Lean ,
Value Stream Mapping . Dan pautas y valores comunes, lo cual ya es bueno, pero estas son solo pautas. Y con soluciones específicas, sé amable, conviértete. Es por eso que tú y el líder del equipo.
En el artículo contaré cómo el equipo y yo nos formamos gradualmente y ahora perfeccionamos regularmente el enfoque para un trabajo efectivo. El punto clave es que las herramientas seleccionadas son realmente aceptadas por todo el equipo y han echado raíces en el trabajo. Esto da esperanza de que el enfoque sea útil.
Un poco de contexto
En True Engineering, estamos comprometidos con el desarrollo empresarial. Hacemos un gran producto de varios años en el que participan muchos equipos. Específicamente, nuestro equipo consta de siete personas: cuatro desarrolladores, un líder de equipo técnico (escribe código y mucho), un control de calidad y un primer ministro. El producto en el que está trabajando el equipo tiene dos años. La condición técnica, por los esfuerzos de todo el equipo, es casi ejemplar.
El malestar como herramienta de diagnóstico.
Para encontrar y reconocer problemas en el equipo, utilizamos una herramienta bastante simple: la incomodidad de los participantes.
Esto, por supuesto, no se trata de una situación en la que una persona tiene aire acondicionado y otra está caliente. Estoy hablando de fallas en el flujo normal de trabajo.
Por ejemplo, el lanzamiento fue torcido, aunque cada uno hizo bien su trabajo. O la estabilización ha estado ocurriendo durante dos semanas y el equipo se está desgarrando, aunque nosotros mismos hicimos estimaciones y nadie nos molestó en hacerlo bien. O el negocio no obtuvo lo que esperaba.
Cómo actuar en una situación similar:
- Detén el pánico y date cuenta de por qué nos sentimos incómodos en este momento.
- Llegar al fondo de la causa raíz. Por ejemplo, usando la técnica Five Why o simplemente sentido común.
- Decide cómo tratar el problema. Las pautas para elegir la solución correcta se discutirán al final del artículo. Aquí noto un punto fundamentalmente importante: utilizamos la incomodidad para diagnosticar problemas, pero esto no significa que la pauta para elegir soluciones sea lograr la comodidad. Recuerde que la razón principal por la que usted existe como equipo es el valor comercial. Nadie necesita un equipo feliz que no traiga resultados.
- Después de un tiempo, realice una retrospectiva. Si la decisión no ayudó, volvemos al párrafo 1 con un nuevo entendimiento. Si ayuda, automatizamos o agregamos a la lista de principios para futuros principiantes. Ya no se necesita control, los propios participantes adoptarán el enfoque para trabajar si es realmente bueno.
El algoritmo descrito es simple, pero los detalles no son suficientes. A continuación, describiré los principios que hemos deducido utilizando este enfoque. Para que el artículo no se convierta en una memoria, describiré solo el resultado obtenido, y no toda la historia desde la conciencia del dolor hasta su eliminación.
Los principios sobre los que construimos el proceso.
1. Creamos y acortamos constantemente bucles de retroalimentación
Toda interacción humana con el mundo exterior se basa en la retroalimentación, sin ella es imposible verificar la corrección de la acción realizada. Imagine cómo sería nuestra vida si no sintiéramos dolor al saltar desde una altura de cuatro metros o al agarrar una tetera al rojo vivo.
En el desarrollo, la finalización del código puede servir como un ejemplo de un buen ciclo de retroalimentación breve: nos informa sobre la corrección de la acción justo en el momento de la entrada del código.
Ahora un ejemplo de la ausencia de un bucle de retroalimentación: sabemos sobre el problema con los usuarios, pero no podemos reproducirlo, no tenemos registros, no hay forma de implementar rápidamente la solución y ni siquiera sabemos qué versión está actualmente en el producto. No desearás al enemigo.
Cada acción en el proceso de desarrollo puede y debe dar retroalimentación: compilación, pelusa, autocomprobaciones aprobadas, pruebas realizadas, una sesión de prueba con el negocio, implementación exitosa, monitoreo de productos: todas estas son formas de detectar errores y ajustar sus acciones adicionales.
También vale la pena señalar que el costo del error aumenta a medida que avanza. Si lanzamos un error de producción en producción que estropea los datos, entonces la tarea no es solo solucionarlo, sino también restaurar los datos (si es posible). El costo de la eliminación tardía de dicho error es muy alto, sin mencionar las consecuencias para el negocio.
Por lo tanto, la presencia de una gran cantidad de circuitos de retroalimentación rápidos e informativos es vital.
Debajo están los bucles que conscientemente apoyamos y acortamos si es posible. Supongo que la mayoría de ustedes lo saben. ¿Pero realmente los tienes y trabajas?
- La capacidad de ejecutar y ejecutar un proyecto localmente.
- Diseñado para fallar rápido .
- Creación rápida e informativa de CI.
- Revisión constante del código y trabajo con código a través de solicitudes de extracción.
- Disponibilidad de autotest. Las pruebas son mensajes de error rápidos, estables e informativos.
- Despliegue automático, porque el manual se realizará con menos frecuencia.
- Lanzamientos frecuentes en lugar de acumular y lanzar una versión una semana después de completar las tareas.
- Registros informativos, monitoreo, herramientas de diagnóstico. Acceso a ellos desde todo el equipo.
- La capacidad de filtrado y visualización gráfica de registros.
- Monitoreo continuo de los indicadores técnicos y funcionales del sistema como parte del trabajo diario.
- Estudio empírico del sistema: Google Analytics, análisis de los datos acumulados en el sistema.
- Almacenar el historial de cambios de datos en lugar del estado final, si corresponde.
- Trabajo conjunto y apretado de Dev, Ops, QA, negocios en lugar de "arrojar la valla" de los resultados de la etapa anterior.
- Realización de retrospectivas periódicas tanto dentro del equipo como con el negocio.
- Comentarios regulares de la empresa. Aún mejor es la retroalimentación del usuario final.
- La capacidad de observar el trabajo de los usuarios "en los campos".
- La capacidad de observar al usuario que ve su sistema por primera vez.
En general, la retroalimentación en sí misma debe ser llamativa. Como, por ejemplo, una construcción rota.
Lo que es notable, a veces un cambio muy pequeño es suficiente para una mejora radical.
Por ejemplo, escribe registros en
ELK . Están estructurados, analizados, disponibles al público: todo está bien. Pero, ¿con qué frecuencia pasa el desarrollador durante la depuración? Lo más probable es que no.
Si los mensajes de nivel de advertencia y superior se muestran directamente en el IDE, entonces existe la posibilidad de notar, por ejemplo, el tiempo de ejecución de la consulta. Incluso si no está relacionado con la tarea actual. Existe la posibilidad de notar el problema antes, y el costo de solucionarlo será menor.
2. Cualquier actividad deja artefactos públicos
Los artefactos deben ser exactamente públicos. Y útil.
Gracias a este principio, minimizamos el
factor bus , brindamos una comprensión unificada de la situación, trabajamos (y fakapim) conscientemente, sacando conclusiones constantemente.
Algunas prácticas son obvias y generalmente aceptadas: mensajes informativos de confirmaciones, conexión de confirmaciones con tareas, descripción de cómo evaluar, definición de hecho.
Hay puntos menos obvios:
- No puede "simplemente arruinarlo", la falla debe ser realizada. Si el análisis revela requisitos mal pensados, entonces el refinamiento deliberado se convertirá en un artefacto para todos. Si el problema está en la arquitectura del sistema, el artefacto será el deber técnico descrito con un término claro para llevarlo al trabajo.
- La cantidad de conocimiento en el correo, mensajería instantánea, cabezas debe ser mínima. Todos los refinamientos se reflejan en la base de conocimiento o en el rastreador de tareas. Entonces, cuando el probador acepta la tarea, los requisitos cambiantes para él no serán noticia. Cuando una empresa acepta un resultado, todos entienden lo que deben obtener. Este estado convierte el trabajo en una corriente continua. Bríndelo (descubra los detalles, actualice la base de conocimientos y la descripción de las tareas): la tarea de cada participante en el proceso.
- Los resultados de la prueba no son solo "Verifiqué, todo está bien", sino una lista disponible públicamente de casos de prueba aprobados, que se compiló y discutió antes de la prueba, y no durante o después. La lista puede ser estudiada y complementada por cada participante en el proceso.
3. Respetamos el derecho del otro al trabajo concentrado
La importancia del trabajo
en la corriente y las
consecuencias de la interrupción , creo, ya son bien conocidas. Por lo tanto, no me detendré en el problema en detalle, sino que me referiré inmediatamente a nuestras prácticas.
- Solo se recomiendan los auriculares.
- La comunicación de trabajo es asíncrona. No distraiga a su colega con una pequeña pregunta, pregúntele en el rastreador de tareas (consulte la sección sobre artefactos disponibles públicamente).
- A veces suceden cosas que interrumpen el modo normal de operación: un accidente en la producción, requisitos incomprensibles para una tarea ya puesta en marcha. Una señal puede ser una discusión ruidosa en la oficina, en la que participan tres o más personas. Si esta situación no se resuelve en unos minutos, nombraré a una persona para que aclare los detalles. El resto volverá a la operación normal hasta que la persona responsable proporcione información para su posterior análisis.
4. Evitamos la multitarea
Porque la
multitarea no funciona . Ella solo agota, rocía la atención y pospone recibir el resultado.
Qué prácticas ayudan:
- Límite de trabajo en progreso .
- Centrándose en el flujo de valor, no en los recursos. Por ejemplo, el primer desarrollador puede hacer la tarea en un día y el segundo en tres. Pero el primero se lanzará solo después de una semana. Entonces, el segundo toma la tarea de trabajar. Dedicaremos más tiempo a la implementación, pero entregaremos el resultado más rápido (tres días en lugar de una semana y un día) y pasaremos a la siguiente tarea. Al mismo tiempo, no estamos tratando de "empujar lo inédito" al primer desarrollador y no nos distrae el trabajo que "colgó" en sus expectativas.
- Si varias personas están involucradas en una tarea y el trabajo está completado en un 90%, entonces el objetivo número uno para el equipo es hacer todo lo posible para terminar el último 10%. Solo después de eso seguimos adelante.
5. Tomamos decisiones arquitectónicas lo más tarde posible
Este no es nuestro conocimiento, sino
uno de los principios básicos de la fabricación ajustada .
La decisión tomada e implementada limita la posibilidad de más cambios. Y si la decisión se toma en condiciones de información incompleta (y este es casi siempre el caso), entonces las posibilidades de tomar una decisión incorrecta son significativamente mayores.
Si el hecho de no tomar una decisión no bloquea el trabajo y no conduce a un aumento exponencial de la deuda técnica, debe posponerse, dejando el sistema listo para cualquier decisión en el futuro, cuando tengamos más información.
Esta es la base del desarrollo: no construimos arquitecturas "grandes" antes del inicio del proyecto. En cambio, hacemos que el proceso de refactorización sea seguro (consulte la sección sobre bucles de retroalimentación) y lo convertimos en una parte natural del proceso.
Del mismo modo, no estamos tratando de adivinar los requisitos futuros del sistema o crear una solución universal. La capacidad de refactorizar de forma segura es más universal porque permite realizar cambios en el futuro.
6. El código está operativo en cualquier momento.
Por supuesto, este estado es inalcanzable en absoluto, el sistema se descompondrá periódicamente después de realizar cambios. Pero esto no significa que no se deba buscar esta característica.
Cuando un colapso es una situación anormal, y no una norma de vida, sus causas son fáciles de encontrar. Esta suele ser la última confirmación. Por lo tanto, la persona responsable es comprensible, los pasos para eliminar son comprensibles, está claro cuando volvemos a un estado estable.
La confianza resultante en el funcionamiento del sistema ofrece una valiosa oportunidad de lanzamiento en cualquier momento.
El segundo valor es que tenemos más confianza para hacer promesas de disponibilidad. Si dividimos el trabajo en dos fases: "desarrollo" y "estabilización", entonces es difícil hacer una promesa concreta, ya que "estabilización" es trabajar con problemas que aún no conocemos. Por lo tanto, no podemos evaluarlos con precisión.
Si la estabilización va inextricablemente con el desarrollo y hay todas las herramientas necesarias para esto, entonces la situación es más predecible.
Cómo mantenemos un rendimiento continuo:
- Obvio: revisión de código, pruebas automáticas, banderas de características.
- Cualquier cambio se implementa inmediatamente en el entorno de prueba. Si está roto, no podrá repararlo más tarde: el control de calidad está bloqueado.
- Prueba en un flujo continuo inmediatamente después de la finalización de las tareas, mientras que el desarrollador recuerda la tarea y el código y rápidamente realiza correcciones.
- No hacemos el trabajo en partes. Si se necesitan dos personas para la implementación, entonces trabajan en pares, en una rama, cargan el código en la rama principal cuando está completamente listo y cubierto en pruebas.
- Automatización de entrega y artefactos de entrega fijos que no necesitan ser "terminados" manualmente.
- Cada miembro del equipo conoce herramientas de diagnóstico, sabe cómo trabajar con ellas y sabe cómo realizar lanzamientos.
7. Somos un equipo, no un grupo de desarrollo.
¿Qué significa "equipo":
- Todo el código es revisado por al menos una persona. Si se descubre un problema grave, se los alienta a sentarse juntos y programar en pareja. Compartir un libro, un artículo, una explicación detallada en lugar de transmitir opiniones personales no tiene precio.
- En lugar de desarrollar en pedazos con la posterior integración dolorosa del resultado, trabajamos estrechamente en pares cuando es necesario.
- No convertimos al revisor en una herramienta para verificar errores tipográficos, traemos una solicitud de extracción limpia y pequeña a la revisión.
- No lanzamos tareas "a través de la cerca", sino que entregamos cuidadosamente el trabajo de QA, comprobando el camino feliz usted mismo. Ayudamos al control de calidad a comprender qué y cómo evaluar, ayudamos a pasar los escenarios fronterizos (por ejemplo, romper artificialmente el sistema).
- QA, a su vez, estudia la estructura interna del sistema, sabe cómo recopilar todos los detalles necesarios (registros, estado de los datos) y obtener un error extremadamente informativo.
8. Picamos colas
Para maximizar la eficiencia y la concentración del trabajo actual, eliminamos las "deudas" asociadas con el trabajo ya realizado:
- Las tareas se llevan a las ventas lo más rápido posible. Solo después de eso los consideramos hechos.
- Estamos eliminando constantemente la deuda técnica para que no aumente el alto costo de la reparación (una semana) y no bloquee el trabajo, arruinando los planes para la entrega de la funcionalidad comercial.
- No comenzamos tareas que haremos "algún día", pero eliminamos las tareas de larga duración. Una empresa ciertamente vendrá a realizar una tarea cuando (si) realmente llegue el momento de hacerlo. Y por si acaso, en el rastreador de tareas, puede restaurar la tarea eliminada. Pero esta función nunca nos ha sido útil.
- Ramas de larga vida, código comentado, To-do-shki: todo esto es un código muerto, cuyo lugar está en la canasta.
- Las pruebas inestables se corrigen o eliminan inmediatamente y se reemplazan por otras inferiores.
- Hacemos un seguimiento de las tareas "progresivas".
El último punto merece una explicación por separado.
Me refiero a tareas “progresivas” con costos laborales iniciales pequeños, pero que se mantienen en progreso durante varios días o semanas.
¿Por qué puede ser esto?
- La tarea inicialmente estaba mal diseñada, ya requería muchos refinamientos, las aclaraciones son contradictorias o incompletas. Entonces, dejamos de perder el tiempo, dejamos de trabajar en la tarea y volvemos a la declaración.
- La tarea está en un estado de espera de un resultado de alguien. Por ejemplo, un servicio de otro equipo o refinamiento de una empresa. Mantenemos tales tareas en un lápiz y no las dejamos ir solas.
Es difícil cumplir con este punto. En primer lugar, se debe realizar el "arrastre". Luego, debe tomar una decisión decidida y dar un paso atrás hacia los detalles. Esto es difícil para el desarrollador, ya que ya se ha gastado tiempo. Y, por supuesto, tal decisión enfrentará la resistencia del negocio. Pero la práctica muestra que esto reduce las posibilidades de producir un resultado con el que ni el equipo, ni el negocio, ni los usuarios estarán contentos.
El gráfico de tiempo de ciclo ayuda en la búsqueda de tales tareas. Muestra el tiempo desde el momento de llevar al trabajo hasta su finalización. Si la tarea está "fuera de la multitud", entonces este es un candidato para un examen minucioso.
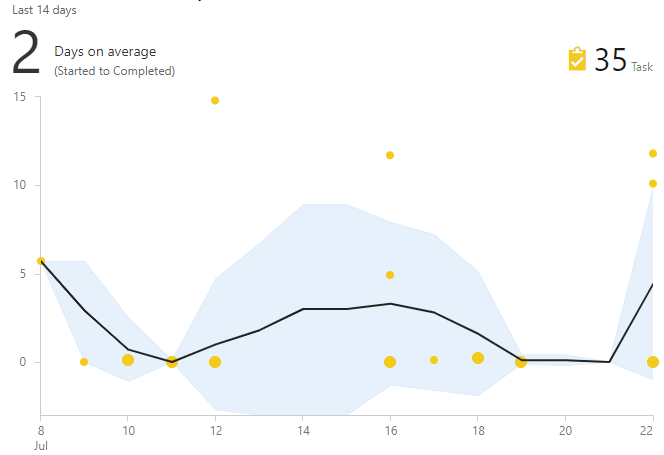
Cómo elegir soluciones útiles
Desafortunadamente, no tengo una receta lista para usar. La efectividad del equipo es una tarea heurística, lo que significa que no tiene soluciones garantizadas.
Pero todavía hay alguna lista de verificación. Aquí esta:
- Escribí sobre esto al comienzo del artículo y repito aquí: el hecho de que usemos la incomodidad para diagnosticar problemas no significa que nos esforcemos por la comodidad al tomar decisiones. Recuerde el objetivo principal: aumentar el valor para el negocio.
- Al analizar los problemas, recuerde que todos los participantes tienen buenas intenciones . Si su pensamiento se basa en una creencia paranoica de que alguien lo está lastimando intencionalmente, tomar una buena decisión es muy difícil.
- No intentes romper todo y reconstruir. Muévase en pequeños pasos, haciendo cambios gradualmente. Espere hasta que los cambios realizados traigan resultados, y solo entonces introduzca otros nuevos.
- Si no hay una solución clara, avance en pequeños pasos, evaluando constantemente el resultado y probando varias opciones. Un ciclo de retroalimentación claro y una reflexión constante son una herramienta de desarrollo inagotable para usted y el equipo.
- Forja la plancha mientras hace calor. No posponga el análisis hasta la retrospectiva: el equipo ya olvidará lo que estaba sucediendo. Es mejor llegar a una retrospectiva con un problema ya reconocido y soluciones preparadas que aún deben sopesarse con el equipo y elegir la mejor.
- La decisión debe ser tomada por todo el equipo. No plantar desde arriba funcionará, y los intentos de controlar son solo una ilusión.
- No inculque en personas tareas que sean atípicas para sus actividades diarias. Encontrará mil explicaciones plausibles de por qué no se hizo la promesa, pero no obtendrá el resultado.
- El efecto de la decisión debe ser tangible. Raramente tendrá éxito en formular una decisión sobre las características de SMART , pero debe existir alguna forma consciente de evaluar el resultado. Al menos sobre la base de "ahora esto sucede con menos frecuencia".
- Intenta registrar regularmente lo que más duele ahora. Si después de medio año vuelves a leer las grabaciones con una sonrisa, pensando "había una lata", estás en el camino correcto.
Conclusión
En conclusión, discutamos las debilidades del enfoque.
En primer lugar, este enfoque funciona para buscar optimizaciones locales; no es posible construir una estrategia de desarrollo para el producto y toda la empresa con él. Por supuesto, la conciencia de los problemas es mejor que inconscientemente basura y quemaduras en el trabajo, pero este es solo el primer paso.
También le pido que no tome una lista de principios ya preparada, tome la herramienta con la que fue creada. He aquí por qué:
Nuestra lista no está completa. Contiene solo lo que ya hemos implementado en nuestro trabajo diario.
El equipo no toma principios arraigados, la importancia de la cual ella no se dio cuenta, a pesar del dolor de su ausencia. En lugar de ideas de trabajo, obtendrá un hombre del saco que todos llevarán por la oficina durante algún tiempo, y luego colocará el polvo en una esquina.
Nuestra lista es específica. Por ejemplo, si la deuda técnica del proyecto ha sido ignorada durante cinco años y es comparable a la deuda pública de los Estados Unidos, entonces será muy difícil obtener el beneficio del principio del exterminio constante de la deuda técnica. Es justo admitirlo: una deuda de este tamaño nunca será pagada. Y enfóquese en soluciones que realmente ayuden a mejorar la situación.
¿Cómo se mejora el proceso? ¿Y qué principios has adoptado en tu trabajo?