En los últimos años,
la traducción automática neuronal (NMP) utilizando los modelos de "transformador" ha logrado un éxito extraordinario. Los FMI basados en redes neuronales profundas generalmente se entrenan de principio a fin en casos paralelos muy voluminosos de textos (pares de texto) únicamente sobre la base de los datos mismos, sin la necesidad de asignar reglas de lenguaje exactas.
A pesar de todos los éxitos, los modelos NMP pueden ser sensibles a pequeños cambios en los datos de entrada, que pueden manifestarse en forma de varios errores: traducción insuficiente, traducción excesiva y traducción incorrecta. Por ejemplo, la próxima propuesta alemana, el "transformador" modelo NMP de alta calidad se traducirá correctamente.
"Der Sprecher des Untersuchungsausschusses hat angekündigt, vor Gericht zu ziehen, falls sich die geladenen Zeugen weiterhin weigern sollten, eine Aussage zu machen".
(Traducción automática: "El portavoz de la Comisión de Investigación ha anunciado que si los testigos convocados continúan negándose a declarar, lo llevarán a los tribunales").
Traducción: Un representante del Comité de Investigación anunció que si los testigos invitados continúan negándose a declarar, él será responsable.
Sin embargo, cuando realiza un pequeño cambio en la oración entrante, reemplazando la palabra geladenen con el sinónimo vorgeladenen, la traducción cambia dramáticamente (y se vuelve incorrecta):
"Der Sprecher des Untersuchungsausschusses hat angekündigt, vor Gericht zu ziehen, falls sich die vorgeladenen Zeugen weiterhin weigern sollten, eine Aussage zu machen".
(Traducción automática: "El comité de investigación ha anunciado que lo llevarán ante la justicia si los testigos que han sido invitados continúan negándose a declarar").
Traducción: el comité de investigación anunció que sería llevado ante la justicia si los testigos invitados continúan negándose a testificar.
La falta de estabilidad de los modelos NMP no permite que los sistemas comerciales se apliquen a tareas en las que un nivel similar de inestabilidad es inaceptable. Por lo tanto, la disponibilidad de aprender modelos de traducción sostenibles no solo es deseable, sino que a menudo es necesario. Al mismo tiempo, aunque una comunidad de investigadores de la visión por computadora estudia activamente la estabilidad de las redes neuronales, existen pocos materiales sobre modelos de NMP de aprendizaje estable.
En nuestro
documento, "Traducción automática sostenible con doble entrada de confrontación", proponemos un enfoque que utiliza los ejemplos de confrontación generados para mejorar la estabilidad de los modelos de traducción automática para pequeños cambios de entrada. Enseñamos un modelo NMP estable para superar los ejemplos competitivos generados teniendo en cuenta el conocimiento sobre este modelo y para distorsionar sus predicciones. Mostramos que este enfoque mejora la eficiencia del modelo NMP en las pruebas estándar.
Entrenamiento modelo con AdvGen
Un modelo NMP ideal debería generar traducciones similares para diferentes entradas que tienen ligeras diferencias. La idea de nuestro enfoque es interferir con el modelo de traducción utilizando aportes competitivos con la esperanza de aumentar su estabilidad. Esto se lleva a cabo utilizando el algoritmo de Generación Adversarial (AdvGen), que genera ejemplos competitivos válidos que interfieren con el modelo y luego los introducen en el modelo para el entrenamiento. Aunque este método está inspirado en la idea de redes competitivas generativas (GSS), no utiliza una red discriminante, sino que simplemente utiliza un ejemplo competitivo en el entrenamiento, de hecho, diversificando y expandiendo el conjunto de entrenamiento.
El primer paso es indignar los datos con AdvGen. Comenzamos utilizando un transformador para calcular la pérdida de una transferencia en función de la oferta entrante original, la oferta de entrada objetivo y la oferta de salida objetivo. AdvGen luego selecciona aleatoriamente las palabras en la oración original, actuando bajo el supuesto de su distribución uniforme. Cada palabra tiene una lista correspondiente de palabras similares, es decir candidatos de sustitución. A partir de él, AdvGen selecciona la palabra que es más probable que conduzca a errores en la salida del transformador. Luego, esta oración adversaria generada se retroalimenta al transformador, comenzando la etapa de defensa.
 Primero, el modelo del transformador se aplica a la oración entrante (abajo a la izquierda), y luego la pérdida de traducción se calcula junto con la oración de salida objetivo (arriba) y la oración de entrada objetivo (en el centro a la derecha, comenzando con "<sos>"). AdvGen luego acepta la oración original, la distribución de selección de palabras, los candidatos de palabras y la pérdida de traducción como entrada, y crea un ejemplo de código fuente contradictorio.
Primero, el modelo del transformador se aplica a la oración entrante (abajo a la izquierda), y luego la pérdida de traducción se calcula junto con la oración de salida objetivo (arriba) y la oración de entrada objetivo (en el centro a la derecha, comenzando con "<sos>"). AdvGen luego acepta la oración original, la distribución de selección de palabras, los candidatos de palabras y la pérdida de traducción como entrada, y crea un ejemplo de código fuente contradictorio.En la etapa de defensa, el código fuente adversario se retroalimenta al transformador. La pérdida de traducción se cuenta nuevamente, pero esta vez utilizando la fuente de entrada contenciosa. Utilizando el mismo método que antes, AdvGen usa una oración entrante dirigida, distribución de selección de palabras calculada a partir de la matriz de atención, candidatos para el reemplazo de palabras y pérdida de traducción para crear un ejemplo de código fuente contencioso.
 En la etapa de defensa, el código fuente contradictorio se convierte en la entrada para el transformador y se calculan las pérdidas de traducción. Usando el mismo método que antes, AdvGen crea un ejemplo de código fuente contencioso basado en la entrada de destino.
En la etapa de defensa, el código fuente contradictorio se convierte en la entrada para el transformador y se calculan las pérdidas de traducción. Usando el mismo método que antes, AdvGen crea un ejemplo de código fuente contencioso basado en la entrada de destino.Finalmente, la oración de confrontación se retroalimenta al transformador, y la pérdida de estabilidad se calcula con base en el ejemplo de fuente de confrontación, el ejemplo de confrontación de la entrada de destino y la sentencia de destino. Si la intervención en el texto condujo a pérdidas significativas, se minimizan de modo que cuando los modelos encuentran perturbaciones similares, ella no repite el mismo error. Por otro lado, si la perturbación conduce a pequeñas pérdidas, no sucede nada, lo que sugiere que el modelo ya puede hacer frente a tales perturbaciones.
Modelo de rendimiento
Demostramos la efectividad de nuestro enfoque al aplicarlo a pruebas de traducción estándar del chino al inglés y del inglés al alemán. Obtenemos una mejora significativa en la traducción de 2.8 y 1.6 puntos BLEU, respectivamente, en comparación con el modelo de la competencia del transformador, y logramos una nueva calidad de registro de la traducción.
 Comparación de modelos de transformadores en pruebas estándar
Comparación de modelos de transformadores en pruebas estándarLuego evaluamos el rendimiento de nuestro modelo en un conjunto de datos ruidosos utilizando un procedimiento similar al descrito para AdvGen. Tomamos datos de entrada puros, por ejemplo, los utilizados en las pruebas estándar de traductores, y seleccionamos al azar palabras que reemplazamos por otras similares. Encontramos que nuestro modelo muestra una estabilidad mejorada en comparación con otros modelos recientes.
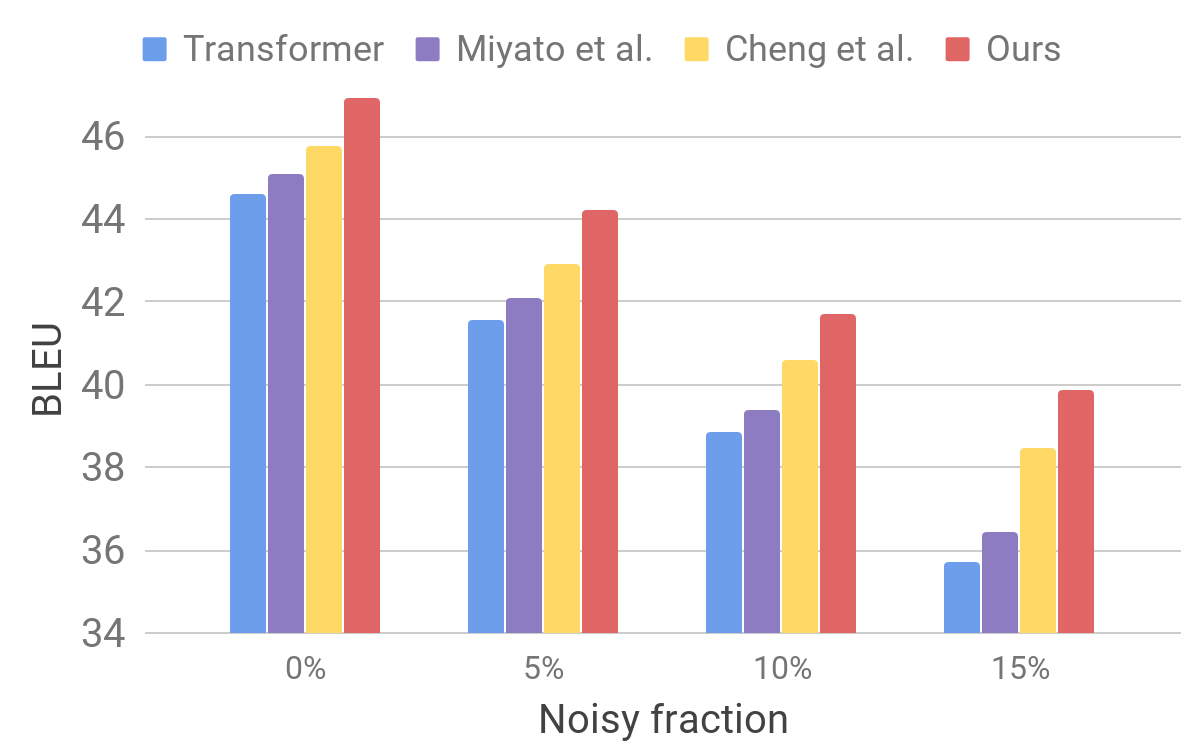 Comparación de transformador y otros modelos en datos de entrada artificialmente ruidosos
Comparación de transformador y otros modelos en datos de entrada artificialmente ruidososEstos resultados muestran que nuestros métodos son capaces de superar pequeñas perturbaciones que surgen en la oración entrante y mejorar la eficiencia de la generalización. Está por delante de los modelos de traducción de la competencia y logra una eficiencia de traducción récord en las pruebas estándar. Esperamos que nuestro modelo de traductor se convierta en una base estable para mejorar los resultados de la resolución de muchos de los siguientes problemas, especialmente aquellos que son sensibles o intolerantes a los textos de entrada imperfectos.