Las pruebas A / B son una forma poderosa de probar las interfaces antes de publicarlas para toda una audiencia. Decidí decir en qué consiste esta herramienta, qué características de registro tiene, cómo se compilan las métricas y cuál es la esencia de los experimentos en la interfaz. Hablemos de sus dispositivos y servicios para resolver tareas analíticas diarias. Discutiremos varias rutas de desarrollo para un desarrollador que parece ser capaz de hacer todo, pero quiere más.
- Mi nombre es Lesha, trabajo en Búsqueda y desarrollo el producto más importante, probablemente Yandex: resultados de búsqueda.
Todos ustedes, de una forma u otra, han utilizado alguna de las búsquedas. Un par de términos El problema consta de varios bloques. Hay documentos orgánicos simples que recopilamos de todo el Internet y de alguna manera sabemos cómo presentar, y hay bloques especiales que mostramos como marcas especiales. Conocemos muchos datos sobre sus contenidos. Estos bloques se llaman brujos. Terminología específica adoptada por Yandex y no solo.
Hoy quiero contarles cómo llevamos a cabo experimentos, qué matices, herramientas y qué maravillosos inventos hay en nuestros zashniks en esta área de nuestra actividad.
¿Para qué sirve la prueba A / B?
Por donde empezar ¿Por qué Yandex necesita experimentos A / B?
Me gustaría comenzar con la letra. No hace mucho tiempo, con mi hija, vi un cortometraje científico "4.5 mil millones de años en 40 minutos. Historia de la Tierra ". Muy a menudo hay experimentos A / B. Incluyendo estos. Traté de hacer uno de los más interesantes y divertidos en esta diapositiva. Esto es cuando la evolución tiene varias ramas. Por ejemplo, hay dos familias: marsupiales y placentarias. Y como vemos ahora, la placenta de alguna manera gana. Por eso ganan.

Este ya es el cerebro humano concebido. En el desarrollo prenatal y posterior de los marsupiales, la caja del cráneo se endurece rápidamente y evita que el cerebro se desarrolle. Y en la placenta, todo progresa, todo es blando hasta que el cerebro se pliega con surcos, la superficie crece y hace que el neocórtex se enfríe. Como resultado, la placentaria ganará en la evolución. Cual es el punto? La naturaleza tiene evolución, y sus fuerzas impulsoras son la mutación y la selección natural, como probablemente ya sepas.

La compañía tiene una analogía de los experimentos A / B de la naturaleza: cualquier negocio quiere desarrollarse de manera estable e invierte ciertos esfuerzos, utilizando los experimentos A / B como una forma de mutar algo, cambiar algo. La compañía utiliza todo el poder matemático de la analítica para seleccionar estos mismos experimentos.
Los experimentos A / B y toda la evolución tienen como objetivo lograr objetivos, ser capaces de observarse desde el exterior, comparar con los competidores y buscar nuevos nichos, hipótesis. Para los desarrolladores en general, especialmente para los proveedores front-end, es importante probar nuevas características en una pequeña fracción de la producción.

Una historia corta se parece a esto. Podemos decir que 2010, cuando nuestros gerentes de producto hicieron los primeros experimentos A / B, es un período posterior al Big Bang. Ciertos cúmulos de estrellas acaban de comenzar a surgir, una comprensión de cómo realizar experimentos A / B, qué mirar, cómo iniciar sesión. Los primeros golpes, los primeros errores, se acumularon.
Durante este período de 2010 a 2019, logramos resultados significativos. Hoy, todos estos términos relacionados con registros, experimentos, métricas, objetivos, logros, etc., ya son básicos para nosotros, en particular para los recién llegados a los nuevos desarrolladores. Esta es nuestra jerga, nuestra mentalidad Yandex interna.
Gran búsqueda
Pasamos directamente a la carne, sobre la gran Búsqueda. Big Search en su estructura se parece a esto.
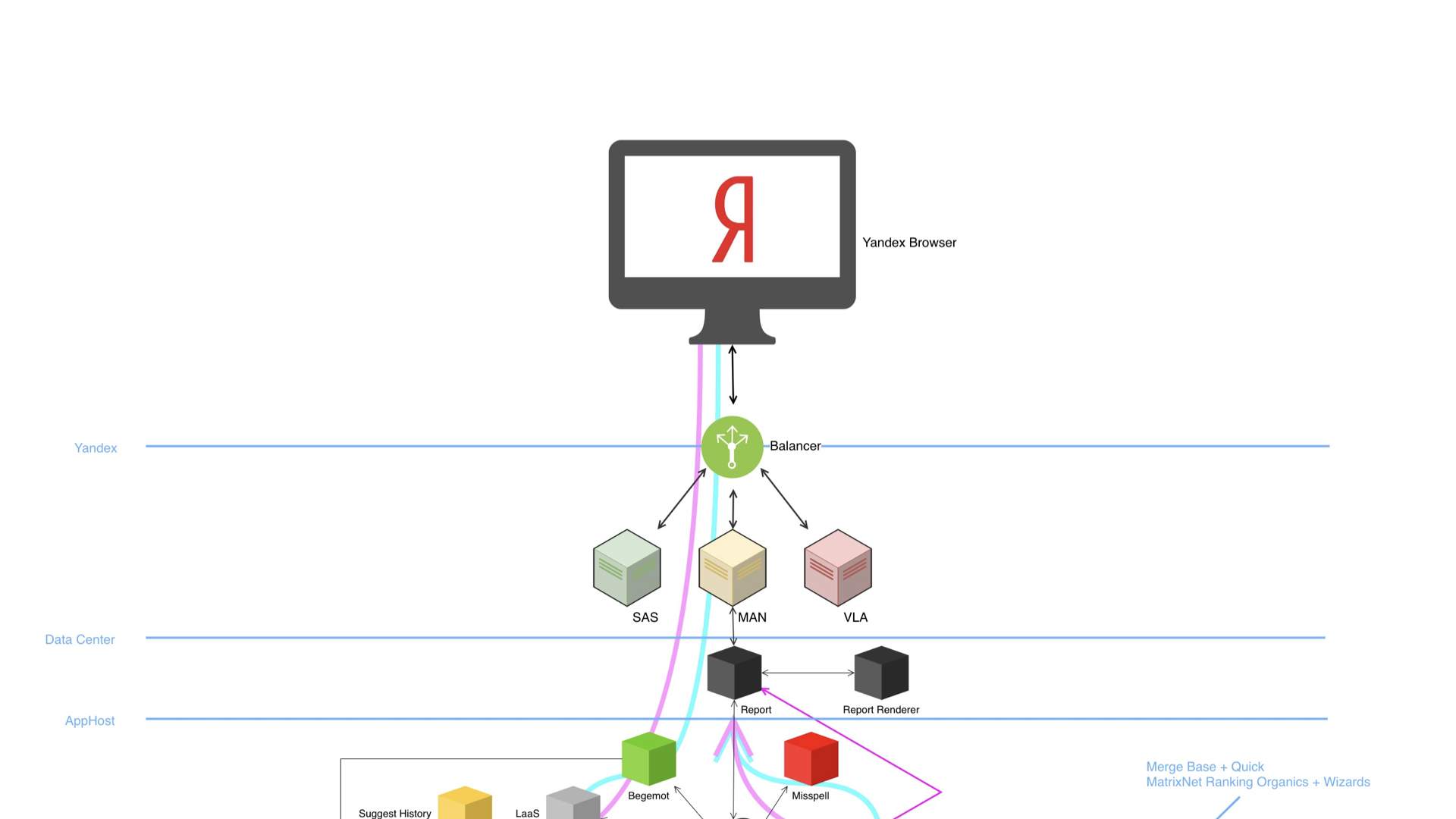
Tenemos un navegador, un equilibrador, muchos centros de datos y una infraestructura enorme y rica bajo el capó. El diagrama demuestra que el dispositivo es complejo, hay muchos componentes. Y lo que es más sorprendente, todos estos componentes pueden realizar experimentos A / B y, por supuesto, escribir y analizar registros.
Registros

Los registros están escritos por muchos, muchos componentes. Por supuesto, es más interesante para nosotros hablar en el contexto de la interfaz. La interfaz registra dos grandes rebanadas significativas. Estos son registros puramente técnicos relacionados con la medición directa de algún tiempo, el rendimiento en los dispositivos del cliente. Medición real del usuario, métricas RUM. Estos son los tiempos antes del primer byte, antes de la primera representación, antes de cargar todo el contenido DOM y antes de la interactividad.
Junto con esto, hay registros escritos por la composición tipográfica del servidor y del cliente. Estos son los registros de comestibles. En nuestras realidades, incluso aquí hay un término "baobab". ¿Por qué baobab? Porque el árbol: el árbol de componentes, el árbol de características, en el que uno de los registros principales son los registros de impresiones, clics y otros eventos técnicos que registramos para su posterior análisis.
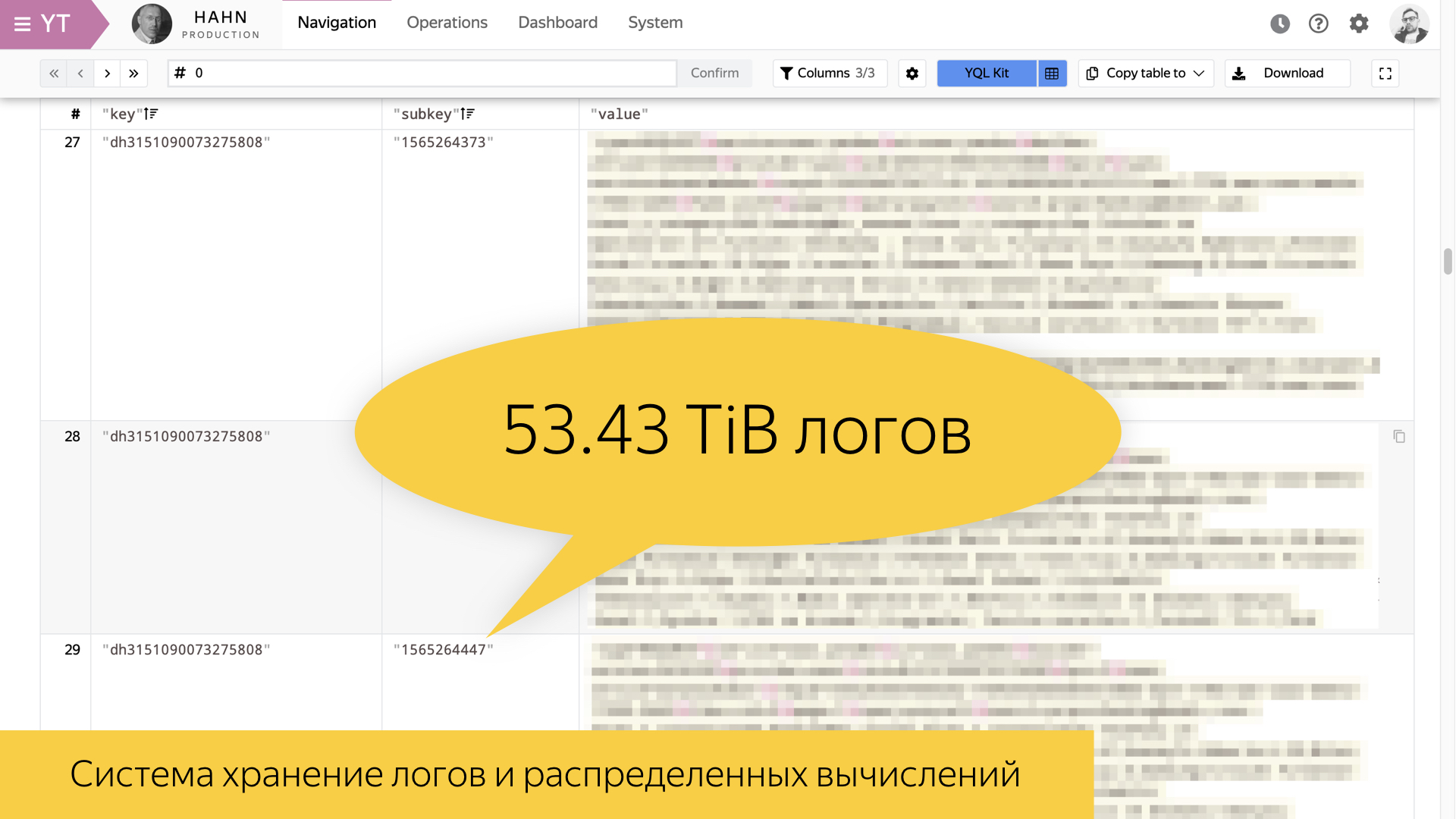
Esta diapositiva muestra una herramienta para almacenar registros dentro de Yandex y para la informática distribuida. Lo tenemos llamado
Yandex Tables, YT . Todo lo desarrollado en Yandex tiene la letra Y. Intenté recordar el análogo de esta herramienta en el mundo exterior. En mi opinión, Facebook tiene una herramienta MapReduce llamada Hadoop. Le permite implementar almacenamiento y cálculo.
La diapositiva muestra estadísticas del 8 de agosto de este año. Uno de los registros de búsqueda más valiosos, las sesiones de usuario, tiene 54 terabytes por día en su forma. Esta es una gran cantidad de información que no puede ser mezclada en su forma cruda. Por lo tanto, uno debe ser capaz de construir algunas historias de alto nivel.
Para trabajar con registros, en particular, todos nuestros desarrolladores especialmente experimentados deben dominar algún tipo de herramienta analítica.
Dentro de Yandex, hay una herramienta
YQL . Este es un lenguaje de consulta y cálculo similar a SQL sobre nuestros registros, que le permite crear todo tipo de entornos, realizar análisis de bajo nivel, mirar directamente números específicos, percentiles promedio y generar informes. La herramienta es bastante poderosa, tiene una gran API ramificada y muchas características. Muchos procesos de infraestructura se construyen sobre su base.
Además, entre nuestros desarrolladores front-end y, en particular, los analistas, la herramienta Jupyter tiene una gran demanda y popularidad. Ya es posible con el poder de las herramientas de Numpy y otras conocidas por usted, por ejemplo, Pandas, realizar algún tipo de transformaciones y análisis de alto nivel sobre nuestros registros.
Realmente valoramos los registros, literalmente luchamos por cada entrada. Para hacer esto, en el repositorio de nuestro proyecto de búsqueda, hay pruebas en el código front-end que nos permiten verificar que todos los eventos se registran correctamente. Escribimos pruebas para cada una de nuestras características, podemos verificar una secuencia de comandos específica, hacer clic en ciertos enlaces, botones, desplazarnos por ciertas galerías en nuestra interfaz y ver exactamente qué cantidad de registros se registra exactamente con los valores que esperamos, que registramos, para los cuales hicimos Algunas normas. Y luego entraremos en estos valores de referencia.
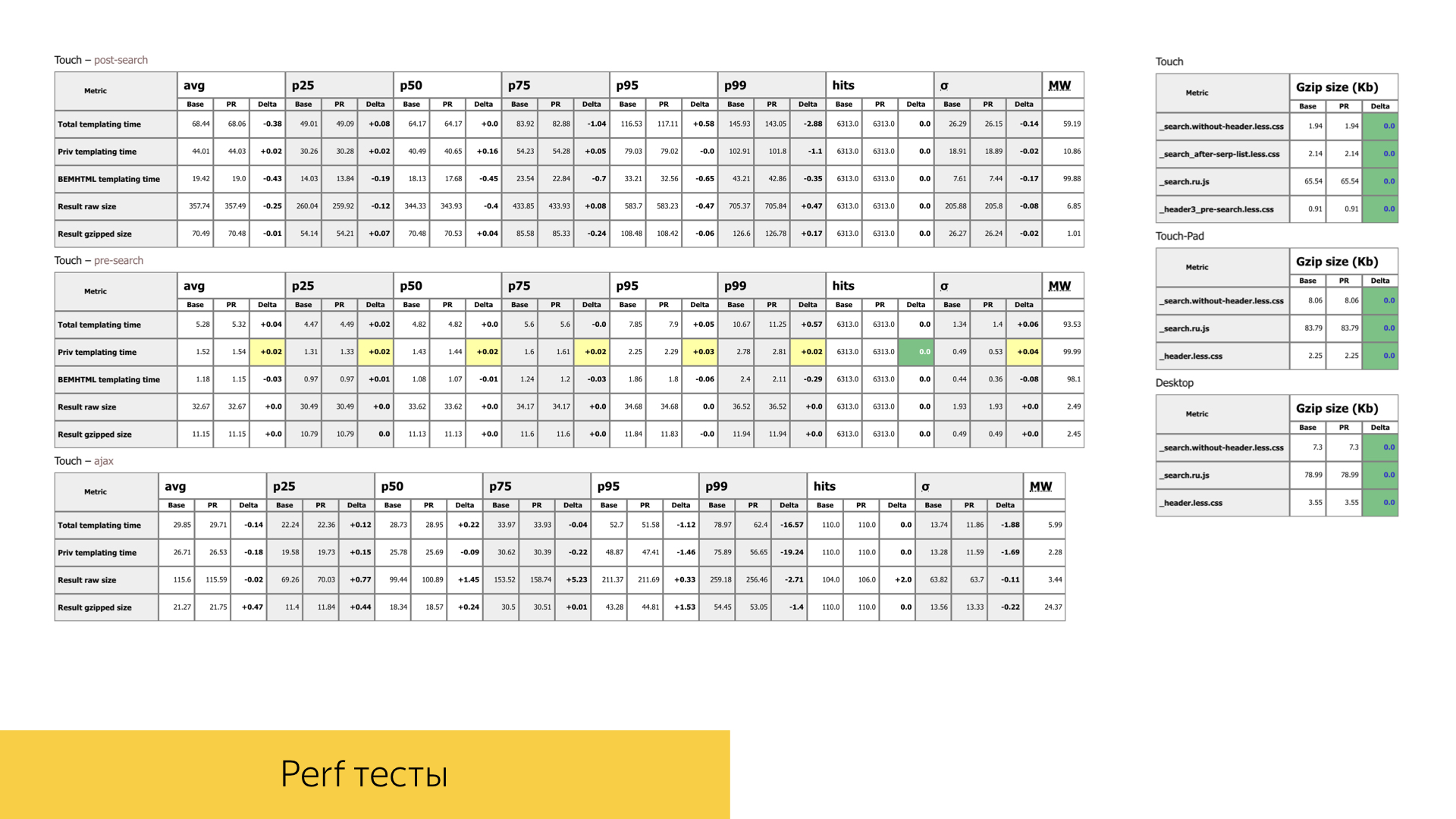
También prestamos mucha atención al rendimiento de nuestras interfaces. En cualquier solicitud de grupo con nueva funcionalidad o refactorización de la funcionalidad existente, prestamos mucha atención a los tiempos, volúmenes y número de llamadas de ciertas funciones. En la diapositiva hay uno de los informes de una solicitud de agrupación completamente aleatoria. Tenemos dos etapas de búsqueda, una es del tipo ajax: primero cargamos el encabezado en la página con la flecha de búsqueda, y cuando todas las fuentes de búsqueda funcionan, aún podemos medir los tiempos de la plantilla y todo el rendimiento al representar la parte principal de la salida.
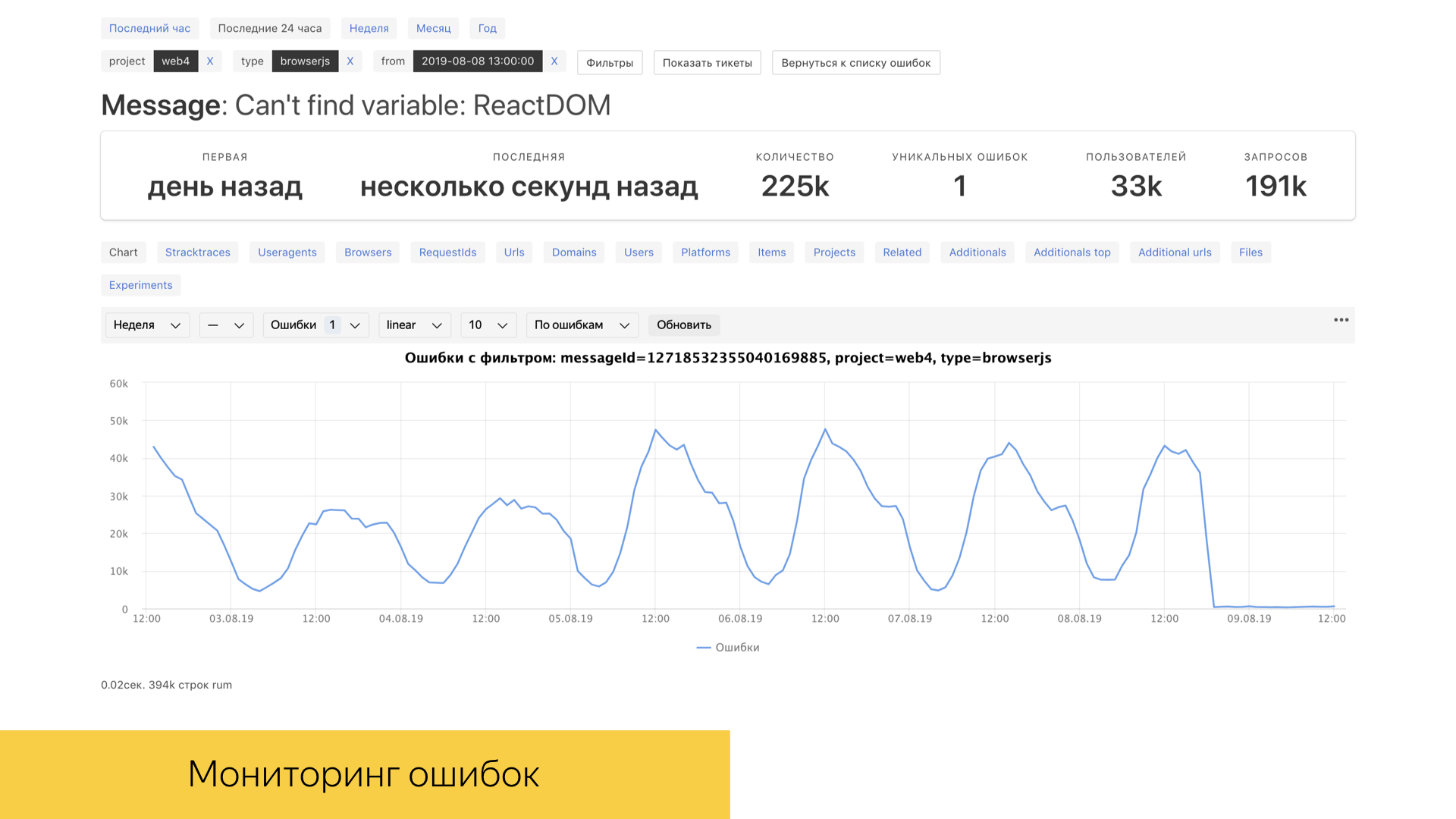
Para nosotros, como, por supuesto, y para cualquier otro tema en TI, los errores en la producción y en entornos especiales son muy importantes. Tenemos una herramienta llamada refuerzo de errores, que le permite ver errores reales en la producción en tiempo real con un marco de tiempo bastante bueno. Bajo el capó, esta herramienta utiliza la base de datos ClickHouse, en la que las solicitudes se procesan con bastante rapidez, y la base de datos en sí está diseñada para el trabajo analítico. La mayoría de las interacciones se implementan específicamente con ClickHouse.
Hablamos de troncos, de sus variedades. Hay muchos de ellos. Para mover experimentos y analizar algo, para tomar decisiones sobre algo, tenemos una gran cantidad de métricas. Estas son algunas convoluciones sobre grandes volúmenes de datos sin procesar.
Métricas
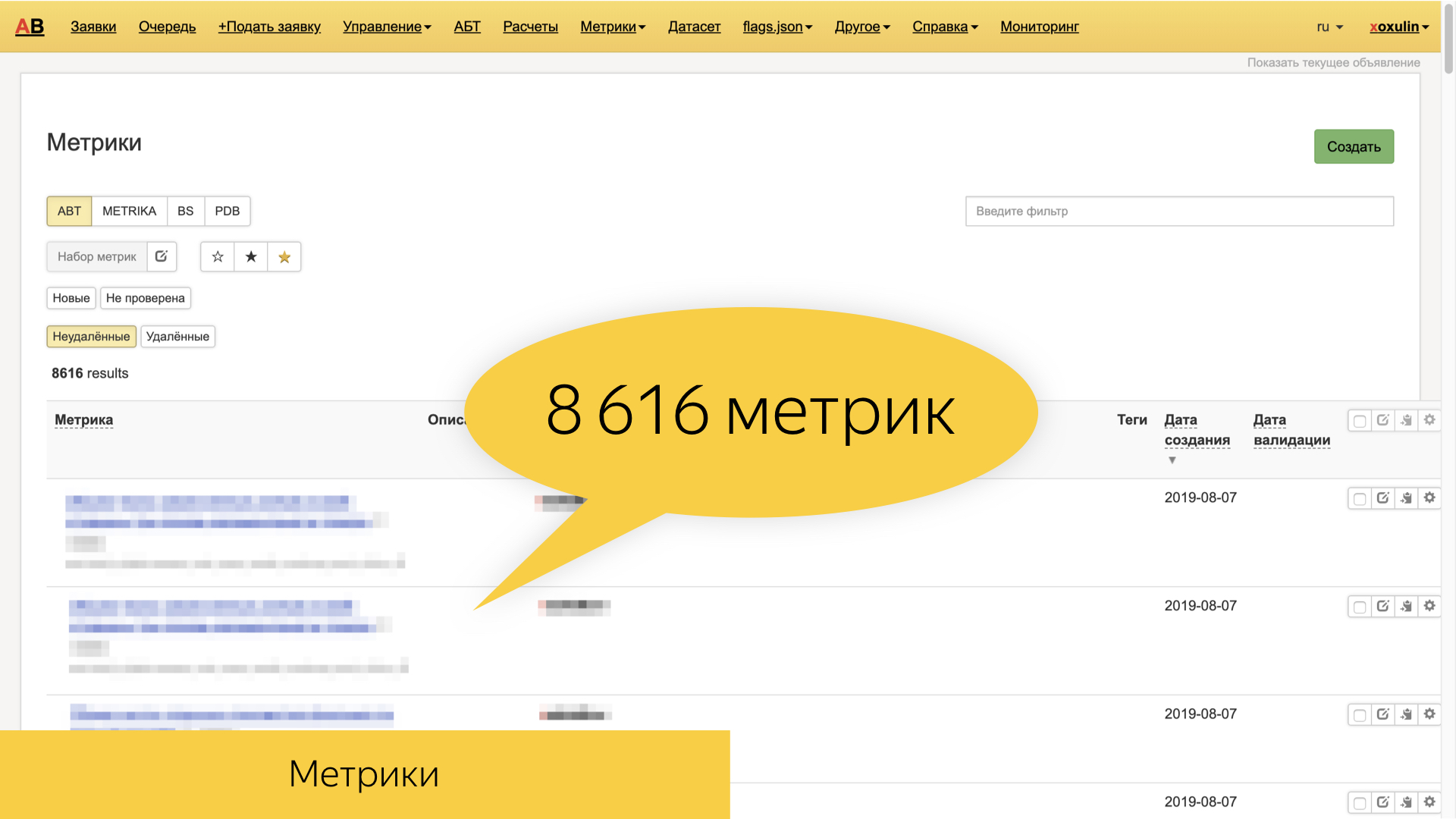
Yandex ahora tiene alrededor de 8.6 mil métricas diferentes que se basan en los mismos registros sin procesar, y otras de nivel superior, como las sesiones de búsqueda y de usuario. Son muy diversos y, a menudo, están precisamente orientados a funciones. Es decir, estas son métricas específicas de un hechicero en particular, un bloque específico, una porción de solicitudes, el tipo de documentos que mostramos.
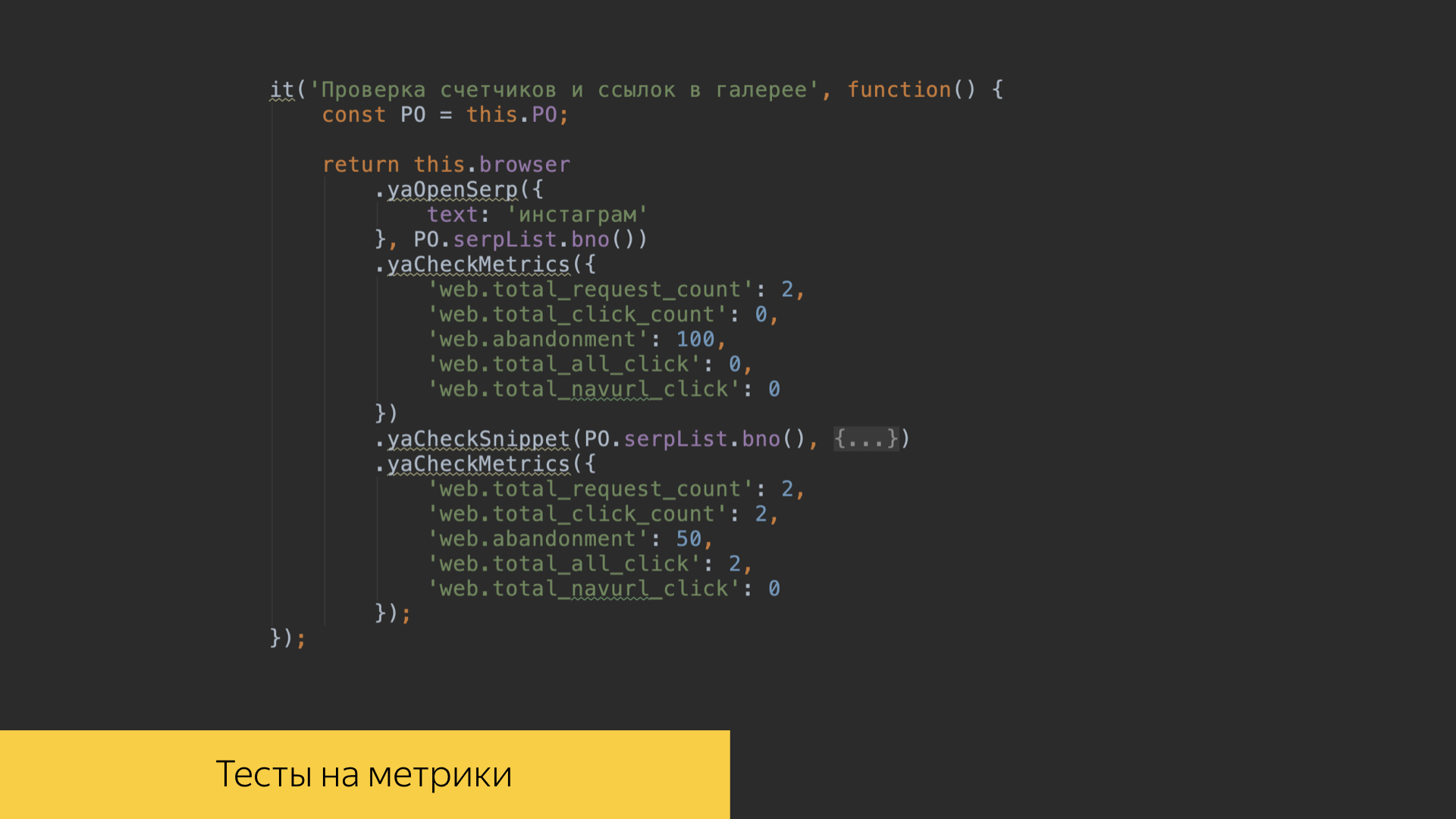
En nuestros escenarios de prueba, es posible verificar el valor de las métricas en nuestras propias interfaces. Cuando perdimos ciertos escenarios, podemos ver los resultados de los cálculos sobre los registros y obtener ciertos valores métricos.
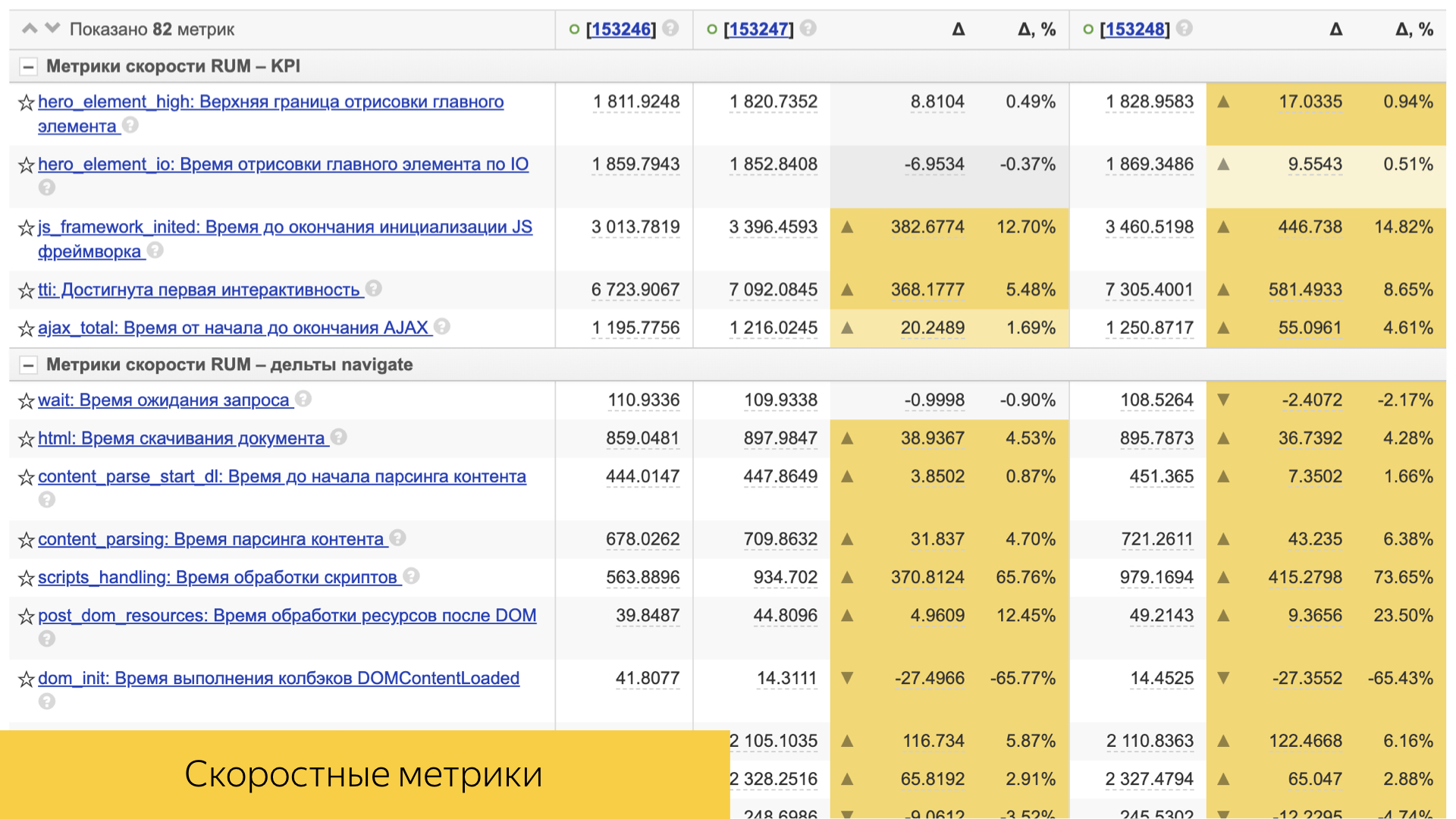
Las métricas de velocidad juegan un papel importante. Todos ellos son lo suficientemente simples organizados. Esto suele ser algún tipo de percentil, o el valor promedio y su desviación y significación estadística.
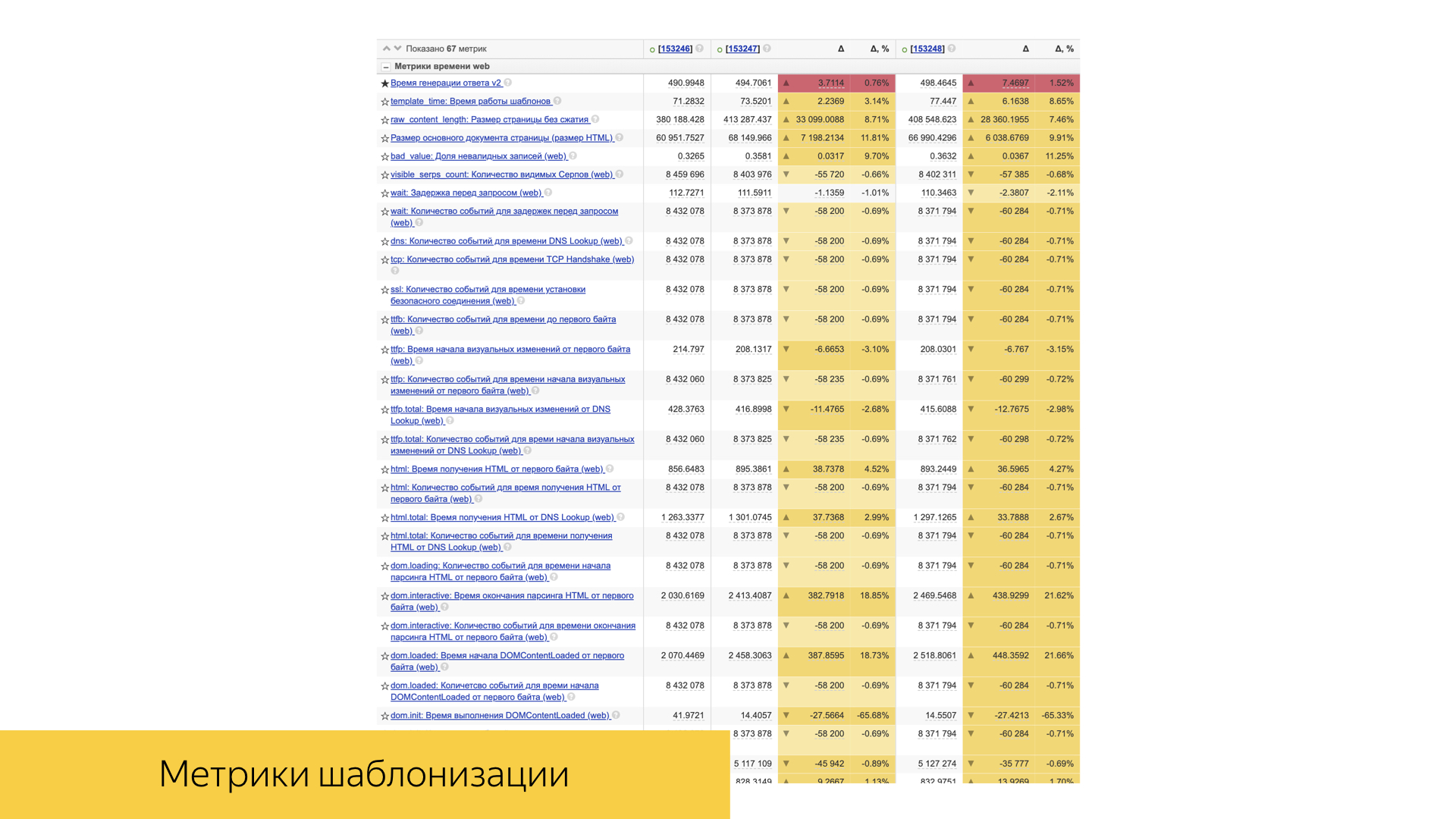
Hay muchos de ellos, tienen en cuenta tanto el tiempo de estandarización como el tiempo de entrega del contenido al dispositivo del usuario.
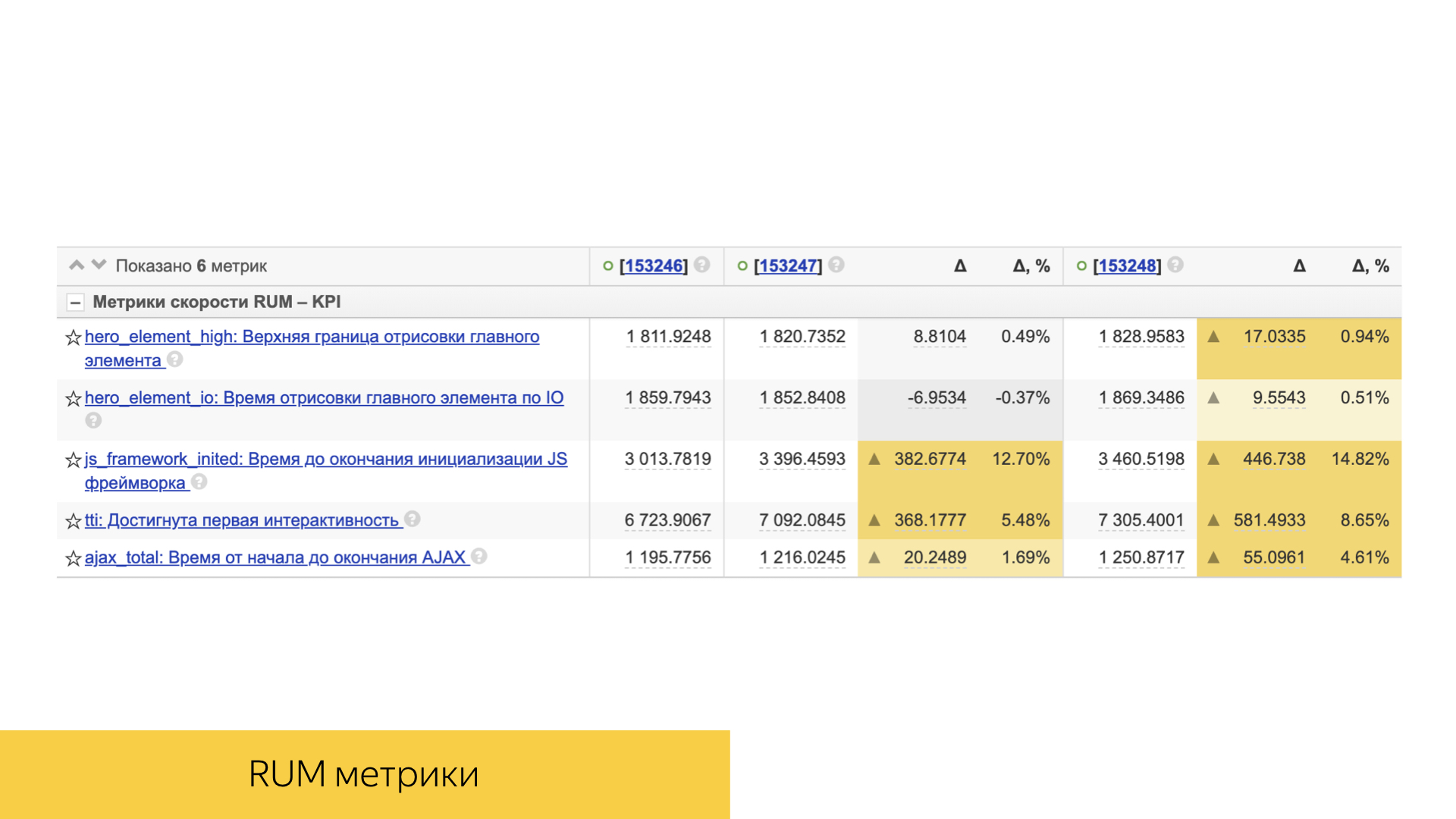
El rendimiento directo del cliente también se tiene en cuenta: tiempo de representación, tiempo de interactividad y otros.
Los experimentos

Entonces, ¿cómo llevamos a cabo experimentos? Por ejemplo, hay dos usuarios que repentinamente decidieron usar la búsqueda de Yandex. Estuvimos de acuerdo el uno con el otro: hoy vamos, por ejemplo, a Starbucks, y lo estamos buscando usando nuestra búsqueda. Sus solicitudes, que caen en la infraestructura de nuestras fuentes de búsqueda, están marcadas con ciertos marcadores. Por marcadores, estos usuarios caen en varias canastas de experimentos. Cada cesta contiene un conjunto específico de banderas que activan experimentos en cada una de las fuentes de búsqueda. Por ejemplo, estos dos usuarios fueron a los resultados de búsqueda y usaron sugerencias de búsqueda. El primero presenta "Starbucks", ve algunos consejos palabra por palabra en forma de palabras. Cuando termina con una búsqueda, ve un bloqueo sobre esta organización, dice: sí, lo encontré, voy allí. Y el segundo usuario descubre una pista de navegación que ya está en la interfaz de búsqueda, cambia rápidamente a la organización y recibe una respuesta más rápida.
Para toda esta variedad de cambios, diferencias en la interfaz, en una cierta funcionalidad, la herramienta BEM es responsable. Esto no es solo un marco, sino una metodología completa para la declaración de componentes visuales, sus modificaciones. Incluso aquí en el fondo están los mismos cromosomas de ADN que parecen mutar a través de Bem. De hecho, bem es Yandex DNA, el ADN de los experimentos en la parte frontal.

Hay varias implementaciones en la metodología. Uno de ellos está en la pila i-bem ya establecida, que está en algún lugar debajo del capó conectado a jQuery. Esto ya es una tecnología bastante madura. En esa pila, podemos resolver muchos problemas. Hoy en día, la tecnología bem-react, que ya está implementada en el marco React y el lenguaje TypeScript, está ganando un gran impulso y desarrollo. Todas estas herramientas le permiten construir experimentos y predicar la idea principal: la capacidad de declarar componentes visuales y sus modificaciones. Tenemos un nivel completamente separado en el repositorio con declaraciones de esos mismos experimentos. Pero alrededor de 2015, se dieron cuenta de que no era rentable difundir nuestras banderas experimentales en todo el código de front-end. El hecho es que las unidades de experimentos alcanzan una producción real, y todo lo que no se utiliza es muy difícil de eliminar del código más adelante. Por lo tanto, los desalojamos a un nivel separado de definición. Y aquí nuevamente gracias a la metodología bem, que nos dio la oportunidad de usar niveles de redefinición. Declaramos nuestros experimentos sobre ellos.

Este es uno de los informes de experimentos. Dos columnas: control y experimento. Ante ti ni siquiera está todo lo que está en el informe. ¿Por qué es tan largo? En primer lugar, viste cuántas métricas tenemos: 8,6 mil.

Pero el papel principal solo lo juegan las métricas que difieren. Y podemos realizar nuestros experimentos al mismo tiempo, es decir, en un usuario podemos tener simultáneamente alrededor de 20 experimentos. No entran en conflicto entre sí de ninguna manera, y en todos nuestros experimentos solo se manchan sus métricas puramente de producto, sin afectarse entre sí. Ahora hay alrededor de 800 experimentos en producción: no solo motores de búsqueda, sino también de tantos servicios. La herramienta se llama AB, lo cual no es sorprendente. Los servicios comienzan experimentos en él, declaran ciertas muestras y luego observan las diferencias entre las métricas, que después de un período comienzan a diferir en el experimento y el control.
Roles relacionados del desarrollador
Como consecuencia de esta diversidad en el trabajo de los desarrolladores front-end, incluso hay roles entre ellos. Hay expertos en experimentos, y para esto oficialmente damos logros en el marco de la red interna de Yandex, la gente realmente pasa los exámenes. Analizan experimentos, validan sus resultados sobre expertos y obtienen un pasaporte que dice: "Soy analista, puedo analizar experimentos". Y, en general, todo el trabajo con experimentos, con nuestras métricas, se centra principalmente en mejorar el producto en sí. Soy uno de los representantes, estoy muy motivado para desarrollar el producto, y no solo el código y no la tecnología. Y realmente me motiva cuando vengo a un equipo y hago un producto.

¿Cuál es el resultado final? Tenemos una gran cantidad de registros escritos diariamente en nuestros sistemas de almacenamiento. Calculamos una gran cantidad de métricas, realizamos experimentos con ellas. Infraestructura muy grande. La herramienta moderna superior que le permite implementar una gran cantidad de herramientas es el paquete bem-react. Prestamos mucha atención a los indicadores de velocidad y calidad, estabilidad del producto. Y, en general, estamos desarrollando en nuestros desarrolladores más y más roles nuevos relacionados con la especialidad principal: la interfaz. Lo tengo todo Gracias por su atencion