Aunque las redes neuronales comenzaron a usarse para la síntesis del habla no hace mucho tiempo ( por ejemplo ), ya han logrado superar los enfoques clásicos y cada año experimentan tareas cada vez más nuevas.
Por ejemplo, hace un par de meses hubo una implementación de síntesis de voz con clonación de voz Real-Time-Voice-Cloning . Intentemos averiguar en qué consiste y realizar nuestro modelo de fonema multilingüe (ruso-inglés).
Edificio
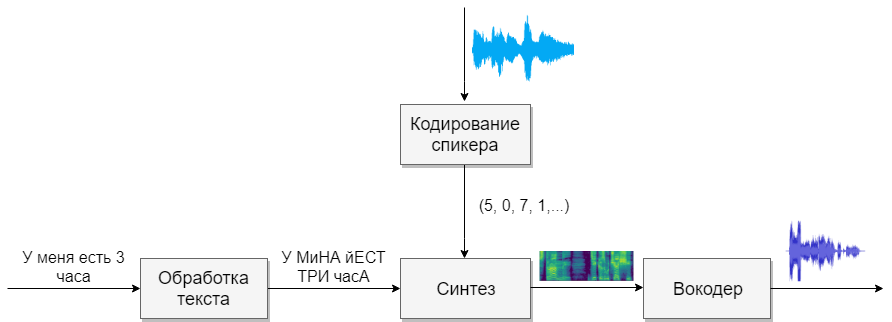
Nuestro modelo consistirá en cuatro redes neuronales. El primero convertirá el texto en fonemas (g2p), el segundo convertirá el discurso que queremos clonar en un vector de signos (números). El tercero sintetizará los espectrogramas Mel basados en las salidas de los dos primeros. Y finalmente, el cuarto recibirá sonido de espectrogramas.
Conjuntos de datos
Este modelo necesita mucho discurso. A continuación se presentan las bases que ayudarán con esto.
Procesamiento de textos
La primera tarea será el procesamiento de texto. Imagine el texto en la forma en que se expresará más. Representaremos números en palabras y abriremos abreviaturas. Lea más en el artículo sobre síntesis . Esta es una tarea difícil, así que supongamos que ya hemos procesado el texto (se ha procesado en las bases de datos anteriores).
La siguiente pregunta que debe hacerse es si se debe usar la grabación de grafema o fonema. Para una voz monofónica y monolingüe, también es adecuado un modelo de letra. Si desea trabajar con un modelo multilingüe de varias voces, le aconsejo que use la transcripción (Google también ).
G2p
Para el idioma ruso, hay una implementación llamada russian_g2p . Se basa en las reglas del idioma ruso y se adapta bien a la tarea, pero tiene desventajas. No todas las palabras subrayan, y tampoco es adecuado para un modelo multilingüe. Por lo tanto, tome el diccionario creado para ella, agregue el diccionario para el idioma inglés y alimente la red neuronal (por ejemplo, 1 , 2 )
Antes de entrenar la red, vale la pena considerar qué sonidos de diferentes idiomas suenan similares, y puede seleccionar un carácter para ellos, y para lo cual es imposible. Cuantos más sonidos haya, más difícil será aprender el modelo, y si hay muy pocos, el modelo tendrá un acento. Recuerde enfatizar caracteres individuales con vocales estresadas. Para el idioma inglés, el estrés secundario juega un papel pequeño, y no lo distinguiría.
Codificación de altavoces
La red es similar a la tarea de identificar a un usuario por voz. En la salida, diferentes usuarios obtienen diferentes vectores con números. Sugiero usar la implementación de CorentinJ, que se basa en el artículo . El modelo es un LSTM de tres capas con 768 nodos, seguido de una capa totalmente conectada de 256 neuronas, lo que da un vector de 256 números.
La experiencia ha demostrado que una red capacitada en inglés habla bien con ruso. Esto simplifica enormemente la vida, ya que la capacitación requiere muchos datos. Recomiendo tomar un modelo ya entrenado y volver a entrenar en inglés de VoxCeleb y LibriSpeech, así como todos los discursos en ruso que encuentre. El codificador no necesita una anotación de texto de fragmentos de voz.
Entrenamiento
- Ejecute
python encoder_preprocess.py <datasets_root> para procesar los datos - Ejecute "visdom" en una terminal separada.
- Ejecute
python encoder_train.py my_run <datasets_root> para entrenar el codificador
Síntesis
Pasemos a la síntesis. Los modelos que conozco no obtienen sonido directamente del texto, porque es difícil (demasiados datos). Primero, el texto produce sonido en forma espectral, y solo entonces la cuarta red se traducirá en una voz familiar. Por lo tanto, primero entendemos cómo la forma espectral está asociada con la voz. Es más fácil descubrir el problema inverso de cómo obtener un espectrograma del sonido.
El sonido se divide en segmentos de 25 ms en incrementos de 10 ms (el valor predeterminado en la mayoría de los modelos). Luego, usando la transformada de Fourier para cada pieza, se calcula el espectro (oscilaciones armónicas, cuya suma da la señal original) y se presenta en forma de gráfico, donde la franja vertical es el espectro de un segmento (en frecuencia), y en horizontal: una secuencia de segmentos (en el tiempo). Este gráfico se llama espectrograma. Si la frecuencia se codifica de forma no lineal (las frecuencias más bajas son mejores que las superiores), entonces la escala vertical cambiará (necesaria para reducir los datos), entonces este gráfico se llama espectrograma Mel. Así es como funciona la audición humana, que escuchamos una ligera desviación en las frecuencias más bajas mejor que en las más altas, por lo tanto, la calidad del sonido no sufrirá
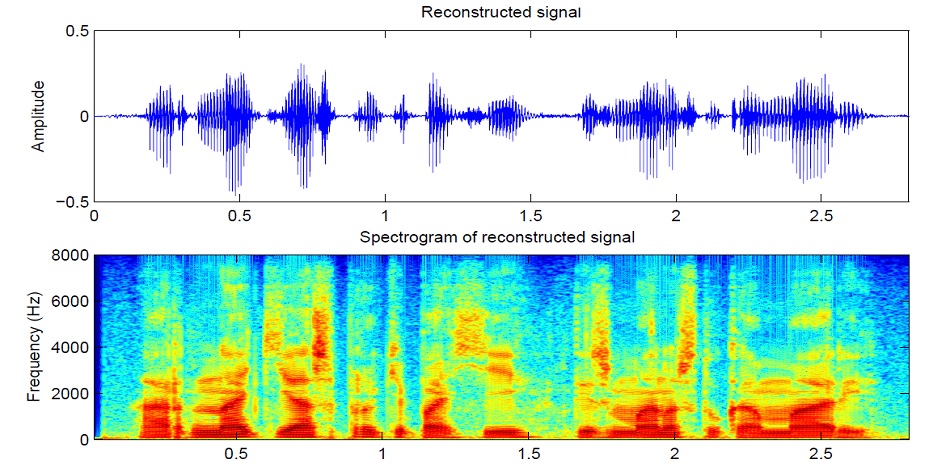
Hay varias implementaciones de síntesis de espectrograma buenas, como Tacotron 2 y Deepvoice 3 . Cada uno de estos modelos tiene sus propias implementaciones, por ejemplo 1 , 2 , 3 , 4 . Usaremos (como CorentinJ) el modelo Tacotron de Rayhane-mamah.
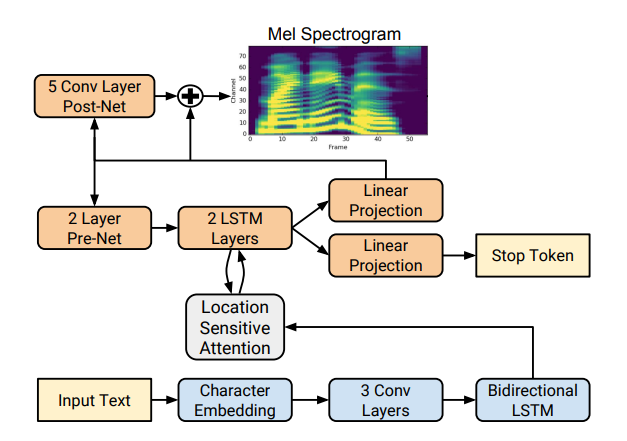
Tacotron se basa en la red seq2seq con un mecanismo de atención. Lee los detalles en el artículo .
Entrenamiento
No olvide editar utils / symbols.py si sintetiza no solo el habla inglesa, hparams.p, sino también preprocess.py.
La síntesis requiere una gran cantidad de sonido limpio y bien marcado de diferentes altavoces. Aquí un idioma extranjero no ayudará.
- Ejecute
python synthesizer_preprocess_audio.py <datasets_root> para crear sonido procesado y espectrogramas - Ejecute
python synthesizer_preprocess_embeds.py <datasets_root> para codificar el sonido (obtenga los signos de una voz) - Ejecute
python synthesizer_train.py my_run <datasets_root> para entrenar el sintetizador
Vocoder
Ahora solo queda convertir los espectrogramas en sonido. Para esto, la última red es el vocoder. Surge la pregunta, si los espectrogramas se obtienen del sonido usando la transformada de Fourier, ¿es posible obtener sonido nuevamente usando la transformación inversa? La respuesta es sí y no. Las oscilaciones armónicas que componen la señal original contienen amplitud y fase, y nuestros espectrogramas contienen información solo sobre la amplitud (en aras de reducir los parámetros y trabajar con espectrogramas), por lo que si hacemos la transformación inversa de Fourier, obtendremos un mal sonido.
Para resolver este problema, inventaron un algoritmo rápido de Griffin-Lim. Él hace la transformada inversa de Fourier del espectrograma, obteniendo un sonido "malo". Luego realiza una conversión directa de este sonido y recibe un espectro que ya contiene una pequeña información sobre la fase, y la amplitud no cambia en el proceso. Luego, la transformación inversa se toma nuevamente y se obtiene un sonido más limpio. Desafortunadamente, la calidad de la voz generada por tal algoritmo deja mucho que desear.
Fue reemplazado por vocoders neuronales como WaveNet , WaveRNN , WaveGlow y otros. CorentinJ usó el modelo WaveRNN de fatchord

Para el preprocesamiento de datos, se utilizan dos enfoques. Obtenga espectrogramas del sonido (usando la transformación de Fourier) o del texto (usando el modelo de síntesis). Google recomienda un segundo enfoque.
Entrenamiento
- Ejecute
python vocoder_preprocess.py <datasets_root> para sintetizar espectrogramas - Ejecute
python vocoder_train.py <datasets_root> para vocoder
Total
Tenemos un modelo de síntesis de voz multilingüe que puede clonar una voz.
Ejecute toolbox: python demo_toolbox.py -d <datasets_root>
Se pueden escuchar ejemplos aquí
Consejos y conclusiones
- Necesita muchos datos (> 1000 votos,> 1000 horas)
- La velocidad de operación es comparable con el tiempo real solo en la síntesis de al menos 4 oraciones
- Para el codificador, use el modelo pre-entrenado para el idioma inglés, ligeramente reentrenamiento. Ella esta bien
- Un sintetizador entrenado en datos "limpios" funciona mejor, pero clona peor que uno que entrenó en un volumen mayor, pero datos sucios
- El modelo funciona bien solo con los datos sobre los que estudié
Puede sintetizar su voz en línea usando colab , o ver mi implementación en github y descargar mis pesos .