Hola a todos, alguna información "de debajo del capó" es la fecha del taller de ingeniería de Alfastrakhovaniya, que emociona nuestras mentes técnicas.

Apache Spark es una herramienta maravillosa que le permite procesar rápida y fácilmente grandes cantidades de datos en recursos informáticos bastante modestos (me refiero al procesamiento de clúster).
Tradicionalmente, el jupyter notebook se usa en el procesamiento de datos ad hoc. En combinación con Spark, esto nos permite manipular marcos de datos de larga duración (Spark se ocupa de la asignación de recursos, los marcos de fechas viven en algún lugar del clúster, su vida útil está limitada por la vida útil del contexto de Spark).
Después de transferir el procesamiento de datos a Apache Airflow, la vida útil de los marcos se reduce considerablemente: el contexto de Spark "vive" dentro de la misma declaración de Airflow. Cómo evitar esto, por qué moverse y qué tiene que ver Livy con eso, lea debajo del corte.
Veamos un ejemplo muy, muy simple: supongamos que necesitamos desnormalizar datos en una tabla grande y guardar el resultado en otra tabla para su posterior procesamiento (un elemento típico de la tubería de procesamiento de datos).
¿Cómo haríamos esto?
- datos cargados en el marco de datos (selección de una tabla grande y directorios)
- miró con "ojos" el resultado (¿funcionó correctamente?)
- marco de datos guardado en la tabla de Hive (por ejemplo)
Según los resultados del análisis, es posible que debamos insertar en el segundo paso un procesamiento específico (reemplazo del diccionario u otra cosa). En términos de lógica, tenemos tres pasos.
- paso 1: descargar
- paso 2: procesamiento
- Paso 3: guardar
En jupyter notebook, así es como lo hacemos: podemos procesar los datos descargados durante un tiempo arbitrariamente largo, lo que le da a Spark el control de los recursos.
Es lógico esperar que dicha partición se pueda transferir a Airflow. Es decir, tener un gráfico de este tipo

Desafortunadamente, esto no es posible cuando se usa la combinación Airflow + Spark: cada declaración de Airflow se ejecuta en su propio intérprete de Python, por lo tanto, entre otras cosas, cada declaración debe de alguna manera "persistir" en los resultados de sus actividades. Por lo tanto, nuestro procesamiento se "comprime" en un solo paso: "desnormalizar datos".
¿Cómo se puede devolver la flexibilidad del portátil jupyter a Airflow? Está claro que el ejemplo anterior "no vale la pena" (tal vez, por el contrario, resulta un buen paso de procesamiento comprensible). Pero aún así, ¿cómo hacer que las declaraciones de Airflow se ejecuten en el mismo contexto de Spark en un espacio de trama de datos común?
Bienvenida Livy
Otro producto del ecosistema Hadoop viene al rescate: Apache Livy.
No trataré de describir aquí qué tipo de "bestia" es. Si es muy breve y en blanco y negro, Livy le permite "inyectar" código de Python en un programa que ejecuta el controlador:
- primero creamos una sesión de Livy
- después de eso, tenemos la capacidad de ejecutar código arbitrario de Python en esta sesión (muy similar a la ideología jupyter / ipython)
Y para todo esto hay una API REST.
Volviendo a nuestra tarea simple: con Livy podemos guardar la lógica original de nuestra desnormalización
- en el primer paso (la primera declaración de nuestro gráfico) cargaremos y ejecutaremos el código de carga de datos en el marco de datos
- en el segundo paso (segunda instrucción): ejecute el código para el procesamiento adicional necesario de este marco de datos
- en el tercer paso: el código para guardar el marco de datos en la tabla
Lo que en términos de flujo de aire podría verse así:
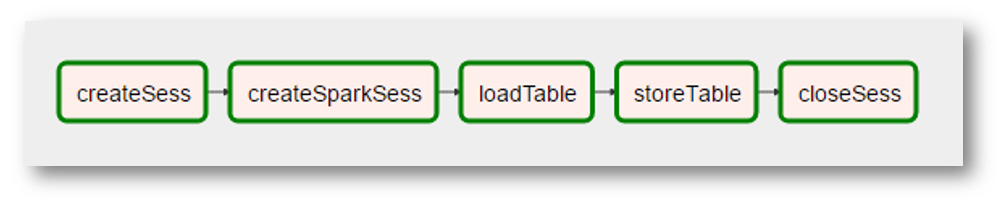
(dado que la imagen es una captura de pantalla muy real, se agregaron "realidades" adicionales: la creación del contexto de Spark se convirtió en una operación separada con un nombre extraño, el "procesamiento" de los datos desapareció porque no era necesario, etc.)
Para resumir, obtenemos
- declaración de flujo de aire universal que ejecuta código python en una sesión de Livy
- la capacidad de "organizar" el código de Python en gráficos bastante complejos (flujo de aire para eso)
- la capacidad de abordar optimizaciones de nivel superior, por ejemplo, en qué orden necesitamos realizar nuestras transformaciones para que Spark pueda mantener los datos generales en la memoria del clúster durante el mayor tiempo posible
Una canalización típica para preparar datos para modelar contiene alrededor de 25 consultas en 10 tablas, es obvio que algunas tablas se usan con más frecuencia que otras (los mismos "datos generales") y hay algo que optimizar.
Que sigue
La capacidad técnica ha sido probada, pensamos más allá: cómo traducir más tecnológicamente nuestras transformaciones en este paradigma. Y cómo abordar la optimización mencionada anteriormente. Todavía estamos al comienzo de esta parte de nuestro viaje; cuando hay algo interesante, definitivamente lo compartiremos.