En este artículo, quiero considerar un enfoque para dividir las tareas en subtareas al usar Clean Architecture.
El equipo de desarrollo móvil de NullGravity encontró el problema de descomposición y, a continuación, cómo lo resolvimos y qué sucedió al final.

Antecedentes
Era el otoño de 2018, estábamos desarrollando la próxima aplicación para un operador de telecomunicaciones. Pero esta vez fue diferente. Los términos eran bastante estrictos y vinculados a la campaña de marketing del cliente. El equipo de Android ha crecido de 3 a 6-7 desarrolladores. Se realizaron varias tareas en el sprint y la pregunta era cómo descomponerlas de manera efectiva.
¿Qué queremos decir cuando hablamos con eficacia?
- El número máximo de tareas paralelas.
Esto hace posible ocupar todos los recursos disponibles. - Reducción del tamaño de las solicitudes de fusión.
No se verán durante el programa, y aún puede detectar posibles problemas en la etapa de revisión del código. - Reduce el número de conflictos de fusión.
Las tareas fluirán más rápido y no hay necesidad de cambiar el desarrollador a la resolución de conflictos. - Una oportunidad para recopilar estadísticas de gastos de tiempo.
- Automatizar la creación de tareas en Jira.
¿Cómo resolvimos el problema?
Dividimos todas las subtareas en los siguientes tipos:
- Datos
- Dominio
- Vacio
- UI
- Artículo
- Personalizado
- Integración
Los datos y el dominio corresponden a capas en Clean Architecture.
Vacío, IU, Elemento y Personalizado se refieren a la capa de presentación.
La integración se aplica tanto al dominio como a las capas de presentación.
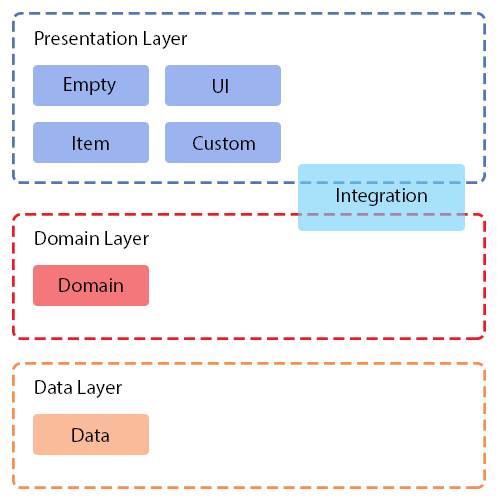 Figura 1. Ubicación de las tareas relativas a las capas de Arquitectura limpia
Figura 1. Ubicación de las tareas relativas a las capas de Arquitectura limpiaVeamos cada tipo individualmente.
Datos
Descripción de DTO, API, trabajo con base de datos, fuente de datos, etc.
Dominio
Interfaz de repositorio, descripción de modelos de negocio, interactores.
También se implementa la interfaz del repositorio en la capa de datos.
Tal separación algo ilógica, a primera vista, hizo posible aislar las tareas de los tipos de datos y dominio tanto como sea posible.
UI
Crear un diseño de pantalla básico y estados adicionales, si los hay.
Artículo
Si la pantalla es una lista de elementos, entonces para cada tipo necesita crear un modelo - Elemento. Para asignar el elemento al diseño, necesita AdapterDelegate. Usamos el concepto de
adaptador delegado , pero con algunas
modificaciones .
A continuación, cree un ejemplo de trabajo con un elemento de lista en PresentationModel.
Vacio
Las clases base necesarias para tareas como ui o item: PresentationModel, Framgent, layout, DI module, AdapterDelagate factory. Interfaces e implementaciones vinculantes. Crea un punto de entrada en la pantalla.
El resultado de la tarea es la pantalla de la aplicación. Contiene la barra de herramientas, RecyclerView, ProgressView, etc. es decir, elementos de interfaz comunes, cuya adición podría ser duplicada por diferentes desarrolladores y conduciría a conflictos de fusión inevitables.
Personalizado
Implementación de un componente de interfaz de usuario no estándar.
Se necesita un tipo adicional para separar el desarrollo de un nuevo componente de una tarea de tipo UI.
Integración
Integración de dominio y capas de presentación.
Como regla general, esta es una de las tareas que más tiempo consume. Es necesario reducir las dos capas y refinar los puntos que podrían haberse perdido en las etapas anteriores.
Orden de tareas
Se pueden iniciar tareas como datos, vacías y personalizadas inmediatamente después de que comience el sprint. Son independientes de otras tareas.
La tarea de dominio se ejecuta después de la tarea de datos.
Las tareas de interfaz de usuario y elemento después de la tarea vacía.
La tarea de integración es la última en completarse, ya que requiere la finalización de todas las tareas anteriores.
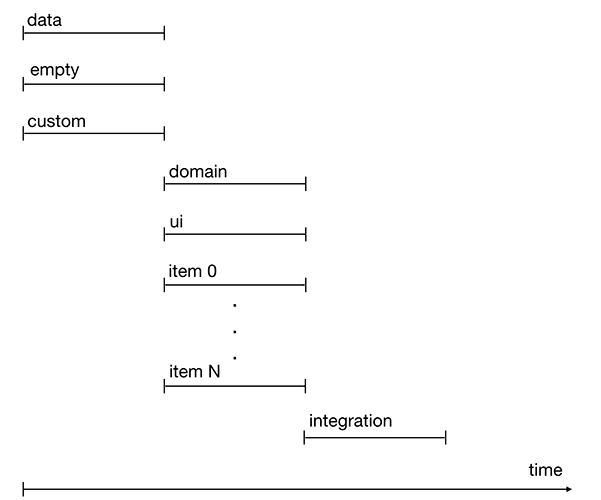 Figura 2. Ejecución de tareas de línea de tiempo
Figura 2. Ejecución de tareas de línea de tiempoA pesar de que algunas tareas están bloqueadas por otras tareas, pueden iniciarse al mismo tiempo o con un ligero retraso. Dichas tareas incluyen dominio, interfaz de usuario y elemento. Por lo tanto, el proceso de desarrollo se acelera.
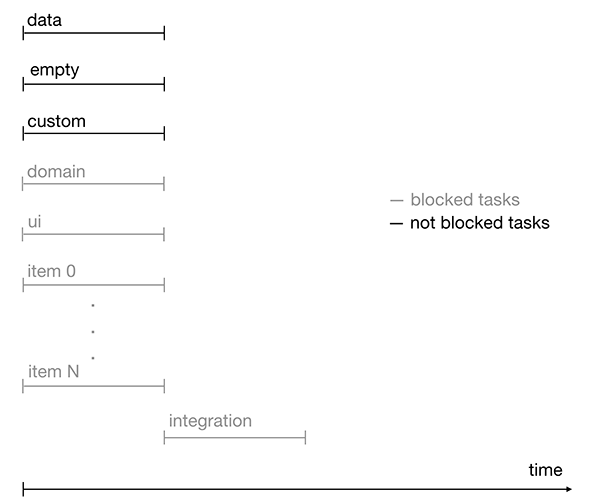 Figura 3. Cronología de la realización de tareas con bloqueos
Figura 3. Cronología de la realización de tareas con bloqueosPara cada funcionalidad específica, el conjunto de tareas puede variar.
Puede haber un número diferente de tareas vacías, ui, ítem e integración, y algunos tipos pueden simplemente estar ausentes.
Automatización de procesos y recopilación de estadísticas.
Para recopilar estadísticas al crear una tarea, se le asigna una etiqueta. Este mecanismo en el futuro le permitirá analizar el tiempo dedicado a cada tipo y formar los costos promedio. La información recopilada se puede aplicar al evaluar un nuevo proyecto.
Para la automatización, también logramos encontrar una solución. Como las tareas son típicas, su descripción en Jira debería ser diferente. Desarrollamos plantillas para resumen y descripción. Al principio era solo un archivo json, el analizador Python de este archivo y la API REST de Jira estaba conectada para generar tareas.
De esta forma, el guión duró casi un año. Hoy se ha convertido en una aplicación de escritorio completa escrita en Python usando la arquitectura PyQt y MVP.
Tal vez MVP estaba sobrecargado, pero cuando la primera versión en Tkinter bloqueó la versión 10.14.6 de MacOS y no todos los equipos pudieron usar la aplicación, reescribimos fácilmente la vista para PyQt en medio día y funcionó. Una vez más, estábamos convencidos de que el uso de enfoques arquitectónicos, incluso para tareas tan simples, tiene sus ventajas. En la Figura 4 se muestra una captura de pantalla de JiraSubTaskCreator.
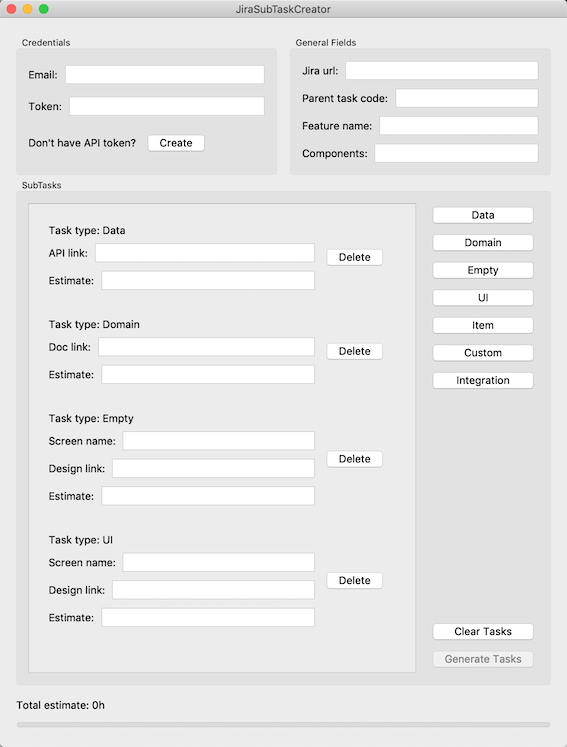 Figura 4. La pantalla principal de JiraSubTaskCreator
Figura 4. La pantalla principal de JiraSubTaskCreatorConclusiones
- Hemos desarrollado un enfoque para la descomposición de tareas en subtareas mínimamente dependientes entre sí;
- Plantillas generadas para describir tareas;
- Recibimos pequeñas solicitudes de fusión, lo que hace posible revisar y cambiar cuidadosamente el código de forma aislada.
- Se redujo el número de conflictos con las solicitudes de fusión;
- Tuvimos la oportunidad de evaluar y analizar con mayor precisión el tiempo dedicado a cada tipo de tarea;
- Parte automatizada del trabajo de rutina.