Comparación de varias herramientas (RabbitMQ, Crossbar.io, Nats.io, Nginx, etc.) para organizar RPC entre microservicios.
Prueba de procesador múltiple Artículo actualizado 2019-12-15Resumen La implementación de llamadas RPC síncronas a través del sistema MQ clásico no es efectiva: brinda un rendimiento reducido y efectos secundarios que deben ser enrollados manualmente (o con herramientas adicionales).
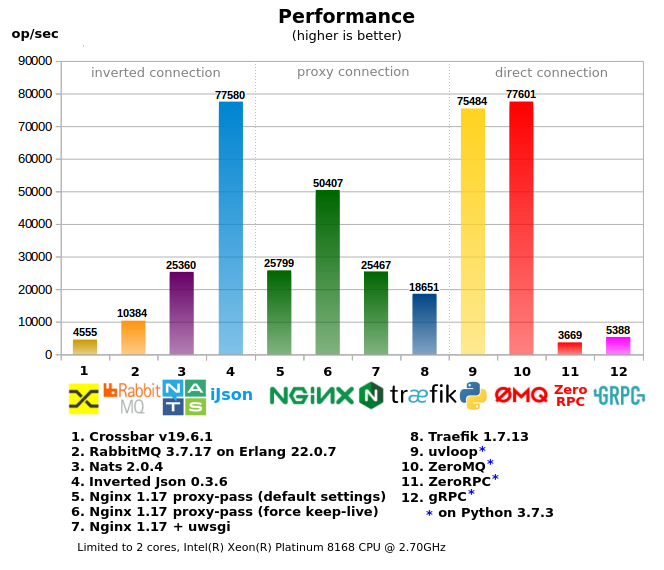
Inverted Json es un servidor de tareas liviano que le permite realizar llamadas RPC síncronas "honestas" (el cliente y el servidor se conectan a través de Inverted Json para enviar información), lo que garantiza un alto rendimiento (7 veces más rápido que RabbitMQ), y la comunicación se realiza a través de http , que le permite usar cualquier herramienta http, incluso curl desde la consola.
1. Pruebas
Todas las herramientas se dividen en 3 grupos:
- "Conexión directa" : cuando el cliente se dirige directamente al trabajador, en proyectos con una gran cantidad de trabajadores / servicios es el más difícil de configurar, requiere un "cliente inteligente", es decir al llamar, el cliente debe tener información sobre cómo y dónde enviar la solicitud (o se necesita un proxy local adicional), como regla, produce la menor carga en la red.
- "Conexión de proxy" : una variante con un único punto de entrada, un cliente simple, pero al mismo tiempo las dificultades siguen siendo del lado de los trabajadores / seriales: reenvío y asignación de puertos, registro de direcciones para servidores proxy, configuraciones de firewall más complicadas, herramientas adicionales a menudo se utilizan para administrar toda esta granja .
- “Conexión invertida” : un único punto de entrada tanto para clientes como para trabajadores (puede considerarse como un ESB), la configuración de red más simple.
- Uso de memoria y procesador tomado de `estadísticas del acoplador`
- En la prueba de "2 núcleos", el servidor y los clientes con interruptores se dividen en diferentes núcleos para reducir la influencia mutua, por lo tanto, el servidor está limitado a 2 núcleos a través del conjunto de tareas (prueba de múltiples núcleos sin restricciones)
Algunas reflexiones sobre el punto de referencia a continuación.
2. MQ o RPC
Aunque estos 2 métodos de comunicación son diferentes, a veces se usa el primero en lugar del segundo y viceversa.
Si intenta delinear los límites, cuándo usar qué, puede obtener algo como esto:
- RPC (llamada a procedimiento sincrónico): cuando el cliente requiere una respuesta inmediata (en un corto período de tiempo), cuando el trabajador necesita responder mientras el cliente espera una respuesta, y si el cliente se ha ido (por tiempo de espera), esta respuesta ya no es necesaria (es por eso que no necesita guardar " solicitud ", como suele hacerse en los sistemas MQ).
Por ejemplo, cuando realiza una consulta en la base de datos, hace RPC, no querrá usar MQ para esto. - MQ (llamada a procedimiento asincrónico): cuando no se necesita la respuesta (inmediatamente), cuando solo necesita completar algún tipo de tarea al final o simplemente transferir datos.
Por ejemplo, para enviar cartas puede enviar una tarea a través de MQ
3. RPC sobre RabbitMQ
RabbitMQ a menudo se usa para organizar RPC, pero al igual que los sistemas MQ similares, crea una sobrecarga adicional, por lo que su uso no es muy productivo.
Si usa la "cola" para RPC, entonces necesita limpiar los canales, porque Si el trabajador se ha caído por un tiempo, luego de reiniciarlo puede obtener un montón de tareas irrelevantes, porque los clientes enviaron solicitudes todo este tiempo y, además, esperaron en vano una respuesta. El trabajador no estaba activo. En total, el trabajador recibirá la tarea incluso si el cliente se fue antes, lo mismo con el cliente, si el canal del cliente no se cuenta, entonces puede estar obstruido con las respuestas no recibidas del trabajador, aunque en RabbitMQ es posible cerrar el canal del cliente, pero al mismo tiempo el rendimiento se reducirá drásticamente.
También debe hacer un trabajador porcino para saber si está vivo.
Además, los recursos se gastan en trabajar con canales, cuando en los sistemas RPC los datos simplemente se envían al trabajador y viceversa.
4. Json invertido
Hay muchos sistemas MQ diferentes, pero no muchos servidores Job (RPC) como Gearman / Crossbar.io son opciones muy pequeñas, por lo que los desarrolladores a menudo toman sistemas MQ para RPC.
Por lo tanto, se creó
Inverted JSON (iJson): un servidor proxy con una interfaz http donde los clientes y los trabajadores se conectan como un cliente de red: [cliente] -> [Inverted Json] <- [trabajador], escrito en C / C ++, utiliza epoll, máquinas de estado para enrutamiento, json streaming parser, cortes en lugar de cadenas *, etc. formas para un mejor rendimiento.
Ventajas de JSON invertido sobre RabbitMQ:- No es necesario limpiar los canales de clientes y trabajadores de los mensajes no recibidos
- No es necesario hacer ping al trabajador, el cliente recibirá un error inmediatamente si el trabajador se desconecta (con una conexión de mantenimiento)
- API más fácil: solo una solicitud http (como regla, ya es compatible con todos los idiomas y marcos)
- Funciona más rápido y consume menos memoria.
- Una forma más fácil de enviar comandos a un trabajador específico (por ejemplo, si hay varios trabajadores en la cola, pero necesita trabajar con uno específico)
Otra información de Json invertida- La capacidad de transferir datos binarios (no solo json, como su nombre podría sugerir)
- No es necesario especificar la identificación si el trabajador está conectado como keep-alive, Json invertido simplemente conecta al cliente y al trabajador directamente.
- La capacidad de "suscribirse" a varios comandos (canales), suscribirse a un patrón (por ejemplo, comando / *) sin perder rendimiento.
- La imagen de Docker es de solo 2.6 MB (versión delgada)
- Kernel Inverted Json solo ~ 1400 líneas de código (v0.3), menos código - menos errores;)
- El JSON invertido no modifica el cuerpo (cuerpo) de la solicitud, sino que lo envía tal cual.
5. Prueba Inverted Json en 3 minutos
Puedes probar Inverted Json ahora mismo si tienes
Docker y
curl :

Descripción de la imagen:
1) Al iniciar la imagen acoplable de
Json invertido en el puerto 8001, --log 47 registra las solicitudes entrantes, etc.
$ docker run -it -p 8001:8001 lega911/ijson --log 47
2) Registre al trabajador para la tarea "calc / sum" y espere la tarea, solicite el tipo "get", es decir - obtener la tarea:
$ curl localhost/calc/sum -H 'type: get'
3) El cliente realiza una solicitud de cálculo / suma RPC:
$ curl localhost/calc/sum -d '{"id": 15, "data": "2+3"}'
4) El trabajador recibe la tarea `{" id ": 15," data ":" 2 + 3 "}` - los datos no han cambiado, ahora debe enviar el resultado al mismo id, tipo de solicitud "result":
$ curl localhost -H 'type: result' -d '{"id": 15, "result": 5}'
... y el cliente obtiene el resultado como es
`{"id": 15, "result": 5}`5.1. Jsonrpc
JsonRPC 2 no es compatible, pero existen algunos rudimentos, por ejemplo, el cliente puede enviar solicitudes como (url / rpc / call):
{"jsonrpc": "2.0", "method": "calc/sum", "params": [42, 23], "id": 1}
aceptar errores como:
{"jsonrpc": "2.0", "error": {"code": -32601, "message": "Method not found"}, "id": null}
Sin embargo, si hay demanda, entonces se puede mejorar el soporte de JsonRPC.
5.2. Ejemplo de cliente y trabajador de Python
Y aquí puede encontrar un ejemplo en el "modo trabajador", que es más productivo y compacto.
6. Algunas reflexiones sobre el resultado de referencia
- Crossbar.io : se basa en python, por lo que no es tan rápido y no puede usar múltiples núcleos debido a GIL.
- RabbitMQ : RPC sobre MQ, que impone una sobrecarga adicional. Una caída rápida en el rendimiento con una carga creciente (no reflejada en la prueba).
- Nats : no es malo, aunque inferior a Json invertido, como RPC sobre MQ también tendrá los mismos problemas.
- Json invertido : alcanzó el límite de la red (es decir, el lanzamiento de varias copias de pruebas en diferentes núcleos no da un mejor resultado en total), mostró el uso más eficiente de la memoria y el procesador en relación con el rendimiento.
- Nginx : cuando se pasa el proxy, el rendimiento disminuye rápidamente si el modo mantener vivo no está activado (desactivado de manera predeterminada), debido a que Linux no permite abrir / cerrar muchos enchufes en un corto período de tiempo (esto no se refleja en la prueba).
- Traefik : muy voraz, utiliza el 600% de la CPU en el pico, inferior a nginx en velocidad
- uvloop (bajo asyncio): ofrece muy buen rendimiento, porque más escrito en C / C ++, para RPC es más preferible que ZeroMQ
- ZeroMQ : el trabajador en sí está escrito en Python, por lo que se ejecutó en el kernel, aunque la prueba multiprocesador consume más del 100% de CPU, esto se debe al hecho de que zeromq está escrito en C / C ++ sin captura de GIL. Ofrece un gran rendimiento, pero, por otro lado, si el trabajador no solo a + b, cualquier complicación conducirá a una reducción significativa en RPC, porque llegará al núcleo incluso antes.
- ZeroRPC : declarado como un contenedor ligero sobre ZeroMQ, en realidad, el 95% del rendimiento de ZeroMQ se pierde, parece que no es tan ligero.
- GRPC : la opción para python produce una gran cantidad de código python repetitivo, es decir el procesador resulta pesado y descansa rápidamente en la CPU, para los idiomas compilados probablemente no haya tal problema.
- Pruebas de 2 núcleos y múltiples núcleos, en varios núcleos algunos indicadores disminuyeron, ya que tiene que competir por los recursos de la CPU con el código de prueba del cliente, por otro lado, algunas pruebas dieron un gran rendimiento, por ejemplo Traefik, que se comió el 600% de la CPU
7. Conclusión
Si tiene una gran empresa y muchos empleados, puede permitirse soportar varias herramientas complejas para organizar conexiones directas entre microservicios, que pueden proporcionar una comunicación efectiva.
Y para pequeñas empresas y nuevas empresas, donde un pequeño equipo necesita resolver problemas de varios campos, Json invertido puede ahorrar tiempo y recursos.
Para el desarrollo de Inverted Json, los planes incluyen soporte para pubsub, kubernetes y otras ideas interesantes.
Si está interesado en el proyecto o simplemente quiere ayudar al autor, puede poner un asterisco en el
proyecto github , gracias.
PD:
- Tomó más tiempo crear este artículo, incluidas las pruebas, que crear el propio Json invertido
- Los prototipos de Json invertidos también se escribieron en 1. python + asyncio + uvloop, 2. en GoLang
- Las pruebas fueron revisadas por diferentes expertos.
- "Rebanadas en lugar de cadenas": en la mayoría de los casos, al analizar http / json, los datos no se copian en cadenas, pero se utiliza el enlace a los datos de origen, por lo tanto, no hay asignación y copia innecesarias de la memoria.
- Si va a probar, no use solicitudes en python, es muy lento, mejor que pycurl, este contenedor se usa en las pruebas.
- El punto de referencia está aquí
- Fuentes aquí