En arquitecturas grandes o de microservicios, el servicio más importante no siempre es el más productivo y, en ocasiones, no está destinado a cargas elevadas. Estamos hablando del backend. Funciona lentamente: pierde tiempo en el procesamiento de datos y espera una respuesta entre este y el DBMS, y no escala. Incluso si la aplicación en sí se escala fácilmente, este cuello de botella no se escala en absoluto. ¿Cómo resolver este problema y garantizar un alto rendimiento? ¿Cómo proporcionar una respuesta del sistema cuando las fuentes importantes de información están en silencio?

Si su arquitectura cumple totalmente con el manifiesto Reactivo, los componentes de la aplicación se escalan indefinidamente con una carga creciente independientemente uno del otro, y resisten la caída de cualquier nodo: ya sabe la respuesta. Pero si no, entonces
Oleg Nizhnikov (
Odomontois ) contará cómo se resolvió el problema de escalabilidad en Tinkoff construyendo su Fallback Cache indolora en Scala sin reescribir la aplicación.
Nota El artículo tendrá un mínimo de código Scala y un máximo de principios e ideas generales.Backend inestable o lento
Al interactuar con el back-end, la aplicación promedio es rápida. Pero el backend hace la mayor parte del trabajo y procesa la mayor parte de los datos internamente; lleva más tiempo. Se pierde tiempo extra esperando una respuesta de back-end y DBMS. Incluso si la aplicación en sí se escala fácilmente, este cuello de botella no se escala en absoluto. ¿Cómo aliviar la carga en el backend y resolver el problema?
Caché incrustado
La primera idea es tomar datos para leer, solicitudes que reciben datos y configurar el caché al nivel de cada nodo en memoria.
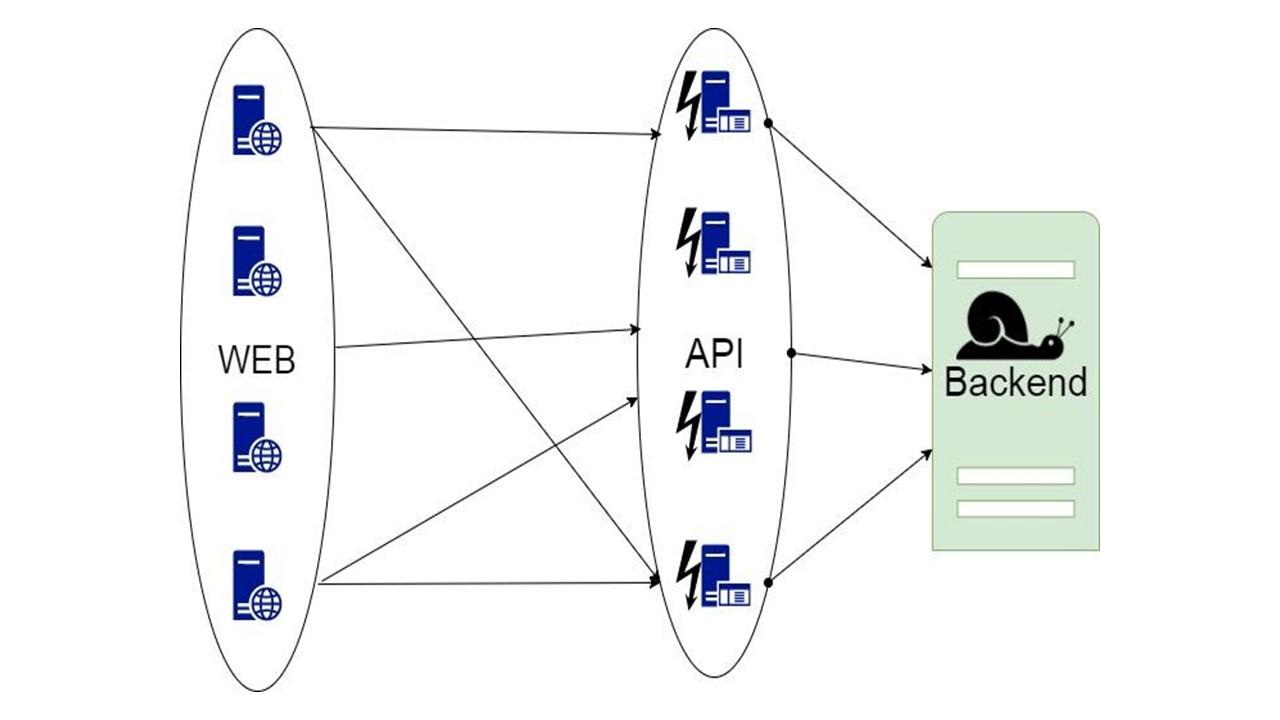
El caché vive hasta que el nodo se reinicia y almacena solo la última pieza de datos. Si la aplicación falla y entran nuevos usuarios que no han estado en la última hora, día o semana, la aplicación no puede hacer nada al respecto.
Proxy
La segunda opción es un proxy, que toma parte de las solicitudes o modifica la aplicación.
Pero en proxy, no puede hacer todo el trabajo para la aplicación en sí.
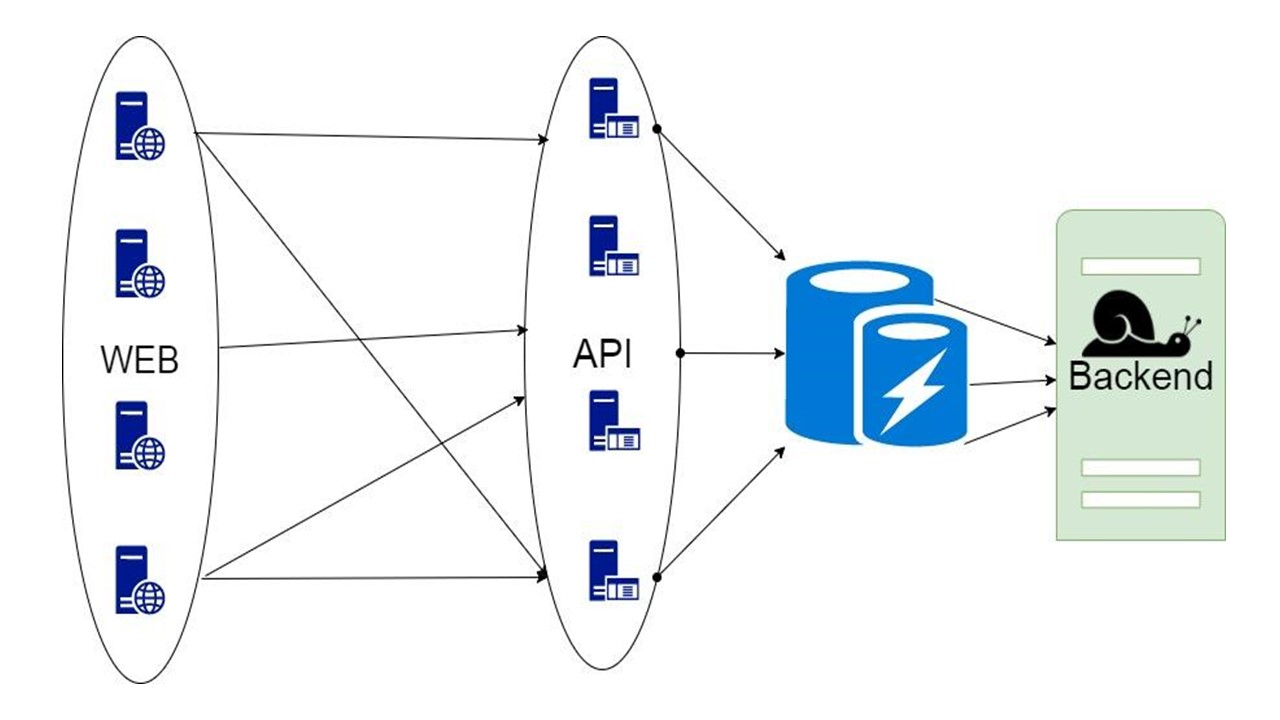
Base de datos de caché
La tercera opción es complicada cuando la parte de los datos que devuelve el back-end se puede almacenar durante mucho tiempo. Cuando son necesarios, mostramos al cliente, incluso si ya no son relevantes. Esto es mejor que nada.
Esta decisión será discutida.
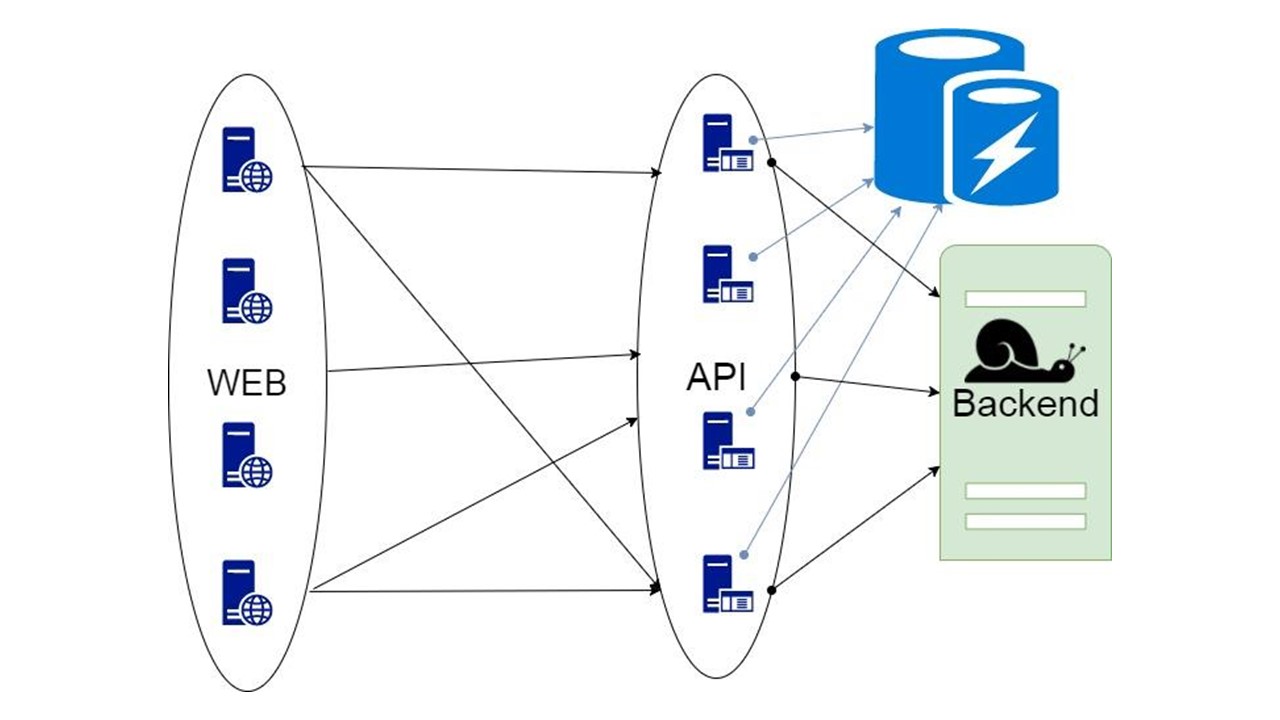
Caché de reserva
Esta es nuestra biblioteca Está incrustado en la aplicación y se comunica con el backend. Con un refinamiento mínimo, analiza la estructura de datos, genera formatos de serialización y, con la ayuda del algoritmo del disyuntor, aumenta la tolerancia a fallas. La serialización efectiva se puede implementar en cualquier idioma donde los tipos se puedan analizar de antemano si se definen de forma suficientemente estricta.
Componentes
Nuestra biblioteca se parece a esto.

La parte izquierda está dedicada a interactuar con este repositorio, que incluye dos componentes importantes:
- el componente responsable del proceso de inicialización: acciones preliminares con el DBMS antes de usar Fallback Cache;
- Módulo de generación de serialización automática.
El lado derecho es la funcionalidad general que se relaciona con Fallback.
¿Cómo funciona todo? Hay consultas en el medio de la aplicación y tipos intermedios para almacenar el estado. Este formulario expresa los datos que recibimos del servidor para una o más solicitudes. Enviamos los parámetros a nuestro método y obtenemos los datos desde allí. Estos datos deben ser serializados de alguna manera para poder almacenarse, por lo que los envolvemos en código. Un módulo separado es responsable de esto. Utilizamos el patrón del disyuntor.
Requisitos de almacenamiento
Larga vida útil: 30-500 días . Algunas acciones pueden llevar mucho tiempo, y todo este tiempo es necesario para almacenar datos. Por lo tanto, queremos un almacenamiento que pueda almacenar datos durante mucho tiempo. En memoria no es adecuado para esto.
Gran volumen de datos: 100 GB-20 TB . Queremos almacenar docenas de terabytes de datos en el caché, y aún más debido al crecimiento. Mantener todo esto en la memoria es ineficiente: la mayoría de los datos no se solicitan constantemente. Mienten mucho tiempo, esperando a su usuario, que entrará y preguntará. En la memoria no cae bajo estos requisitos.
Alta disponibilidad de datos . Al servicio le puede pasar cualquier cosa, pero queremos que el DBMS permanezca disponible todo el tiempo.
Bajos costos de almacenamiento . Enviamos datos adicionales al caché. Como resultado, se produce una sobrecarga. Al implementar nuestra solución, queremos minimizarla.
Soporte para consultas a intervalos . Nuestra base de datos debería haber podido extraer un dato no solo en su totalidad, sino a intervalos: una lista de acciones, el historial de un usuario durante un período determinado. Por lo tanto, un valor clave puro no es adecuado.
Supuestos
Los requisitos limitan la lista de candidatos. Suponemos que hemos implementado el resto, y hacemos las siguientes suposiciones, sabiendo por qué exactamente necesitamos Fallback Cache.
No se requiere integridad de datos entre dos solicitudes GET diferentes . Por lo tanto, si muestran dos estados diferentes que no son consistentes entre sí, lo soportaremos.
No se requiere relevancia ni invalidación de datos . En el momento de la solicitud, se supone que tenemos la última versión que estamos mostrando.
Enviamos y recibimos datos del backend.
La estructura de estos datos se conoce de antemano .
Selección de almacenamiento
Como alternativas, consideramos tres opciones principales.
El primero es
Cassandra . Ventajas: alta disponibilidad, fácil escalabilidad y mecanismo de serialización integrado con la colección UDT.
UDT o
tipos definidos por el usuario , significa algún tipo. Le permiten apilar eficientemente tipos estructurados. Los campos de tipo se conocen de antemano. Estos campos de serialización están marcados con etiquetas separadas como en Protocol Buffers. Después de leer esta estructura, es posible comprender qué campos hay en función de las etiquetas. Suficientes metadatos para averiguar su nombre y tipo.
Otra ventaja de Cassandra es que, además de la clave de partición, tiene una
clave de agrupación adicional. Esta es una clave especial, debido a que los datos se ordenan en un nodo. Esto le permite implementar una opción como consultas de intervalo.
Cassandra ha existido por un tiempo relativamente largo, hay
muchas soluciones de monitoreo para ello , y
una menos es la JVM . Esta no es la opción más productiva para plataformas en las que puede escribir un DBMS. La JVM tiene problemas con la recolección de basura y los gastos generales.
La segunda opción es
CouchBase . Ventajas: accesibilidad de datos, escalabilidad y sin esquema.
Con CouchBase, debe pensar menos en la serialización. Esto es tanto un más como un menos: no necesitamos controlar el esquema de datos. Existen índices globales que le permiten ejecutar consultas de intervalo de forma global en un clúster.
CouchBase es un híbrido donde
Memcache se agrega a un DBMS habitual
: caché rápido . Le permite almacenar automáticamente en caché todos los datos en el nodo, el más caliente, con una disponibilidad muy alta. Gracias a su caché, CouchBase puede ser rápido si se solicitan los mismos datos con mucha frecuencia.
Sin esquema y
JSON también pueden ser un signo menos. Los datos pueden almacenarse durante tanto tiempo que la aplicación tenga tiempo de cambiar. En este caso, la estructura de datos que CouchBase va a almacenar y leer también cambiará. La versión anterior puede no ser compatible. Solo aprenderá sobre esto cuando lea, y no cuando desarrolle datos, cuando se encuentren en algún lugar de la producción. Tenemos que pensar en una migración adecuada, y esto es exactamente lo que no queremos hacer.
La tercera opción es
Tarantool . Es famoso por su súper velocidad. Tiene un maravilloso motor LUA que le permite escribir un montón de lógica que se ejecutará directamente en el servidor en LuaJit.
Por otro lado, este es un valor clave modificado. Los datos se almacenan en tuplas. Necesitamos pensar por nosotros mismos en la serialización correcta, esto no siempre es una tarea obvia. Tarantool también tiene un enfoque específico para la
escalabilidad . Lo que está mal con él, lo discutiremos más a fondo.
Fragmentación / replicación
Quizás nuestra aplicación necesite
Sharding / Replication . Tres repositorios los implementan de manera diferente.
Cassandra sugiere una estructura que generalmente se llama un "anillo".
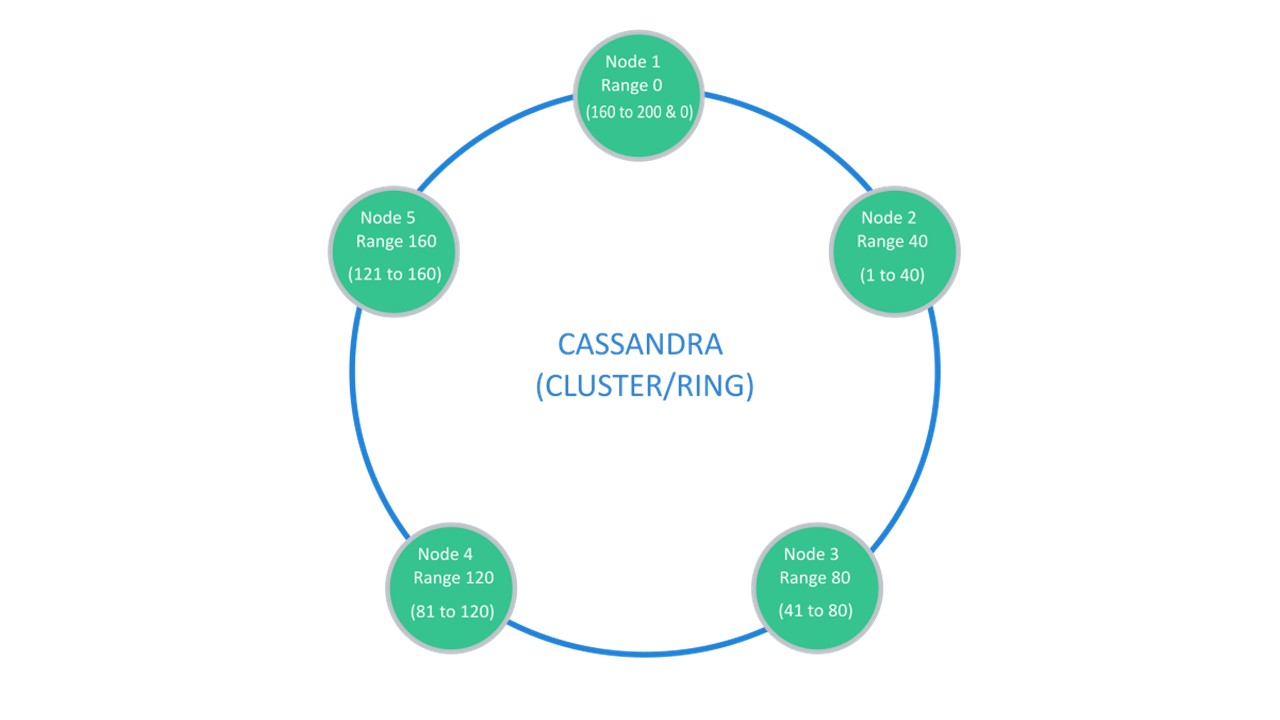
Muchos nodos están disponibles. Cada uno de ellos almacena sus datos y los datos de los nodos más cercanos como réplicas. Si uno abandona, los nodos a su lado pueden servir parte de sus datos hasta que aumente el abandono.
Sharding \ Replication es responsable de la misma estructura. Para desempaquetar en 10 piezas y factor de replicación 3, 10 nodos son suficientes. Cada uno de los nodos almacenará 2 réplicas de las vecinas.
En CouchBase, la estructura de interacción entre nodos se estructura de manera similar:
- hay datos que están marcados como activos, de los cuales el nodo mismo es responsable;
- Hay réplicas de nodos vecinos que almacena CouchBase.
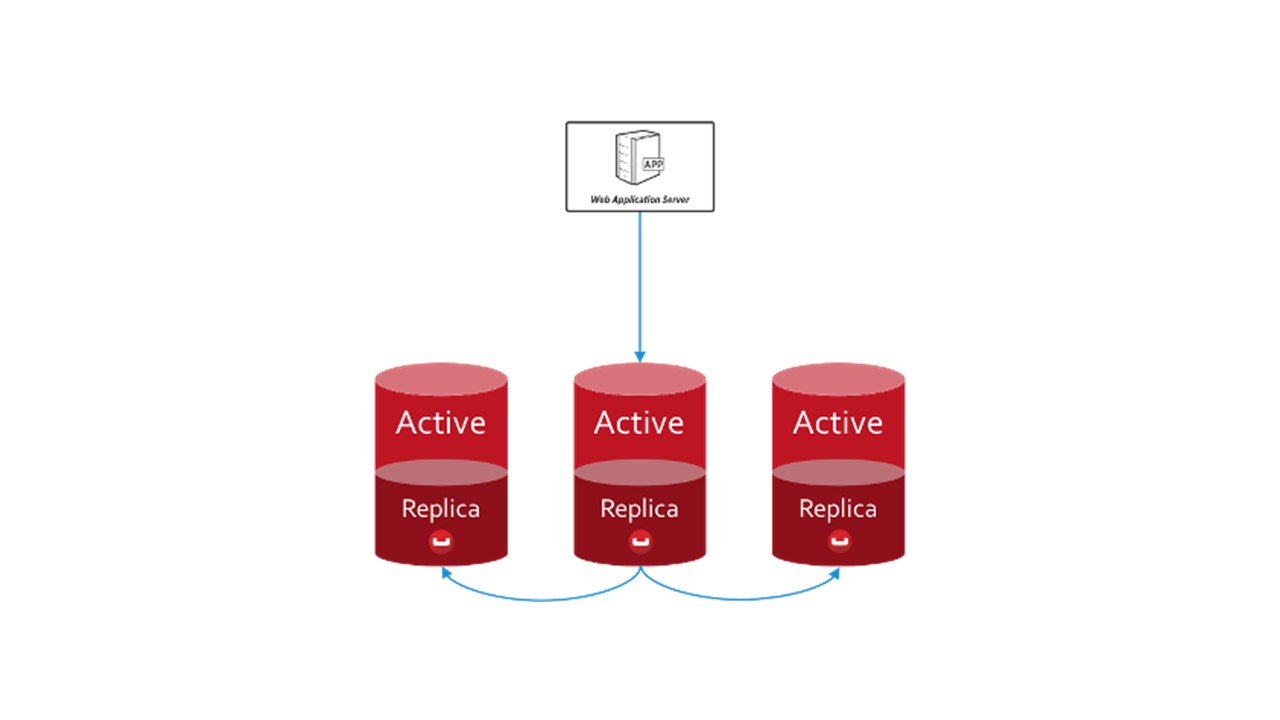
Si un nodo se cae, los vecinos, los compartidos, se responsabilizan del mantenimiento de esta parte de las claves.
En Tarantool, la arquitectura es similar a MongoDB. Pero con un matiz: hay grupos de particiones que se replican entre sí.
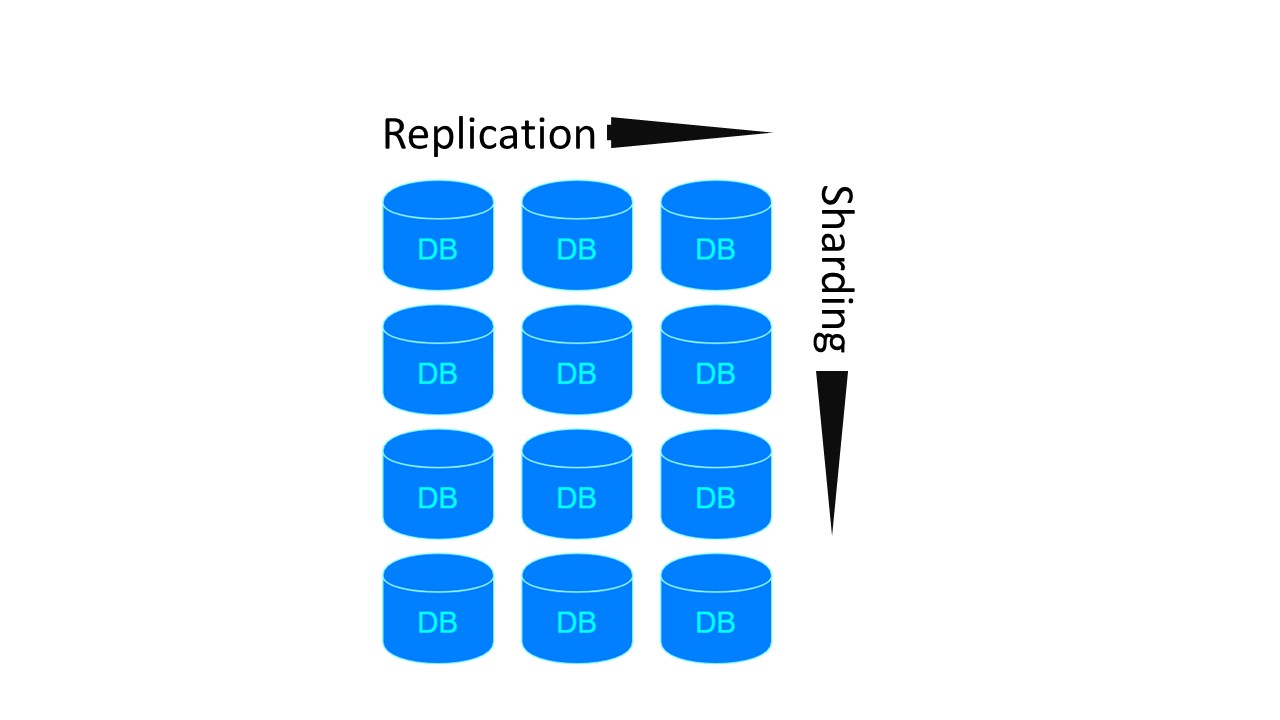
Para las dos arquitecturas anteriores, si queremos hacer 4 fragmentos y el factor de replicación 3, se requieren 4 nodos. Para Tarantool - 12! Pero la desventaja se compensa con la velocidad que garantiza Tarantool.
Cassandra
Los módulos opcionales para fragmentación en Tarantool aparecieron recientemente. Por lo tanto, elegimos el DBMS Cassandra como el principal candidato. Recordemos que hablamos sobre su serialización específica.
Serialización automática
El protocolo SQL supone que es bastante libre de definir un esquema de datos.
Puedes usar esto como una ventaja. Por ejemplo, serialice datos para que los nombres de campo largos de nuestras estructuras frondosas no se almacenen cada vez en nuestros valores. En este caso, tendremos algunos metadatos que describen el dispositivo de datos. Los UDT también indican qué campos corresponden a etiquetas y etiquetas.
Por lo tanto, la serialización generada automáticamente tiene lugar aproximadamente de la misma manera. Si tenemos uno de los tipos básicos que pueden coincidir con el tipo de la base de datos uno a uno, lo hacemos. Un conjunto de tipos Int, Long, String, Double también está en Cassandra.
Si se encuentra un campo opcional en alguna estructura, no hacemos nada extra. Le indicamos el tipo en el que debe convertirse este campo. La estructura almacenará nulo. Si encontramos nulo en la estructura en el nivel de deserialización, asumimos que esta es la ausencia de un valor.
Todos los tipos de colección de la colección en Scala se convierten a la lista de tipos. Estas son colecciones ordenadas que tienen un elemento de coincidencia de índice.
Las colecciones de conjuntos sin ordenar garantizan que hay exactamente un elemento con cada valor. Cassandra también tiene un tipo de set especial para ellos.
Lo más probable es que tengamos muchos mapas (), especialmente con las teclas de cadena. Cassandra tiene un tipo de mapa especial para ellos. También está escrito y tiene dos parámetros de tipo. Para que podamos crear un tipo apropiado para cualquier clave
Hay tipos de datos que nos definimos en nuestra aplicación. En muchos idiomas se denominan
tipos de datos algebraicos . Se definen definiendo un producto con nombre de tipos, es decir, una estructura. Asignamos esta estructura al tipo definido por el usuario. Cada campo de la estructura corresponderá a un campo en el UDT.
El segundo tipo es la
suma algebraica de tipos . En este caso, el tipo corresponde a varios subtipos o subespecies previamente conocidos. Además, de cierta manera, le asignamos una estructura.
El tipo de datos abstracto se traduce a UDT
Tenemos una estructura y la mostramos uno a uno: para cada campo definimos el campo en el UDT creado en Cassandra:
case class Account ( id: Long, tags: List[String], user: User, finData: Option[FinData] ) create type account ( id bigint, tags: frozen<list<text>>, user frozen<user>, fin_data frozen<fin_data> )
Los tipos primitivos se convierten en tipos primitivos. Un enlace a un tipo predefinido antes de que esto se congele. Este es un contenedor especial en Cassandra, lo que significa que no puede leer de este campo pieza por pieza. El contenedor está "congelado" en este estado. Solo podemos leer o guardar al usuario, o la lista, como en el caso de las etiquetas.
Si nos encontramos con un campo opcional, descartamos esta característica. Tomamos solo el tipo de datos correspondiente al tipo de campo que será. Si encontramos no aquí, la ausencia de un valor, escribimos nulo en el campo correspondiente. Al leer, también tomaremos correspondencia no nula.
Si nos encontramos con un tipo que tiene varias alternativas conocidas, también definimos un nuevo tipo de datos en Cassandra. Para cada alternativa, un campo en nuestro tipo de datos en UDT.
Como resultado, en esta estructura, solo uno de los campos en un momento dado no será nulo. Si conoció a algún tipo de usuario y resultó ser una instancia de un moderador en tiempo de ejecución, el campo del moderador contendrá algún valor, el resto será nulo. Para admin - admin, el resto - nulo.
Esto le permite codificar la estructura de la siguiente manera: tenemos 4 campos opcionales, le garantizamos que solo se escribirá uno de ellos. Cassandra usa solo una etiqueta para identificar la presencia de un campo particular en la estructura. Gracias a esto, obtenemos una estructura de almacenamiento sin gastos generales.
De hecho, para guardar el tipo de usuario, si es un moderador, tomará la misma cantidad de bytes necesarios para almacenar el moderador. Más un byte para mostrar qué alternativa particular está presente aquí.
Inicialización
La inicialización es un procedimiento preliminar que debe completarse antes de que podamos usar nuestro respaldo.
¿Cómo funciona este proceso?
- En cada nodo generamos definiciones de tablas, tipos y textos de consulta basados en los tipos que se presentan.
- Lea el esquema actual del DBMS. En Cassandra, esto es fácil de hacer simplemente conectándose a él. Cuando está conectado, en casi todos los controladores, el objeto "sesión" mismo bombea los metadatos del espacio clave al que está conectado. Entonces puedes ver lo que tienen.
- Revisamos los metadatos, comparamos y verificamos que todo lo que queremos crear esté permitido y que la migración incremental sea posible.
- Si todo es normal y la inicialización es posible, realizamos la migración.
- Estamos preparando solicitudes.
sealed trait User case class Anonymous extends User case class Registered extends User case class Moderator extends User case class Admin extends User create type user ( anonymous frozen<anonymous>, registered frozen<registered>, moderator frozen<moderator>, admin frozen<admin> )
Sucede así. Tenemos
tipos ,
tablas y
consultas . Los tipos dependen de otros tipos, los de otros. Las tablas dependen de estos tipos. Las consultas ya dependen de las tablas de las que leen los datos. La inicialización verificará todas estas dependencias y creará en el DBMS todo lo que pueda crear, de acuerdo con ciertas reglas.
Tipo de migración
¿Cómo determinar que un tipo se puede migrar gradualmente?
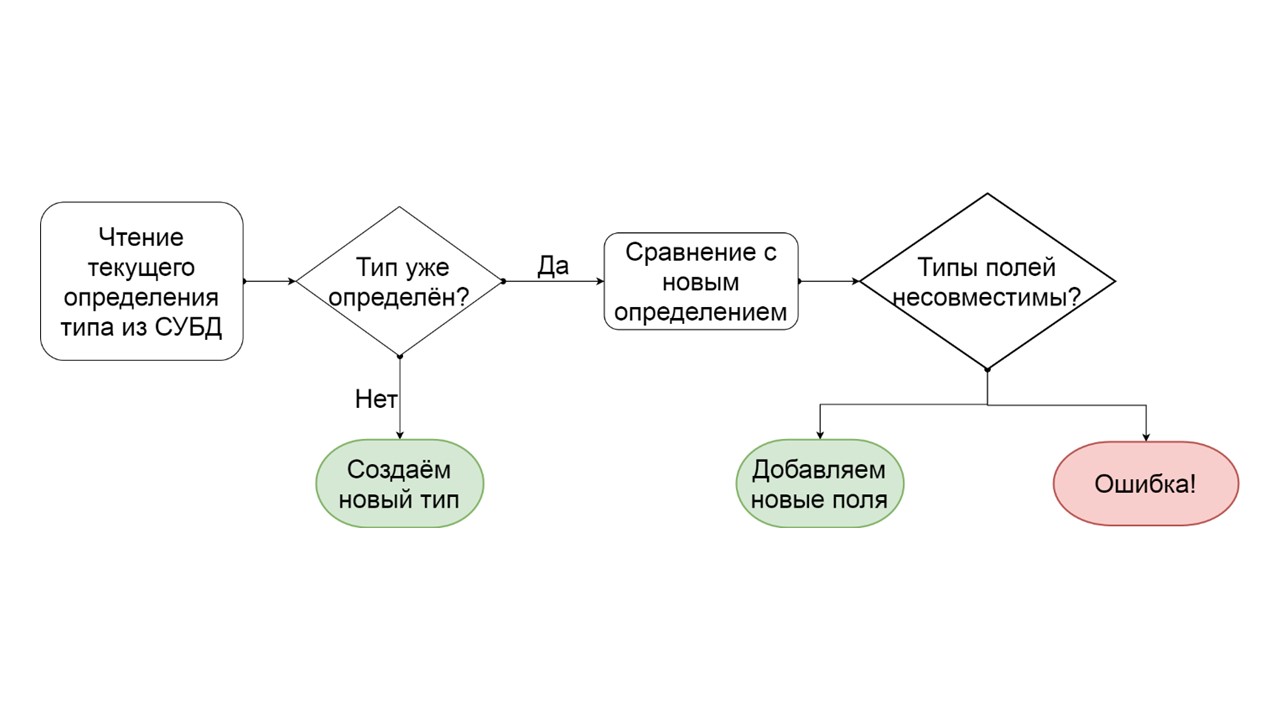
- Leemos cómo se define este tipo en el DBMS.
- Si no existe ese tipo, es decir, se nos ocurrió uno nuevo: lo creamos.
- Si tal tipo ya existe, estamos tratando de comparar campo por campo la definición existente con la que queremos dar a este tipo.
- Si resulta que queremos agregar solo unos pocos campos que ya no existen, lo hacemos. Cree una lista de operaciones ALTER TYPE mutantes e inícielas.
- Si resulta que tenemos algún tipo de campo que era de un tipo diferente, generamos un error. Por ejemplo, había una lista, se convirtió en un mapa, o había un enlace a un tipo definido por el usuario, y estamos tratando de hacerlo diferente.
El desarrollador puede ver este error incluso antes de iniciar la funcionalidad en producción. Supongo que exactamente el mismo esquema de datos está en su entorno de desarrollo. Él ve que de alguna manera creó un esquema de datos no migrables, y para evitar estos errores, puede anular la serialización generada automáticamente, agregar opciones, renombrar campos o todos los tipos y tablas en su conjunto.
Inicialización: tipos
Imagine que hay varios tipos de definiciones:
case class Product (id: Long, name: ctring, price: BigDecimal) case class UserOffers (valiDate: LocalDate, offers: Seq[Products]) case class UserProducts (user User, products: Map[Date, Product]) case class UserInfo: UserOffers, products: UserProducts)
Clase de caso : una clase que contiene un conjunto de campos. Este es un análogo de struct en Rust.
Generaremos aproximadamente tales definiciones de datos para cada uno de los 4 tipos, lo que queremos eventualmente aumentar:
CREATE TYPE product (id bigint, name text, price decimal); CREATE TYPE user_offers (valid_date date, offers frozen<list<frozen<offer>>>); CREATE TYPE user_products (user frozen<user>, products frozen<map<date, frozen<product>>); CREATE TYPE user_jnfo (offers: frozen<user_offers>, products: frozen<user_products>);
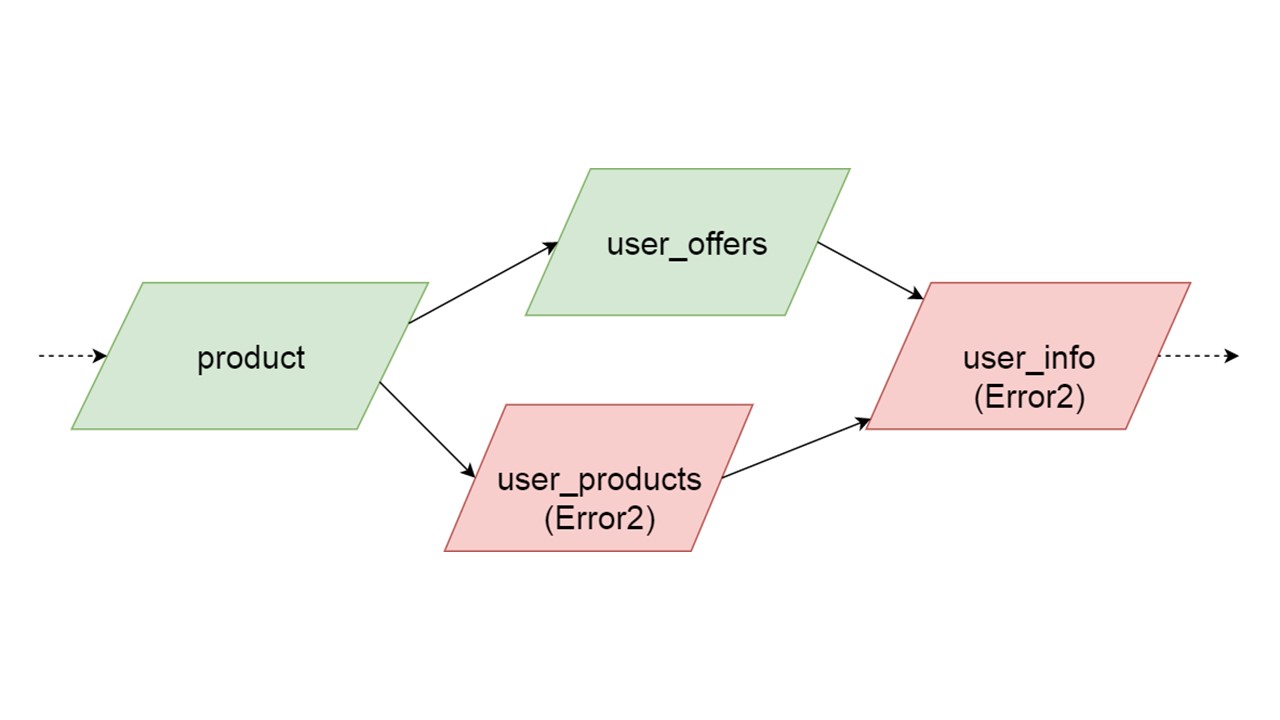
El tipo de ofertas de usuario depende del tipo de oferta, los productos de usuario dependen del tipo de producto, la información de usuario en el segundo y tercer tipo.

Tenemos tal dependencia entre tipos, y queremos inicializarla correctamente. El diagrama muestra que inicializaremos user_offers y user_products en paralelo. Esto no significa que lanzaremos dos operaciones paralelas. No, comenzamos todas las declaraciones, todos los análisis secuencialmente, para no crear accidentalmente el mismo tipo en dos hilos paralelos.
Pero hay cierto paralelismo a nivel de corrección de errores. Si se produce un error de tipo, todo lo que dependa de él extraerá el error original.
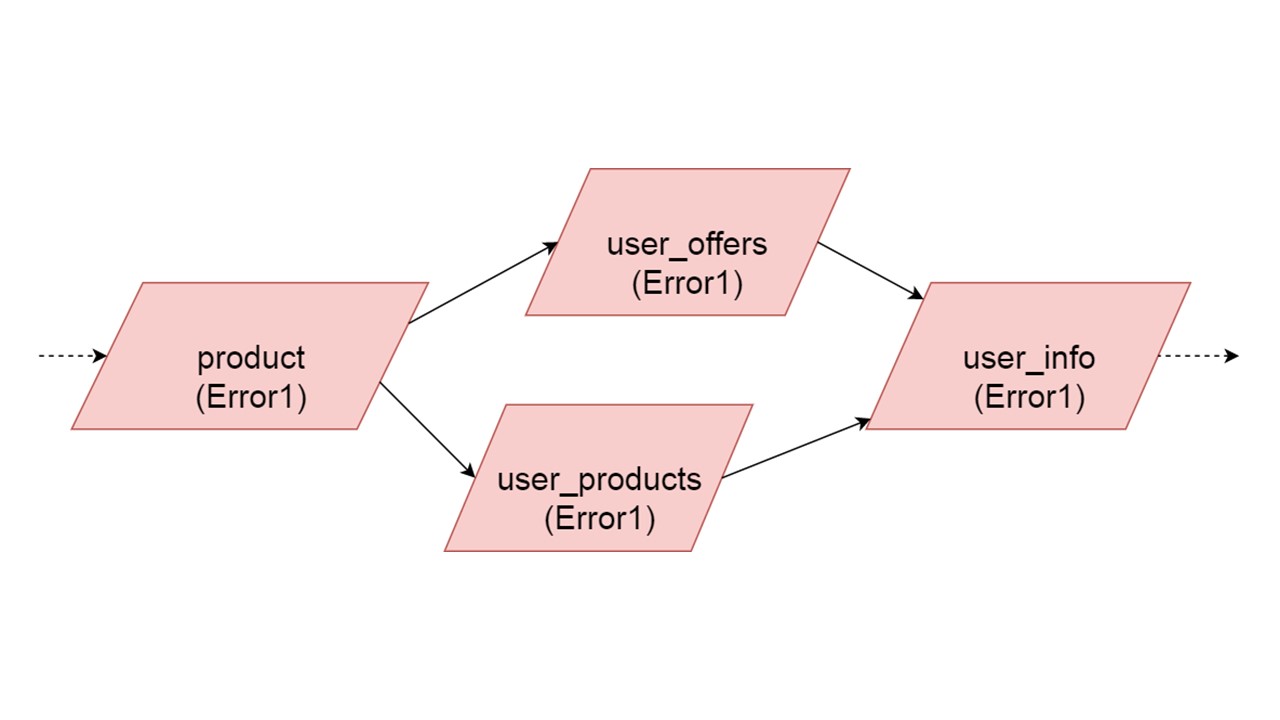
Si cualquiera de las ramas paralelas genera un error, todo lo que dependa de los datos migrados normalmente se generará sin un error. Si hay más definiciones de tablas, declaraciones preparadas de ellas, podemos inicializar de manera segura esta parte de nuestra caché de reserva. La comunicación se perderá solo con alguna parte de los backends o con alguna funcionalidad. Los restos se inicializan.
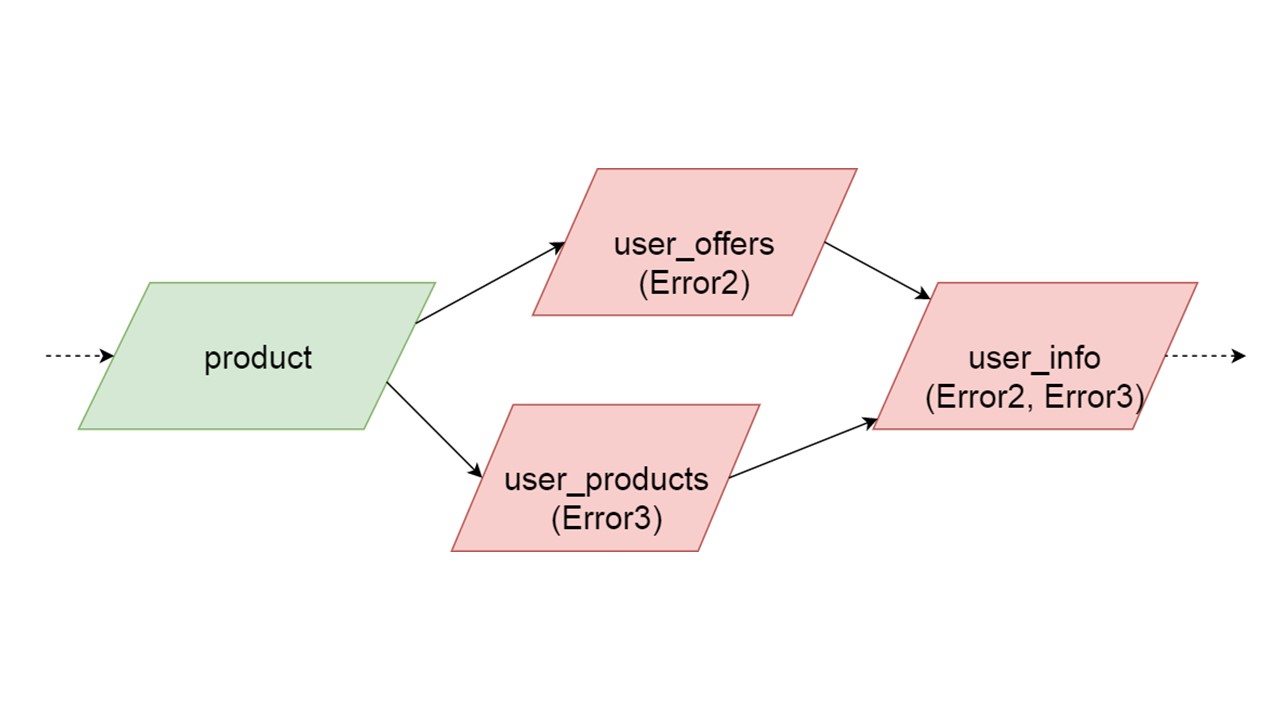
Puede suceder que dos tipos que se inicializan simultáneamente generen errores diferentes. En este caso, la funcionalidad que depende de ambos tipos producirá un tipo de error sumador. El desarrollador, al inicializar su Fallback en el entorno de desarrollo, recibirá una lista completa de datos con errores. Naturalmente, puede solucionarlo aquí y obtener el error aún más. Pero no será tal que una rama completamente independiente cierre los errores que podamos obtener, independientemente de esta rama.
Inicialización: tablas
A continuación creamos las tablas.
def getOffer (user: User, number: Long): Future[OfferData] create table get_offer( key frozen<tuple<frozen<user>, bigint>>PRIMARY KEY, value frozen<friend_data> )
Dicha solicitud puede iniciar directamente una solicitud REST o SOAP, crear operaciones adicionales dentro o incluso ejecutar varias solicitudes. Todo depende de su código: cómo organizará el código será así. Fallback no analiza por completo lo que sucede dentro del método en el que cuelgas dicho trozo.
El método debe ser asíncrono, porque Fallback es el mismo.
En Scala, esto está etiquetado con un tipo especial de futuro. Esto significa que el resultado volverá algún día. Cuándo exactamente, es desconocido: tal vez de inmediato, o tal vez no.
Para el método, cree una tabla. La clave en la tabla es una tupla de todos los tipos que corresponden a los parámetros de este método. El valor no clave es el resultado, que se devuelve de forma asincrónica. Para cada una de esas tablas, preparamos dos consultas paramétricas por adelantado: insertar datos y leer datos.
insert into get_offer(key, value) values (?key, ?value); select value from get_offer where key = ?key;
Todo está listo para interactuar con el DBMS. Queda por descubrir cómo leeremos los datos de Fallback.
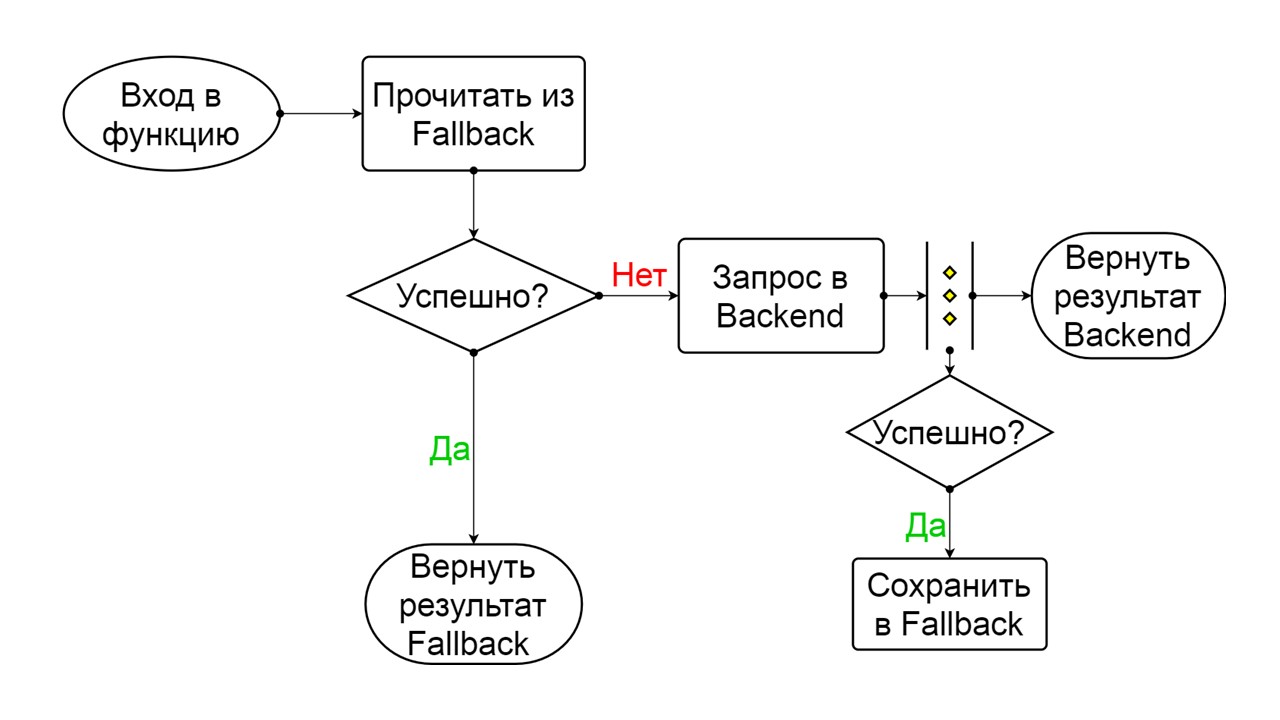
Disyuntor
Aquí, la responsabilidad pasa a la zona del famoso patrón de disyuntor.
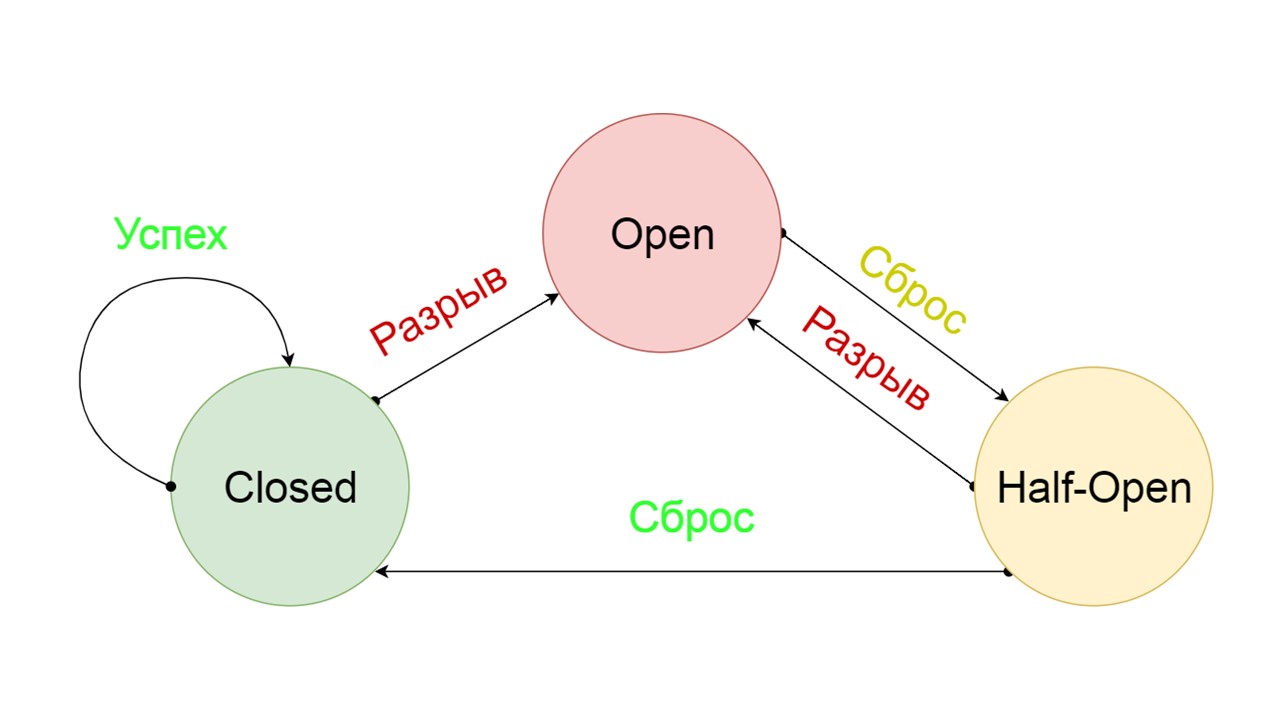
Un disyuntor típico incluye tres estados.
Cerrado: el estado cerrado predeterminado que cierra nuestro backend. El principio es que primero leemos los datos del backend, y solo si no podemos obtenerlos, vamos a Fallback. Si logramos obtener los datos, no buscamos en Fallback, sino que guardamos los datos en él y no sucede nada.
Si los problemas van uno tras otro, asumimos que el servidor está mintiendo. Para no enviar correos no deseados con una cantidad gigantesca de nuevas solicitudes, cambiamos a
Abrir, en un estado desgarrado . En él, estamos tratando de leer datos solo de Fallback. Si no funciona, inmediatamente devolvemos un error, y ni siquiera tocamos el back-end principal.
Después de un tiempo, decidimos averiguar si el backend se despertó e intentamos restablecer el estado
Half-Open, un estado de corta duración . Su esperanza de vida es una petición.
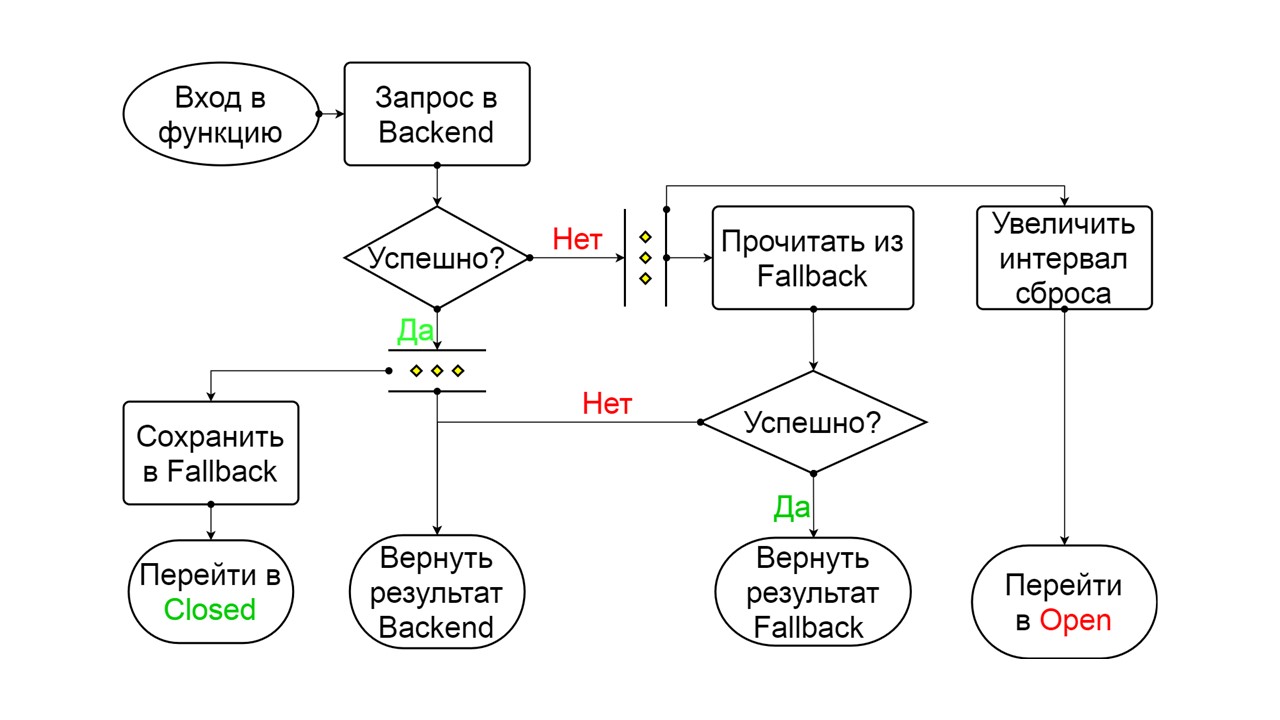
En el estado de corta duración, elegimos cerrar de nuevo o abrir por un tiempo aún más largo. Si en el estado Medio abierto llegamos con éxito a Fallback y recibimos la siguiente solicitud, pasamos al estado Cerrado. Si no pudimos pasar, volvemos a Open, pero durante mucho tiempo.
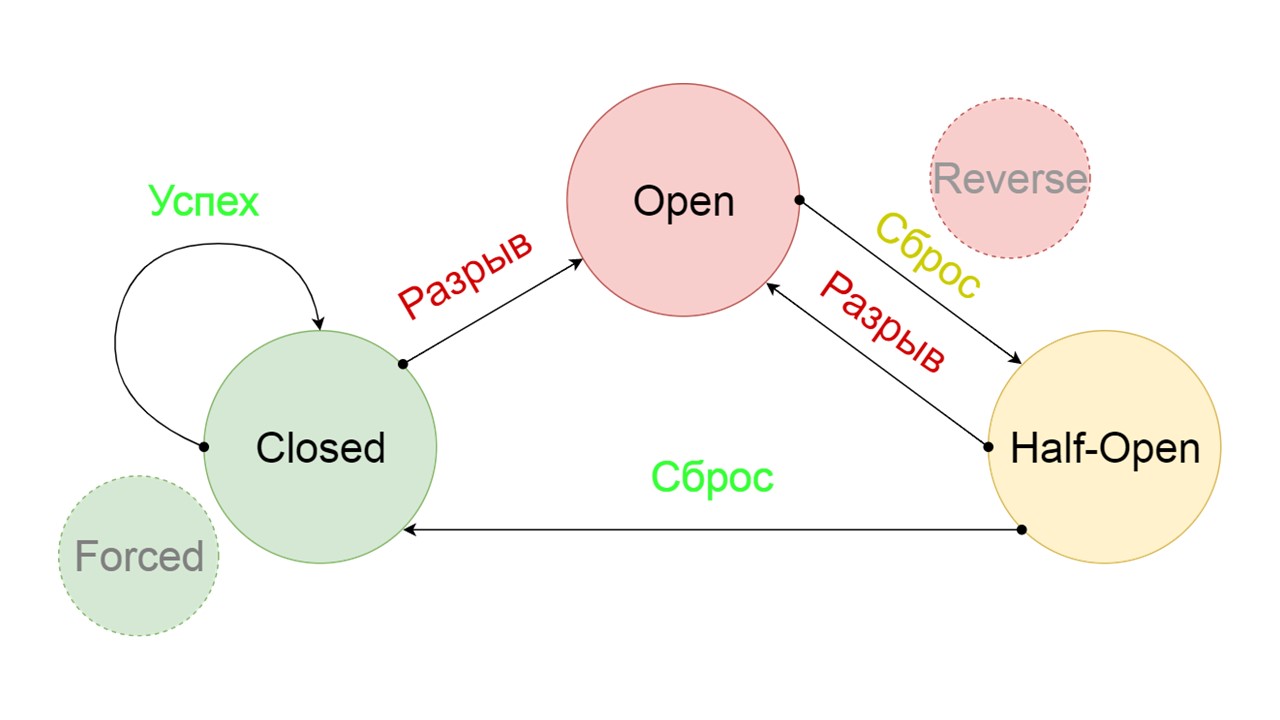
Agregamos dos estados adicionales que claramente no están relacionados con el circuito del disyuntor:
- Forzado - estado forzado cerrado;
- Invertido: prioridad para el estado abierto, cerrado invertido.
Veamos que hacen.
El principio de funcionamiento de los estados.
Cerrado El esquema es grande, pero es suficiente para entender el principio general de él. Mantenemos Fallback en paralelo con la forma en que devolvemos el resultado del backend, si todo salió bien allí y leemos de Fallback. Si es malo en todas partes, devolvemos la prioridad de error.
De los dos errores, seleccione el error del backend.
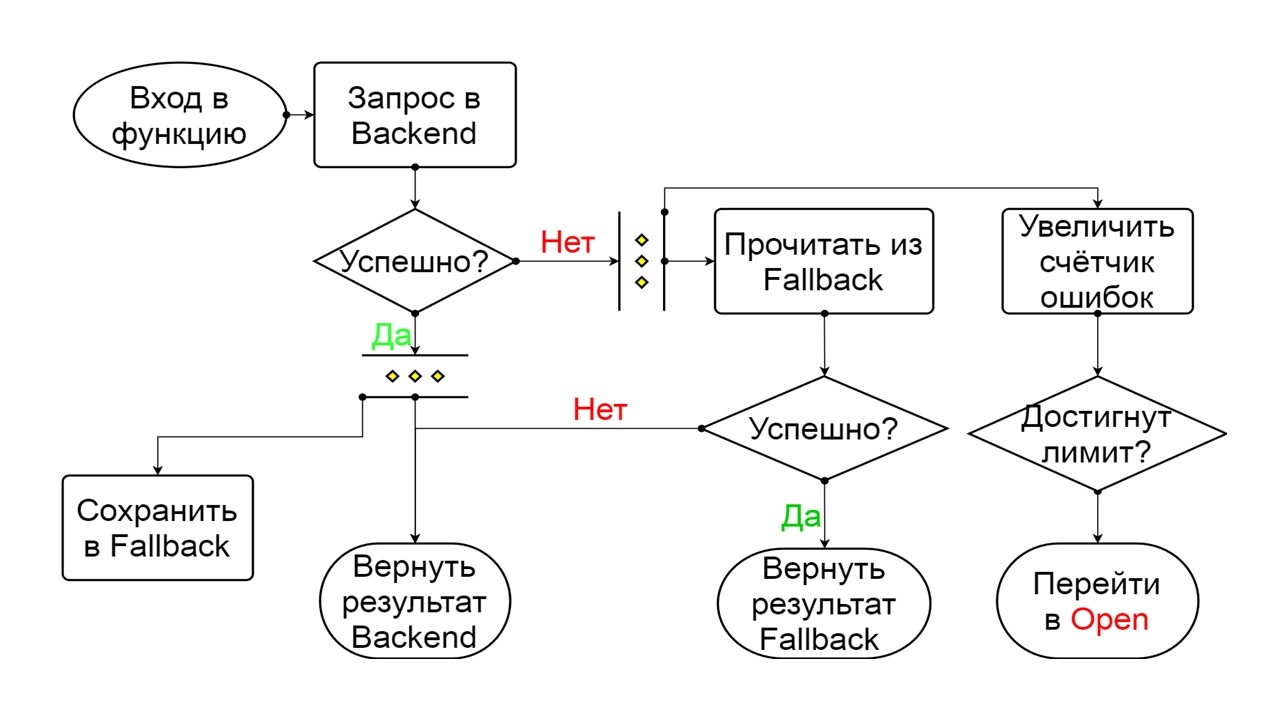
Si no hay errores, incrementamos el contador en paralelo con esto y pasamos al estado abierto cuando hay demasiadas solicitudes.
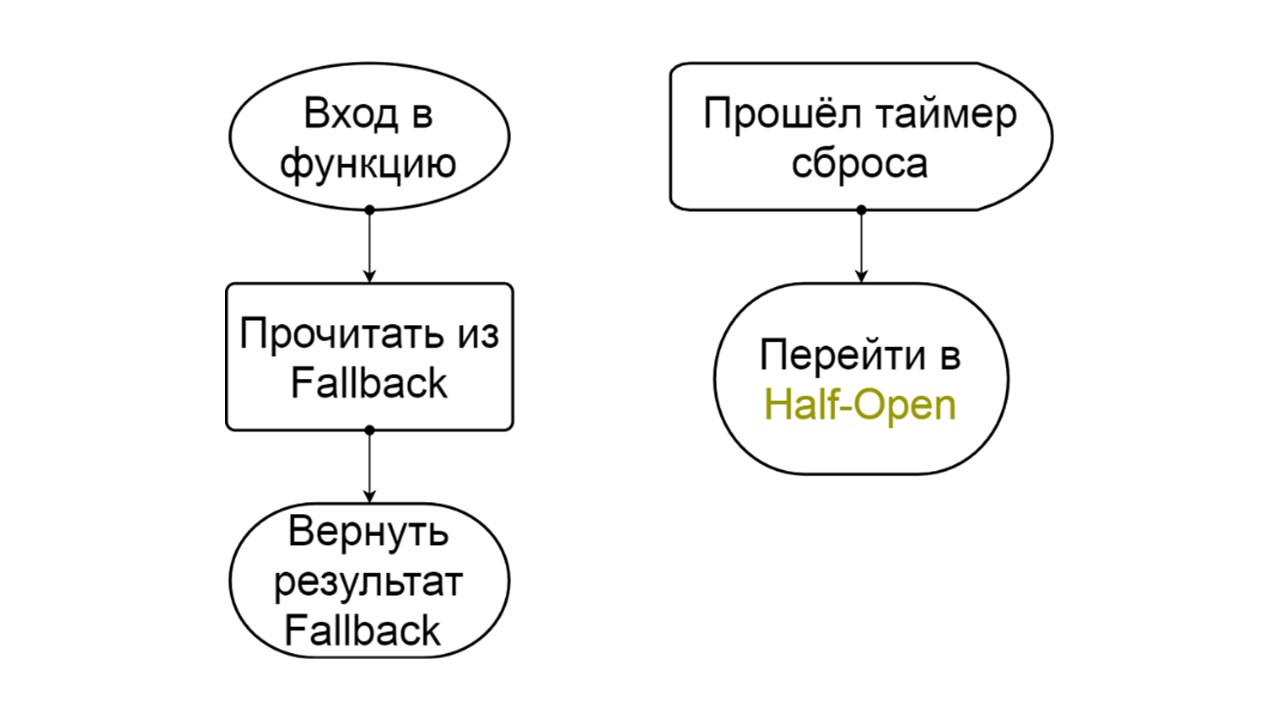 Abierto
Abierto El estado abierto de Abrir es más simple: leemos constantemente de Fallback, pase lo que pase, y después de un tiempo intentamos cambiar al estado Medio abierto.
Medio abierto . El estado en la estructura se asemeja a Cerrado. La diferencia es que en el caso de una respuesta exitosa, entramos en un estado cerrado. En caso de falla, volvemos a la apertura con un intervalo extendido.
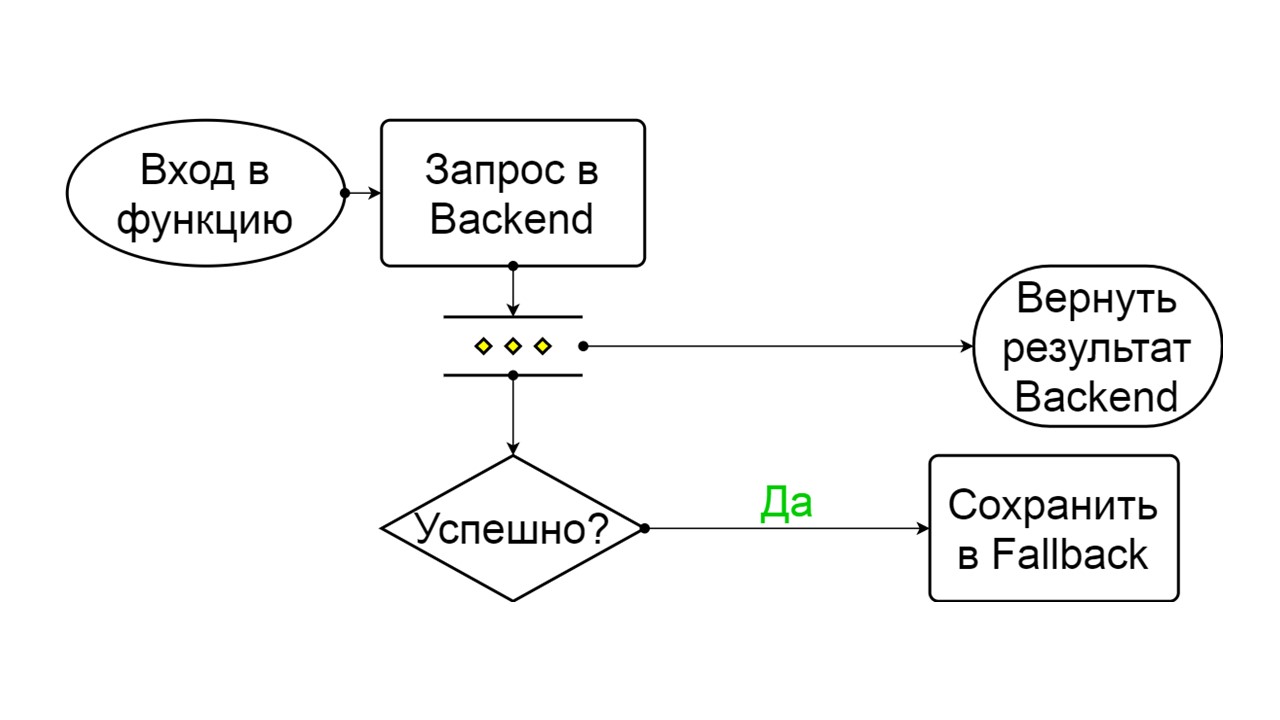
 Forzado es un estado adicional para calentar el caché
Forzado es un estado adicional para calentar el caché . Cuando lo llenamos con datos, nunca intenta leer de Fallback, sino que solo agrega registros.
 Invertido es un segundo estado descabellado
Invertido es un segundo estado descabellado . Funciona como un caché persistente. Activamos el estado cuando queremos eliminar permanentemente la carga del back-end, incluso si los datos pueden ser irrelevantes. Invierte las primeras búsquedas en Fallback, y si la búsqueda falla, va al backend y se ocupa de ello.
Los problemas
Con todo este esquema, tuvimos varios problemas. La más grave es comprender cómo funcionan las
declaraciones preparadas en Cassandra. Este problema se ha solucionado en la versión 4.0, que aún no se ha lanzado, así que te lo diré.
Cassandra está diseñada para conectar a millones de clientes al mismo tiempo, y todos están tratando de preparar sus declaraciones preparadas. Naturalmente, Cassandra no prepara todas las declaraciones preparadas, de lo contrario se quedará sin memoria. Calcula el parámetro MD5 en función del texto, el espacio clave y las opciones de consulta. Si recibe exactamente la misma solicitud con exactamente el mismo MD5, acepta la solicitud ya preparada. Ya tiene información sobre metadatos y cómo manejarlo.
Pero hay problemas de versión. Estamos lanzando una nueva versión, realizó migraciones con éxito, agregó campos en tipos y ejecutó declaraciones preparadas. Vuelven con la versión anterior de nuestro estado y metadatos, con tipos sin campos. Al momento de leer los datos, estamos tratando de escribir sus nuevas columnas requeridas, ¡y nos enfrentamos al hecho de que simplemente no existen! Cassandra dice que este es generalmente un tipo diferente que ella no conoce.
Nos ocupamos de este problema de la siguiente manera:
agregamos un texto único a cada una de nuestras solicitudes preparadas .
create table get_offer( key frozen<tuple<frozen<user>, bigint>> PRIMARY KEY, value frozen<friend_data>, query_tag text ) insert into get_offer (key, value, query_tag) values (?key, ?value, 'tag_123'); select value as tag_123 from get_offer where key = ?key;
No tendremos millones de clientes conectados, sino solo una sesión para cada nodo que contenga varias conexiones. Para cada declaración de preparación una vez. Suponemos que está bien si para cada versión de la aplicación o para cada inicio de un nodo, se genera un texto único, que claramente estará en el texto de nuestra solicitud.
Agregamos un campo especial para engañarlo. Al insertar, escribimos una constante en este campo. Es único para cada versión de lanzamiento o aplicación; esto se configura en la biblioteca. Al leer, usamos este nombre como alias para el valor que obtenemos. La solicitud es exactamente la misma, todavía estamos haciendo un valor de selección, pero el texto es diferente. Cassandra no se da cuenta de que esta es la misma solicitud, calcula otro MD5 y prepara la solicitud nuevamente con nuevos metadatos.
El segundo problema es la
carrera migratoria . Por ejemplo, queremos hacer varias migraciones paralelas. Comencemos algunas notas y al mismo tiempo comenzarán los cálculos, ejecutarán crear tablas, crear tipos. Esto puede llevar al hecho de que en cada nodo o en cada uno de los subprocesos paralelos todo será exitoso y dos tablas parecen ser creadas con éxito. Pero dentro de Cassandra se confunde, y recibiremos tiempos de espera para escribir y leer.
Puede romper Cassandra si intenta paralelizar procesos de múltiples hilos o de múltiples nodos.
Si sabemos que debemos tener una migración alternativa,
migramos desde un nodo especial antes del lanzamiento . Solo entonces comenzaremos todos nuestros nodos durante el lanzamiento. Entonces resolvimos este problema.
El tercer problema es la
falta de datos en Fallback Cache . Puede ser que hayamos "respaldado" el método, debería almacenar datos históricos de hace un año, pero en realidad lo lanzamos ayer.
El problema se resolvió calentando . Utilizamos el estado Forzado y lanzamos nodos especiales que no se comunicarán con usuarios reales. Tomarán todas las claves posibles que suponemos y calentarán el caché en un círculo. El calentamiento va muy rápido para no matar el backend del que estamos leyendo.
Escalado de aplicaciones, backend, big data y frontend: Scala es adecuado para todo esto. 26 de noviembre, estamos celebrando una conferencia profesional para desarrolladores de Scala . Estilos, enfoques, docenas de soluciones para el mismo problema, los matices del uso de enfoques antiguos y probados, la práctica de la programación funcional, la teoría de la cosmonautica funcional radical: hablaremos de todo esto en la conferencia. Solicite un informe si desea compartir su experiencia Scala antes del 26 de septiembre, o reserve sus boletos .