Hola Equipo de análisis ad-hoc de Big Data conectado de X5 Retail Group.
En este artículo, hablaremos sobre nuestra metodología de prueba A / B y los desafíos que enfrentamos a diario.
Big Data X5 emplea a unas 200 personas, incluidas 70 la fecha de los científicos y la fecha de los analistas. Nuestra parte principal se dedica a productos específicos: demanda, surtido, campañas de promoción, etc. Además de ellos, está nuestro equipo de análisis Ad-hoc separado.
Somos:
- ayudamos a las unidades de negocios con solicitudes de análisis de datos que no se ajustan a los productos existentes;
- ayudamos a los equipos de productos si necesitan manos adicionales;
- Nos dedicamos a las pruebas A / B, y esta es la función principal del equipo.
La situación en la que trabajamos es muy diferente de las pruebas A / B típicas. Típicamente, la técnica está asociada con métricas en línea y en línea: cómo los cambios afectaron la conversión, retención, CTR, etc. La mayoría de los experimentos están relacionados con cambios en la interfaz: reorganizar el banner, volver a pintar el botón, reemplazar el texto, etc.
El negocio de X5 es diferente: son 15,000 tiendas fuera de línea en vivo de varios formatos, distribuidas en todo el país. Esta característica impone ciertas limitaciones. En primer lugar, el conjunto de métricas que se pueden probar varía enormemente y, en segundo lugar, se impone la restricción de los experimentos. La tarea de cambiar el diseño de un escaparate de una tienda en línea no es comparable en términos de mano de obra a la tarea de cambiar el orden de los departamentos en las tiendas fuera de línea.
La compañía tiene un equipo que se dedica a un programa de fidelización y sus pilotos están más cerca de la idea clásica de las pruebas A / B. Las preguntas que nos llegan son muy atípicas para las pruebas A / B "ordinarias". Por ejemplo:
- ¿Cómo cambiará el rendimiento financiero de la tienda si cambio el orden de los departamentos de salchichas y pasteles?
- ¿Cómo afectará el modelo de rotación de clientes al resultado financiero?
- ¿Cómo afectará la configuración de postamatos al rendimiento de la tienda?
Los clientes creen que cierto cambio afectará positivamente a uno de los indicadores (hablaremos de ellos más adelante). Nuestro trabajo es ayudarlos a validar sus hipótesis basadas en datos.
Métricas
¿Qué indicadores estamos probando?
RTO ,
verificación promedio y
tráfico son las palabras más utilizadas en nuestro espacio abierto.
- RTO (facturación minorista): la cantidad de dinero ganada por la tienda.
Una de las principales métricas para los negocios y la más difícil de probar.
La facturación diaria de la tienda se mide en millones de rublos. En consecuencia, la propagación del indicador se mide en al menos miles de rublos. La fórmula compleja y larga para determinar el tamaño de la muestra dice que cuanto mayor es la varianza, más datos se necesitan para llegar a conclusiones significativas. Para captar el efecto incluso en el décimo por ciento con una dispersión tan grande de PTO, los pilotos en las tiendas deben pasar seis meses.
Imagine la reacción de la junta, si en una reunión con ellos dice que el piloto necesita pasar seis meses, o incluso un año en todas las tiendas. =)
Tenemos dos enfoques estándar.
El primer enfoque: no estamos considerando el RTO de toda la tienda, sino algún tipo de categoría de producto. Por ejemplo, como resultado de la reorganización de dos secciones en la tienda ("Tortas" y "Salchichas"), se espera un aumento en el PTO en ambas categorías. El RTO de una categoría es mucho más pequeño que el RTO de toda la tienda, por lo tanto, la dispersión es menor. En este caso, esperamos que el piloto en estas categorías esté aislado de las categorías restantes.
Segundo enfoque: tomamos muestras del tiempo. La unidad de observación no es el PTO de la tienda para todo el piloto, sino el PTO por semana o día. Por lo tanto, aumentamos el número de observaciones, mientras mantenemos la varianza de los datos sin procesar.
- Cheque promedio , o RTO / número de cheques : la cantidad promedio de dinero en un cheque.
Parte de los cambios tiene como objetivo hacer que las personas compren más, por lo que probamos el RTO / número de cheques, o el cheque promedio, si hacemos analogías con las métricas habituales.
La dificultad para probar esta métrica está relacionada con los detalles del comercio minorista. Por ejemplo, con el lanzamiento piloto de la promoción “3 por el precio de 2”, una persona que planeó comprar un producto compraría tres, y el monto del cheque aumentará. Pero, ¿qué pasa si más tarde tiene menos probabilidades de ir a la tienda y el piloto no tiene tanto éxito?
- Tráfico : el número de cheques en la tienda durante un cierto período de tiempo.
Para evitar conclusiones erróneas al probar hipótesis que afectan la verificación promedio, simultáneamente observamos los cambios de tráfico. No podemos rastrear directamente cuántas personas vinieron a la tienda, ya que no todos los visitantes son clientes del programa de fidelización, por lo tanto, para las pruebas A / B, cada cheque es una "visita única" al cliente. Por analogía con PTO, consideramos el tráfico en varios intervalos de tiempo: tráfico por día, tráfico por hora.
La relación entre el control promedio y el tráfico es muy importante: ¿podría el piloto aumentar el control promedio, pero reducir el tráfico y, en última instancia, no conducir a un aumento en el PTO, sino a su disminución? ¿Podría el piloto ayudar a aumentar el tráfico sin cambiar la factura promedio?
- Margen : la diferencia entre el precio de un producto y su costo
Hay pilotos en cuyo marco cambiamos los precios de los bienes: para algunos, el precio ha aumentado, para otros, por el contrario. Como no afectamos los costos de producción, al cambiar los precios, cambiamos el margen de los bienes. Tal piloto puede conducir a un aumento del tráfico y a aumentar la verificación promedio. Pero, ¿significa esto que el piloto tiene éxito y que vale la pena cambiar los precios en todas las tiendas de la red? No, bien podría suceder que la gente comenzara a comprar productos con un margen negativo o pequeño con mayor frecuencia y abandonara los productos con un margen alto. Por lo tanto, no siempre un aumento en RTO es seguido por un aumento en el margen total; por lo tanto, vale la pena probar estos indicadores por separado.
Bueno, digamos que hemos decidido las métricas objetivo. Las siguientes preguntas:
- ¿Qué efecto de tamaño planea recibir el cliente?
- ¿Qué efecto se puede detectar realmente en el experimento?
- ¿Cuánto dura el experimento?
- Que grupos
Resumen del experimento
Las pruebas A / B realizadas en usuarios en línea tienen una ventaja significativa: tienen una alta capacidad de generalización. En otras palabras, las conclusiones obtenidas durante el experimento se pueden escalar a todos los usuarios. La capacidad de generalización está garantizada por la configuración del experimento: los grupos de control y prueba se forman aleatoriamente, casi exactamente ambos grupos de la misma distribución, puede atrapar mucho tráfico en ambos grupos, habría un presupuesto.
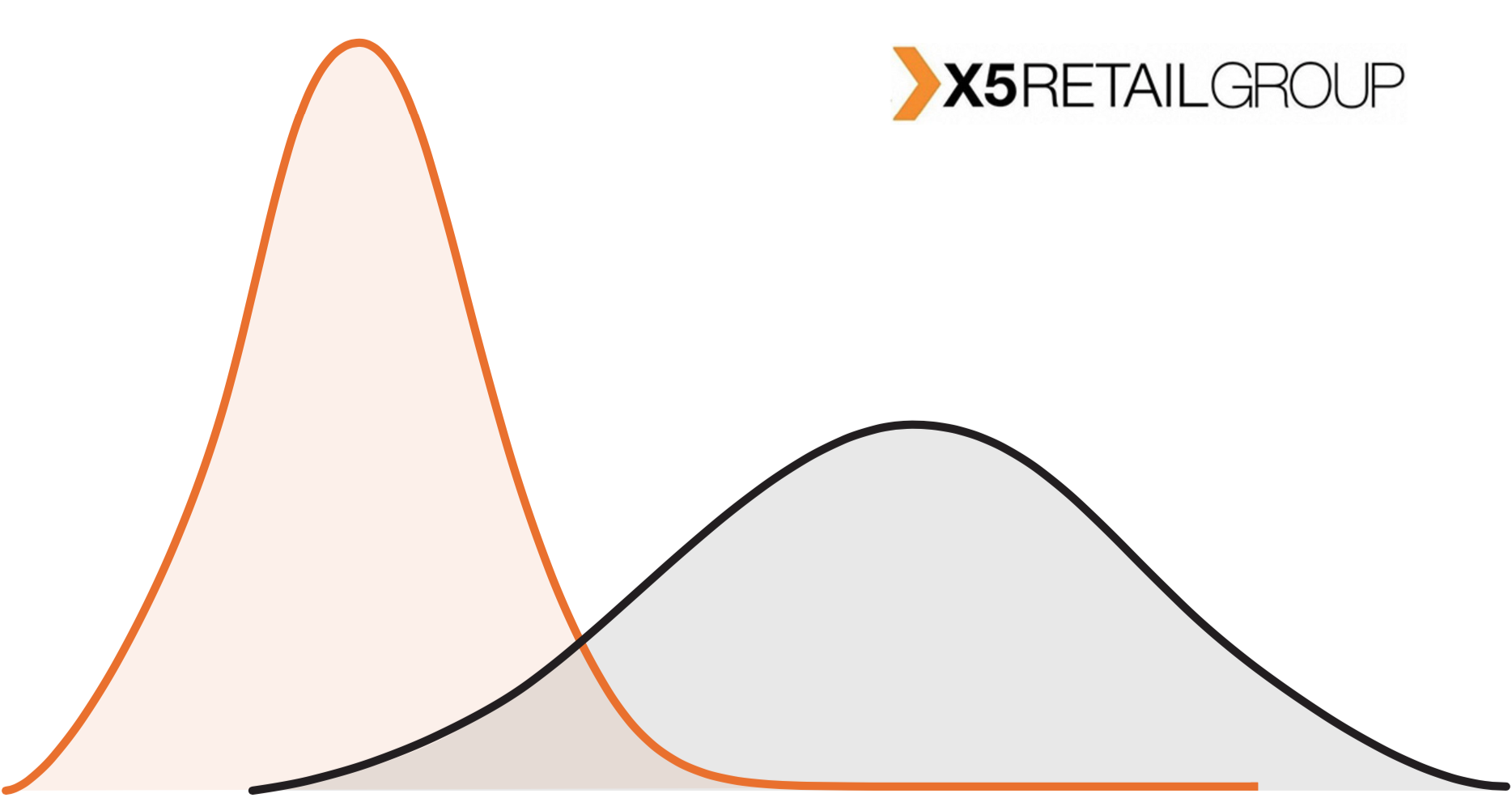
En el caso del comercio minorista sin conexión, ninguna de estas configuraciones funciona. En primer lugar, hay un límite en el número de tiendas. En segundo lugar, las tiendas son muy diferentes entre sí. La tienda Perekrestok en el área residencial y Perekrestok cerca del centro de negocios son, de hecho, objetos muy diferentes de diferentes distribuciones.

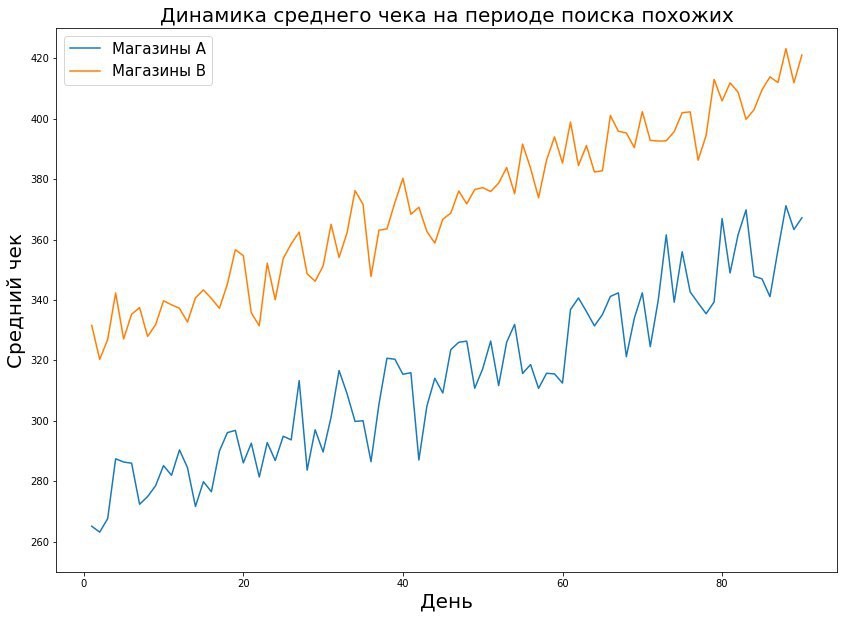
En el gráfico vemos que las tiendas del grupo de prueba son diferentes de las tiendas de toda la red. Esta es una situación bastante típica: en la cadena de tiendas Pyaterochka se encuentran no solo en las ciudades, sino también en pequeños asentamientos. Los grandes pilotos se llevan a cabo con mayor frecuencia en las ciudades. Cualquiera que sea el efecto que detectemos, escalarlo en toda la red está mal.
El efecto total
Є del piloto que evaluamos mediante la fórmula:

a es el área de intersección de las distribuciones del grupo piloto y todas las tiendas en la red.
Tenga en cuenta que esto no es una consecuencia de las leyes estadísticas, pero nuestra suposición sobre cómo es lógico considerar el efecto acumulativo.
La opción ideal es reclutar una muestra representativa para el grupo de prueba, es decir, aquellas tiendas que realmente reflejen todo el estado de la red. Pero la representatividad conduce a la heterogeneidad de la muestra, porque Se tomarán muestras de tiendas con PTO alto o bajo.
Tamaños de grupo, duración del piloto y efecto mínimo detectable
Y ahora para lo más importante: el tamaño del efecto y la duración del piloto. Como regla, nos enfrentamos a una de tres situaciones:
- el cliente tiene un límite de tiempo para el piloto y la cantidad de tiendas con las que puede trabajar;
- el cliente sabe qué tamaño de efecto espera recibir y solicita indicar la cantidad de tiendas que necesita el piloto (y luego las tiendas mismas);
- El cliente está abierto a nuestras ofertas.
No se puede decir que ninguno de los escenarios sea más simple, porque en cualquier caso estamos preparando una tabla del error de efecto.
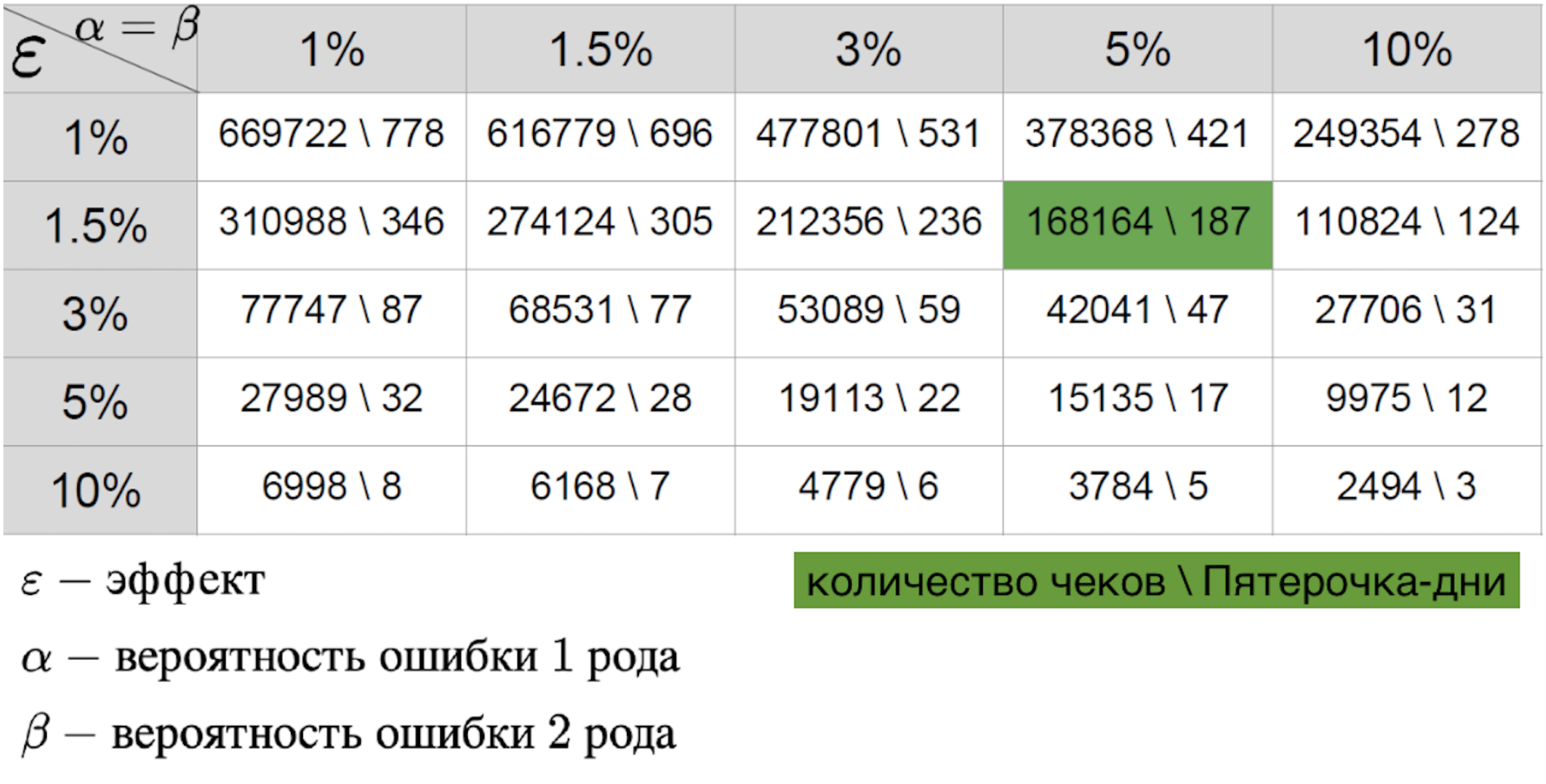
Importante para ella:
- un error del primer tipo: la probabilidad de ver el efecto cuando no está allí;
- un error del segundo tipo: la probabilidad de omitir el efecto cuando lo es;
- El tamaño del efecto que se espera ver con un piloto exitoso.
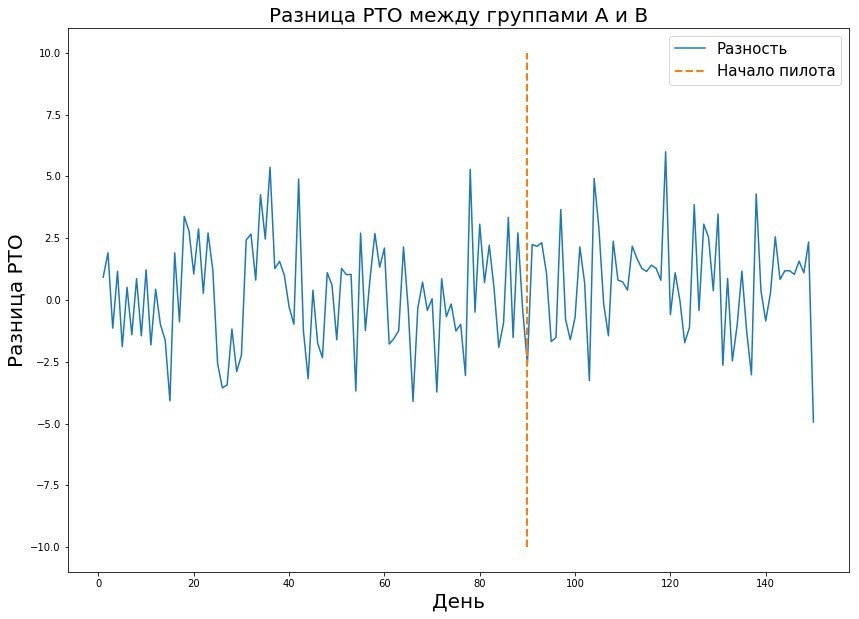
La combinación de estos tres parámetros le permite calcular la duración requerida del piloto. El valor en la tabla es el tamaño de la muestra, en este caso, el número de recibos o la métrica promedio en la tienda por día, que son necesarios para realizar el piloto. Si hablamos del mundo real, generalmente la probabilidad de errores del primer y segundo tipo es del 5-10 por ciento. Como se puede ver en la tabla, con tales errores fijos, necesitamos 421 días de Pyaterochka para captar el efecto del uno por ciento. Parece que la cifra es bastante buena: después de todo, 421 Pyaterochka-day es piloto en 40 tiendas durante 10 días. Sin embargo, hay un "pero": hay muy pocos pilotos que realmente esperan un efecto del uno por ciento. Por lo general, estamos hablando de décimas de porcentaje. Dado que el RTO se mide en miles de millones, una décima parte del porcentaje del efecto de un piloto exitoso puede generar un gran aumento en los ingresos. Debido a esto, quiero medir incluso el efecto más pequeño. Pero cuanto menor es el tamaño del efecto, mayor es el error del segundo tipo. Esto es comprensible: el pequeño efecto es similar al ruido aleatorio y rara vez se considerará una desviación real de la norma. Esto se ve claramente en el gráfico a continuación, donde queremos capturar un pequeño efecto en los datos con gran varianza.

Pruebas A / A
Antes de que comience el piloto, debe decidir sobre el grupo de prueba y control. El cliente puede o no tener un grupo piloto. Estamos listos para ayudarlo en ambos casos solicitando restricciones; por ejemplo, las tiendas deben ser estrictamente de tres regiones específicas.
Supongamos que hemos elegido de alguna manera un grupo de prueba y control. ¿Cómo asegurarse de que los grupos seleccionados son buenos y que realmente puede realizar pruebas A / B en ellos? Parece que todo suena armonioso: calificamos el número requerido de observaciones, de acuerdo con la fórmula podemos captar el efecto de 0.7%, encontramos tiendas similares. Lo que ahora no nos conviene?
Desafortunadamente, muchos hechos serios:
- los elementos de la muestra no son de la misma distribución: nuestra muestra es una mezcla de observaciones de diferentes tiendas, y cada tienda tiene su propia distribución.
- los elementos de la muestra no son independientes: en la muestra hay muchas observaciones de una tienda, respectivamente, hay una conexión entre ellas;
- la igualdad de medios no está garantizada en ausencia de un piloto, es decir no estamos del todo seguros de que si no hubiera un piloto, las estadísticas de la tienda no diferirían.
Todos estos problemas no se tienen en cuenta en el cálculo de la fórmula para seleccionar el número de observaciones dependiendo de los errores y el efecto. Para comprender el alcance del impacto de los problemas anteriores, realizamos pruebas A / A. De hecho, esta es una simulación de todo el piloto en las tiendas en un momento en que no hay piloto en las tiendas. Este período se llama pre-piloto.

Durante el período pre-piloto, repetimos tres pasos muchas veces:
- selección de grupos similares;
- prueba de igualdad en dos grupos;
- agregando efecto al grupo de prueba y probando los medios para la igualdad.

Coincidencia de grupos similares
No inventamos una bicicleta, por lo que buscamos grupos similares con el viejo método de los vecinos más cercanos. La estrategia de generar características para la tienda es un arte separado. Encontramos tres métodos de trabajo:
- Cada tienda se describe mediante un vector de características de acuerdo con la métrica que estamos probando. Por ejemplo, al examinar el cheque promedio, describimos los cheques promedio diarios durante 8 semanas; obtenemos 56 letreros para la tienda. Luego tomamos la distancia euclidiana entre los signos de un par de tiendas.
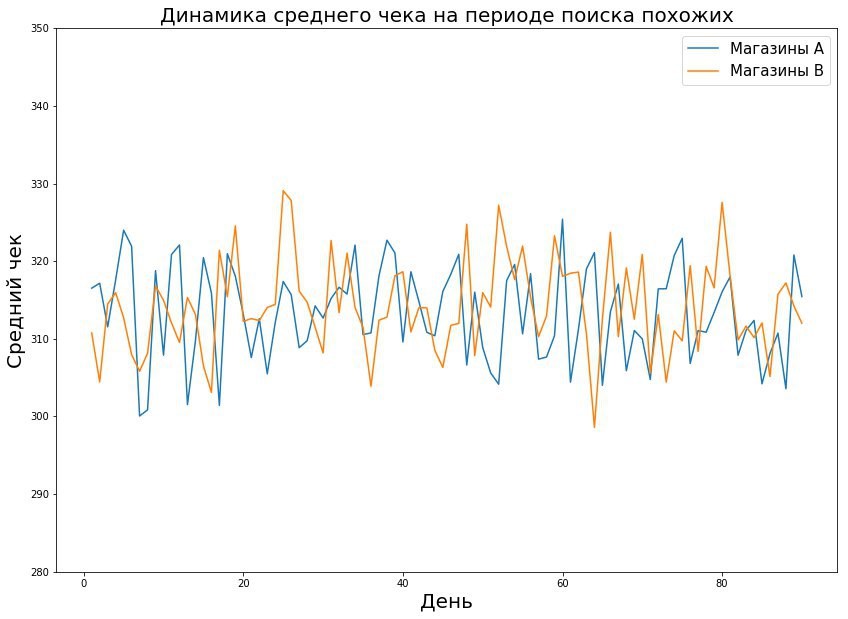
- Encuentra tiendas similares en dinámica. Las tiendas pueden diferir en los valores absolutos de las métricas, pero coinciden en las tendencias, y con ciertas manipulaciones matemáticas, estas tiendas pueden considerarse iguales.
- Predecir el rendimiento de la tienda durante el período del piloto (en el futuro) y seleccionar otros similares basados en ellos, pero aquí necesitamos un oráculo que pueda predecir el rendimiento del piloto con bastante precisión.
Nos adherimos a una hipótesis muy simple: si las tiendas fueran similares antes del piloto, si no hubiera habido un cambio piloto, habrían permanecido similares.
Puede notar que incluso en estos tres métodos de trabajo hay muchos aspectos que pueden variar: el número de días / semanas por los que se considera una característica, un método para evaluar la dinámica de un indicador, etc.
No existe una píldora universal, en cada experimento pasamos por diferentes opciones basadas en nuestro objetivo. Pero es muy simple: encuentre un método para seleccionar los vecinos más cercanos que proporcione errores razonables del primer y segundo tipo. De dónde vienen, contamos más.
Prueba de igualdad de medios, o un error del primer tipo de método
Recordemos que en este punto nosotros:
- determinó con el cliente el tamaño del efecto y la duración del piloto
- explicó la esencia de los errores del primer y segundo tipo
- construyó un método para seleccionar grupos similares
El objetivo de esta etapa es asegurarse de que el método que seleccionamos en la Sección 3 encuentre grupos que antes de que el piloto inicie el indicador (RTO, verificación promedio, tráfico) en estas tiendas no sea estadísticamente diferente.
En el ciclo, seleccionamos los grupos seleccionados repetidamente para la igualdad mediante algún tipo de prueba estadística y bootstrap. Si la proporción de errores (es decir, los grupos no son iguales entre sí) es mayor que el umbral, entonces el método se rechaza y se selecciona uno nuevo. Entonces, hasta que alcancemos el umbral de error deseado.
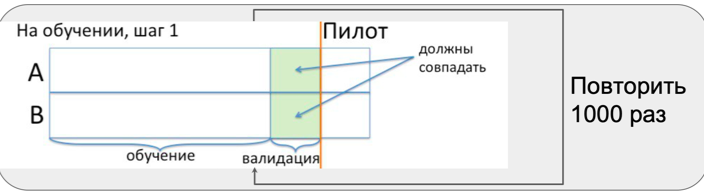
Es importante averiguar con qué frecuencia captamos el efecto cuando no está allí, es decir. si nuestro método de selección responde a diferencias aleatorias entre tiendas o no.
Agregar un efecto o un error del segundo tipo de método
Una pregunta razonable, pero ¿no nos estamos volviendo a capacitar de tal manera que también percibamos los efectos reales como ruido y los ignoremos? En otras palabras, ¿podemos detectar un efecto cuando lo es?
Después de asegurarnos en el último paso de que los grupos coinciden, agregamos un efecto artificial a uno de los grupos, es decir, Garantizamos que el piloto es exitoso y el efecto debería serlo.
Esta vez, el objetivo es descubrir con qué frecuencia se rechaza la hipótesis de igualdad, es decir, La prueba fue capaz de distinguir entre dos grupos. El error en este caso es suponer que los grupos son iguales. Llamamos a este error un error del segundo tipo.
Nuevamente en el ciclo probamos la igualdad del grupo de control y el grupo de prueba "ruidoso". Si rara vez cometemos errores, creemos que el método de selección de grupos ha pasado la validación. Se puede utilizar para seleccionar grupos en el período piloto y asegurarse de que si el piloto produce un efecto, podremos detectarlo.

Sobre la heterogeneidad
Ya hemos mencionado que la heterogeneidad de datos es uno de los peores enemigos con los que estamos luchando. Las inhomogeneidades surgen de varias causas fundamentales:
- heterogeneidad de compras: cada tienda tiene su propio valor métrico promedio (en las tiendas RTO de Moscú y el tráfico es mucho más que en las tiendas de la aldea)
- heterogeneidad por día de la semana: distribución diferente del tráfico y verificación promedio diferente en diferentes días de la semana: el tráfico del martes no se parece al tráfico del viernes
- heterogeneidad en el clima: las personas van de compras de manera diferente en diferentes condiciones climáticas
- heterogeneidad en la época del año: el tráfico en los meses de invierno difiere del tráfico en el verano; esto debe tenerse en cuenta si el piloto dura varias semanas.
La falta de homogeneidad aumenta la variación, que, como se mencionó anteriormente, en la evaluación de las tiendas de toma de fuerza ya tiene una enorme importancia. El tamaño del efecto capturado depende directamente de la varianza. Por ejemplo, reducir la dispersión en un factor de cuatro le permite detectar un efecto medio.
En el caso más simple, estamos luchando con la heterogeneidad de la linealización.
Supongamos que tenemos un piloto en dos tiendas durante tres días (sí, esto contradice todas las fórmulas prescritas sobre el tamaño del efecto, pero este es un ejemplo). Los
RTO promedio en las tiendas son, respectivamente, 200 mil y 500 mil, mientras que la variación en ambos grupos es de 10,000 y, según todas las observaciones, 35,000
Después del piloto, los promedios están en los grupos 300 y 600 y las variaciones son 10,000 y 22,500, respectivamente, y el grupo completo es 40,000.

Un movimiento simple y elegante es linealizar los datos, es decir reste del valor de cada período el promedio del anterior.

En la salida, la muestra: 100, 0, 200, -50, 100, 250. La dispersión en el período piloto se redujo en 3 veces a 13000.
Esto significa que podemos ver un efecto mucho más sutil que con los valores absolutos originales.
Esta no es la única forma de lidiar con la heterogeneidad. Hablaremos de otros en el próximo artículo.
Enfoque general de las pruebas A / B
La preparación para los grandes pilotos y su evaluación pasan por nuestro equipo y se prueban exhaustivamente.
Nuestro protocolo:
- recibir información del cliente sobre la métrica y el efecto esperado;
- determinar el tamaño de los grupos y la duración del piloto;
- desarrollar un algoritmo para la distribución de tiendas por grupos;
- realizar una prueba A / A entre grupos y validar este algoritmo;
- Espere a que el piloto termine y calcule el efecto.
Ninguna de estas etapas pasa sin dificultades; cada una de ellas tiene características. Cómo tratamos con algunos de ellos, lo describimos en este artículo. En el próximo, hablaremos de ...
El equipo
Al final, me gustaría mencionar a todos los actores:
- Valery Babushkin
- Alexander Sakhnov
- Denis Ivanov
- Sergey Demchenko
- Nikolay Nazarov
- Sergey Kabanov
- Yuri Galimullin
- Helen Tevanyan
- Vladislav Ladenkov
- Sergey Zakharov
- Vasily Stories
- Alexander Belyaev
- Kismat Magomedov
- Egor Krashennikov
- Egor Karnaukh
- Svyatoslav Oreshin
- Yuri Trubitsyn