Hoy comenzaremos a estudiar el enrutamiento OSPF. Este tema, así como la consideración del protocolo EIGRP, es el más importante a lo largo del curso CCNA. Como puede ver, la Sección 2.4 se llama “Configuración, verificación y problemas con una zona única y multizona OSPFv2 para IPv4 (excepto para autenticación, filtrado, suma manual de rutas, redistribución, área de callejón sin salida, red virtual y LSA)”.

El tema OSPF es bastante extenso, por lo que tomará 2, posiblemente 3 videos tutoriales. La lección de hoy estará dedicada al lado teórico del tema, te diré qué es este protocolo en términos generales y cómo funciona. En el siguiente video, cambiaremos al modo de configuración OSPF usando Packet Tracer.
Entonces, en esta lección veremos tres cosas: qué es OSPF, cómo funciona y qué son las zonas OSPF. En la lección anterior, dijimos que OSPF es un protocolo de enrutamiento de tipo de estado de enlace que examina los canales de comunicación entre enrutadores y toma decisiones basadas en la velocidad de estos canales. Un canal largo con una velocidad más alta, es decir, con un ancho de banda más alto, será una prioridad en comparación con un canal corto con un ancho de banda más bajo.
El protocolo RIP, que es un vector de distancia, elegirá una ruta en un salto, incluso si este canal tiene una velocidad baja, y OSPF elegirá una ruta larga de varias esperanzas si la velocidad total en esta ruta es mayor que la velocidad del tráfico en una ruta corta.

Más adelante veremos el algoritmo de toma de decisiones, por ahora debe recordar que OSPF es el protocolo de estado de enlace del estado del enlace. Este estándar abierto se creó en 1988, por lo que todos los fabricantes de equipos de red y cualquier proveedor de red podrían usarlo. Por lo tanto, OSPF es mucho más popular que EIGRP.
OSPF versión 2 solo es compatible con IPv4, y un año después, en 1989, los desarrolladores anunciaron el lanzamiento de la versión 3, que es compatible con IPv6. Sin embargo, la tercera versión totalmente funcional de OSPF para IPv6 apareció solo en 2008. ¿Por qué elegiste OSPF? En la última lección, aprendimos que este protocolo de puerta de enlace interno realiza la convergencia de rutas mucho más rápido que RIP. Este es un protocolo sin clases.
Si recuerda, RIP es un protocolo de clase, es decir, no envía información sobre la máscara de subred, y si encuentra una dirección IP de clase A / 24, no la aceptará. Por ejemplo, si le presenta una dirección IP del formulario 10.1.1.0/24, la percibirá como una red 10.0.0.0, porque no entiende cuándo una red se divide en subredes utilizando más de una máscara de subred.
OSPF es un protocolo seguro. Por ejemplo, si dos enrutadores intercambian información OSPF, puede configurar la autenticación para que pueda compartir información con un enrutador vecino solo después de ingresar la contraseña. Como dijimos, este es un estándar abierto, por lo que muchos fabricantes de equipos de red utilizan OSPF.
En un sentido global, OSPF es el mecanismo de intercambio de publicidad de estado de enlace, o LSA, link State Advertisemen. Los mensajes LSA son generados por el enrutador y contienen mucha información: un identificador único para la identificación del enrutador del enrutador, datos en redes conocidas por el enrutador, datos sobre su costo, etc. El enrutador necesita toda esta información para tomar una decisión sobre el enrutamiento.

El enrutador R3 envía su información LSA al enrutador R5, y el enrutador R5 comparte su información LSA con R3. Estas LSA son una estructura de datos que forma una base de datos de estado de enlace, o LSDB, base de datos de estados de enlace. El enrutador recopila todos los LSA recibidos y los coloca en su LSDB. Después de que ambos enrutadores hayan creado sus propias bases de datos, intercambian mensajes de saludo, que se utilizan para descubrir vecinos, y comienzan el procedimiento de comparación de sus LSDB.
El enrutador R3 envía un mensaje DBD, o "descripción de la base de datos", a R5, y R5 envía su DBD a R3. Estos mensajes contienen los índices LSA que se encuentran en las bases de cada enrutador. Después de recibir un DBD, R3 envía una solicitud de estado de red LSR a R5, que dice: "Ya tengo los mensajes 3.4 y 9, así que envíeme solo 5 y 7".
R5 hace exactamente lo mismo, diciéndole al tercer enrutador: "Tengo información 3,4 y 9, así que envíeme 1 y 2". Al recibir las solicitudes de LSR, los enrutadores envían paquetes de actualización de estado de red de LSU, es decir, en respuesta a su LSR, el tercer enrutador recibe la LSU del enrutador R5. Después de que los enrutadores actualicen sus bases de datos, todos ellos, incluso si tiene 100 enrutadores, tendrán el mismo LSDB. Tan pronto como se creen las bases de datos LSDB en los enrutadores, cada una de ellas conocerá toda la red en su conjunto. El protocolo OSPF utiliza el algoritmo Primero la ruta más corta para crear una tabla de enrutamiento, por lo que la condición más importante para su correcto funcionamiento es la sincronización del LSDB de todos los dispositivos en la red.

El diagrama anterior contiene 9 enrutadores, cada uno de los cuales intercambia mensajes LSR, LSU, etc. con los vecinos. Todos ellos están conectados entre sí como p2p, o interfaces punto a punto que admiten el protocolo OSPF, e interactúan entre sí para crear el mismo LSDB.

Tan pronto como se sincronizan las bases de datos, cada enrutador, utilizando el algoritmo de ruta más corta, forma su propia tabla de enrutamiento. Diferentes enrutadores tendrán diferentes tablas. Es decir, todos los enrutadores usan el mismo LSDB, pero crean tablas de enrutamiento basadas en sus propias consideraciones sobre las rutas más cortas. Para usar este algoritmo, OSPF necesita actualizaciones periódicas de la base de datos LSDB.
Entonces, para su propio funcionamiento, OSPF primero debe proporcionar 3 condiciones: encontrar vecinos, crear y actualizar LSDB, y crear una tabla de enrutamiento. Para cumplir con la primera condición, el administrador de red puede necesitar configurar manualmente la identificación del enrutador, los tiempos o la máscara comodín. En el siguiente video, consideraremos cómo configurar el dispositivo para que funcione con OSPF, hasta ahora debe saber que este protocolo usa una máscara inversa, y si no coincide, si sus subredes no coinciden o la autenticación no coincide, la vecindad de los enrutadores no se formará. Por lo tanto, al solucionar problemas de OSPF, debe averiguar por qué no se forma este vecindario, es decir, verificar que los parámetros anteriores coincidan.
Como administrador de red, no está involucrado en el proceso de creación de una LSDB. Las bases de datos se actualizan automáticamente después de crear una vecindad de enrutadores, así como de crear tablas de enrutamiento. Todo esto lo hace el propio dispositivo, que está configurado para funcionar con el protocolo OSPF.
Veamos un ejemplo. Tenemos 2 enrutadores, para los cuales he asignado identificadores RID 1.1.1.1 y 2.2.2.2 por simplicidad. Tan pronto como los conectemos, el canal de enlace pasará inmediatamente al estado activo, porque primero configuré estos enrutadores para que funcionen con OSPF. Tan pronto como se forma el canal de comunicación, el enrutador A enviará inmediatamente el segundo paquete de saludo. Este paquete contendrá información que este enrutador no ha "visto" a nadie en este canal, porque envía Hello por primera vez, así como su propio identificador, datos sobre la red conectada a él y otra información que puede compartir con un vecino.

Una vez recibido este paquete, el enrutador B dirá: "Veo que en este canal de comunicación hay un candidato potencial para la vecindad OSPF" y cambiará al estado inicial Estado inicial. El paquete de saludo no es un mensaje de difusión única o de difusión, es un paquete de difusión múltiple enviado a la dirección IP de multidifusión de OSPF 224.0.0.5. Algunas personas preguntan qué es una máscara de subred para una multidifusión. El hecho es que una multidifusión no tiene una máscara de subred, se distribuye como una señal de radio que es escuchada por todos los dispositivos sintonizados a su frecuencia. Por ejemplo, si desea escuchar una transmisión de radio FM a una frecuencia de 91.0, sintonice su radio a esta frecuencia.
Del mismo modo, el enrutador B está configurado para recibir mensajes para la dirección de multidifusión 224.0.0.5. Al escuchar este canal, recibe el paquete Hello enviado por el enrutador A y le responde con su mensaje.

Además, el vecindario se puede establecer solo si la respuesta B satisface un conjunto de criterios. El primer criterio: la frecuencia de envío de mensajes de saludo y el intervalo de espera de una respuesta a este mensaje de intervalo muerto debe coincidir para ambos enrutadores. Normalmente, el intervalo muerto es igual a varios valores del temporizador de saludo. Por lo tanto, si el temporizador de saludo del enrutador A es de 10 s, y el enrutador B le envía un mensaje después de 30 s con un intervalo muerto igual a 20 s, el vecindario no tendrá lugar.
El segundo criterio es que ambos enrutadores deben usar el mismo tipo de autenticación. En consecuencia, las contraseñas de autenticación también deben coincidir.
El tercer criterio es la coincidencia de los identificadores de zona Arial ID, el cuarto es la coincidencia de la longitud del prefijo de red. Si el enrutador A informa el prefijo / 24, entonces el enrutador B también debe tener un prefijo de red / 24. En el siguiente video, consideraremos esto con más detalle, por ahora notaré que esta no es una máscara de subred, aquí los enrutadores usan la máscara de comodín inversa. Y, por supuesto, las banderas de la zona de código auxiliar del área Stub también deben coincidir si los enrutadores están en esta zona.
Después de verificar estos criterios, si coinciden, el enrutador B envía su paquete de saludo al enrutador A. A diferencia del mensaje A, el enrutador B informa que vio el enrutador A y se presenta.

En respuesta a este mensaje, el enrutador A envía nuevamente Hello al enrutador B, en el que confirma que también vio el enrutador B, el canal de comunicación entre ellos consiste en los dispositivos 1.1.1.1 y 2.2.2.2, y es el dispositivo 1.1.1.1. Esta es una etapa muy importante para establecer un vecindario. En este caso, se utiliza una conexión bidireccional de 2 VÍAS, pero ¿qué sucede si tenemos un conmutador con una red distribuida de 4 enrutadores? En dicho entorno "compartido", uno de los enrutadores debe desempeñar el papel de un enrutador dedicado DR designado del enrutador, y el segundo - un enrutador dedicado de respaldo Enrutador designado de respaldo, BDR

Cada uno de estos dispositivos formará una conexión Completa, o un estado de adyacencia completa, luego consideraremos qué es, sin embargo, una conexión de este tipo se establecerá solo con DR y BDR, los dos enrutadores inferiores D y B aún se comunicarán entre sí de acuerdo con el esquema de conexión bidireccional Punto a punto
Es decir, con DR y BDR, todos los enrutadores establecen una relación de proximidad completa y una conexión punto a punto entre sí. Esto es muy importante, porque cuando se conectan los dispositivos adyacentes de forma bidireccional, todos los parámetros del paquete Hello deben coincidir. En nuestro caso, todo coincide, por lo que los dispositivos forman un vecindario sin problemas.
Tan pronto como se establece la comunicación bidireccional, el enrutador A envía al enrutador B el paquete de Descripción de la base de datos, o la "descripción de la base de datos", y cambia al estado ExStart: el comienzo del intercambio, o esperando la descarga. El Descriptor de la base de datos es información similar a la tabla de contenido del libro; esta es una enumeración de todo lo que está disponible en la base de datos de enrutamiento. En respuesta, el enrutador B envía su descripción de la base de datos al enrutador A y entra en el estado de intercambio de datos en los canales de Exchange. Si en el estado de Exchange, el enrutador detecta que hay información en su base de datos, pasará al estado de arranque LOADING y comenzará a intercambiar mensajes LSR, LSU y LSA con el vecino.

Entonces, el enrutador A envía un LSR a un vecino, responderá con un paquete LSU, a lo que el enrutador A responderá al enrutador B con un mensaje LSA. Este intercambio ocurrirá tantas veces como la cantidad de veces que el dispositivo quiera intercambiar mensajes LSA. Un estado CARGANDO significa que aún no se ha producido una actualización completa de la base de datos LSA. Después de descargar todos los datos, ambos dispositivos entrarán en el estado de adyacencia COMPLETO.
Observo que con una conexión bidireccional, el dispositivo está simplemente en el estado de proximidad, y el estado de adyacencia completa solo es posible entre enrutadores, DR y BDR. Esto significa que cada enrutador informa al DR sobre los cambios en la red, y todos los enrutadores se enteran de estos cambios desde el DR
La elección de DR y BDR es un tema importante. Considere cómo la selección de DR en un entorno común. Supongamos que en nuestro circuito hay tres enrutadores y un interruptor. Primero, los dispositivos OSPF comparan la prioridad en los mensajes de saludo, luego comparan la ID del enrutador.
El dispositivo con la prioridad más alta se convierte en DR. Si las prioridades de los dos dispositivos coinciden, entonces, de los dos dispositivos, se selecciona el dispositivo con la ID de enrutador más alta, que se convierte en DR
Un dispositivo con la segunda prioridad más alta o la segunda ID de enrutador más importante se convierte en el enrutador BDR dedicado de respaldo. Si el DR falla, será reemplazado inmediatamente por BDR. Comenzará a desempeñar el papel de DR y el sistema elegirá otro BDR.

Espero que hayas descubierto la elección de DR y BDR; si no, volveré a este tema en uno de los siguientes videos y explicaré este proceso.
Entonces, observamos qué es Hello, una descripción del Descriptor de la base de datos y los mensajes LSR, LSU y LSA. Antes de pasar al siguiente tema, hablemos un poco sobre el costo de OSPF.

En Cisco, el costo de una ruta se calcula utilizando la fórmula para la relación del ancho de banda Ancho de banda de referencia, que de forma predeterminada se establece en 100 Mbps, al costo del canal. Por ejemplo, cuando se conectan dispositivos a través de un puerto serie, la velocidad es de 1.544 Mb / sy el costo es de 64. Cuando se usa una conexión Ethernet con una velocidad de 10 Mb / s, el costo es de 10 y el costo de una conexión FastEthernet con una velocidad de 100 Mb / s será de 1.
Cuando usamos Gigabit Ethernet, tenemos una velocidad de 1000 Mbps, pero en este caso siempre se supone que la velocidad es 1. Por lo tanto, si tiene Gigabit Ethernet en su red, debe cambiar el valor predeterminado Ref. BW por 1000. En este caso, el costo será 1, y toda la tabla se volverá a calcular con un aumento del valor de 10 veces. Después de formar el vecindario y construir la base de datos LSDB, procedemos a la construcción de la tabla de enrutamiento.

Después de recibir el LSDB, cada uno de los enrutadores procede de forma independiente a formar una lista de rutas utilizando el algoritmo SPF. En nuestro esquema, el enrutador A creará dicha tabla por sí mismo. Por ejemplo, calcula el costo de la ruta A-R1 y determina que es igual a 10. Para simplificar la comprensión del esquema, suponga que el enrutador A determina la ruta óptima al enrutador B. El costo de la conexión A-R1 es 10, la conexión A-R2 es 100 y el costo de la ruta A-R3 es 11, es decir, la suma de la ruta A-R1 (10) y R1-R3 (1).
Si el enrutador A quiere llegar al enrutador R4, puede hacerlo a lo largo de la ruta A-R1-R4 o a lo largo de la ruta A-R2-R4, y en ambos casos el costo de las rutas será el mismo: 10 + 100 = 100 + 10 = 110. La ruta A-R6 costará 100 + 1 = 101, que ya es mejor. A continuación, consideramos la ruta al enrutador R5 a lo largo de la ruta A-R1-R3-R5, cuyo costo será 10 + 1 + 100 = 111.
La ruta al enrutador R7 se puede establecer a lo largo de dos rutas: A-R1-R4-R7 o A-R2-R6-R7. El costo del primero será 210, el segundo - 201, por lo que debe elegir 201. Entonces, para llegar al enrutador B, el enrutador A puede usar 4 rutas.

El costo de la ruta A-R1-R3-R5-B será 121. La ruta A-R1-R4-R7-B costará 220. La ruta A-R2-R4-R7-B cuesta 210, y A-R2-R6-R7- B tiene un costo de 211. En base a esto, el enrutador A selecciona la ruta con el costo más bajo igual a 121 y la coloca en la tabla de enrutamiento. Este es un diagrama muy simplificado de cómo funciona el algoritmo SPF. De hecho, la tabla no solo contiene las designaciones de los enrutadores a través de los cuales se ejecuta la ruta óptima, sino también las designaciones de los puertos que los conectan y toda la información necesaria.
Considere otro tema que concierne a las zonas de enrutamiento. Por lo general, al configurar dispositivos OSPF de una empresa, todos se encuentran en una zona común.

¿Qué sucede si un dispositivo conectado al enrutador R3 falla repentinamente? El enrutador R3 comenzará inmediatamente a enviar un mensaje a los enrutadores R5 y R1 de que el canal con este dispositivo ya no funciona, y todos los enrutadores comenzarán a intercambiar actualizaciones sobre este evento.
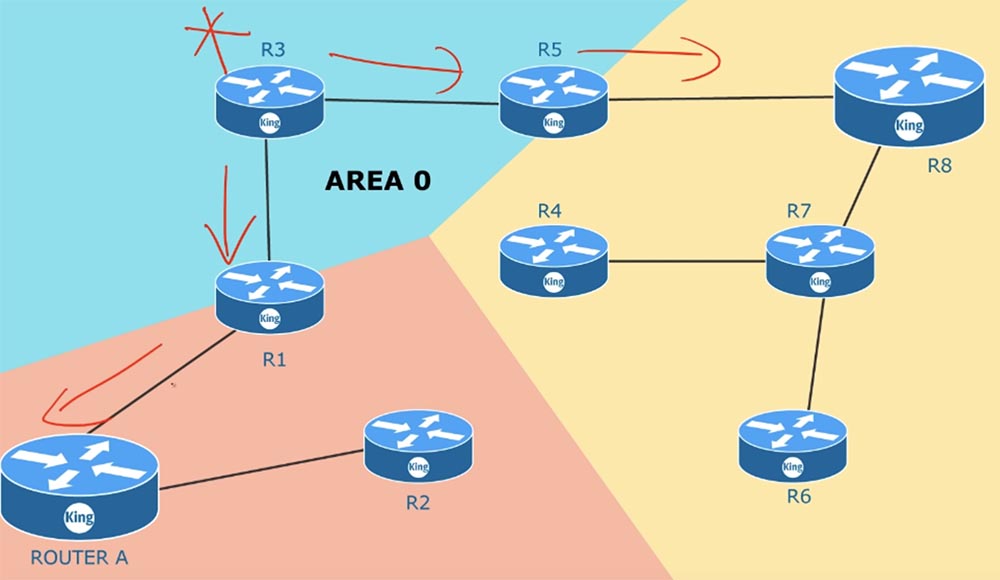
Si tiene 100 enrutadores, todos ellos actualizarán la información sobre el estado de los canales, ya que están en la misma zona común. Lo mismo sucederá si falla uno de los enrutadores vecinos: todos los dispositivos de la zona intercambiarán actualizaciones de LSA. Después de intercambiar tales mensajes, la topología de la red cambiará. Una vez que esto sucede, el SPF volverá a calcular las tablas de enrutamiento de acuerdo con las condiciones cambiadas. Este es un proceso muy largo, y si tiene miles de dispositivos en una zona, debe controlar el tamaño de la memoria de los enrutadores para que sea suficiente almacenar todos los LSA y una gran base de datos del estado del canal LSDB. Tan pronto como se producen cambios en una parte de la zona, el algoritmo SPF recalcula inmediatamente las rutas. Por defecto, el LSA se actualiza cada 30 minutos. Este proceso no ocurre simultáneamente en todos los dispositivos, sin embargo, en cualquier caso, cada enrutador realiza actualizaciones con una frecuencia de 30 minutos. Más dispositivos de red. Cuanta más memoria y tiempo se tarda en actualizar el LSDB.
Puede resolver este problema si divide una zona común en varias zonas separadas, es decir, utiliza la zonificación múltiple. Para hacer esto, debe tener un plan o diagrama de toda la red que administra. La zona cero AREA 0 es su zona principal. Este es el lugar donde se conecta a una red externa, por ejemplo, acceso a Internet. Al crear nuevas zonas, debe guiarse por la regla: cada zona debe tener un ABR, enrutador de borde de área. El enrutador de borde tiene una interfaz en una zona y una segunda interfaz en otra zona. Por ejemplo, el enrutador R5 tiene interfaces en la zona 1 y la zona 0. Como dije, cada una de las zonas debe estar conectada a la zona cero, es decir, tener un enrutador de borde, una de las cuales está conectada a AREA 0.
 Suponga que la conexión R6-R7 está fuera de servicio. En este caso, la actualización LSA se distribuirá solo en la zona AREA 1 y solo se referirá a esta zona. Los dispositivos en la zona 2 y la zona 0 ni siquiera lo sabrán. El enrutador de borde R5 resume la información sobre lo que está sucediendo en su zona y envía a la zona principal AREA 0 la información total sobre el estado de la red. Los dispositivos en una zona no necesitan estar al tanto de todos los cambios de LSA dentro de otras zonas, porque el enrutador ABR reenviará información resumida sobre las rutas de una zona a otra.Si no tiene completamente claro el concepto de zonas, puede encontrar más información en la próxima lección cuando vamos a configurar el enrutamiento OSPF y considerar algunos ejemplos.
Suponga que la conexión R6-R7 está fuera de servicio. En este caso, la actualización LSA se distribuirá solo en la zona AREA 1 y solo se referirá a esta zona. Los dispositivos en la zona 2 y la zona 0 ni siquiera lo sabrán. El enrutador de borde R5 resume la información sobre lo que está sucediendo en su zona y envía a la zona principal AREA 0 la información total sobre el estado de la red. Los dispositivos en una zona no necesitan estar al tanto de todos los cambios de LSA dentro de otras zonas, porque el enrutador ABR reenviará información resumida sobre las rutas de una zona a otra.Si no tiene completamente claro el concepto de zonas, puede encontrar más información en la próxima lección cuando vamos a configurar el enrutamiento OSPF y considerar algunos ejemplos.Gracias por quedarte con nosotros. ¿Te gustan nuestros artículos? ¿Quieres ver más materiales interesantes?
Apóyenos haciendo un pedido o recomendándolo a sus amigos, un
descuento del 30% para los usuarios de Habr en un análogo único de servidores de nivel de entrada que inventamos para usted: toda la verdad sobre VPS (KVM) E5-2650 v4 (6 núcleos) 10GB DDR4 240GB SSD 1Gbps de $ 20 o cómo dividir el servidor? (las opciones están disponibles con RAID1 y RAID10, hasta 24 núcleos y hasta 40GB DDR4).
Dell R730xd 2 veces más barato? ¡Solo tenemos
2 x Intel TetraDeca-Core Xeon 2x E5-2697v3 2.6GHz 14C 64GB DDR4 4x960GB SSD 1Gbps 100 TV desde $ 199 en los Países Bajos! Dell R420 - 2x E5-2430 2.2Ghz 6C 128GB DDR3 2x960GB SSD 1Gbps 100TB - ¡desde $ 99! Lea sobre
Cómo construir un edificio de infraestructura. clase utilizando servidores Dell R730xd E5-2650 v4 que cuestan 9,000 euros por un centavo?