¿Por qué incluso queremos escribir código competitivo? Porque los procesadores dejaron de crecer a lo largo de las inmersiones y comenzaron a crecer a lo largo de los núcleos. La cantidad de núcleos de procesador aumenta cada año, y queremos utilizarlos de manera efectiva. Ir es el lenguaje creado para esto. La documentación lo dice.
Tomamos Go, comenzamos a escribir código competitivo. Por supuesto, esperamos que podamos frenar fácilmente la potencia de cada núcleo de nuestro procesador. Es asi?
Me llamo Artemy. Esta publicación es una transcripción gratuita de mi charla con GopherCon Rusia. Apareció como un intento de dar impulso a las personas que quieren descubrir cómo escribir un código bueno y competitivo.
Video de la conferencia GopherCon Rusia
Modelos de interacción
Para comprender si Go realmente nos lo facilita, veamos dos modelos de interacción: Memoria compartida y Transmisión de mensajes .

La memoria compartida se trata de la memoria compartida que utilizan varios subprocesos para intercambiar datos. El acceso a la memoria debe estar sincronizado. Esta sincronización generalmente se implementa mediante algún tipo de bloqueos. Este enfoque se considera comunicación implícita.
El paso de mensajes dice que interactuaremos explícitamente, y para esto utilizaremos los canales en los que enviaremos mensajes. El CSP ( procesos secuenciales de comunicación ) y el modelo de actor se basan en este enfoque.

Rob Pike , quien es el padre fundador de Go, dice que debe abandonar la programación de bajo nivel utilizando la memoria compartida y utilizar el enfoque de paso de mensajes . Este enfoque lo ayudará a escribir código de manera más fácil, más eficiente y, lo más importante, con menos errores. Go elige el enfoque CSP . El mismo enfoque influyó mucho en el desarrollo de un lenguaje como Erlang.
Pregunta: ¿Es cierto que si tomamos Go, todo estará bien?

Me encontré con un estudio en el que se encontró esta tableta. La tableta muestra los motivos y la cantidad de errores relacionados con las cerraduras. La primera columna muestra los productos que se tomaron en el estudio. Estos son los productos más populares escritos en Go. La columna Memoria compartida muestra el número de errores que surgen debido al uso incorrecto de la Memoria compartida, y la columna Paso de mensaje, respectivamente, muestra el número de errores debido al Paso de mensaje.
Lo más importante en este plato es la línea Total . Si lo mira, notará que hay más errores al usar Pasar mensajes que al usar Memoria compartida . Estoy seguro de que las personas que escriben Kubernetes, Docker o etcd son desarrolladores bastante experimentados, pero incluso su Pase de mensajes no se salva de errores, y no hay menos que estos errores que con la Memoria compartida.
Por lo tanto, tomar Go y comenzar a escribir código sin errores fallará.
Concurrencia y paralelismo
Cuando comenzamos a hablar sobre el desarrollo de subprocesos múltiples, necesitamos introducir conceptos como Concurrencia y Paralelismo . En el mundo de Go, existe la expresión "La concurrencia no es paralelismo" . La conclusión es que la concurrencia se trata de diseño, es decir, cómo diseñamos nuestro programa. El paralelismo es solo una forma de ejecutar nuestro código.

Si tenemos varios hilos de instrucciones que se ejecutan simultáneamente, entonces ejecutamos el código en paralelo. El paralelismo requiere competencia. No será posible paralelizar un programa sin un diseño competitivo, mientras que la competitividad no requiere paralelismo, porque un programa que puede funcionar en muchos núcleos, de hecho, puede funcionar en un núcleo.
Go es un lenguaje que nos ayuda a escribir programas competitivos, nos ayuda a construir diseño. Le permite pensar un poco menos sobre cosas de bajo nivel.
Ley de Amdahl
Queremos utilizar los núcleos del procesador, escribimos un código para esto. Pero surge la pregunta: qué tipo de aumento en la productividad obtenemos con un aumento en el número de núcleos. Entonces, la aceleración que podemos obtener está, de hecho, limitada por la ley de Amdal .
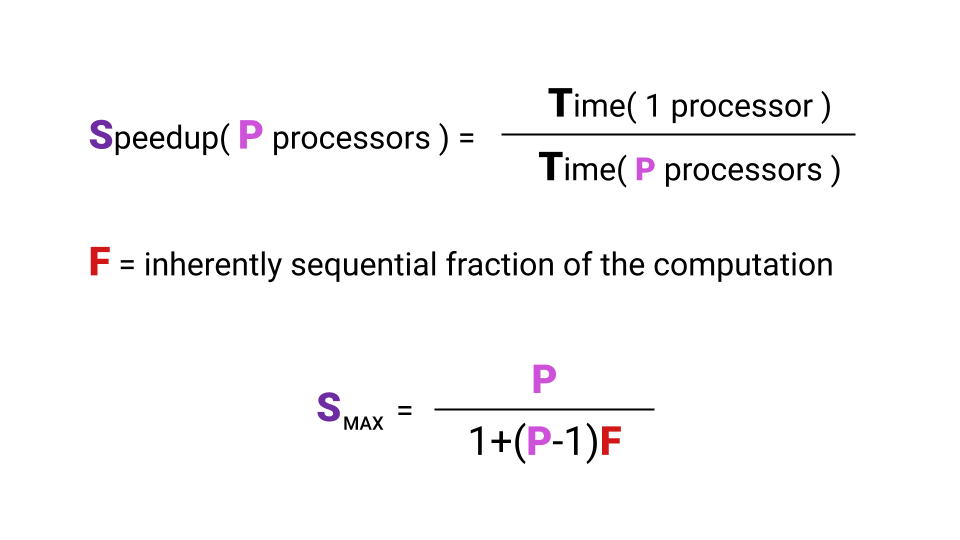
¿Qué es la aceleración? La aceleración es el tiempo que un programa se ejecuta en un único procesador dividido por el tiempo que un programa se ejecuta en procesadores P. La letra F ( Fracción ) denota la parte del programa que debe ejecutarse secuencialmente. Y aquí ni siquiera es necesario profundizar en la fórmula, lo principal es tener en cuenta que la aceleración máxima que obtenemos con un aumento en el número de núcleos depende de F. Echa un vistazo a la gráfica para visualizar esta relación.
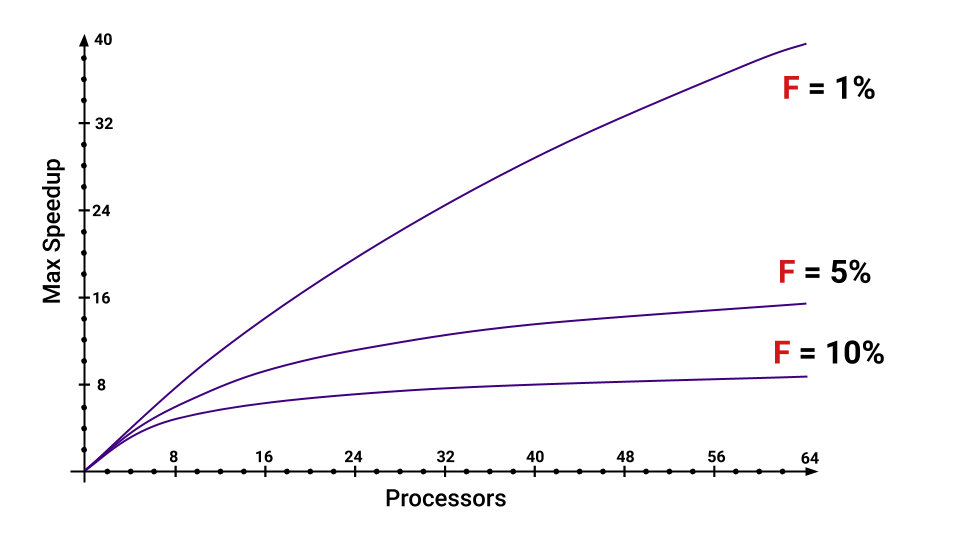
Incluso si solo tenemos el 5% del programa que se ejecutará secuencialmente, la aceleración máxima que obtenemos disminuirá considerablemente con un aumento en el número de núcleos. Puedes estimar cuáles son las partes que aumentan F.
CPU enlazada vs E / S enlazada
No siempre tiene sentido usar subprocesos múltiples. Primero debes mirar el tipo de carga. Hay dos tipos de carga: CPU Bound y I / O Bound . La diferencia es que con CPU Bound estamos limitados por el rendimiento del procesador, y con I / O Bound estamos limitados por la velocidad de nuestro subsistema de E / S. Ni siquiera la velocidad, sino el tiempo de espera de una respuesta. Conectarse en línea, esperando una respuesta, yendo al disco, nuevamente esperando una respuesta. ¿Cuál es la diferencia, cuántos núcleos hay, si la mayoría de las veces esperamos una respuesta?
Por lo tanto, un núcleo o mil, no obtendremos un aumento en el rendimiento bajo la carga limitada de E / S. Pero si tenemos una carga CPU Bound, entonces existe la posibilidad de acelerar cuando paralelizamos nuestro programa.
Aunque hay situaciones en las que se carga la CPU Bound aparente, en realidad degenera en una E / S Bound. Si, por ejemplo, queremos tomar y sumar todos los elementos de una gran matriz, ¿qué haremos? Escribiremos un ciclo, todo funcionará. Luego pensamos: “Entonces tenemos un montón de núcleos. Vamos a tomarlo, dividir la matriz en trozos y paralelizar todo ”. ¿Cuál será el resultado?
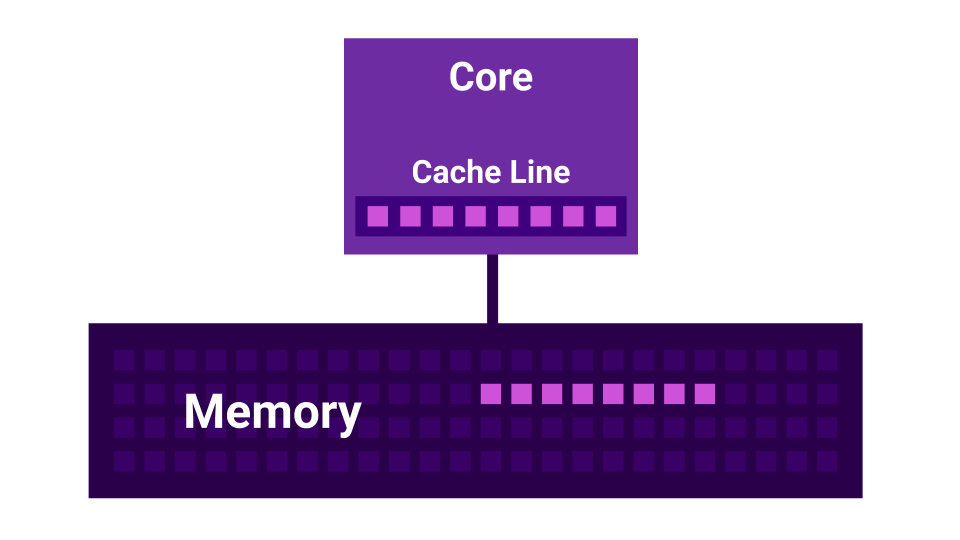
El resultado es una situación en la que nuestro procesador procesa datos más rápido de lo que logran venir de la memoria. En este caso, la mayoría de las veces esperamos los datos de la memoria, y la carga, que parecía estar unida a la CPU, en realidad resulta estar unida a la E / S.
Intercambio falso
Además, hay una historia como False Sharing . False Sharing es una situación en la que los núcleos comienzan a interferir entre sí. Hay un primer núcleo, hay un segundo núcleo, y cada uno de ellos tiene su propia caché L1 . La caché L1 se divide en líneas ( línea de caché ) de 64 bytes. Cuando obtenemos algunos datos de la memoria, siempre obtenemos no menos de 64 bytes. Al cambiar estos datos, deshabilitamos las memorias caché de todos los núcleos.

Resulta que si dos núcleos cambian datos muy cercanos entre sí ( a una distancia de menos de 64 bytes ), comienzan a interferir entre sí, invalidando las memorias caché. En este caso, si el programa se escribiera secuencialmente, funcionaría más rápido que cuando se usan varios núcleos que interfieren entre sí. Cuantos más núcleos, menor es el rendimiento.
Programadores
Nos elevaremos al siguiente nivel de abstracción: a los planificadores.
Cuando el trabajo comienza con un código competitivo, aparecen los planificadores. Go tiene un llamado planificador de espacio de usuario que opera en goroutines . El sistema operativo también tiene su propio programador , que funciona con subprocesos del sistema operativo . E incluso el procesador no es tan simple. Por ejemplo, los procesadores modernos tienen predicción de ramas y otras formas de estropear nuestra hermosa imagen de la linealización del mundo.
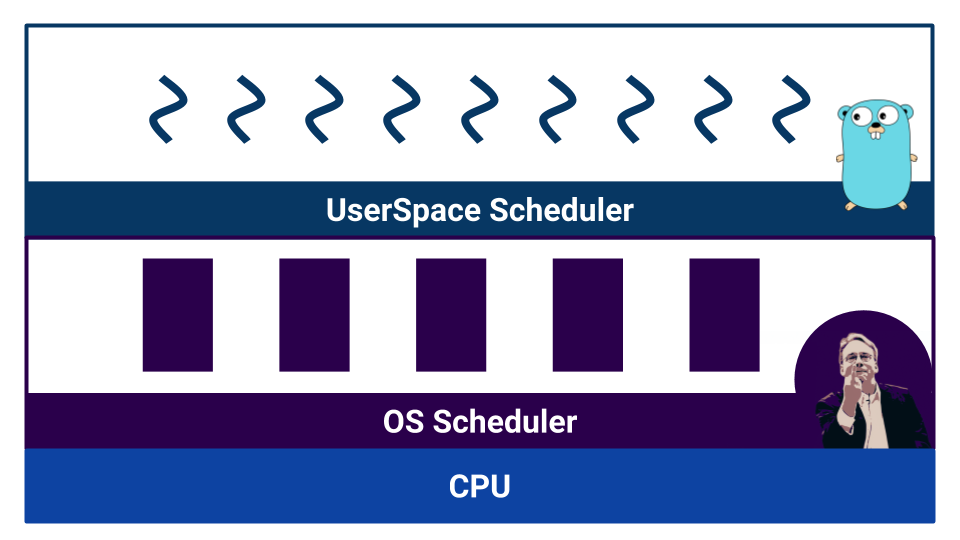
Los programadores se dividen por tipo de multitarea. Hay multitarea cooperativa y multitarea preventiva . En el caso de la multitarea cooperativa , el proceso de ejecución en sí mismo decide cuándo necesita transferir el control a otro proceso, y en el caso de la multitarea abarrotada, hay un componente externo : el planificador, que controla la cantidad de recursos asignados al proceso.

La multitarea cooperativa permite que un proceso "monopolice" todo el recurso de la CPU. En la multitarea preventiva, esto no sucederá, porque hay un organismo controlador. Pero con la multitarea cooperativa, el cambio de contexto es más eficiente, porque el proceso sabe con certeza en qué momento es mejor dar el control a otro proceso. En la multitarea preventiva, el planificador puede detener el proceso en cualquier momento; no es muy eficiente. Al mismo tiempo, en la multitarea preventiva, podemos proporcionar el mismo recurso para cada proceso gracias a un planificador externo.
El sistema operativo utiliza un planificador basado en la multitarea preventiva, ya que el sistema operativo es necesario para garantizar condiciones iguales para cada usuario. ¿Qué hay de ir?
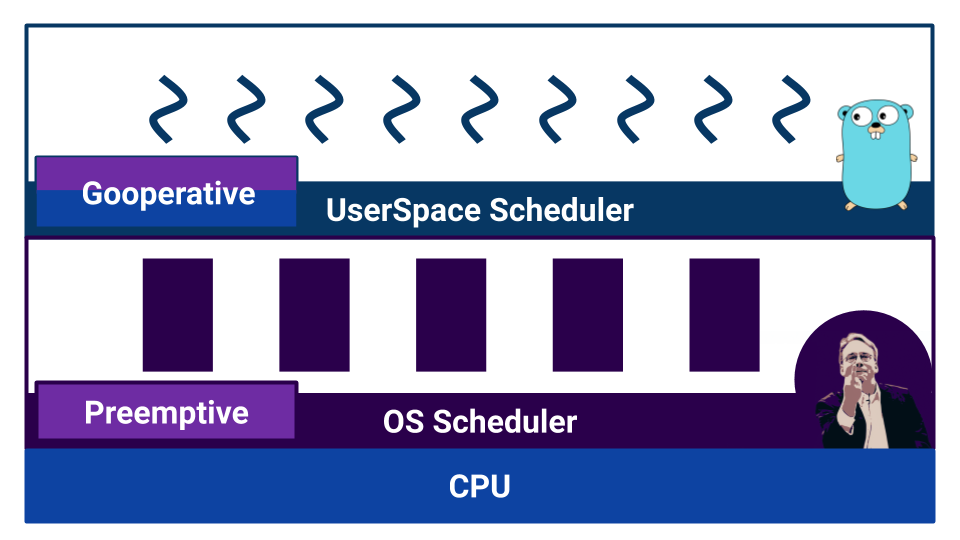
Si leemos la documentación, aprendemos que el planificador en Go es preventivo. Pero, cuando comenzamos a entender, resulta que Go no tiene un planificador como componente externo. En Go, el compilador establece puntos de cambio de contexto. Y aunque nosotros, como desarrolladores, no necesitamos cambiar manualmente el contexto, el control de cambio no se lleva al componente externo. Gracias a esto, Go es muy efectivo para cambiar una gorutina a otra. Pero un malentendido de las características del trabajo de tal "planificador" puede conducir a un comportamiento inesperado. Por ejemplo, ¿qué generará este código?

Tal código se congelará.
Por qué Porque al principio, usando GOMAXPROCS , GOMAXPROCS al programa a usar solo un núcleo. Después de eso, se puso a la rutina en la cola, dentro de la cual debería funcionar un ciclo interminable. Luego esperamos 500 ms e imprimimos x . Después del time.Sleep Dormir time.Sleep rutina comenzará realmente, pero no habrá forma de salir del bucle infinito, porque el compilador no pondrá el punto de cambio de contexto. El programa se congela.
Y si agregamos runtime.Gosched() dentro del bucle, entonces todo estará bien, porque runtime.Gosched() explícitamente que queremos cambiar el contexto.
Tales características también necesitan saber y recordar.
Hablamos sobre el cambio de contexto, pero ¿dónde suele insertar Go los puntos de cambio?

runtime.morestack() y runtime.newstack() generalmente se insertan en el momento en que se llama a la función. runtime.Goshed() podemos suministrarnos nosotros mismos. Y, por supuesto, el cambio de contexto ocurre durante bloqueos, subidas de red y llamadas al sistema. Puedes ver este tema en un informe de Kirill Lashkevich . Muy bien, te aconsejo.
Vayamos más cerca del código. Veremos los errores.
Condición de carrera
Uno de los errores más populares que cometemos es la Race Condition . La conclusión es que cuando hacemos, por ejemplo, un incremento, de hecho no hacemos una operación, sino varias: el procesador lee los datos de la memoria para registrarse, actualiza el registro y escribe los datos en la memoria.

Estas tres operaciones no se realizan atómicamente. Por lo tanto, el planificador en cualquier momento, en cualquiera de estas operaciones, puede tomar y desplazar nuestro flujo. Resulta que la acción no está terminada, y por eso atrapamos errores.
Aquí hay un ejemplo de dicho código (el incremento se descompone inmediatamente en varias operaciones ).

El planificador puede evitar el primer subproceso después de ejecutar la primera línea y el segundo subproceso después de verificar la condición. En este caso, ambos flujos caerán en la sección crítica y, por lo tanto, es "crítico": no se pueden ingresar allí simultáneamente.
Podemos bloquear usando sync.Mutex del paquete de sync estándar. El bloqueo de acceso nos permite indicar explícitamente que el código debe ser ejecutado por un hilo a la vez. Con este código, obtenemos lo que necesitamos.

Las cerraduras son una operación bastante costosa. Por lo tanto, hay operaciones atómicas a nivel de procesador. En este caso, el incremento puede hacerse atómico al reemplazarlo con la operación atomic.AddInt64 del paquete atomic .
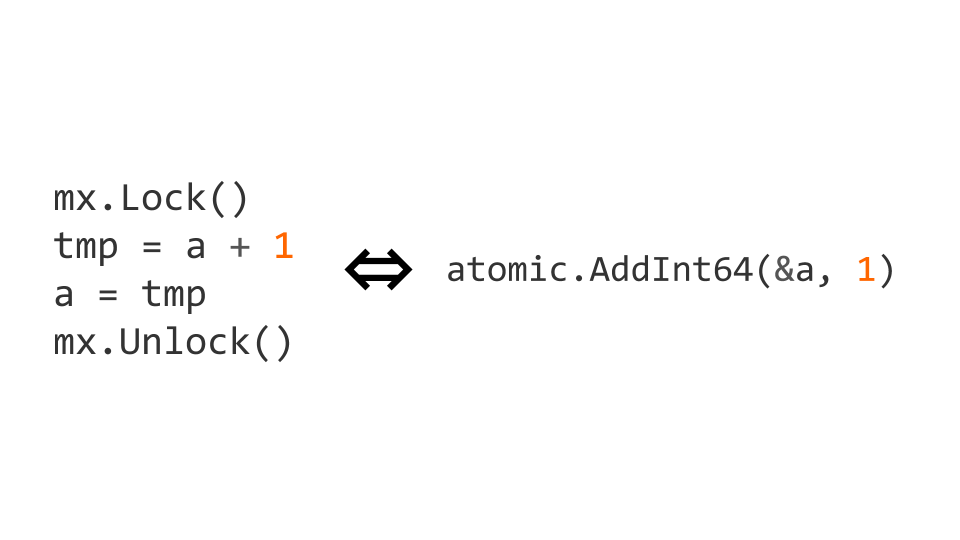
Si comenzamos a trabajar con instrucciones atómicas, entonces no solo debemos escribir atómicamente, sino también leer atómicamente. Si no lo hacemos, pueden surgir problemas.
Optimización: ¿qué podría salir mal?
Las cerraduras son buenas, pero pueden ser caras. Los atómicos son lo suficientemente baratos como para no preocuparse por el rendimiento.
Entonces, aprendimos que las primitivas de sincronización introducen sobrecarga y decidimos agregar optimización: verificaremos el indicador sin tener en cuenta el subprocesamiento múltiple y luego verificaremos nuevamente usando primitivas de sincronización. Todo se ve bien y debería funcionar.

Todo está bien, excepto que el compilador está tratando de optimizar nuestro código. Que esta haciendo el Él intercambia las instrucciones de asignación, y obtenemos un comportamiento no válido, porque nuestro done hace true antes de que se asigne el valor de la variable "
No intente hacer tales optimizaciones, debido a ellas obtendrá muchos problemas. Le aconsejo que lea la especificación de The Go Memory Model y un artículo de Dmitry Vyukova ( @dvyukov ) Razas de datos benignas: ¿qué podría salir mal? para entender mejor los problemas.
Si realmente confía en el rendimiento de las cerraduras, escriba código sin bloqueo, pero no necesita hacer un acceso no sincronizado a la memoria.
Punto muerto
El siguiente problema que enfrentaremos es Deadlock. Puede parecer que todo es bastante trivial aquí. Hay dos recursos, por ejemplo, dos Mutex . En el primer hilo, primero capturamos el primer Mutex , y en el segundo hilo primero capturamos el segundo Mutex . Además, vamos a querer tomar el segundo Mutex en el primer hilo, pero no podremos hacerlo porque ya está bloqueado. En el segundo hilo, intentaremos tomar, respectivamente, el primer Mutex y también bloquear. Ahí está, Deadlock.
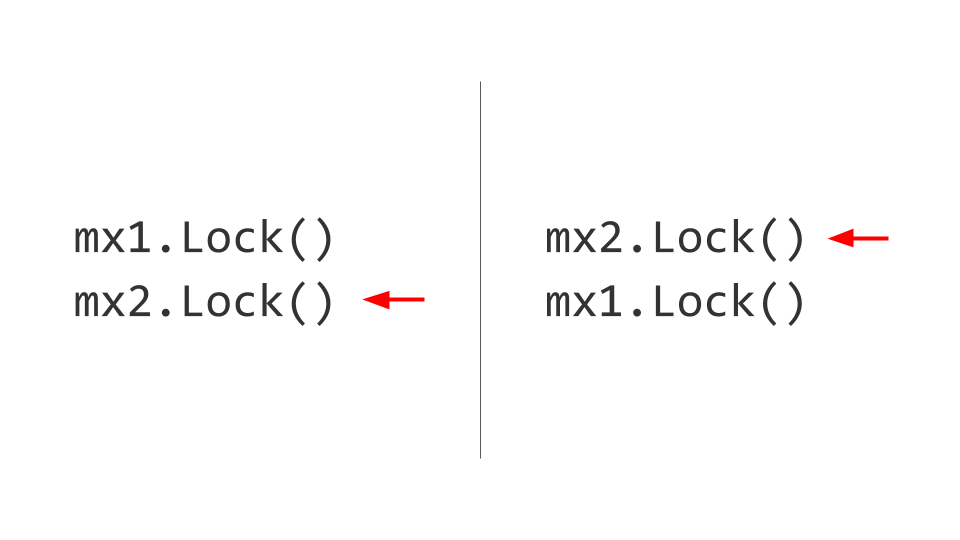
Ninguno de estos dos hilos podrá avanzar más, porque ambos esperarán el recurso. ¿Cómo se resuelve esto? Intercambiamos cerraduras, y luego no surgen problemas. Por supuesto, es fácil de decir, pero mantener esta regla durante toda la vida del producto no es fácil. Si es posible, hágalo: tome y dé las cerraduras en el mismo orden .
Puede parecer que los desarrolladores experimentados no encuentran tales errores, pero aquí hay un ejemplo de un punto muerto del código del proyecto, etc.

Aquí el problema principal es que escribir en un canal sin búfer es bloquear; para escribir, por otro lado, necesita un lector. Tomando el mutex, el primer hilo espera a que aparezca el lector. El segundo hilo ya no puede capturar el mutex. Punto muerto
Te aconsejo que pruebes el emocionante juego The Deadlock Empire . En este juego, actúas como un programador que debe cambiar el contexto para evitar que el código se ejecute correctamente.
Tipo de problemas
¿Qué problemas existen todavía? Comenzamos con las condiciones de carrera . Luego miramos Deadlock (todavía hay una variante de Livelock , esto es cuando no podemos capturar el recurso, pero no hay bloqueos explícitos). Hay hambre , es cuando vamos a la impresora para imprimir un trozo de papel, y hay una cola, y no podemos acceder al recurso. Observamos el comportamiento del programa con False Sharing . Todavía hay un problema: bloqueo de contención , cuando el rendimiento se degrada debido a una gran competencia por un recurso (por ejemplo, un mutex que necesitan una gran cantidad de subprocesos).

Detección de carrera
Go es potente con la caja de herramientas provista de fábrica. Race Detector es una de esas herramientas. Usarlo es simple: escribimos pruebas o lo ejecutamos en una carga de combate y detectamos errores.
Puede leer más sobre el uso del Detector de carreras en la documentación , pero recuerde que tiene limitaciones. Detengámonos en ellos con más detalle.

En primer lugar, el código que no se ejecutó no es verificado por el detector de carreras. Por lo tanto, la cobertura de la prueba debe ser alta. Además, el Detector de carreras recuerda el historial de llamadas a cada palabra en la memoria, pero este historial de llamadas tiene profundidad. En Go, por ejemplo, esta profundidad es cuatro: cuatro elementos, cuatro accesos. Si el Detector de carreras no ha atrapado una carrera dentro de esta profundidad, cree que no hay carrera. Por lo tanto, aunque el Detector de carrera nunca se equivoca, no detectará todos los errores. Puede esperar el Detector de carreras, pero debe recordar sus limitaciones. Por separado, puede leer sobre el algoritmo de trabajo .
Perfil de bloque
El perfil de bloqueo es otra herramienta que nos permite encontrar y solucionar problemas de bloqueo.

Se puede usar tanto en el nivel de prueba de referencia como durante la carga de combate. Por lo tanto, si está buscando problemas asociados con la sincronización de acceso a datos, intente comenzar con el Detector de carrera y continúe usando el Perfil de bloque.
Programa ejemplo
Veamos el código real con el que podemos tropezar. Escribiremos una función que simplemente tome una matriz de solicitudes e intente ejecutarlas: cada solicitud en secuencia. Si alguna de las solicitudes devuelve un error, la función termina la ejecución.

Si escribimos en Go, debemos usar todo el poder del lenguaje. Lo intentamos Obtenemos tres veces más código.

Pregunta: ¿hay algún error en el código?
Por supuesto! Veamos cuáles.
En el circuito corremos goroutines. Para la orquestación de goroutine, utilizamos sync.WaitGroup . ¿Pero qué estamos haciendo mal? Ya dentro de la rutina de ejecución, llamamos wg.Add(1) , es decir, agregamos una nueva rutina para esperar. Y usando wg.Wait() , estamos esperando que se completen todas las gorutinas. Pero puede suceder que cuando se wg.Wait() , no se inicie ni una sola rutina. En este caso, wg.Wait() considerará que todo está hecho, wg.Wait() el canal y saldremos de la función sin errores, creyendo que todo está bien.

¿Qué pasará después? Luego comenzarán las rutinas, se ejecutará el código y quizás una de las solicitudes devolverá un error. Se escribe un error en un canal cerrado, y escribir en un canal cerrado es pánico. Nuestra aplicación se bloqueará. Es poco probable que esto sea lo que quería obtener, por lo que lo corregimos indicando de antemano cuántas gorutinas lanzaremos.

Tal vez todavía hay algunos problemas?
Hay un error relacionado con cómo aparece el objeto req dentro de la función. La variable req actúa como un iterador del ciclo, y no sabemos qué valor tendrá en el momento del lanzamiento de la rutina.

En la práctica, en este código, el valor req probablemente será igual al último elemento de la matriz. Por lo tanto, solo envía la misma solicitud N veces. Solución: explícitamente pasa nuestra solicitud como argumento a la función.

Echemos un vistazo más de cerca a cómo manejamos los errores. Declaramos un canal almacenado en una ranura. Cuando ocurre un error, lo enviamos a este canal. Todo parece estar bien: se produjo un error; devolvimos este error de una función.

Pero, ¿qué pasa si todas las solicitudes regresan con un error?
Luego, escribir en el canal obtendrá solo el primer error, el resto bloqueará la ejecución de goroutines. Como no habrá más lecturas del canal al momento de salir de la función de lectura, tenemos una fuga de rutina. Es decir, todos esos gorutinos que no pudieron escribir el error en el canal simplemente se quedan en la memoria.
Lo arreglamos de manera muy simple: seleccionamos en el canal de ranura el número de solicitudes. Esto resuelve nuestro problema de memoria poco eficiente, porque si tenemos mil millones de solicitudes, necesitamos asignar mil millones de ranuras.

Solucionamos los problemas. El código ahora es competitivo. Pero el problema es la legibilidad: en comparación con la versión síncrona del código, hay muchos. Y esto no es bueno, porque el desarrollo de programas competitivos ya es difícil, ¿por qué lo complicamos con mucho código?

Errgroup
Sugiero aumentar la legibilidad del código.
Me gusta usar el paquete errgroup en lugar de sync.WaitGroup . Este paquete no requiere especificar cuántas gorutinas esperar y le permite ignorar la colección de errores. Así es como se verá nuestra función cuando use errgroup :

Además, errgroup permite orquestar convenientemente los componentes de nuestro programa usando context.Context . A que me refiero
Supongamos que tenemos varios componentes de nuestro programa, si al menos uno de ellos falla, queremos terminar cuidadosamente todos los demás. Entonces errgroup cuando errgroup un error, completa el context y, por lo tanto, todos los componentes reciben una notificación sobre la necesidad de completar el trabajo.

Esto se puede usar para construir programas complejos de múltiples componentes que se comporten de manera predecible.
Conclusiones
Hazlo lo más simple posible. Mejor sincrónicamente. El desarrollo de programas multiproceso es generalmente un proceso complejo, que conduce a la aparición de errores desagradables.

No use la sincronización implícita. Si realmente descansó en él, piense en cómo deshacerse de los bloqueos, cómo hacer un algoritmo sin bloqueo.
Go es un buen lenguaje para escribir programas que funcionan efectivamente con una gran cantidad de núcleos, pero no es mejor que todos los demás idiomas, y siempre aparecerán errores. Por lo tanto, incluso armado con Go, trata de comprender varios niveles de abstracciones inferiores a lo que trabajas.
