Presentamos a su atención la segunda parte de la traducción del material sobre la lucha del equipo de gitlab.com contra la tiranía del tiempo.

→ Aquí, por cierto, es la
primera parte .
Límite de velocidad de procesamiento de solicitudes
En este punto, no estábamos interesados en simplemente aumentar los valores del parámetro
MaxStartups . Aunque un aumento del 50% en este parámetro demostró ser bueno, su aumento adicional sin razón suficiente parecía una solución bastante cruda para el problema. Seguramente había algo más que podíamos hacer.
Las búsquedas me llevaron al nivel HAProxy, que estaba ubicado frente a los servidores SSH. HAProxy tiene una buena opción de
rate-limit sessions que afecta la parte del sistema que acepta solicitudes entrantes. Si esta opción está configurada, se usa para limitar el número de nuevas solicitudes TCP por segundo que la interfaz envía a los servidores, mientras deja conexiones entrantes adicionales al socket TCP. Si la velocidad de las solicitudes entrantes excede el límite (modificable cada milisegundo), las nuevas conexiones simplemente se retrasan. El cliente TCP (en este caso, SSH) simplemente ve el retraso antes de establecer una conexión TCP. Esto, en mi opinión, es un movimiento muy hermoso. Hasta que la velocidad a la que se reciben las solicitudes, durante períodos de tiempo demasiado largos, excedan demasiado el límite, el sistema funcionará bien.
La siguiente pregunta fue la selección del valor de la opción de
rate-limit sessions , que deberíamos usar. Encontrar una respuesta a esta pregunta fue complicado por el hecho de que tenemos 27 backends SSH y 18 frontales de HAProxy (16 principales y 2 alt-ssh), así como el hecho de que los frontends no se coordinan entre sí con respecto a la velocidad del procesamiento de solicitudes . Además, tuvimos que tener en cuenta cuánto tiempo lleva el paso de autenticación de la nueva sesión SSH. Suponga que el primer valor de
MaxStartups es 150. Esto significa que si la fase de autenticación toma dos segundos, entonces podemos transferir cada uno de los backends solo 75 nuevas sesiones por segundo.
Aquí puede encontrar detalles sobre el cálculo del valor de
rate-limit sessions de
rate-limit sessions , no entraré en detalles aquí. Solo noto que para calcular este valor, se deben tener en cuenta cuatro parámetros. El primero y el segundo son el número de servidores de ambos tipos. El tercero es el valor de
MaxStartups . El cuarto es
T : cuánto tiempo se tarda en autenticar una sesión SSH. El valor de
T extremadamente importante, pero solo se puede deducir aproximadamente. Hicimos exactamente eso, dejando el resultado a los 2 segundos. Como resultado, obtuvimos el valor de
rate-limit para los front-end, que ascendió a 112.5. Lo redondeamos a 110.
Y ahora, la nueva configuración entró en vigencia. ¿Quizás crees que después de esto todo terminó felizmente? Debe haber sido que el número de errores se apresuró a cero y todos los que estaban alrededor estaban inmensamente felices. Bueno, en realidad estaba lejos de ser tan bueno. Este cambio no resultó en ningún cambio visible en la tasa de error. Francamente, estaba bastante molesto. Perdimos algo importante o entendimos mal la esencia del problema.
Como resultado, volvimos a los registros (y, finalmente, a la información HAProxy) y pudimos asegurarnos de que el límite de velocidad de procesamiento de consultas al menos funciona actuando en las consultas como esperábamos. Anteriormente, los indicadores correspondientes eran más altos, esto nos permitió concluir que limitamos con éxito la velocidad con la que se envían las solicitudes entrantes para su procesamiento. Pero estaba claro que la velocidad a la que llegaron las solicitudes todavía era demasiado alta. Aunque también estaba claro que ni siquiera se acercaba a esos niveles cuando podía tener un efecto notable en el sistema. Cuando analizamos el proceso de selección de backends (de acuerdo con los registros de HAProxy), notamos una rareza allí. Al comienzo de la hora, las conexiones de back-end se distribuían de manera desigual entre los servidores SSH. En el intervalo de tiempo elegido para el análisis, el número de conexiones por segundo en diferentes servidores varió de 30 a 121. Y esto significó que nuestro equilibrio de carga no funcionó bien. El análisis de la configuración mostró que utilizamos la opción de
balance source , de modo que un cliente con una dirección IP específica siempre está conectado al mismo backend. Esto puede considerarse como un fenómeno positivo en los casos en que se necesita un enlace de sesión. Pero estamos tratando con SSH, por lo que no necesitamos esto. Esta opción fue configurada por nosotros una vez, pero no encontramos ninguna pista sobre por qué se hizo esto. No pudimos encontrar una buena razón para seguir usándolo. Como resultado, decidimos cambiar a
leastconn . Gracias a esta opción, las nuevas conexiones entrantes ofrecen backends con el número mínimo de conexiones actuales. Esto afectó el uso de los recursos del procesador por parte de nuestros servidores SSH (Git). Aquí está el horario correspondiente.
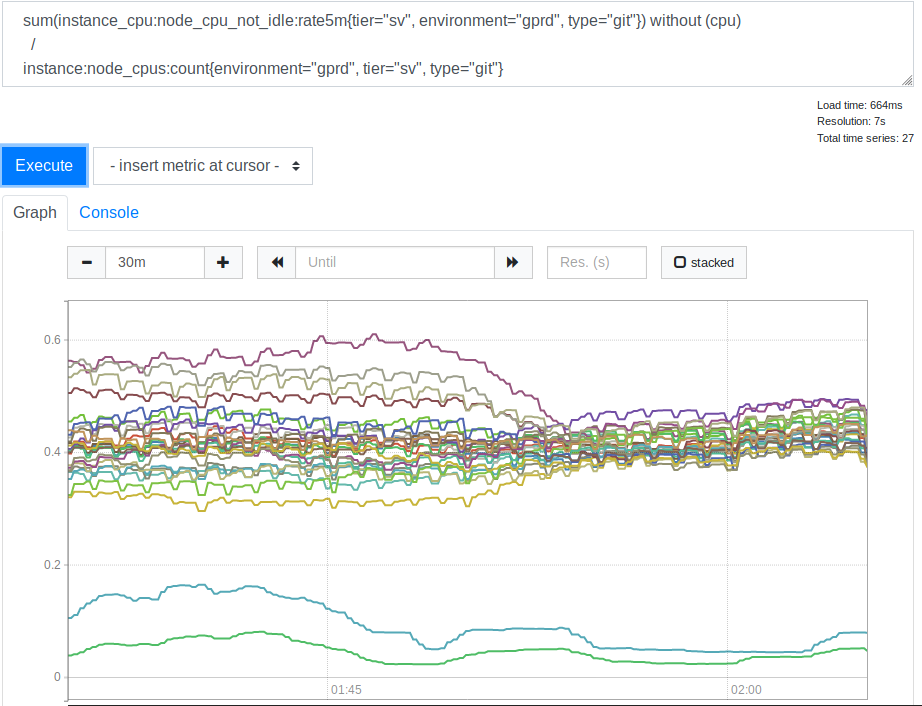 Consumo de CPU por parte de los servidores antes y después de aplicar la opción lessconn
Consumo de CPU por parte de los servidores antes y después de aplicar la opción lessconnDespués de ver esto, nos dimos cuenta de que usar
leastconn es una buena idea. Las dos líneas que se encuentran en la parte inferior del gráfico son nuestros servidores Canarios, puede ignorarlos. Pero antes, la distribución de los valores de carga de la CPU para diferentes servidores se correlacionaba como 2: 1 (del 30% al 60%). Esto indica claramente que anteriormente algunos de nuestros backends se cargaron más que otros debido a la conexión de los clientes con ellos. Fue una sorpresa para mí. Parecía razonable esperar que una amplia gama de direcciones IP de clientes fuera suficiente para cargar nuestros servidores de manera mucho más uniforme. Pero, aparentemente, para distorsionar los indicadores de carga del servidor, varios clientes grandes fueron suficientes, cuyo comportamiento difiere de alguna opción promedio.
Lección número 4. Cuando selecciona configuraciones específicas que difieren de las configuraciones predeterminadas, coméntelas o deje un enlace a los materiales que explican los cambios. Cualquiera que tenga que lidiar con estos ajustes en el futuro se lo agradecerá.
Esta transparencia es
uno de los valores centrales de GitLab .
Habilitar la opción
leastconn también ayudó a reducir los niveles de error. Y eso era exactamente lo que estábamos luchando. Por lo tanto, decidimos dejar esta opción. Pero, al continuar experimentando, redujeron el nivel de límites de velocidad de procesamiento de solicitudes a 100, lo que ayudó a reducir aún más el nivel de errores. Esto indicó que la selección inicial del valor de
T probablemente se realizó incorrectamente. Pero si es así, entonces este indicador era demasiado pequeño, lo que conducía a un límite de velocidad demasiado fuerte, e incluso 100 solicitudes por segundo se percibían como un valor muy bajo, y no estábamos listos para reducirlo aún más. Desafortunadamente, por alguna razón interna, estos dos cambios fueron solo un experimento. Tuvimos que volver a usar la opción de
balance source y limitar la velocidad de procesamiento de las solicitudes a 100 solicitudes por segundo.
Dado que la velocidad de procesamiento de la consulta se estableció en un nivel bajo que nos
leastconn , y que no podíamos usar el
leastconn , intentamos aumentar el parámetro
MaxStartups . Al principio lo aumentamos a 200, esto dio algún efecto. Luego, hasta 250. Los errores desaparecieron casi por completo y no sucedió nada malo.
Lección número 5. Si bien los MaxStartups altos pueden parecer intimidantes, tienen muy poco impacto en el rendimiento incluso cuando son mucho más altos que los valores predeterminados.
Quizás esto sea algo así como una palanca grande y poderosa, que podemos, si es necesario, usar en el futuro. Quizás encontremos problemas si hablamos de cifras en la región de varios miles o varias decenas de miles, pero todavía estamos lejos de eso.
¿Qué dice esto sobre mis estimaciones del parámetro
T , el tiempo que lleva instalar y autenticar una sesión SSH? Si trabaja con la fórmula para calcular el indicador de límite de velocidad de procesamiento de la conexión, sabiendo que 200 no es suficiente para el indicador
MaxStartups y 250 es suficiente, puede descubrir que
T probablemente tenga un valor de 2.7 a 3.4 segundos. Como resultado, un valor estimado de 2 segundos no estaba lejos de la verdad, pero el valor real, por supuesto, era más alto de lo esperado. Volveremos a esto un poco más tarde.
Pasos finales
Volvimos a mirar los registros, teniendo en cuenta lo que ya sabíamos y, después de reflexionar, descubrimos que el problema con el que todo comenzó puede identificarse mediante los siguientes signos. En primer lugar, este es un valor
t_state igual a
SD . En segundo lugar, este es el valor de
b_read (bytes leídos por el cliente), igual a 0. Como ya se mencionó, procesamos aproximadamente 26-28 millones de conexiones SSH por día. Fue desagradable saber que, en medio del desastre, aproximadamente el 1.5% de estas conexiones se rompieron gravemente. Obviamente, la escala del problema fue mucho mayor de lo que pensábamos al principio. Además, no había nada que no pudiéramos detectar antes (incluso cuando nos dimos cuenta de que
t_state="SD" indicaba el problema en los registros), pero no pensamos en cómo hacerlo, aunque y deberías pensarlo. Probablemente debido a esto, dedicamos mucho más tiempo y esfuerzo a resolver el problema de lo que podríamos haber gastado.
Lección número 6. Mida los niveles de error reales lo antes posible.
Si inicialmente estuviéramos conscientes del alcance del problema, podríamos prestarle más atención. Aunque, cómo percibirlo, aún depende del conocimiento de las características que nos permiten describir los problemas.
Si hablamos de las ventajas que aparecieron después de aumentar los valores de
MaxStartups y ajustar la velocidad de procesamiento de solicitudes, podemos decir que el nivel de error se redujo a 0.001%. Es decir, hasta varios miles por día. Esta situación parecía mucho mejor, pero un nivel similar de errores era aún mayor que el que nos gustaría alcanzar. Después de descubrir algunas cosas, nuevamente pudimos usar la opción
leastconn y los errores desaparecieron por completo. Después de eso, pudimos respirar aliviados.
Trabajo futuro
Obviamente, la fase de autenticación SSH todavía lleva mucho tiempo. Tal vez hasta 3.4 segundos. GitLab puede usar
AuthorizedKeysCommand para buscar directamente una clave SSH en una base de datos. Esto es muy importante para operaciones rápidas cuando hay una gran cantidad de usuarios. De lo contrario, SSHD necesita leer secuencialmente un archivo muy grande
authorized_keys para encontrar la clave pública del usuario. Esta tarea no escala bien. Implementamos una búsqueda usando una cierta cantidad de código Ruby que realiza llamadas a una API HTTP externa.
Stan Hugh , el jefe de nuestro departamento de ingeniería y una fuente inagotable de conocimiento sobre GitLab, descubrió que las instancias Unicorn de servidores Git / SSH están bajo carga constante por las solicitudes que se les hacen. Esto podría hacer una contribución significativa a los tres segundos necesarios para autenticar las solicitudes. Como resultado, nos dimos cuenta de que en el futuro deberíamos investigar este problema. Quizás aumentaremos el número de instancias de Unicornio (o Puma) en estos nodos para que los servidores SSH no tengan que esperar para acceder a ellos. Sin embargo, existe un cierto riesgo aquí, por lo que debemos ser cuidadosos y prestar atención a la recopilación y el análisis de los indicadores del sistema. El trabajo en productividad continúa, pero ahora, después de que se resuelve el problema principal, las cosas van más despacio. Es posible que podamos reducir el valor de
MaxStartups , pero dado que su alto nivel no crea el impacto negativo en el sistema que parece estar creando, esto no es particularmente necesario. Será mucho más fácil para todos vivir si OpenSSH puede en cualquier momento decirnos qué tan cerca estamos de los límites de
MaxStartups . Será mejor si siempre podemos estar al tanto. Esto es mucho mejor que aprender que se superan los límites cuando se enfrentan conexiones interrumpidas.
Además, necesitamos algún tipo de sistema de notificación cuando aparecen las entradas de registro HAProxy, lo que indica un problema con las conexiones desconectadas. El hecho es que esto, en la práctica, no debería suceder en absoluto. Si esto sucede nuevamente, necesitaremos aumentar aún más los valores de
MaxStartups , o si nos encontramos con una falta de recursos, necesitaremos agregar más nodos Git / SSH al sistema.
Resumen
Partes de sistemas complejos interactúan en patrones complejos. Y en ellos, para resolver varios problemas, a menudo se puede encontrar lejos de una "palanca". Cuando se trata con tales sistemas, es útil conocer las herramientas presentes en ellos. El hecho es que todos tienen sus pros y sus contras. Además, debe tenerse en cuenta que puede ser arriesgado realizar ciertas configuraciones basadas en suposiciones y valores estimados. Ahora, mirando el camino que hemos recorrido, trataría de medir con la mayor precisión posible el tiempo requerido para completar la autenticación de la solicitud, lo que llevaría al valor aproximado de
T que deduje que estaría más cerca de la verdad.
Pero la principal lección que aprendimos de todo esto es que cuando mucha gente planifica tareas basadas en algunas métricas de tiempo agradables, esto, para proveedores de servicios centralizados como GitLab, conduce a problemas de escala realmente inusuales.
Si usted es uno de los que utiliza las herramientas de inicio de tareas programadas, es posible que deba considerar configurar el tiempo para iniciar sus tareas de una manera nueva. Por ejemplo, puede hacer que las tareas se "duerman" por un tiempo, comenzando a funcionar realmente solo 30 segundos después del lanzamiento. Puede, por ejemplo, indicar tiempos aleatorios dentro de la hora en el cronograma de inicio de la tarea (aquí puede agregar un tiempo de espera aleatorio antes de la ejecución real de la tarea). Esto nos ayudará a todos en la lucha contra la tiranía de los relojes.
Estimados lectores! ¿Te has encontrado con problemas similares a aquellos a cuya historia se dedica este material?
