El material, la primera parte de la traducción que publicamos hoy, está dedicado a un problema a gran escala que surgió en gitlab.com. Aquí hablaremos sobre cómo la encontraron, cómo pelearon con ella y cómo, finalmente, la resolvieron. Además, ante este problema, el equipo de gitlab.com descubrió cuál es la tiranía de los relojes.

→
La segunda parte .
El problema
Comenzamos a recibir mensajes de clientes que, al trabajar con gitlab.com, periódicamente encuentran errores al ejecutar solicitudes de extracción. Los errores generalmente ocurren al realizar tareas de CI o durante la operación de otros sistemas automatizados similares. Los mensajes de error se veían así:
ssh_exchange_identification: connection closed by remote host fatal: Could not read from remote repository
La situación se complicó aún más por el hecho de que los mensajes de error aparecían de forma irregular y, como parecía, de forma impredecible. No pudimos reproducirlos a voluntad, no pudimos identificar ningún signo obvio de lo que estaba sucediendo en los gráficos o en los registros. Los mensajes de error en sí mismos tampoco aportaron muchos beneficios. El cliente SSH fue informado de que la conexión se interrumpió, pero la razón de esto podría ser cualquier cosa: un cliente fallido o una máquina virtual inestable, un firewall que no controlamos, acciones extrañas del proveedor o un problema con nuestra aplicación.
Nosotros, trabajando en el esquema GIT-over-SSH, estamos lidiando con un gran número de conexiones, aproximadamente 26 millones por día. Este es un promedio de 300 conexiones por segundo. Por lo tanto, un intento de seleccionar una pequeña cantidad de conexiones fallidas del flujo de datos existente prometió ser una tarea difícil. Lo bueno de esta situación es que nos gusta resolver problemas complejos.
Primera pista
Contactamos a uno de nuestros clientes (gracias a Hubert Holtz, de Atalanda), quien se encontró con un problema varias veces al día. Esto nos dio un punto de apoyo. Hubert pudo proporcionarnos una dirección IP pública adecuada. Esto significaba que podíamos capturar paquetes en nuestros nodos front-end HAProxy para tratar de aislar el problema confiando en un conjunto de datos que es más pequeño de lo que podría llamarse "todo el tráfico SSH". Aún mejor, la compañía usó un
puerto ssh alternativo . Esto significaba que necesitábamos analizar la situación en solo dos servidores HAProxy, y no en dieciséis.
El análisis de paquetes, sin embargo, no fue particularmente divertido. A pesar de las restricciones en aproximadamente 6.5 horas, se recolectaron paquetes de aproximadamente 500 MB. Encontramos compuestos de corta duración. Se estableció la conexión TCP, el cliente envió el identificador, después de lo cual nuestro servidor HAProxy se desconectó inmediatamente utilizando la secuencia TCP FIN correcta. Como resultado, tuvimos a nuestra disposición la primera pista excelente. Ella nos permitió concluir que la conexión se cerró definitivamente por iniciativa de gitlab.com, y no por algo entre nosotros y el cliente. Esto significaba que nos enfrentamos a un problema que podemos investigar y corregir.
Lección número 1. El menú de estadísticas de la herramienta Wireshark tiene un montón de herramientas útiles a las que, antes de este caso, no he prestado mucha atención.
En particular, estamos hablando del elemento del menú
Conversations , que puede demostrar información básica sobre los datos capturados sobre las conexiones TCP. Hay información sobre tiempo, paquetes, bytes. Los datos que se muestran en la ventana correspondiente se pueden ordenar. Debería usar esta herramienta desde el principio en lugar de jugar manualmente con los datos capturados. Luego me di cuenta de que necesitaba buscar conexiones con una pequeña cantidad de paquetes. La ventana
Conversations le permitió prestarles atención de inmediato. Después de eso, pude encontrar otros compuestos similares y asegurarme de que la primera conexión no fuera un fenómeno anormal.
Inmersión de registro
¿Qué causó que HAProxy se desconectara del cliente? El servidor, por supuesto, no hizo esto de manera arbitraria: lo que estaba sucediendo debería haber tenido alguna razón más profunda; si lo desea, "otro nivel de
tortugas ". Hubo la sensación de que el próximo objeto de estudio deberían ser los registros HAProxy. Nuestros registros se almacenaron en GCP BigQuery. Esto es conveniente, ya que tenemos muchos registros, y necesitábamos analizarlos exhaustivamente. Pero primero, pudimos identificar la entrada de registro para uno de los incidentes, que se encontró en los paquetes capturados. Confiamos en el tiempo y en el puerto TCP, que fue un logro importante en nuestro estudio. El detalle más interesante en el registro encontrado fue el
t_state (Estado de terminación), que tenía el valor
SD . Aquí hay un extracto de la documentación de HAProxy:
S: , . D: DATA.
El significado del significado de
D se explica de manera muy simple. La conexión TCP se estableció correctamente, se enviaron datos. Esto coincidió con la evidencia obtenida de los paquetes capturados. Un valor de
S significaba que HAProxy recibió un mensaje de error RST o ICMP del backend. Pero no pudimos encontrar inmediatamente una pista de por qué estaba sucediendo esto. La razón de esto podría ser cualquier cosa, desde una red inestable (por ejemplo, una falla o congestión) hasta un problema de nivel de aplicación. Al usar BigQuery para agregar datos en backends de Git, descubrimos que el problema no está vinculado a ninguna máquina virtual en particular. Necesitábamos más información.
Quiero señalar que las entradas de registro con el valor
SD no eran algo especial, característico solo para nuestro problema. En el puerto ssh alternativo, recibimos muchas solicitudes relacionadas con el escaneo de HTTPS. Esto condujo al hecho de que el valor
SD cayó en los registros cuando el servidor SSH vio el mensaje
TLS ClientHello mientras esperaba recibir un saludo SSH. Esto condujo brevemente nuestra investigación de una manera indirecta.
Habiendo capturado algo de tráfico entre el HAProxy y el servidor Git y nuevamente usando las herramientas de Wireshark, descubrimos rápidamente que el SSHD en el servidor Git se desconectó del TCP FIN-ACK inmediatamente después de un protocolo de enlace de tres vías de TCP. HAProxy todavía no envió el primer paquete de datos, pero estaba a punto de hacerlo. Cuando envió el paquete, el servidor Git le respondió con TCP RST. Como resultado, ahora hemos descubierto la razón por la cual HAProxy escribió en los registros sobre la falla de conexión con el valor
SD . SSH cerró la conexión, haciéndolo de manera intencional y correcta, y RST fue solo un artefacto del hecho de que el servidor SSH recibió el paquete después de FIN-ACK. No significaba nada más.
Horario elocuente
Al observar y analizar registros con valores
SD en BigQuery, nos dimos cuenta de que los errores tienen una relación pronunciada con el tiempo. Es decir, encontramos picos en el número de conexiones fallidas en los primeros 10 segundos de cada minuto. Se observaron durante 5-6 segundos.
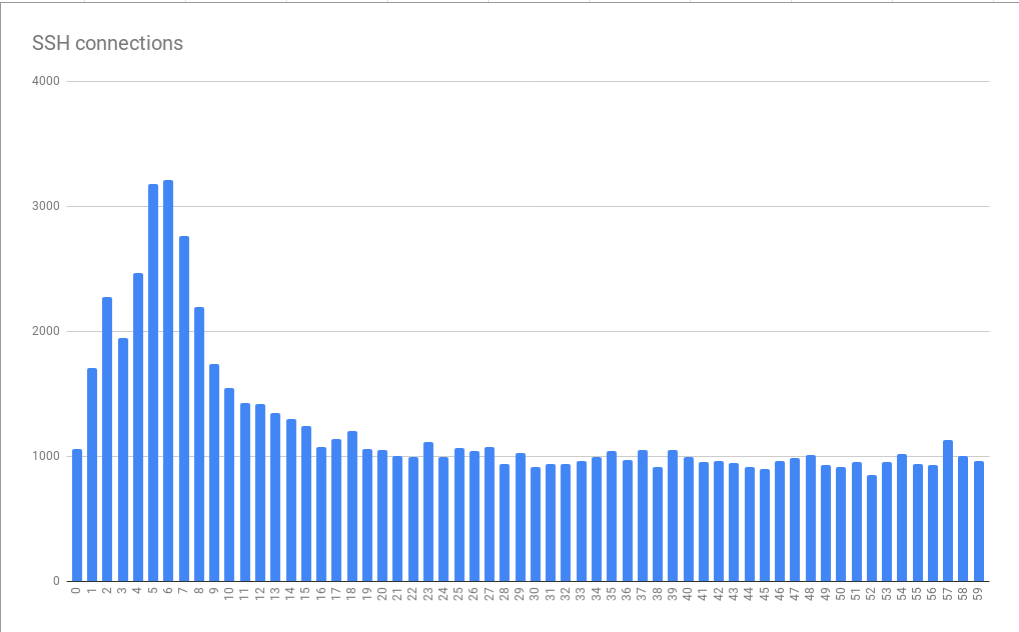 Errores de conexión agrupados en minutos a segundos
Errores de conexión agrupados en minutos a segundosEste gráfico se basa en datos recopilados durante muchas horas. El hecho de que el patrón detectado de distribución de errores resultó ser estable indica que la causa de los errores se manifiesta de manera estable en minutos y horas individuales y, posiblemente aún peor, aparece de manera estable en diferentes momentos del día. Es muy interesante que el tamaño pico promedio es aproximadamente 3 veces mayor que la carga base. Esto significaba que nos enfrentamos con un problema no trivial de escalado. Como resultado, simplemente conectar "más recursos" en forma de máquinas virtuales adicionales, diseñadas para ayudarnos a hacer frente a las cargas máximas, en teoría podría ser inaceptablemente costoso. Esto también indicó que estamos llegando a algún tipo de restricción severa. Como resultado, recibimos la primera pista sobre el problema sistémico fundamental que causa errores. Lo llamé la tiranía de las horas.
Cron o sistemas de programación similares a menudo no difieren en la capacidad de personalizar la ejecución de tareas al segundo más cercano. Si tales sistemas tienen tales capacidades, no se usan con mucha frecuencia debido al hecho de que las personas prefieren considerar el tiempo, dividido en intervalos, expresados por hermosos números redondos. Como resultado, las tareas comienzan al comienzo de un minuto u hora, o en otros momentos similares. Si las tareas necesitaran un par de segundos para preparar el comando
git fetch para descargar materiales de gitlab.com, esto podría explicar el patrón que encontramos cuando la carga en el sistema aumenta bruscamente durante varios segundos cada minuto. En esos momentos, aumenta el número de errores.
Lección número 2. Aparentemente, mucha gente usa la sincronización horaria correctamente configurada (a través de NTP o usando otros mecanismos).
Si nadie sincronizara el tiempo, entonces nuestro problema no se habría manifestado tan claramente. Buenas tardes, NTP!
Pero, ¿qué hace que SSH se desconecte?
Más cerca del núcleo del problema
Al estudiar la documentación de SSHD, descubrimos el parámetro
MaxStartups . Controla el número máximo de conexiones no autenticadas. Parece plausible que el límite de conexión se agote cuando al comienzo del minuto el sistema está sujeto a la carga creada por una ráfaga de llamadas de tareas programadas de todo Internet. El parámetro
MaxStartups consta de tres números. El primero es el límite inferior (el número de conexiones al llegar que comienzan las interrupciones en las conexiones). El segundo es el porcentaje de compuestos que exceden el límite inferior de los compuestos que deben romperse al azar. El tercer valor es el número máximo absoluto de conexiones, después de lo cual se rechazan todas las conexiones nuevas. El valor predeterminado de MaxStartups se ve como 10: 30: 100, nuestra configuración se ve como 100: 30: 200. Esto indicó que en el pasado hemos aumentado los límites de conexión estándar. Tal vez, es hora de aumentarlos nuevamente.
Resultó ser un poco desagradable que desde que se instaló OpenSSH 7.2 en nuestros servidores, la única forma de ver los límites establecidos en
MaxStartups fue cambiar al nivel de
Debug depuración. Con este enfoque, una avalancha de datos cae en los registros. Por lo tanto, activamos brevemente este modo en uno de los servidores. Afortunadamente, después de un par de minutos quedó claro que el número de conexiones excedía los límites establecidos en
MaxStartups , como resultado de lo cual se produjo una desconexión temprana.
Resultó que en OpenSSH 7.6 (esta versión viene con Ubuntu 18.04) se organiza un enfoque más conveniente para registrar lo que está relacionado con
MaxStartups . Aquí solo necesita cambiar al modo de registro
Verbose . Aunque no es lo ideal, sigue siendo mejor que cambiar al nivel de
Debug .
Lección número 3. Se considera una buena forma de escribir información interesante en los registros a niveles de registro estándar, y la información sobre una desconexión intencional por cualquier motivo es ciertamente interesante para los administradores del sistema.
Ahora que hemos descubierto la causa del problema, surgió la pregunta sobre cómo resolverlo. Podríamos aumentar los valores en el parámetro
MaxStartups , pero ¿cuánto nos costaría? Ciertamente, esto requeriría un poco de memoria adicional, pero ¿conduciría a consecuencias adversas en aquellas partes del sistema donde se procesan las solicitudes? Solo podíamos pensarlo, así que decidimos tomar y probar la nueva configuración de
MaxStartups . Es decir, los cambiamos por lo siguiente: 150: 30: 300. Anteriormente, parecían 100: 30: 200, es decir, aumentamos el número de conexiones en un 50%. Esto ha tenido un fuerte efecto positivo en el sistema. Al mismo tiempo, no se observaron algunos efectos negativos, como el aumento de la carga en los procesadores.
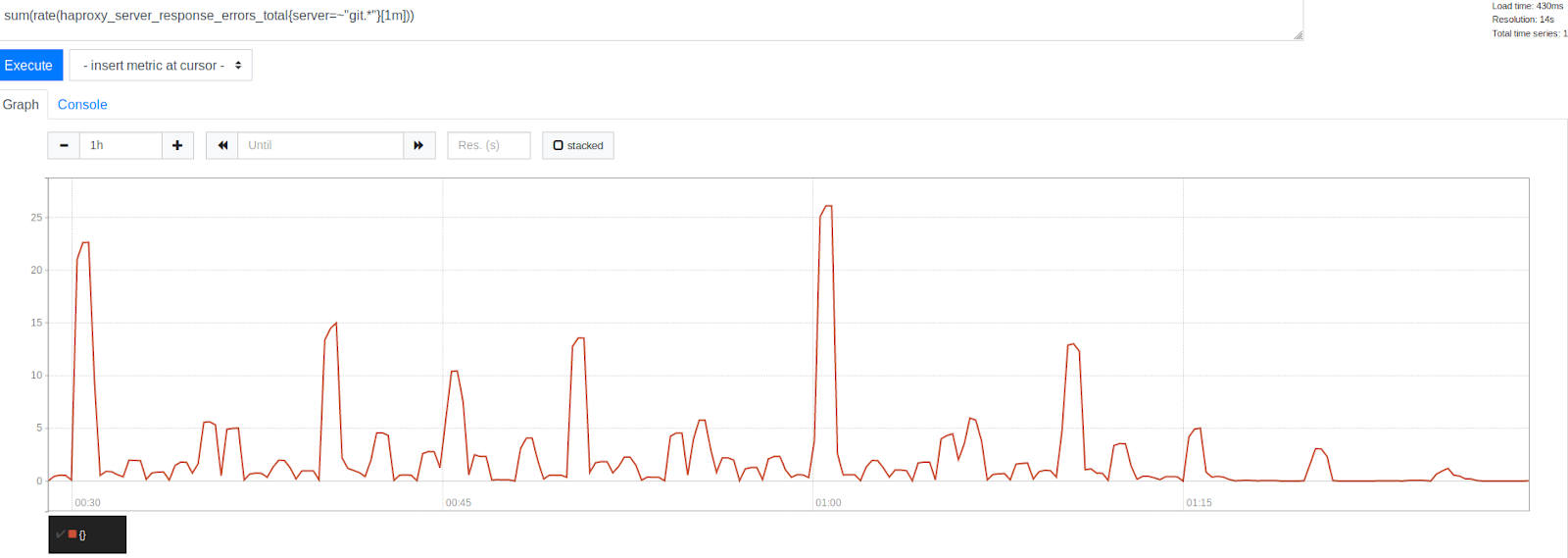 El número de errores antes y después de aumentar MaxStartups en un 50%
El número de errores antes y después de aumentar MaxStartups en un 50%Tenga en cuenta la reducción significativa de errores después de la marca de tiempo 1:15. Esto indica claramente que pudimos eliminar una parte significativa de los errores, aunque algunos de ellos todavía estaban presentes. Es interesante observar que los errores se agrupan alrededor de marcas de tiempo representadas por hermosos números redondos. Este es el comienzo de la hora, cada 30, 15 y 10 minutos. Sin lugar a dudas, la tiranía del reloj continuó. Al comienzo de cada hora, se observa el pico más alto de errores. Esto, dado lo que ya hemos descubierto, parece bastante comprensible. Muchas personas simplemente planean ejecutar tareas cada hora que se ejecuta 0 minutos después del comienzo de la hora. Este hecho confirmó nuestra teoría de que los picos de error son causados por el lanzamiento de tareas programadas. Esto indicó que estábamos en el camino correcto para resolver el problema ajustando los límites del sistema.
Para nuestro placer, cambiar el límite de
MaxStartups no condujo a efectos negativos notables. El uso de la CPU en los servidores SSH se mantuvo en el mismo nivel que antes, la carga en nuestros sistemas tampoco aumentó. Fue muy agradable, considerando que ahora aceptamos más conexiones, de aquellas que simplemente se habrían roto antes. Además, la situación no empeoró por el hecho de que hicimos esto en un momento en que nuestros sistemas estaban muy cargados. Todo parecía prometedor.
Continuará ...
Estimados lectores! ¿Qué herramientas utilizas para analizar el tráfico y los registros?
