Hola habr
Después de experimentar con una conocida base de 60,000 números escritos a mano, MNIST, surgió la pregunta lógica de si había algo similar, pero con soporte no solo para los números, sino también para las letras. Al final resultó que existe, y se llama tal base, como se puede adivinar, Extended MNIST (EMNIST).
Si alguien está interesado en cómo usar esta base de datos puede hacer un simple reconocimiento de texto, bienvenido a cat.
 Nota
Nota : este ejemplo es experimental y educativo, solo estaba interesado en ver qué sucede. No planeé y no planeo hacer el segundo FineReader, por lo que muchas cosas aquí, por supuesto, no están implementadas. Por lo tanto, no se aceptan reclamos en el estilo de "por qué", "ya es mejor", etc. Probablemente ya haya bibliotecas de OCR listas para Python, pero fue interesante hacerlo usted mismo. Por cierto, para aquellos que quieren ver cómo se hizo el verdadero FineReader, hay dos artículos en su blog sobre Habr en 2014:
1 y
2 (pero, por supuesto, sin códigos fuente y detalles, como en cualquier blog corporativo). Bueno, comencemos, todo está abierto aquí y todo es de código abierto.
Por ejemplo, tomaremos el texto sin formato. Aquí hay uno:
HOLA MUNDO
Y veamos qué se puede hacer con él.
Romper texto en letras
El primer paso es dividir el texto en letras separadas. OpenCV es útil para esto, más precisamente su función findContours.
Abra la imagen (cv2.imread), traduzca a b / w (cv2.cvtColor + cv2.threshold), aumente ligeramente (cv2.erode) y encuentre los contornos.
image_file = "text.png" img = cv2.imread(image_file) gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) ret, thresh = cv2.threshold(gray, 0, 255, cv2.THRESH_BINARY) img_erode = cv2.erode(thresh, np.ones((3, 3), np.uint8), iterations=1)
Obtenemos un árbol jerárquico de contornos (parámetro cv2.RETR_TREE). Primero viene el contorno general de la imagen, luego los contornos de las letras, luego los contornos internos. Solo necesitamos el esquema de las letras, así que verifico que el "esquema" es el esquema general. Este es un enfoque simplificado, y para escaneos reales esto puede no funcionar, aunque no es crítico reconocer capturas de pantalla.
Resultado:
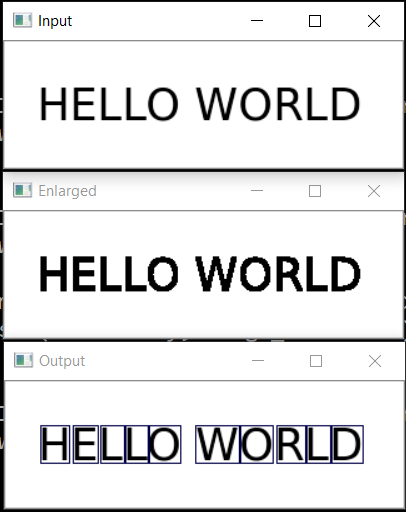
El siguiente paso es guardar cada letra, habiéndola escalado previamente a un cuadrado de 28x28 (es en este formato que se almacena la base de datos MNIST). OpenCV se basa en numpy, por lo que podemos usar las funciones de trabajar con matrices para recortar y escalar.
def letters_extract(image_file: str, out_size=28) -> List[Any]: img = cv2.imread(image_file) gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) ret, thresh = cv2.threshold(gray, 0, 255, cv2.THRESH_BINARY) img_erode = cv2.erode(thresh, np.ones((3, 3), np.uint8), iterations=1)
Al final, clasificamos las letras por la coordenada X, tal como puede ver, guardamos los resultados en forma de tupla (x, w, letra), para que se puedan seleccionar espacios entre los espacios entre las letras.
Asegúrate de que todo funcione:
cv2.imshow("0", letters[0][2]) cv2.imshow("1", letters[1][2]) cv2.imshow("2", letters[2][2]) cv2.imshow("3", letters[3][2]) cv2.imshow("4", letters[4][2]) cv2.waitKey(0)

Las cartas están listas para el reconocimiento, las reconoceremos utilizando una red convolucional; este tipo de red es muy adecuado para tales tareas.
Red neuronal (CNN) para reconocimiento
El conjunto de datos EMNIST de origen tiene 62 caracteres diferentes (A..Z, 0..9, etc.):
emnist_labels = [48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 83, 84, 85, 86, 87, 88, 89, 90, 97, 98, 99, 100, 101, 102, 103, 104, 105, 106, 107, 108, 109, 110, 111, 112, 113, 114, 115, 116, 117, 118, 119, 120, 121, 122]
Una red neuronal, en consecuencia, tiene 62 salidas, en la entrada recibirá imágenes de 28x28, después del reconocimiento "1" estará en la salida de red correspondiente.
Crea un modelo de red.
from tensorflow import keras from keras.models import Sequential from keras import optimizers from keras.layers import Convolution2D, MaxPooling2D, Dropout, Flatten, Dense, Reshape, LSTM, BatchNormalization from keras.optimizers import SGD, RMSprop, Adam from keras import backend as K from keras.constraints import maxnorm import tensorflow as tf def emnist_model(): model = Sequential() model.add(Convolution2D(filters=32, kernel_size=(3, 3), padding='valid', input_shape=(28, 28, 1), activation='relu')) model.add(Convolution2D(filters=64, kernel_size=(3, 3), activation='relu')) model.add(MaxPooling2D(pool_size=(2, 2))) model.add(Dropout(0.25)) model.add(Flatten()) model.add(Dense(512, activation='relu')) model.add(Dropout(0.5)) model.add(Dense(len(emnist_labels), activation='softmax')) model.compile(loss='categorical_crossentropy', optimizer='adadelta', metrics=['accuracy']) return model
Como puede ver, esta es una red convolucional clásica que resalta ciertas características de la imagen (el número de filtros 32 y 64), a cuya "salida" está conectada la red MLP "lineal", que forma el resultado final.
Entrenamiento de redes neuronales
Pasamos a la etapa más larga: capacitación en red. Para hacer esto, tomamos la base de datos EMNIST, que se puede descargar
desde el enlace (tamaño de archivo 536Mb).
Para leer la base de datos, use la biblioteca idx2numpy. Prepararemos datos para capacitación y validación.
import idx2numpy emnist_path = '/home/Documents/TestApps/keras/emnist/' X_train = idx2numpy.convert_from_file(emnist_path + 'emnist-byclass-train-images-idx3-ubyte') y_train = idx2numpy.convert_from_file(emnist_path + 'emnist-byclass-train-labels-idx1-ubyte') X_test = idx2numpy.convert_from_file(emnist_path + 'emnist-byclass-test-images-idx3-ubyte') y_test = idx2numpy.convert_from_file(emnist_path + 'emnist-byclass-test-labels-idx1-ubyte') X_train = np.reshape(X_train, (X_train.shape[0], 28, 28, 1)) X_test = np.reshape(X_test, (X_test.shape[0], 28, 28, 1)) print(X_train.shape, y_train.shape, X_test.shape, y_test.shape, len(emnist_labels)) k = 10 X_train = X_train[:X_train.shape[0] // k] y_train = y_train[:y_train.shape[0] // k] X_test = X_test[:X_test.shape[0] // k] y_test = y_test[:y_test.shape[0] // k]
Hemos preparado dos juegos para entrenamiento y validación. Los caracteres en sí mismos son matrices comunes que son fáciles de mostrar:

También usamos solo 1/10 del conjunto de datos para el entrenamiento (parámetro k), de lo contrario, el proceso tomará al menos 10 horas.
Comenzamos el entrenamiento en red, al final del proceso guardamos el modelo entrenado en el disco.
El proceso de aprendizaje en sí toma aproximadamente media hora:
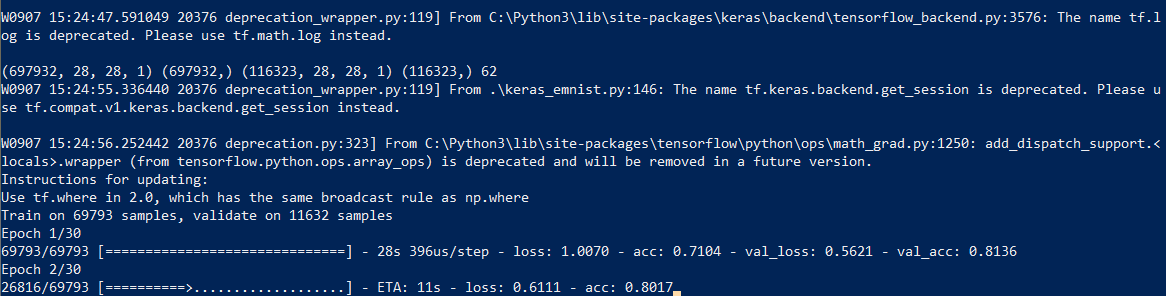
Esto debe hacerse solo una vez, luego usaremos el archivo de modelo ya guardado. Cuando finaliza el entrenamiento, todo está listo, puede reconocer el texto.
Reconocimiento
Para el reconocimiento, cargamos el modelo y llamamos a la función predict_classes.
model = keras.models.load_model('emnist_letters.h5') def emnist_predict_img(model, img): img_arr = np.expand_dims(img, axis=0) img_arr = 1 - img_arr/255.0 img_arr[0] = np.rot90(img_arr[0], 3) img_arr[0] = np.fliplr(img_arr[0]) img_arr = img_arr.reshape((1, 28, 28, 1)) result = model.predict_classes([img_arr]) return chr(emnist_labels[result[0]])
Al final resultó que, las imágenes en el conjunto de datos se rotaron inicialmente, por lo que tenemos que rotar la imagen antes del reconocimiento.
La función final, que recibe un archivo con una imagen en la entrada y da una línea en la salida, ocupa solo 10 líneas de código:
def img_to_str(model: Any, image_file: str): letters = letters_extract(image_file) s_out = "" for i in range(len(letters)): dn = letters[i+1][0] - letters[i][0] - letters[i][1] if i < len(letters) - 1 else 0 s_out += emnist_predict_img(model, letters[i][2]) if (dn > letters[i][1]/4): s_out += ' ' return s_out
Aquí usamos el ancho de caracteres previamente guardado para agregar espacios si el espacio entre letras es más de 1/4 del carácter.
Ejemplo de uso:
model = keras.models.load_model('emnist_letters.h5') s_out = img_to_str(model, "hello_world.png") print(s_out)
Resultado:

Una característica divertida es que la red neuronal "confundió" la letra "O" y el número "0", lo cual, sin embargo, no es sorprendente ya que El conjunto original de EMNIST contiene letras y números
escritos a mano que no son exactamente como los impresos. Idealmente, para reconocer textos de pantalla, debe preparar un conjunto separado basado en las fuentes de pantalla, y ya entrenar una red neuronal en él.
Conclusión
Como puede ver, no son los dioses los que queman las ollas, y lo que una vez pareció ser "mágico" con la ayuda de las bibliotecas modernas es bastante simple.
Dado que Python es multiplataforma, el código funcionará en todas partes, en Windows, Linux y OSX. Al igual que Keras está portado a iOS / Android, teóricamente, el modelo entrenado también se puede usar en
dispositivos móviles .
Para aquellos que quieran experimentar por su cuenta, el código fuente está bajo el spoiler.
Como de costumbre, todos los experimentos exitosos.