Continuación de la traducción de un pequeño libro:
"Comprender los corredores de mensajes",
autor: Jakub Korab, editor: O'Reilly Media, Inc., fecha de publicación: junio de 2017, ISBN: 9781492049296.
Traducción completada: tele.gg/middle_javaParte anterior:
Comprender los corredores de mensajes. Aprendiendo la mecánica de la mensajería a través de ActiveMQ y Kafka. Capítulo 2. ActiveMQCAPITULO 3
Kafka
Kafka se desarrolló en LinkedIn para eludir algunas de las limitaciones de los corredores de mensajes tradicionales y evitar la necesidad de configurar múltiples corredores de mensajes para diferentes interacciones punto a punto, que se describe en la sección "Escalado vertical y horizontal" en la página 28 de este libro. LinkedIn se basó en gran medida en la absorción unidireccional de grandes cantidades de datos, como los clics de página y los registros de acceso, al tiempo que permitía que varios sistemas usaran estos datos. de la mañana, sin afectar al rendimiento de otros productores o konsyumerov. De hecho, la razón por la que existe Kafka es para obtener la arquitectura de mensajería que describe Universal Data Pipeline.
Dado este objetivo final, surgieron naturalmente otros requisitos. Kafka debe:
- Se extremadamente rápido
- Proporcionar un mayor rendimiento de mensajería
- Admite modelos de editor-suscriptor y punto a punto
- No disminuya la velocidad con la adición de consumidores. Por ejemplo, el rendimiento de las colas y los temas en ActiveMQ se deteriora a medida que aumenta el número de consumidores en el destino.
- Ser horizontalmente escalable; si un solo mensaje persiste solo puede hacerlo a la velocidad máxima del disco, entonces para aumentar el rendimiento tiene sentido ir más allá de los límites de una instancia de agente
- Delinear el acceso al almacenamiento y recuperación de mensajes
Para lograr todo esto, Kafka ha adoptado una arquitectura que redefinió los roles y responsabilidades de los clientes y los corredores de mensajería. El modelo JMS está muy centrado en el corredor, donde es responsable de la distribución de mensajes, y los clientes solo tienen que preocuparse por enviar y recibir mensajes. Kafka, por otro lado, está orientado al cliente, y el cliente asume muchas de las funciones de un agente tradicional, como la distribución justa de mensajes relevantes entre los consumidores, a cambio de recibir un agente extremadamente rápido y escalable. Para las personas que trabajan con sistemas de mensajería tradicionales, trabajar con Kafka requiere un cambio fundamental de actitud.
Esta dirección de ingeniería ha llevado a la creación de una infraestructura de mensajería que puede aumentar el rendimiento en muchos órdenes de magnitud en comparación con un agente convencional. Como veremos, este enfoque está lleno de compromisos, lo que significa que Kafka no es adecuado para ciertos tipos de cargas y software instalado.
Modelo de destino unificado
Para cumplir con los requisitos descritos anteriormente, Kafka combinó la publicación-suscripción y la mensajería punto a punto en un tipo de destinatario: el
tema . Esto es confuso para las personas que trabajan con sistemas de mensajería, donde la palabra "tema" se refiere a un mecanismo de transmisión desde el cual la lectura (del tema) no es confiable (no es duradera). Los temas de Kafka deben considerarse un tipo de destino híbrido, como se define en la introducción de este libro.
En el resto de este capítulo, a menos que especifiquemos explícitamente lo contrario, el término tema se referirá al tema de Kafka.
Para comprender completamente cómo se comportan los temas y qué garantías ofrecen, primero debemos considerar cómo se implementan en Kafka.
Cada tema en Kafka tiene su propio diario.Los productores que envían mensajes a Kafka se anexan a esta revista, y los consumidores leen la revista utilizando punteros que avanzan constantemente. Kafka elimina periódicamente las partes más antiguas del diario, independientemente de si los mensajes en estas partes se leyeron o no. Una parte central del diseño de Kafka es que al agente no le importa si los mensajes se leen o no, esto es responsabilidad del cliente.
Los términos "revista" e "índice" no se encuentran en la documentación de Kafka . Estos términos bien conocidos se usan aquí para ayudar a comprender.
Este modelo es completamente diferente de ActiveMQ, donde los mensajes de todas las colas se almacenan en un diario, y el intermediario marca los mensajes como eliminados después de haberlos leído.
Veamos ahora un poco más y miremos la revista temática con más detalle.
Kafka Magazine consta de varias particiones (
Figura 3-1 ). Kafka garantiza un orden estricto en cada partición. Esto significa que los mensajes escritos en la partición en cierto orden se leerán en el mismo orden. Cada partición se implementa como un archivo de registro (log) que contiene un
subconjunto de todos los mensajes enviados al tema por sus productores. El tema creado contiene una partición por defecto. Particionar es la idea central de Kafka para el escalado horizontal.
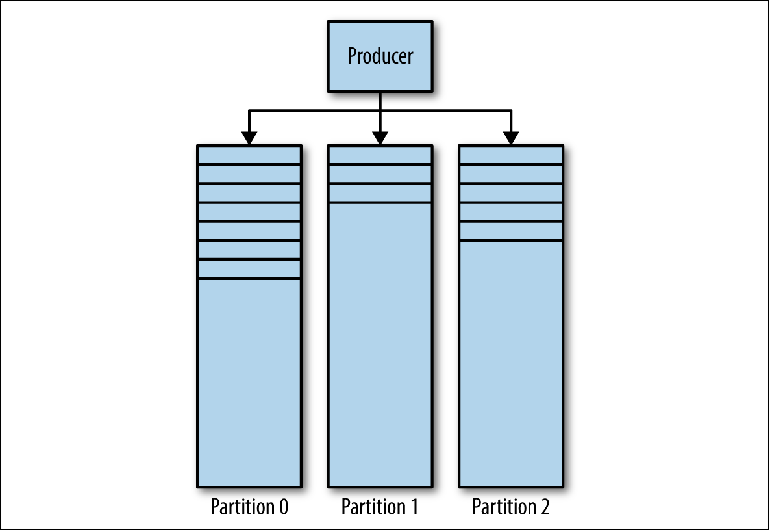 Figura 3-1. Particiones Kafka
Figura 3-1. Particiones KafkaCuando el productor envía un mensaje al tema de Kafka, decide a qué partición enviar el mensaje. Consideraremos esto con más detalle más adelante.
Leer mensajes
Un cliente que quiere leer mensajes controla un puntero con nombre llamado
grupo de consumidores , que indica el
desplazamiento de un mensaje en una partición. Un desplazamiento es una posición con un número creciente que comienza en 0 al comienzo de la partición. Este grupo de consumidores, al que se hace referencia en la API a través de un identificador definido por el usuario group_id, corresponde a un
único consumidor o sistema lógico .
La mayoría de los sistemas de mensajería leen datos del destinatario a través de múltiples instancias y subprocesos para procesar mensajes en paralelo. Por lo tanto, generalmente habrá muchos casos de consumidores que comparten el mismo grupo de consumidores.
El problema de lectura se puede representar de la siguiente manera:
- El tema tiene varias particiones.
- Varios grupos de consumidores pueden usar el tema al mismo tiempo.
- Un grupo de consumidores puede tener varias instancias separadas.
Este es un problema no trivial de muchos a muchos. Para comprender cómo Kafka maneja las relaciones entre grupos de consumidores, instancias de consumidores y particiones, echemos un vistazo a una serie de guiones de lectura cada vez más complejos.
Consumidores y grupos de consumidores
Tomemos un tema de partición única como punto de partida (
Figura 3-2 ).
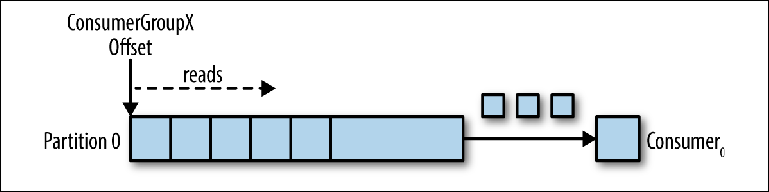 Figura 3-2. El consumidor lee desde la partición
Figura 3-2. El consumidor lee desde la particiónCuando una instancia de consumidor se conecta con su propio group_id a este tema, se le asigna una partición para leer y un desplazamiento en esta partición. La posición de este desplazamiento se configura en el cliente como un puntero a la posición más reciente (el mensaje más reciente) o la posición más temprana (el mensaje más antiguo). El consumidor solicita mensajes (encuestas) del tema, lo que lleva a su lectura secuencial de la revista.
La posición de desplazamiento se devuelve regularmente a Kafka y se guarda como mensajes en el tema interno
_consumer_offsets . Los mensajes leídos aún no se eliminan, a diferencia de un intermediario normal, y el cliente puede rebobinar el desplazamiento para volver a procesar los mensajes ya vistos.
Cuando se conecta un segundo consumidor lógico usando otro group_id, controla un segundo puntero que es independiente del primero (
Figura 3-3 ). Por lo tanto, el tema de Kafka actúa como una cola en la que hay un consumidor y, como tema habitual, un editor-suscriptor (pub-sub), al que se suscriben varios consumidores, con la ventaja adicional de que todos los mensajes se guardan y pueden procesarse varias veces.
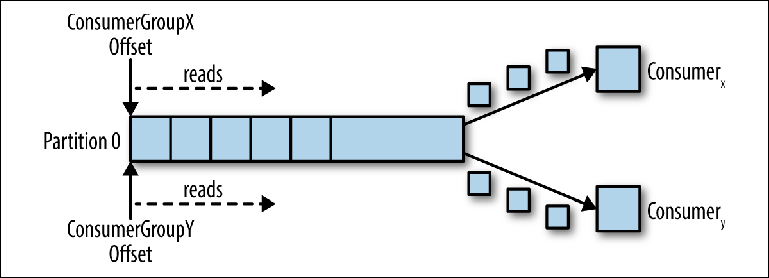 Figura 3-3. Dos consumidores en diferentes grupos de consumidores leen desde la misma partición
Figura 3-3. Dos consumidores en diferentes grupos de consumidores leen desde la misma particiónConsumidores en el grupo de consumidores
Cuando una instancia del consumidor lee datos de la partición, controla completamente el puntero y procesa los mensajes, como se describe en la sección anterior.
Si varias instancias de los consumidores se conectaron con el mismo group_id al tema con una partición, entonces la instancia que se conectó en último lugar tendrá el control sobre el puntero y, a partir de ese momento, recibirá todos los mensajes (
Figura 3-4 ).
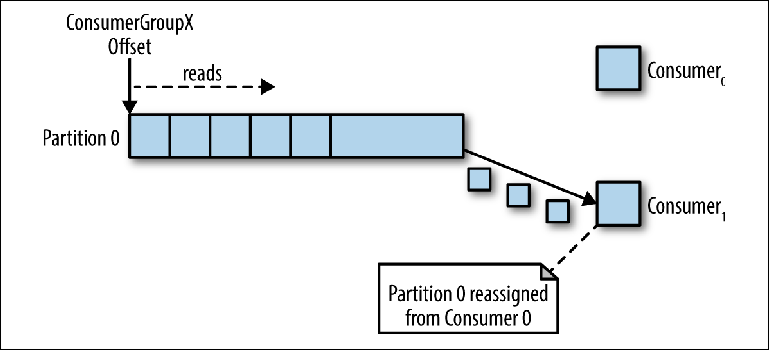 Figura 3-4. Dos consumidores en el mismo grupo de consumidores leen desde la misma partición
Figura 3-4. Dos consumidores en el mismo grupo de consumidores leen desde la misma particiónEste modo de procesamiento, en el que el número de instancias de consumidores excede el número de particiones, puede considerarse como un tipo de consumidor monopolista. Esto puede ser útil si necesita la agrupación "activa-pasiva" (o "caliente-caliente") de sus instancias de consumidores, aunque la operación paralela de varios consumidores ("activo-activo" o "caliente-caliente") es mucho más típica que los consumidores en modo de espera.
Este comportamiento de distribución de mensajes, descrito anteriormente, puede ser sorprendente en comparación con el comportamiento de una cola JMS normal. En este modelo, los mensajes enviados a la cola se distribuirán uniformemente entre los dos consumidores.
Muy a menudo, cuando creamos varias instancias de compiladores, lo hacemos para el procesamiento paralelo de mensajes, para aumentar la velocidad de lectura o para aumentar la estabilidad del proceso de lectura. Dado que solo una instancia de un consumidor puede leer datos de una partición, ¿cómo se logra esto en Kafka?
Una forma de hacerlo es usar una instancia del consumidor para leer todos los mensajes y enviarlos al grupo de subprocesos. Aunque este enfoque aumenta el rendimiento del procesamiento, aumenta la complejidad de la lógica de los consumidores y no hace nada para aumentar la estabilidad del sistema de lectura. Si una instancia del consumidor se apaga debido a una falla de energía o un evento similar, entonces la revisión se detiene.
La forma canónica de resolver este problema en Kafka es usar más particiones.
Particionamiento
Las particiones son el mecanismo principal para paralelizar la lectura y la escala del tema más allá del ancho de banda de una instancia del intermediario. Para comprender mejor esto, veamos una situación en la que hay un tema con dos particiones y un consumidor se suscribe a este tema (
Figura 3-5 ).
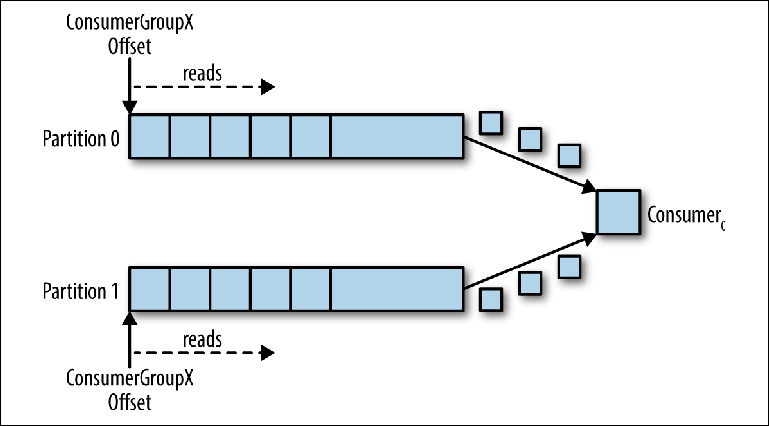 Figura 3-5. Un consumidor lee desde varias particiones
Figura 3-5. Un consumidor lee desde varias particionesEn este escenario, el consultor tiene control sobre los punteros correspondientes a su group_id en ambas particiones, y comienza la lectura de mensajes de ambas particiones.
Cuando se agrega un compilador adicional a este tema para el mismo group_id, Kafka reasigna (reasigna) una de las particiones de la primera a la segunda. Después de eso, cada instancia del consumidor se restará de una partición del tema (
Figura 3-6 ).
Para garantizar que los mensajes se procesen en paralelo en 20 hilos, necesitará al menos 20 particiones. Si habrá menos particiones, seguirá teniendo consumidores que no tienen nada en qué trabajar, como se describió anteriormente en la discusión de monitores exclusivos.
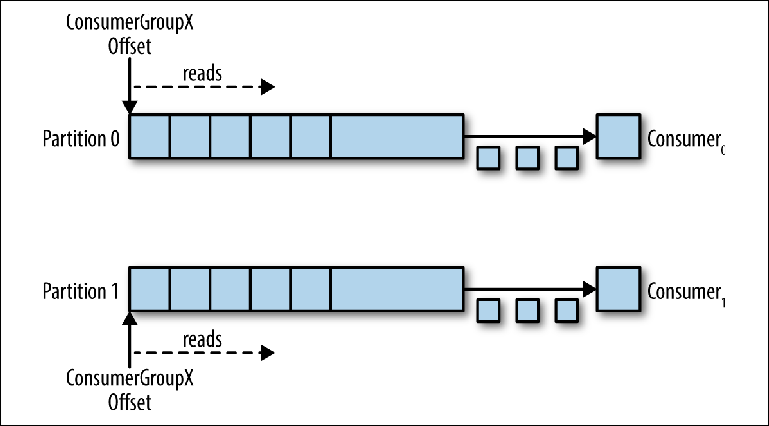 Figura 3-6. Dos consumidores en el mismo grupo de consumidores leen desde diferentes particiones
Figura 3-6. Dos consumidores en el mismo grupo de consumidores leen desde diferentes particionesEste esquema reduce significativamente la complejidad del agente Kafka en comparación con la distribución de mensajes necesaria para admitir la cola JMS. No es necesario ocuparse de los siguientes puntos:
- Qué consumidor debe recibir el siguiente mensaje en función de la distribución por turnos, la capacidad de almacenamiento intermedio de captación previa actual o los mensajes anteriores (como para los grupos de mensajes JMS).
- Qué mensajes se enviaron a qué consumidores y si deberían reenviarse en caso de falla.
Todo lo que el corredor de Kafka debe hacer es enviar mensajes consistentemente al asesor cuando este lo solicite.
Sin embargo, los requisitos para paralelizar la corrección de pruebas y el reenvío de mensajes fallidos no desaparecen; la responsabilidad de ellos simplemente pasa del intermediario al cliente. Esto significa que deben tenerse en cuenta en su código.
Enviando mensajes
La responsabilidad de decidir a qué partición enviar el mensaje es el productor del mensaje. Para comprender el mecanismo por el cual se hace esto, primero debe considerar qué es lo que estamos enviando exactamente.
Mientras que en JMS usamos una estructura de mensaje con metadatos (encabezados y propiedades) y un cuerpo que contiene una carga útil, en Kafka el mensaje es
un par clave-valor . La carga útil del mensaje se envía como un valor. Una clave, por otro lado, se usa principalmente para particionar y debe contener una
clave específica de lógica de negocios para colocar mensajes relacionados en la misma partición.
En el Capítulo 2, discutimos el escenario de apuestas en línea, cuando los eventos relacionados deben ser procesados en orden por un solo consumidor:
- La cuenta de usuario está configurada.
- El dinero se acredita en la cuenta.
- Se realiza una apuesta que retira dinero de la cuenta.
Si cada evento es un mensaje enviado al tema, en este caso el identificador de la cuenta será la clave natural.
Cuando se envía un mensaje utilizando la API de Kafka Producer, se pasa a la función de partición, que, dado el mensaje y el estado actual del clúster de Kafka, devuelve el identificador de la partición a la que se debe enviar el mensaje. Esta característica se implementa en Java a través de la interfaz Partitioner.
Esta interfaz es la siguiente:
interface Partitioner { int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster); }
La implementación del Partitioner usa el algoritmo de hash de propósito general predeterminado sobre la clave o round-robin si la clave no se especifica para determinar la partición. Este valor predeterminado funciona bien en la mayoría de los casos. Sin embargo, en el futuro querrás escribir el tuyo.
Escribir su propia estrategia de partición
Veamos un ejemplo cuando desea enviar metadatos junto con la carga útil del mensaje. La carga útil en nuestro ejemplo es una instrucción para hacer un depósito en una cuenta de juego. Una instrucción es algo que nos gustaría garantizar que no se modifique durante la transmisión, y queremos asegurarnos de que solo un sistema superior confiable pueda iniciar esta instrucción. En este caso, los sistemas de envío y recepción acuerdan el uso de la firma para autenticar el mensaje.
En un JMS normal, simplemente definimos la propiedad de firma del mensaje y la agregamos al mensaje. Sin embargo, Kafka no nos proporciona un mecanismo para transmitir metadatos, solo la clave y el valor.
Dado que el valor es la carga útil de una transferencia bancaria (carga útil de transferencia bancaria), cuya integridad queremos mantener, no tenemos más remedio que determinar la estructura de datos para usar en la clave. Suponiendo que necesitamos un identificador de cuenta para la partición, ya que todos los mensajes relacionados con la cuenta deben procesarse en orden, se nos ocurrirá la siguiente estructura JSON:
{ "signature": "541661622185851c248b41bf0cea7ad0", "accountId": "10007865234" }
Debido a que el valor de la firma variará dependiendo de la carga útil, la estrategia de hash de la interfaz Partitioner predeterminada no agrupará de manera confiable los mensajes relacionados. Por lo tanto, necesitaremos escribir nuestra propia estrategia, que analizará esta clave y compartirá el valor de accountId.
Kafka incluye sumas de verificación para detectar la corrupción de mensajes en el repositorio y tiene un conjunto completo de características de seguridad. Incluso entonces, a veces aparecen requisitos específicos de la industria, como el anterior.
La estrategia de partición del usuario debe garantizar que todos los mensajes relacionados terminen en la misma partición. Aunque esto parece simple, el requisito puede ser complicado debido a la importancia de ordenar los mensajes relacionados y cuán fijo es el número de particiones en el tema.
El número de particiones en el tema puede cambiar con el tiempo, ya que se pueden agregar si el tráfico supera las expectativas iniciales. Por lo tanto, las claves de mensaje se pueden asociar con la partición a la que se enviaron originalmente, lo que implica una parte del estado que debe distribuirse entre las instancias del productor.
Otro factor a considerar es la distribución uniforme de mensajes entre particiones. Como regla general, las claves no se distribuyen uniformemente entre los mensajes, y las funciones hash no garantizan una distribución justa de los mensajes para un pequeño conjunto de claves.
Es importante tener en cuenta que, sin importar cómo decida dividir los mensajes, el separador en sí puede necesitar ser reutilizado.
Considere el requisito para la replicación de datos entre grupos de Kafka en diferentes ubicaciones geográficas. Para este propósito, Kafka viene con una herramienta de línea de comandos llamada MirrorMaker, que se usa para leer mensajes de un clúster y transferirlos a otro.
MirrorMaker debe comprender las claves del tema replicado para mantener el orden relativo entre mensajes durante la replicación entre clústeres, ya que el número de particiones para este tema puede no coincidir en dos clústeres.
Las estrategias de particionamiento personalizadas son relativamente raras, ya que los hashes predeterminados o el round robin funcionan con éxito en la mayoría de los escenarios. Sin embargo, si necesita garantías estrictas de pedido o si necesita extraer metadatos de las cargas útiles, la partición es algo que debe observar más de cerca.
Los beneficios de escalabilidad y rendimiento de Kafka provienen de la transferencia de algunas de las responsabilidades de un corredor tradicional a un cliente. En este caso, se toma una decisión sobre la distribución de mensajes potencialmente relacionados entre varios consumidores que trabajan en paralelo.
Los corredores de JMS también deben ocuparse de tales requisitos. Curiosamente, el mecanismo para enviar mensajes relacionados a la misma cuenta implementada a través de los grupos de mensajes JMS (una especie de estrategia de equilibrio de equilibrio de carga fija (SLB)) también requiere que el remitente marque los mensajes como relacionados. En el caso de JMS, el agente es responsable de enviar este grupo de mensajes relacionados a uno de los muchos clientes y transferir la propiedad del grupo si el cliente se ha caído.
Acuerdo del productor
Particionar no es lo único a tener en cuenta al enviar mensajes. Veamos los métodos send () de la clase Productor en la API de Java:
Future < RecordMetadata > send(ProducerRecord < K, V > record); Future < RecordMetadata > send(ProducerRecord < K, V > record, Callback callback);
Debe notarse de inmediato que ambos métodos devuelven Future, lo que indica que la operación de envío no se realiza de inmediato. Como resultado, resulta que el mensaje (ProducerRecord) se escribe en el búfer de envío para cada partición activa y se transmite al intermediario en la secuencia de fondo en la biblioteca del cliente Kafka. Aunque esto hace que el trabajo sea increíblemente rápido, significa que una aplicación sin experiencia puede perder mensajes si se detiene su proceso.
Como siempre, hay una manera de hacer que la operación de envío sea más confiable debido al rendimiento. El tamaño de este búfer se puede establecer en 0, y el hilo de la aplicación de envío se verá obligado a esperar hasta que el mensaje se envíe al intermediario, de la siguiente manera:
RecordMetadata metadata = producer.send(record).get();
Una vez más sobre leer mensajes
Leer mensajes tiene dificultades adicionales que deben considerarse. A diferencia de la API JMS, que puede iniciar un escucha de mensajes en respuesta a un mensaje, la interfaz
Consumer Kafka solo sondea. Echemos un vistazo más de cerca al método
poll () utilizado para este propósito:
ConsumerRecords < K, V > poll(long timeout);
El valor de retorno del método es una estructura de contenedor que contiene varios objetos
ConsumerRecord de potencialmente varias particiones.
Un ConsumerRecord en sí mismo es un objeto titular para un par clave-valor con metadatos asociados, como la partición de la que se deriva.
Como se discutió en el Capítulo 2, debemos recordar constantemente lo que sucede con los mensajes después de que se procesan con éxito o sin éxito, por ejemplo, si el cliente no puede procesar el mensaje o si interrumpe el trabajo. En JMS, esto se manejó a través del modo de reconocimiento. El intermediario eliminará el mensaje procesado con éxito o volverá a entregar el mensaje sin formato o invertido (siempre que se hayan utilizado las transacciones).
Kafka funciona de una manera completamente diferente. Los mensajes no se eliminan en el intermediario después de la corrección de pruebas, y la responsabilidad de lo que sucede en caso de falla recae en el código mismo.
Como ya dijimos, un grupo de consumidores está asociado con una compensación en la revista. La posición de registro asociada con este sesgo corresponde al siguiente mensaje que se emitirá en respuesta a
poll () . Un punto crucial en la lectura es el momento en que aumenta este desplazamiento.
Volviendo al modelo de lectura discutido anteriormente, el procesamiento de mensajes consta de tres etapas:
- Recuperar un mensaje para leer.
- Procesar el mensaje.
- Confirmar mensaje.
Kafka Consumer Advisor viene con la
opción de configuración
enable.auto.commit . Esta es una configuración predeterminada de uso común, como suele ser el caso con la configuración que contiene la palabra "auto".
Antes de Kafka 0.10, el cliente que usaba este parámetro enviaba el desplazamiento del último mensaje leído en la siguiente llamada
poll () después del procesamiento. Esto significaba que cualquier mensaje que ya hubiera sido recuperado podría volver a procesarse si el cliente ya lo había procesado, pero se destruyó inesperadamente antes de llamar a
poll () . Como el agente no mantiene ningún estado con respecto a cuántas veces se ha leído el mensaje, el próximo consumidor que recupere este mensaje no sabrá que algo malo ha sucedido. Este comportamiento fue pseudo transaccional. El desplazamiento se confirmó solo en caso de procesamiento exitoso del mensaje, pero si el cliente interrumpió, el agente nuevamente envió el mismo mensaje a otro cliente. Este comportamiento era consistente con la garantía de entrega de mensajes "
al menos una vez ".
En Kafka 0.10, el código del cliente se cambió de tal manera que la biblioteca del cliente comenzó a iniciar periódicamente la confirmación, de acuerdo con la configuración
auto.commit.interval.ms . Este comportamiento se encuentra entre los modos JMS AUTO_ACKNOWLEDGE y DUPS_OK_ACKNOWLEDGE. Cuando se utiliza la confirmación automática, los mensajes pueden confirmarse independientemente de si realmente se procesaron; esto podría suceder en el caso de un consumidor lento. Si se interrumpió el compilador, el siguiente compilador recuperó los mensajes, comenzando desde una posición segura, lo que podría provocar que se saltara un mensaje. En este caso, Kafka no perdió mensajes, el código de lectura simplemente no los procesó.
Este modo tiene las mismas perspectivas que en la versión 0.9: los mensajes pueden procesarse, pero en caso de falla, el desplazamiento puede no cerrarse, lo que podría conducir a una duplicación de la entrega. Cuantos más mensajes recupere al hacer
sondeo () , mayor será este problema.
Como se discutió en la
sección "Restar mensajes de la cola" en el
Capítulo 2 , no existe una entrega de mensajes única en el sistema de mensajería, dados los modos de falla.
En Kafka, hay dos formas de arreglar (confirmar) un desplazamiento (desplazamiento): automática y manualmente. En ambos casos, los mensajes se pueden procesar varias veces, en el caso de que el mensaje se haya procesado pero haya fallado antes de la confirmación. Tampoco puede procesar el mensaje si la confirmación se produjo en segundo plano y su código se completó antes de que comenzara a procesarse (posiblemente en Kafka 0.9 y versiones anteriores).
Puede controlar el proceso de confirmación de compensaciones manualmente en la API de Kafka
Consumer configurando
enable.auto.commit en falso y llamando explícitamente a uno de los siguientes métodos:
void commitSync(); void commitAsync();
Si desea procesar el mensaje "al menos una vez", debe confirmar el desplazamiento manualmente mediante
commitSync () ejecutando este comando inmediatamente después de procesar los mensajes.
Estos métodos no permiten que se procesen los mensajes reconocidos antes de que se procesen, pero no hacen nada para eliminar la posible duplicación de procesamiento, al tiempo que crean la apariencia de transaccionalidad. Kafka no tiene transacciones. El cliente no tiene la oportunidad de hacer lo siguiente:
- Revierte automáticamente un mensaje de reversión. Los consumidores mismos deben manejar las excepciones que surgen de cargas útiles problemáticas y desconexiones de backend, ya que no pueden confiar en el corredor para volver a entregar mensajes.
- Enviar mensajes a varios temas dentro de una operación atómica. Como veremos pronto, el control sobre varios temas y particiones se puede ubicar en diferentes máquinas en el clúster de Kafka, que no coordinan las transacciones al enviarlas. Al momento de escribir este artículo, se ha trabajado para hacer esto posible con el KIP-98.
- Asociar la lectura de un mensaje de un tema con el envío de otro mensaje a otro tema. Una vez más, la arquitectura de Kafka depende de muchas máquinas independientes que funcionan como un solo bus y no se intenta ocultarlo. Por ejemplo, no hay componentes API que permitan vincular al consumidor y al productor en una transacción. En JMS, esto es proporcionado por el objeto Session a partir del cual se crean MessageProducers y MessageConsumers .
Si no podemos confiar en las transacciones, ¿cómo podemos proporcionar una semántica más cercana a las proporcionadas por los sistemas de mensajería tradicionales?
Si existe la posibilidad de que la compensación del consumidor pueda aumentar antes de que se haya procesado el mensaje, por ejemplo, durante el fallo del cliente, entonces el cliente no tendrá forma de saber si el grupo de clientes ha perdido el mensaje cuando se asigna la partición. Por lo tanto, una estrategia es rebobinar el desplazamiento a la posición anterior. La API de Kafka Consumer Advisor proporciona los siguientes métodos para esto:
void seek(TopicPartition partition, long offset); void seekToBeginning(Collection < TopicPartition > partitions);
El método
seek () se puede usar con el método
offsetsForTimes (Map <TopicPartition, Long> timestampsToSearch) para rebobinar a un estado en cualquier punto en particular en el pasado.
Implícitamente, el uso de este enfoque significa que es muy probable que algunos mensajes que fueron procesados anteriormente sean leídos y procesados nuevamente. Para evitar esto, podemos usar lecturas idempotentes, como se describe en el Capítulo 4, para rastrear mensajes vistos anteriormente y eliminar duplicados.
Como alternativa, el código de su consumidor puede ser simple si se permite la pérdida o la duplicación de mensajes. Cuando observamos escenarios de uso para los que se usa Kafka, por ejemplo, para procesar eventos de registro, métricas, seguimiento de clics, etc., entendemos que es poco probable que la pérdida de mensajes individuales tenga un impacto significativo en las aplicaciones circundantes. En tales casos, los valores predeterminados son aceptables. Por otro lado, si su aplicación necesita transferir pagos, debe cuidar cuidadosamente cada mensaje individual. Todo se reduce al contexto.
Las observaciones personales muestran que al aumentar la intensidad del mensaje, el valor de cada mensaje individual disminuye. Los mensajes de gran volumen tienden a ser valiosos cuando se ven en forma agregada.
Alta disponibilidad
El enfoque de alta disponibilidad de Kafka es muy diferente de ActiveMQ. Kafka se desarrolla sobre la base de clústeres escalables horizontalmente en los que todas las instancias del intermediario reciben y distribuyen mensajes simultáneamente.
El clúster Kafka consta de varias instancias de intermediario que se ejecutan en diferentes servidores. Kafka fue diseñado para trabajar en un hardware convencional independiente, donde cada nodo tiene su propio almacenamiento dedicado. No se recomienda el uso de Almacenamiento conectado a la red (SAN) porque varios nodos de cómputo pueden competir por intervalos de tiempo de almacenamiento y crear conflictos.
Kafka es un sistema
constantemente en funcionamiento. Muchos usuarios grandes de Kafka nunca extinguen sus clústeres y el software siempre proporciona actualizaciones a través de un reinicio constante. Esto se logra garantizando la compatibilidad con la versión anterior para mensajes e interacciones entre corredores.
Los intermediarios están conectados a un
clúster de servidores de
ZooKeeper , que actúa como un registro de configuración determinado y se utiliza para coordinar los roles de cada intermediario. ZooKeeper es un sistema distribuido que proporciona alta disponibilidad a través de la replicación de información mediante el establecimiento de un
quórum .
En el caso base, el tema se crea en el clúster de Kafka con las siguientes propiedades:
- El número de particiones. Como se discutió anteriormente, el valor exacto utilizado aquí depende del nivel deseado de lectura concurrente.
- El coeficiente de replicación (factor) determina cuántas instancias de intermediario en el clúster deben contener los registros de esta partición.
Usando ZooKeepers para la coordinación, Kafka está tratando de distribuir de manera justa nuevas particiones entre los corredores en el clúster. Esto lo hace una instancia, que actúa como el controlador.
En tiempo
de ejecución
para cada partición del tema, el Controlador asigna al corredor los roles de
líder (líder, maestro, líder) y
seguidores (seguidores, esclavos, subordinados). El corredor, que actúa como líder de esta partición, es responsable de recibir todos los mensajes que le envían los productores y de distribuirlos a los consumidores. Al enviar mensajes a una partición de tema, se replican en todos los nodos del intermediario que actúan como seguidores de esta partición. Cada nodo que contiene los registros de la partición se denomina
réplica . Un corredor puede actuar como líder para algunas particiones y como seguidor para otras.
Un seguidor que contiene todos los mensajes almacenados por el líder se llama
réplica sincronizada (una réplica en un estado sincronizado, réplica sincronizada). Si el agente que actúa como líder de la partición está desconectado, cualquier agente que se encuentre en el estado actualizado o sincronizado para esta partición puede asumir el rol de líder. Este es un diseño increíblemente sostenible.
Parte de la configuración del productor es el parámetro
acks , que determina cuántas réplicas deben acusar recibo de un mensaje antes de que el flujo de la aplicación continúe enviando: 0, 1 o todos. Si el valor se establece en
todos , cuando se reciba el mensaje, el líder enviará una confirmación al productor tan pronto como reciba la confirmación de varias réplicas (incluido él mismo) definidas por la
configuración del tema
min.insync.replicas (por defecto 1). Si el mensaje no se puede replicar con éxito, entonces el productor lanzará una excepción para la aplicación (
NotEnoughReplicas o
NotEnoughReplicasAfterAppend ).
En una configuración típica, se crea un tema con un coeficiente de replicación de 3 (1 líder, 2 seguidores para cada partición) y el parámetro min.insync.replicas se establece en 2. En este caso, el clúster permitirá que uno de los intermediarios que administran la partición se desconecte sin afectar las aplicaciones del cliente.Esto nos devuelve al compromiso ya familiar entre rendimiento y confiabilidad. La replicación ocurre debido al tiempo de espera adicional para los reconocimientos (reconocimientos) de los seguidores. Aunque, dado que se ejecuta en paralelo, la replicación de al menos tres nodos tiene el mismo rendimiento que dos (ignorando el aumento en el uso del ancho de banda de la red).Usando este esquema de replicación, Kafka evita hábilmente la necesidad de escribir físicamente cada mensaje en el disco utilizando la operación sync () . Cada mensaje enviado por el productor se escribirá en el registro de partición, pero, como se discutió en el Capítulo 2, la escritura en el archivo se realiza inicialmente en el búfer del sistema operativo. Si este mensaje se replica a otra instancia de Kafka y está en su memoria, la pérdida de un líder no significa que el mensaje en sí se haya perdido, una réplica sincronizada puede asumirlo.Desactivar la operación de sincronización ()significa que Kafka puede recibir mensajes a la velocidad con la que puede escribirlos en la memoria. Por el contrario, cuanto más tiempo pueda evitar vaciar la memoria en el disco, mejor. Por esta razón, no es raro que los corredores de Kafka asignen 64 GB o más de memoria. Este uso de memoria significa que una instancia de Kafka puede funcionar fácilmente a velocidades miles de veces más rápidas que un agente de mensajes tradicional.Kafka también se puede configurar para usar sync ()para enviar paquetes de mensajes. Dado que todo en Kafka está orientado a paquetes, en realidad funciona bastante bien para muchos casos de uso y es una herramienta útil para usuarios que requieren garantías muy sólidas. La mayor parte del rendimiento puro de Kafka está relacionado con los mensajes que se envían al intermediario en forma de paquetes, y al hecho de que estos mensajes se leen del intermediario en bloques sucesivos utilizando operaciones de copia cero (operaciones que no realizan la tarea de copiar datos de un área de memoria a otro) Esta última es una gran ganancia en términos de rendimiento y recursos y solo es posible mediante el uso de la estructura de datos de registro subyacente que define el esquema de partición.En un clúster Kafka, es posible un rendimiento mucho mayor que cuando se usa un solo agente Kafka, ya que las particiones temáticas se pueden escalar horizontalmente en muchas máquinas separadas.Resumen
En este capítulo, examinamos cómo la arquitectura Kafka reinterpreta la relación entre clientes y corredores para proporcionar una canalización de mensajes increíblemente robusta, con un ancho de banda muchas veces mayor que un corredor de mensajes normal. Discutimos la funcionalidad que utiliza para lograr este objetivo, y revisamos brevemente la arquitectura de las aplicaciones que proporcionan esta funcionalidad. En el próximo capítulo, discutiremos los problemas comunes que las aplicaciones de mensajería necesitan resolver y las estrategias para resolverlos. Concluimos el capítulo describiendo cómo hablar sobre tecnologías de mensajería en general para que pueda evaluar su idoneidad para sus casos de uso.Traducción completada: tele.gg/middle_javaContinuará ...