En Internet, los captchas siguen siendo relevantes, lo que como opción ofrece escuchar el texto de la imagen haciendo clic en el botón correspondiente. Si alguien está familiarizado con la imagen a continuación y / o está interesado en cómo evitarlo utilizando un sistema de reconocimiento de sonido fuera de línea, se sugiere leerlo.
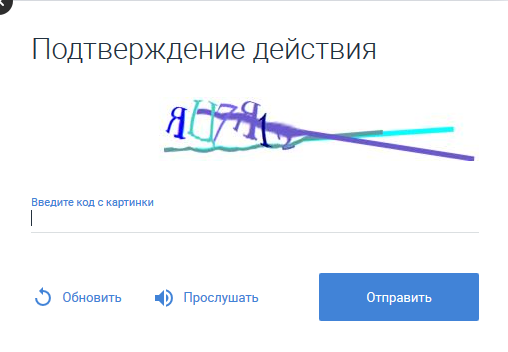
No atormentaremos las intrigas de especialistas en el campo del reconocimiento de voz, afirmando de inmediato que no se ha desarrollado ningún sistema de reconocimiento de voz patentado para los fines establecidos. El artículo utiliza el viejo Pocketsphinx, pero con cierto grado de personalización.
Preparación
"Te encuentras con la oficina de competidores que tienen control de voz en las computadoras, gritas" Era de Sudo menos Eref Home "y te escapas". De los comentarios.
Entonces, el captcha ofrece escucharse a sí mismo haciendo clic en el botón correspondiente. Si guarda el archivo de sonido resultante, puede averiguar cómo es una pequeña pieza de audio en .mp3. Al mismo tiempo, como se vio después, los captchas se ofrecen con voz que actúa en voz femenina o masculina. El "dibujo" de los mismos sonidos hechos por un hombre y una mujer es diferente:
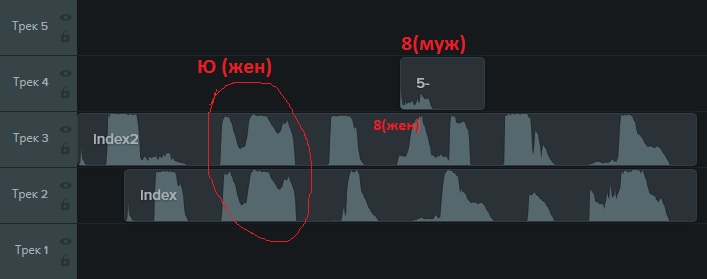
Suenan tanto letras (y ruso) como números.
A primera vista, todo es triste. Pero hay un punto positivo en que los sonidos de las mismas letras coinciden.
Hasta ahora, este conocimiento no ayuda mucho. ¿Cómo meterlo todo en el paquete Sphinx?
Instale Pocketsphinx, un modelo de sonido ruso
* Hay
un artículo sobre Habré donde el sonido se transmite al traductor de Google en línea a través de la redirección de la salida de sonido. Y esto podría terminar esta publicación, si todo esto funcionó para este caso.
Instalar Pocketsphinx en Windows (y también en Linux) no es muy complicado:
descargue e instale.
Dado que, por defecto, pocketsphinx viene con un idioma inglés, modelos acústicos, diccionario, necesitará lo mismo para el idioma ruso.
Descargue la versión rusa -
enlace .
Después de desempaquetar el modelo ruso en la estructura del archivo, puede probar el archivo decoder-text.wav del archivo .wav con el siguiente código de Python:
import os from pocketsphinx import AudioFile, get_model_path, get_data_path
El contenido del archivo de audio debe mostrarse en la línea: "Ilya Ilf Evgeny Petrov Golden Calf".
Si no sale (como en mi situación), entonces necesita convertir decoder-test.wav a otro formato de audio.
Necesitarás ffmpeg para esto.
Ffmpeg
Después de descargar la utilidad ffmpeg, coloque decoder-test.wav en C: \ python3 \ ffmpeg \ bin.
Luego, convierta la línea de comando:
ffmpeg -i decoder-test.wav -ar 16000 decoder-test-.wav
A continuación, arregle el enlace al archivo de audio de origen en código python:
'audio_file': os.path.join(data_path, 'C://python3//decoder-test-.wav'),
Ahora, después de resolver el código:

Es cierto que debe esperar hasta la segunda vez, el código funciona muy lentamente, unos 20 segundos.
Convertimos captcha de audio por el mismo principio de mp3 a wav y alimentamos audio de captcha. Echa un vistazo al código:

Algún tipo de ignorancia, pero hay un resultado. Hubiera sido mucho peor si no se hubiera sacado nada. Como con una voz femenina:

Veamos cómo mejorar el resultado y al mismo tiempo acelerarlo.
Vocabulario
Necesitarás tu propio diccionario. En este caso, constará de todas las letras del alfabeto ruso (excepto b, s, b) y números.
Todos los caracteres deben colocarse en un archivo de texto sin formato, uno en cada línea en codificación UTF-8.
Ahora necesitas convertir el diccionario.
Deberá instalar perl (es necesario para que el convertidor funcione).
A continuación, descargue el proyecto para convertir
ru4sphinx .
Y convierta el diccionario creado anteriormente:
C:\ru4sphinx-master\ru4sphinx-master\text2dict> perl dict2transcript.pl my_dictionary.txt my_dictionary_out.txt.
La salida es un diccionario para el trabajo:

La extensión del diccionario debe renombrarse de formato .txt a .dic, y el archivo en sí debe colocarse en un lugar accesible.
En el código de Python, indicaremos la ubicación del diccionario comentando el diccionario anterior:
Ejecute el programa y vea el resultado:

Mejor, pero igual de lento, y no todas las letras se identifican correctamente.
Crea tu propio modelo
Esto aumentará significativamente la velocidad del trabajo y una pequeña precisión del resultado.
Avancemos un poco de las
instrucciones .
Siga el
enlace y suba nuestro diccionario, creado previamente en formato .txt (¡no .dic!) Al sitio web:
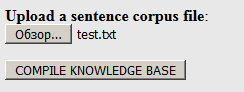
Haga clic en "Compilar ...". En la salida, puede descargar el paquete resultante en el archivo .tgz (contiene todos los archivos necesarios):
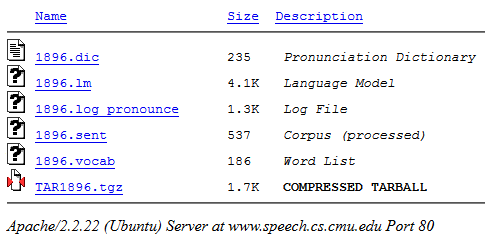
A continuación, tomamos un archivo con la extensión .lm (nuestro modelo) del archivo.
Arreglemos el script de reconocimiento de Python reemplazando el modelo por uno nuevo:
Intentamos:

Funciona mucho más rápido: menos de un segundo, además, todas las letras están definidas.
Pero aquí se necesita un pequeño comentario.
No todos los caracteres se reconocen correctamente, y si en lugar de la letra correcta se muestra un carácter diferente, puede corregir manualmente el diccionario .dic creado previamente haciendo coincidir la correspondencia de la letra.
Por ejemplo, en lugar de la letra a, muestra e. Es necesario tomar una línea del diccionario e:
ryy
transfiéralo (borrando el anterior), cambiando la letra:
ryPero dado que la letra "a" ya está en el diccionario, entonces debe agregar "(2)" (o 3,4) a la letra, en general, un número de serie, dependiendo de cuántos sonidos hay en el diccionario:
a(2) ryVolver a convertir el diccionario no es necesario. De una manera tan simple, puedes "captar" fonemas de todas las letras, casi.
Cherchez la femme
El modelo y el vocabulario funcionan, pero no con una voz femenina. Si la voz del captcha es femenina, no obtenemos nada en la salida. Esto es bueno y malo al mismo tiempo. Primero sobre lo bueno.
Si no reconoció nada al iniciar el programa, significa que estamos tratando con una voz femenina, por lo que puede filtrar captchas "femeninas".
¿Pero qué hacer con ellos?
Aquí necesitas trabajar con la conversión.
Por ejemplo, con un captcha "masculino", la frecuencia era 16000, y para un captcha femenino 24000:
ffmpeg -i acap(3).mp3 -ar 24000 acap(3)2.wav

Todos los sonidos están definidos (en cada línea por sonido), pero su correspondencia es poco convincente.
Es mejor crear un diccionario separado para el modelo femenino y luego editarlo.
Sin embargo, esto es para el autoaprendizaje.
Enlaces utiles:
1.home-smart-home.ru/raspberry-pi-pocketsphinx-offlajn-raspoznavanie-rechi-i-upravlenie-golosom2.https: //itnan.ru/post.php? C = 1 & p = 351376
3.
ru.wikipedia.org/wiki/Cherchez_la_femmeArchivos:
1.
El programa .
2.
El modelo .
3. El
modelo ruso .
4.
Diccionario .
5.
Prueba captcha .
6.
ffmpeg .
7.
Un paquete de captcha .