En el proceso de trabajar en el próximo proyecto, el equipo disputó el uso del formato XML o SQL en Liquibase. Naturalmente, ya se han escrito muchos artículos sobre Liquibase, pero como siempre, quiero agregar mis observaciones. El artículo presentará un pequeño tutorial sobre cómo crear una aplicación simple con una base de datos y considerar la diferencia en la metainformación para estos tipos.
Liquibase es una biblioteca de base de datos independiente para rastrear, administrar y aplicar cambios en el esquema de la base de datos. Para realizar cambios en la base de datos, se crea un archivo de migración (* changeset *), que está conectado al archivo principal (* changeLog *), que controla las versiones y gestiona todos los cambios.
Los formatos XML ,
YAML ,
JSON y
SQL se utilizan para describir la estructura y los cambios de la base de datos.
El concepto básico de migración de base de datos es el siguiente:
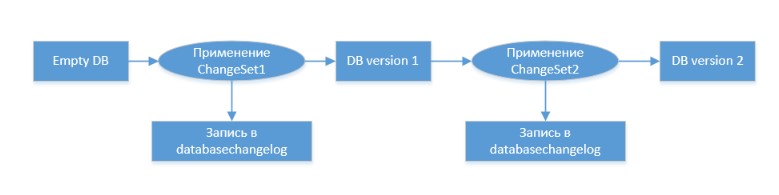
Puede encontrar más información sobre Liquibase
aquí o
aquí . Espero que la imagen general sea clara, así que pasemos a crear el proyecto.
El proyecto de prueba utiliza
- Java 8
- Bota de primavera
- Maven
- H2
- bien liquibase en sí
Creación de proyectos y dependencias
El uso de Spring-boot no es condicional aquí, puede hacer solo un complemento maven para scripts rodantes. Entonces comencemos.
1. Cree un proyecto maven en el IDE y agregue las siguientes dependencias al archivo pom:
<dependencies> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> <dependency> <groupId>org.liquibase</groupId> <artifactId>liquibase-core</artifactId> <version>3.6.3</version> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-test</artifactId> <scope>test</scope> </dependency> <dependency> <groupId>com.h2database</groupId> <artifactId>h2</artifactId> <scope>runtime</scope> </dependency> </dependencies>
2. En la carpeta de recursos, cree el archivo application.yml y agregue las siguientes líneas:
spring: liquibase: change-log: classpath:/db/changelog/db.changelog-master.yaml datasource: url: jdbc:h2:mem:test; platform: h2 username: sa password: driverClassName: org.h2.Driver h2: console: enabled: true
Línea Liquibase: change-log: classpath: /db/changelog/db.changelog-master.yaml: nos dice dónde se encuentra el archivo de script liquibase.
3. En la carpeta de recursos a lo largo de la ruta db.changelog-master, cree los siguientes archivos:
- xmlSchema.xml: cambia el script en formato xml
- sqlSchema.sql: secuencia de comandos de cambios en formato sql
- data.xml: agrega datos a la tabla
- db.changelog-master.yml: lista de conjuntos de cambios
4. Agregar datos a los archivos:
Para la prueba, debe crear dos t no relacionadas
tablas y el conjunto mínimo de datos.
En el archivo sqlSchema.sql, agregamos la conocida sintaxis sql a todos:
El uso de SQL como un conjunto de cambios se maneja mediante scripts fáciles. En los archivos, todos entienden el sql habitual.
Se utiliza un comentario para separar el conjunto de cambios:
--changeset TestUsers_sql: 1 con el número de cambio y el apellido
(los parámetros se pueden encontrar
aquí ).
En el archivo xmlSchema.sql, agregue el DSL que proporciona liquibase: <?xml version="1.0" encoding="UTF-8"?> <databaseChangeLog xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns="http://www.liquibase.org/xml/ns/dbchangelog" xsi:schemaLocation="http://www.liquibase.org/xml/ns/dbchangelog http://www.liquibase.org/xml/ns/dbchangelog/dbchangelog-3.6.xsd"> <changeSet id="Create table test_xml_table" author="TestUsers_xml"> <createTable tableName="test_xml_table"> <column name="name" type="character varying"> <constraints primaryKey="true" nullable="false"/> </column> <column name="description" type="character varying"/> </createTable> </changeSet> <changeSet id="Create table test_xml_table_2" author="TestUsers_xml"> <createTable tableName="test_xml_table_2"> <column name="name" type="character varying"> <constraints primaryKey="true" nullable="false"/> </column> <column name="description" type="character varying"/> </createTable> </changeSet> </databaseChangeLog>
Este formato para describir la creación de tablas es universal para diferentes bases de datos. Al igual que el eslogan de Java:
"Está escrito una vez, funciona en todas partes" . Liquibase usa la descripción xml y la compila en un código sql específico, dependiendo de la base de datos seleccionada. Lo cual es muy conveniente para los parámetros generales.
Cada operación se realiza en un conjunto de cambios separado, que indica la identificación y el nombre del autor. Creo que el lenguaje utilizado en xml es muy fácil de entender y ni siquiera necesita ser explicado.
5. Cargue los datos en nuestras placas, esto no es necesario, pero dado que las placas se han hecho, debe poner algo en ellas. Completamos el archivo data.xml con los siguientes datos:
<?xml version="1.0" encoding="UTF-8"?> <databaseChangeLog xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns="http://www.liquibase.org/xml/ns/dbchangelog" xsi:schemaLocation="http://www.liquibase.org/xml/ns/dbchangelog http://www.liquibase.org/xml/ns/dbchangelog/dbchangelog-3.6.xsd"> <changeSet id="insert data to test_xml_table" author="TestUsers"> <insert tableName="test_xml_table"> <column name="name" value="model"/> <column name="description" value="- "/> </insert> </changeSet> <changeSet id="insert data to test_xml_table_2" author="TestUsers"> <insert tableName="test_xml_table_2"> <column name="name" value="model"/> <column name="description" value="- "/> </insert> </changeSet> <changeSet id="insert data to test_sql_table" author="TestUsers"> <insert tableName="test_sql_table"> <column name="name" value="model"/> <column name="description" value="- "/> </insert> </changeSet> <changeSet id="insert data to test_sql_table_2" author="TestUsers"> <insert tableName="test_sql_table_2"> <column name="name" value="model"/> <column name="description" value="- "/> </insert> </changeSet> </databaseChangeLog>
Se crean archivos para tablas dinámicas, se crean datos para tablas. Es hora de combinar todo esto en un orden continuo y lanzar nuestra aplicación.
Agregue nuestros archivos sql y xml al archivo db.changelog-master.yml:
databaseChangeLog: - include: # schema file: db/changelog/xmlSchema.xml - include: file: db/changelog/sqlSchema.sql # data - include: file: db/changelog/data.xml
Y ahora que tenemos todo creado. Solo ejecuta nuestra aplicación. Puede usar la línea de comando o el complemento para comenzar, pero crearemos solo el método principal y ejecutaremos nuestra SpringApplication.
Ver metadatos
Ahora que hemos ejecutado nuestros dos scripts para crear y llenar las tablas, podemos mirar la tabla databaseChangeLog y ver qué se acumula.

El resultado de rodar xml:
- En el campo de identificación de los archivos xml, aparece un encabezado que el desarrollador apunta a changeSet, cada changeSet individual es una línea separada en la base de datos con un título y una descripción.
- Se indica el autor de cada cambio.
Resultado del rollo SQL:
- No hay información detallada sobre changeSet en el campo id de los archivos sql
- El autor de cada cambio no está indicado.
Otra conclusión importante para usar xml es la reversión. Los comandos como crear tabla, modificar tabla, agregar columna tienen reversión automática cuando se usa xml. Para los archivos sql, cada reversión debe escribirse manualmente.
Conclusión
Todos eligen por sí mismos qué usar. Pero nuestra elección recayó en el lado xml. La metainformación detallada y la fácil transición a otras bases de datos superaron las escalas del formato sql favorito de todos.