Hola Desde el titular, ya entendiste de lo que voy a hablar. Habrá mucho hardcore:
discutiremos Java, C, C ++, ensamblador, un poco de Linux, un poco del núcleo del sistema operativo. También analizaremos un caso práctico, por lo que el artículo tendrá tres partes grandes (bastante voluminoso).
En el primero, intentaremos exprimir todo de los perfiladores existentes.
En la segunda parte, crearemos nuestro propio perfilador pequeño, y en la tercera veremos cómo perfilar lo que no es habitual, porque las herramientas existentes no son muy adecuadas para esto. Si estás listo para seguir este camino, te estoy esperando debajo del corte :)
Contenido
Tiempo y medios de comprensión - perfilador
Desde el punto de vista cotidiano, 1 segundo es muy pequeño. Pero sabemos que 1 segundo es mil millones de nanosegundos. Y deje que tome aproximadamente 4 ciclos de procesador en solo 1 nanosegundo, en 1 segundo se hacen muchas cosas en la computadora que pueden mejorar o empeorar nuestras vidas.
Supongamos que estamos desarrollando una aplicación que en sí misma es lo suficientemente crítica como para acelerar, y para algunos fragmentos de código esto es generalmente crítico. Estas piezas se ejecutan, digamos, cientos de microsegundos, lo suficientemente rápido, pero [las
secciones del código ] afectan directamente el éxito de nuestra aplicación y la cantidad de dinero ganado o perdido. Por ejemplo
Al enviar órdenes para concluir transacciones de intercambio, un retraso de 100 microsegundos puede costar al intercambio 1 millón de rublos o más en cada transacción, que se completa con uno, no dos, o incluso no cien.
Y la
tarea se estableció para mí: por un lado, debe enviar todos los pedidos al mismo tiempo y, por otro lado, enviarlos de modo que la variación entre el primero y el último sea mínima. Es decir, era necesario perfilar una función que envía órdenes al intercambio. Una tarea típica, excepto por un pequeño matiz: el tiempo de ejecución característico de esta función es
significativamente menor que 100 μs .
Pensemos en cómo perfilamos estos 100 μs para comprender lo que está sucediendo dentro.
¿Qué tener en cuenta al elegir esta herramienta?
- La sección de código que nos interesa rara vez se ejecuta, es decir, 100 microsegundos se ejecutan en alguna parte una vez por segundo. Y esto está en el banco de pruebas, y en producción aún menos.
- Será difícil aislar este fragmento de código en un microbenchmark, ya que afecta a una parte importante del proyecto e incluso a la entrada / salida a través de la red.
- Y finalmente, lo más importante, quiero que el perfil resultante corresponda con el comportamiento que tendrá en nuestros servidores de producción.
¿Cómo tomamos en cuenta todos estos matices y perfilamos correctamente el método de interés?
Conceptualmente, todos los perfiladores se pueden dividir en dos grupos de perfiladores de
instrumentos o
muestreo . Consideremos cada grupo por separado.
Los perfiladores de herramientas aportan bastante sobrecarga porque modifican nuestro código de bytes e insertan un registro de temporización en él. De ahí el inconveniente clave de tales perfiladores: pueden afectar significativamente el código ejecutable. Como resultado, será difícil decir cuánto coincide el perfil resultante con el comportamiento en los servidores de producción: algunas optimizaciones pueden funcionar de manera diferente, algunas suceden y otras no. Quizás, en otras escalas de tiempo - segundos, minutos, horas - obtendremos datos representativos. Pero en una escala de 100 μs, la optimización activada o fallida puede hacer que el perfil sea completamente no representativo. Así que echemos un vistazo más de cerca a otro grupo de perfiladores.
Los perfiladores de muestreo contribuyen con una sobrecarga mínima o moderada. Estas herramientas no afectan directamente el código ejecutable, y su uso requiere un poco más de atención por su parte. Por lo tanto, nos detendremos en los perfiladores de muestreo. Veamos qué datos y de qué forma recibiremos de ellos.
¿Cómo funcionan los perfiladores de muestreo?
Para comprender cómo funciona un generador de perfiles de muestreo, considere el siguiente ejemplo: el método
sendToMoex llama a otros métodos. Buscamos:
void sendToMoex() { a.qqq(); b.doo(); c.ccc() } void doo() { da(); db(); }
Si controlamos el estado de la pila de llamadas en el momento de la ejecución de esta sección del programa y la registramos periódicamente, obtendremos información aproximadamente de la siguiente forma:

Este es un conjunto de pilas de llamadas. Suponiendo que las muestras se distribuyen uniformemente, el número de pilas idénticas indica el tiempo de ejecución relativo del método que está en la parte superior de la pila.
En este ejemplo, el método Da se ejecutó tanto como el método C.ccc, y esto es 2 veces más que el método Db. Sin embargo, la suposición de que la distribución de las muestras incluso puede no ser completamente correcta, y entonces la estimación del tiempo de ejecución será incorrecta.
¿Con qué frecuencia necesitamos tomar muestras?
Supongamos que queremos tomar 1000 muestras en 100 microsegundos para comprender lo que se reproduce dentro. Luego, calculamos con una proporción simple que si necesitamos hacer 1000 muestras en 100 μs, entonces son 10 millones de muestras en 1 segundo o 10,000,000 muestras / s.
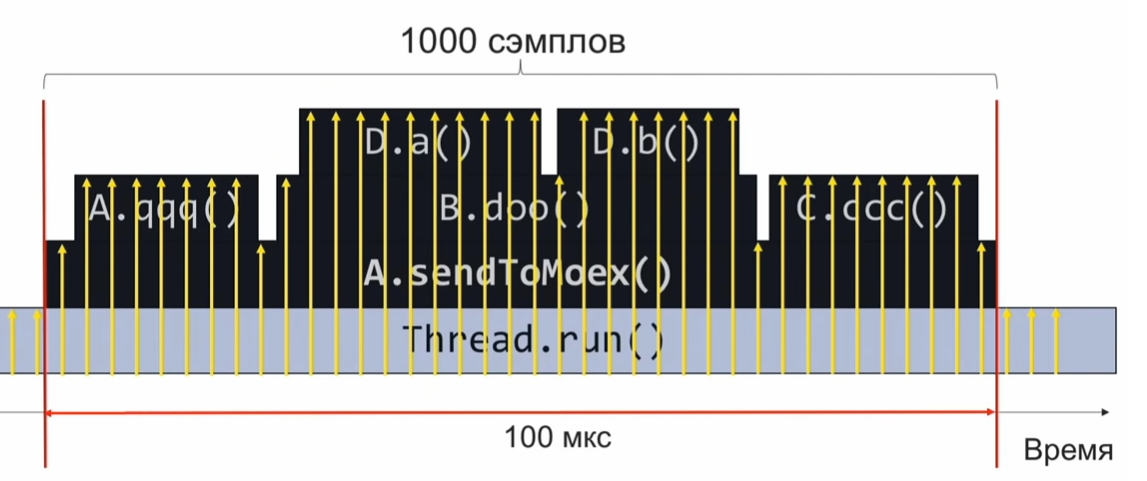
Si tomamos muestras a esa velocidad, en una ejecución del código recolectaremos 1000 muestras, agregaremos y entenderemos lo que funcionó rápida o lentamente. Después de eso, analizaremos el rendimiento y ajustaremos el código.
Sin embargo, una frecuencia de 10 millones de muestras por segundo es mucha. ¿Y si no logramos alcanzar esa velocidad de creación de perfiles desde el principio? Supongamos que recolectamos 10 μs solo 10 muestras, no 1000. En este caso, tenemos que esperar a la próxima ejecución del código perfilado, que sucederá después de 1 segundo (después de todo, el código perfilado se ejecuta una vez por segundo). Entonces recolectaremos 10 muestras más. Como se distribuyen uniformemente con nosotros, se pueden combinar en un conjunto común. Es suficiente esperar hasta que el código perfilado se ejecute 1000/10 = 100 veces, y recopilaremos las 1000 muestras requeridas (10 muestras cada una de 100 veces).
Elige un perfilador
Armados con este conocimiento teórico, pasemos a la práctica.
Tome
Async-profiler. Una gran herramienta (utiliza la llamada de máquina virtual AsyncGetCallTrace) que recopila la pila de llamadas según las instrucciones del código de bytes de la máquina virtual Java. La tasa de muestreo nativa del perfilador asíncrono es de
1000 muestras por segundo .
Resolveremos una proporción simple: 10,000,000 muestras / seg - 1 segundo, 1000 muestras / seg - X segundos.
Obtenemos que a la frecuencia de muestreo estándar de async-profiler, la creación de perfiles llevará aproximadamente 3 horas. Esto es mucho tiempo Idealmente, quiero ensamblar el perfil lo más rápido posible, justo a la velocidad superluminal.
Intentemos overclockear
Async-profiler . Para hacer esto, en el archivo Léame, encontramos la bandera
-i , que establece el intervalo de muestreo. Intentemos establecer el indicador
-i1 (1 nanosegundo), o
-i0 en general, para que el generador de muestras
-i0 sin parar. Obtuve una frecuencia de aproximadamente 2.5 mil muestras por segundo. En este caso, la duración total del perfil será de aproximadamente 1 hora. Por supuesto, no 3 horas, pero tampoco muy rápido. Parece que para alcanzar las velocidades de perfilado requeridas, debe hacer algo cualitativamente diferente para alcanzar un nuevo nivel.
Para lograr frecuencias significativamente más altas, tendrá que abandonar la llamada AsyncGetCallTrace y usar
perf , el generador de perfiles de Linux a tiempo completo que se encuentra en cada distribución de Linux. Sin embargo, perf no sabe nada sobre Java, y todavía tenemos que entrenar a perf para trabajar con Java. Mientras tanto, intentemos ejecutar perf de esta manera aterradora:
$ perf record –F 10000 -p PID -g -- sleep 1 [ perf record: Woken up 1 times to write data ] [ perf record: .. 0.215 MB perf.data (4032 samples) ]
Más sobre notación- perf record significa que queremos grabar un perfil.
- La bandera
-F y el argumento 10,000 son la frecuencia de muestreo. - El indicador
-p indica que queremos perfilar solo el PID específico de nuestro proceso Java. - La bandera
-g es responsable de recoger las pilas de llamadas. - Finalmente, con el sueño 1, limitamos la entrada del perfil a 1 segundo.
¿Por qué necesitamos recolectar pilas de llamadas? Perfilamos todo en una fila, y luego de los datos recopilados extraemos la parte que nos interesa (el método responsable de la formación y el envío de pedidos). El marcador de que la muestra recopilada pertenece a los datos que nos interesan es la presencia del marco de pila de la
llamada al método
sendToMoex .
Aprenda perf para construir un perfil de aplicación Java.
Ejecutamos el comando perf record ..., esperamos 1 segundo y ejecutamos el script perf para ver qué se ha perfilado. Y veremos algo no muy claro:
$ perf script java 8079 2008793.746571: 3745505 cycles:uppp: 7fa1e88b53f8 [unknown] (/tmp/perf-11038.map) java 8079 2008793.747565: 3728336 cycles:uppp: 7fa1e88b5372 [unknown] (/tmp/perf-11038.map) java 8079 2008793.748613: 3731147 cycles:uppp: 7fa1e88b53ef [unknown] (/tmp/perf-11038.map)
Parece que son direcciones, pero no hay nombres de métodos Java. Por lo tanto, debe enseñar a perf para que coincida con estas direcciones con los nombres de los métodos.
En el mundo de C y C ++, la llamada información de depuración se usa para unir direcciones y nombres de funciones. Una correspondencia se almacena en una sección especial del archivo ejecutable: un método se encuentra en dichas direcciones, otro método se encuentra en otras direcciones. Perf extrae esta información y hace un mapeo.
Obviamente, el compilador JIT de máquina virtual no genera información de depuración en este formato. Todavía tenemos otra manera: escribir datos sobre la correspondencia de direcciones y nombres de métodos en un archivo especial de perf-map, que perf tratará como una adición a la información de depuración leída. Este archivo de perf-map debe estar en la carpeta tmp y tener la siguiente estructura de datos:
La primera columna es la dirección del comienzo del código del método, la segunda es su longitud, la tercera columna es el nombre del método.
Entonces, necesitamos generar un archivo similar. Obviamente, no podremos hacer esto manualmente (cómo sabemos en qué direcciones colocará el código el compilador JIT), por lo que utilizaremos el script create-java-perf-map.sh del proyecto perf-map-agent, pasándole el PID de nuestro proceso Java . El archivo está listo, verifique su contenido, ejecute perf-script nuevamente.
$ perf script java 8080 1895245.867498: cycles:uppp: 7fb2dd10f527 Loop3.doRecursiveCall (/tmp/perf-8079.map) java 8080 1895245.868176: 2127960 cycles:uppp: 7fb2dd10f57f Loop3.doRecursiveCall (/tmp/perf-8079.map) java 8080 1895245.868737: 1959990 cycles:uppp: 7fb2dd10f627 Loop3.doRecursiveCall (/tmp/perf-8079.map)
Voila! ¡Vemos los nombres de los métodos de Java! Lo que acaba de suceder: le enseñamos al perfilador de perf, que no sabe nada sobre Java, a perfilar una aplicación Java normal y ver los métodos java más populares de esta aplicación.
Sin embargo, para analizar el rendimiento de la parte del programa que estamos interrogando, no tenemos suficiente pila de llamadas para filtrar los datos de interés de todas las muestras recopiladas.
¿Cómo obtener una pila de llamadas?Ahora necesita hacer algo más con perf o una máquina virtual para obtener pilas de llamadas. Para comprender lo que hay que hacer, demos un paso atrás y veamos cómo funciona la pila en general. Imagine que tenemos tres funciones f1, f2, f3. Además, f1 llama a f2 y f2 llama a f3.
void f1() { f2(); } void f2() { f3(); } void f3() { ... }
En el momento en que
f3 ejecuta la función
f3 , veamos en qué estado se encuentra la pila. Vemos el registro
rsp , que apunta a la parte superior de la pila. También sabemos que la pila tiene la dirección del marco de pila anterior. ¿Y cómo puedo obtener una pila de llamadas?
Si de alguna manera pudiéramos obtener la dirección de esta área, podríamos imaginar la pila como una lista simplemente conectada y comprender la secuencia de llamadas que nos llevaron al punto de ejecución actual.
¿Qué necesitamos para esto? Necesitamos un registro rbp adicional que apunte al área amarilla. Resulta que el registro rbp permite que perf obtenga la pila de llamadas, para comprender la secuencia que nos llevó al punto actual. Recomiendo leer estos detalles en la
interfaz binaria de la aplicación System V. Describe cómo se llaman los métodos en Linux.

Entendimos cuál es nuestro problema. Necesitamos forzar a la máquina virtual a usar el registro rbp para su propósito original, como un puntero al comienzo del marco de la pila. Así es como el compilador JIT debe usar el registro rbp. Hay una bandera PreserveFramePointer en la máquina virtual para esto. Cuando pasamos este indicador a la máquina virtual, la máquina virtual comenzará a usar el registro rbp para su propósito tradicional. Y luego Perf puede hacer girar la pila. Y obtenemos una pila de llamadas real en el perfil. La bandera fue aportada por el famoso Brendan Gregg en solo JDK8u60.
Comenzamos la máquina virtual con una nueva bandera. Ejecute
create-java-perf-map , luego
perf record y
perf script . Ahora podemos construir un perfil preciso con pilas de llamadas:
$ perf script java 18657 1901247.601878: 979583 cycles:uppp: 7fbfd1101edc Loop3.doRecursiveCall (...) 7fbfd1101edc Loop3.doRecursiveCall (...) 7fbfd1101edc Loop3.doRecursiveCall (...) 7fbfd1101edc Loop3.doRecursiveCall (...) 7f285d007b10 Interpreter (...) 7f285d0004e7 call_stub (...) 67d0db [unknown] (... libjvm.so) ... 708c start_thread (... libpthread-2.26.so)
Enseñamos perf profiler, incluido con la mayoría de las distribuciones de Linux, para trabajar con aplicaciones Java. Por lo tanto, ahora podemos ver no solo las secciones activas del código, sino también la secuencia de llamadas que condujeron a la zona activa actual. Un gran logro, dado que el perfilador perf no sabe nada sobre Java. ¡Acabamos de enseñarle a perf todo esto!
Aumentar la tasa de muestreo de perf
Intentemos overclockear perf a 10 millones de muestras por segundo. Ahora tenemos una frecuencia significativamente menor.
Para automatizar todas las tareas que acabamos de hacer, puede usar el script
perf-java-record-stack del proyecto perf-map-agent. Tiene un lápiz maravilloso: la variable de entorno
perf_record-freq , con la que puede establecer la frecuencia de muestreo. Primero, configuremos 100 mil muestras por segundo e intentemos ejecutar. Aparece un terrible mensaje en la consola que indica que hemos excedido la frecuencia de muestreo máxima permitida:
$ PERF_RECORD_FREQ=100000 ./bin/perf-java-record-stack PID ... Maximum frequency rate (30000) reached. Please use -F freq option with lower value or consider tweaking /proc/sys/kernel/perf_event_max_sample_rate. ...
En mi caso, el límite era de 30 mil muestras por segundo. Perf dice inmediatamente qué argumento del kernel debe corregirse, lo que haremos utilizando echo sudo tee para el archivo deseado o directamente a través de
sysctl . Entonces
$ echo '1000000' | sudo tee /proc/sys/kernel/perf_event_max_sample_rate
más o menos:
$ sudo sysctl kernel.perf_event_max_sample_rate=1000000
Ahora le estamos diciendo al núcleo que el límite superior de la frecuencia es ahora de 1 millón de muestras por segundo. Comenzamos el perfilador nuevamente e indicamos la frecuencia de 200 mil muestras por segundo. El generador de perfiles funcionará durante 15 segundos y nos dará 1 millón de muestras. Todo parece estar bien. Al menos no hay mensajes de error formidables. Pero, ¿qué frecuencia obtuvimos realmente? Resulta que solo 70 mil muestras por segundo. ¿Qué salió mal?
Veamos el resultado del
dmesg :
[84430.412898] perf: interrupt took too long (1783 > 200), lowering kernel.perf_event_max_sample_rate to 89700 ... [84431.618452] perf: interrupt took too long (2229 > 2228), lowering kernel.perf_event_max_sample_rate to 71700
Esta es la salida del kernel de Linux. Se dio cuenta de que tomamos muestras con demasiada frecuencia, y lleva demasiado tiempo, por lo que el núcleo reduce la frecuencia. Resulta que necesitamos desenroscar otro controlador en el kernel: se llama
kernel.perf_cpu_time_max_percent y controla la cantidad de tiempo que el kernel puede pasar en las interrupciones de perf.
Ordenaremos una frecuencia de muestreo de 200 mil muestras por segundo. Y después de 15 segundos obtenemos 3 millones de muestras, 200 mil muestras por segundo.
$ PERF_RECORD_FREQ=200000 ./bin/perf-java-record-stack PID Recording events for 15 seconds ... ... [ perf record: Captured ... (2.961.252 samples) ]
Ahora veamos el perfil. Ejecutar
perf script :
$ perf script ... java ... native_write_msr (/.../vmlinux) java ... Loop2.main (/tmp/perf-29621.map) java ... native_write_msr (/.../vmlinux) ...
Vemos funciones extrañas y el módulo ejecutable vmlinux: el kernel de Linux. Este definitivamente no es nuestro código. Que paso La frecuencia resultó ser tan alta que el código del núcleo comenzó a caer en las muestras. Es decir, cuanto mayor sea la frecuencia, más muestras habrá que no estén relacionadas con nuestro código, sino con el kernel de Linux.
Callejón sin salida.
Utilizamos (explícitamente) eventos de hardware PMU / PEBS
Luego decidí intentar usar la tecnología de hardware PMU / PEBS: unidad de monitoreo de rendimiento, muestreo basado en eventos precisos. Le permite recibir notificaciones de que se ha producido un evento varias veces. Esto se llama un "período". Por ejemplo, podemos recibir notificaciones sobre la ejecución por parte del procesador de cada vigésima instrucción. Veamos un ejemplo. Deje que la instrucción xor se ejecute ahora, y el contador PMU obtiene el valor 18; luego viene la instrucción mov: el contador es 19; y en la siguiente instrucción,
agregue% r14,% r13 , PMU se mostrará como "
activo ".
Luego comienza un nuevo ciclo: se ejecuta
inc ; la PMU se restablece a 1. Se realizan algunas iteraciones más del ciclo. Al final, nos detenemos en la instrucción
mov , la PMU se ajusta a 19. La siguiente instrucción add, y nuevamente la marcamos como hot. Ver el listado:
mov aaa, bbbb xor %rdx, %rdx L_START: mov $0x0(%rbx, %rdx),%r14 add %r14, %r13 ; (PMU "") cmp %rdx,100000000 jne L_START
¿No te das cuenta de las rarezas? Un ciclo de cinco instrucciones, pero cada vez que marcamos la misma instrucción como hot. Obviamente, esto no es cierto: todas las instrucciones son "calientes". También pasan tiempo, y marcamos solo uno. El hecho es que entre el período y el contador del número de instrucciones en la iteración tenemos un factor común 4. Resulta que cada cuarta iteración marcaremos la misma instrucción como "activa". Para evitar este comportamiento, debe elegir un número como un período en el que se minimiza la probabilidad de un divisor común entre el número de iteraciones en el bucle y el contador. Idealmente, el período debería ser primo, es decir compartir solo en usted y en la unidad. Para el ejemplo anterior: debe elegir un período igual a 23. Luego, marcaríamos de manera uniforme todas las instrucciones de este ciclo como "activas".
La tecnología PMU / PEBS ha recibido soporte en su forma moderna desde al menos 2009, es decir, está disponible en casi cualquier computadora. Para aplicarlo explícitamente, modifiquemos el script
perf-java-record-stack . Reemplace el indicador
-F con
-e , que especifica explícitamente el uso de PMU / PEBS.
... sudo perf record -F $PERF_RECORD_FREQ ... ...
Transformando el guión:
... sudo perf record -e cycles –c 10007 ... ...
Ya sabes qué propiedades debe tener un período: necesitamos un número primo. Para nuestro caso, será el período 10007.
Lanzamos el script modificado perf-java-record-stack y en 15 segundos recibimos 4.5 millones de muestras, esto es casi 300 mil por segundo, una muestra cada 3 μs. Es decir, para una ejecución de nuestro código perfilado, por 100 μs recolectaremos 33 muestras. A esta frecuencia, el tiempo total de recopilación del perfil es de solo 30 segundos. ¡Ni siquiera tomes una taza de café! En realidad, todo es un poco más complicado. ¿Qué sucede si nuestro código comienza a ejecutarse no una vez por segundo, sino una vez cada 5 segundos? Luego, la duración de la creación de perfiles crecerá hasta 2,5 minutos, lo que también es un resultado bastante decente.
Por lo tanto, en 30 segundos puede obtener un perfil que cubra completamente todas nuestras necesidades de investigación. Victoria
Pero la sensación de algún truco sucio no me dejó. Volvamos a la situación en la que nuestro código se ejecuta cada 5 segundos. Luego, la elaboración de perfiles llevará 150 segundos, tiempo durante el cual recolectaremos alrededor de 45 millones de muestras. De estos, solo necesitamos 1000, es decir, 0.002% de los datos recopilados. Todo lo demás es basura, lo que ralentiza el trabajo de otras herramientas y agrega gastos generales. Sí, el problema está resuelto, pero está resuelto en la frente, fuerza sucia y contundente.
Y esa noche, cuando obtuve un perfil tan detallado con la ayuda de perf, tuve un sueño. Iba a casa del trabajo y pensaba, pero sería bueno si el hierro pudiera ensamblar el perfil en sí mismo e incluso con la precisión de las microestructuras y los microsegundos, y solo analizaríamos los resultados. ¿Se hará realidad mi sueño? Que piensas
Breve resumen:
- Para crear un perfil de una aplicación Java usando perf, necesita generar un archivo con información sobre símbolos usando scripts del proyecto perf-map-agent
- Para recopilar información no solo sobre secciones activas de código, sino también pilas, debe ejecutar una máquina virtual con el indicador -XX: + PreserveFramePointer
- Si desea aumentar la frecuencia de muestreo, debe prestar atención a sysctl'i y kernel.perf_cpu_time_max_percent y kernel.perf_event_max_sample_rate.
- Si las muestras del kernel que no están relacionadas con la aplicación comenzaron a ingresar al perfil, debe pensar en especificar explícitamente el período PMU / PEBS.
Este artículo (y sus partes posteriores) es una transcripción del informe, adaptado en forma de texto. Si desea no solo leer, sino también escuchar sobre la creación de perfiles, una
referencia a la presentación.