En aplicaciones móviles, la función de búsqueda es muy popular. Y si puede descuidarse en productos pequeños, entonces en aplicaciones que brindan acceso a una gran cantidad de información, no puede prescindir de una búsqueda. Hoy te diré cómo implementar correctamente esta función en programas para Android.

Enfoques para la implementación de búsqueda en una aplicación móvil
- Buscar como filtro de datos
Por lo general, parece una barra de búsqueda sobre alguna lista. Es decir, simplemente filtramos los datos terminados. - Búsqueda del servidor
En este caso, entregamos toda la implementación al servidor, y la aplicación actúa como un cliente ligero, desde el cual solo es necesario mostrar los datos en la forma correcta. - Búsqueda integrada
- la aplicación contiene una gran cantidad de datos de varios tipos;
- la aplicación funciona sin conexión;
- La búsqueda es necesaria como un único punto de acceso a las secciones / contenido de la aplicación.
En el último caso, la búsqueda de texto completo integrada en SQLite viene al rescate. Con él, puede encontrar coincidencias muy rápidamente en una gran cantidad de información, lo que nos permite realizar múltiples consultas a diferentes tablas sin sacrificar el rendimiento.
Considere la implementación de dicha búsqueda utilizando un ejemplo específico.
Preparación de datos
Digamos que necesitamos implementar una aplicación que muestre una lista de películas de
themoviedb.org . Para simplificar (para no estar en línea), tome una lista de películas y forme un archivo JSON, póngala en activos y complete nuestra base de datos localmente.
Ejemplo de estructura de archivo JSON:
[ { "id": 278, "title": " ", "overview": " ..." }, { "id": 238, "title": " ", "overview": " , ..." }, { "id": 424, "title": " ", "overview": " ..." } ]
Llenado de bases de datos
SQLite usa tablas virtuales para implementar la búsqueda de texto completo. Exteriormente, se ven como tablas SQLite normales, pero cualquier acceso a ellas hace un trabajo entre bastidores.
Las tablas virtuales nos permiten acelerar la búsqueda. Pero, además de las ventajas, también tienen desventajas:
- No puede crear un activador en una tabla virtual;
- No puede ejecutar los comandos ALTER TABLE y ADD COLUMN para una tabla virtual;
- cada columna de la tabla virtual está indexada, lo que significa que los recursos pueden desperdiciarse en columnas de indexación que no deberían estar involucradas en la búsqueda.
Para resolver este último problema, puede usar tablas adicionales que contendrán parte de la información y almacenar enlaces a elementos de una tabla normal en una tabla virtual.
Crear una tabla es ligeramente diferente del estándar, tenemos las palabras clave
VIRTUAL y
fts4 :
CREATE VIRTUAL TABLE movies USING fts4(id, title, overview);
Comentando sobre la versión fts5Ya se ha agregado a SQLite. Esta versión es más productiva, más precisa y contiene muchas características nuevas. Pero debido a la gran fragmentación de Android, no podemos usar fts5 (disponible con API24) en todos los dispositivos. Puede escribir diferentes lógicas para diferentes versiones del sistema operativo, pero esto complicará seriamente el desarrollo y soporte adicional. Decidimos seguir el camino más fácil y usar fts4, que es compatible con la mayoría de los dispositivos.
El llenado no es diferente de lo habitual:
fun populate(context: Context) { val movies: MutableList<Movie> = mutableListOf() context.assets.open("movies.json").use { val typeToken = object : TypeToken<List<Movie>>() {}.type movies.addAll(Gson().fromJson(InputStreamReader(it), typeToken)) } try { writableDatabase.beginTransaction() movies.forEach { movie -> val values = ContentValues().apply { put("id", movie.id) put("title", movie.title) put("overview", movie.overview) } writableDatabase.insert("movies", null, values) } writableDatabase.setTransactionSuccessful() } finally { writableDatabase.endTransaction() } }
Versión básica
Al ejecutar la consulta, se usa la palabra clave
MATCH lugar de
LIKE :
fun firstSearch(searchString: String): List<Movie> { val query = "SELECT * FROM movies WHERE movies MATCH '$searchString'" val cursor = readableDatabase.rawQuery(query, null) val result = mutableListOf<Movie>() cursor?.use { if (!cursor.moveToFirst()) return result while (!cursor.isAfterLast) { val id = cursor.getInt("id") val title = cursor.getString("title") val overview = cursor.getString("overview") result.add(Movie(id, title, overview)) cursor.moveToNext() } } return result }
Para implementar el procesamiento de entrada de texto en la interfaz, utilizaremos
RxJava :
RxTextView.afterTextChangeEvents(findViewById(R.id.editText)) .debounce(500, TimeUnit.MILLISECONDS) .map { it.editable().toString() } .filter { it.isNotEmpty() && it.length > 2 } .map(dbHelper::firstSearch) .subscribeOn(Schedulers.computation()) .observeOn(AndroidSchedulers.mainThread()) .subscribe(movieAdapter::updateMovies)
El resultado es una opción de búsqueda básica. En el primer elemento, la palabra deseada se encontró en la descripción, y en el segundo elemento tanto en el título como en la descripción. Obviamente, de esta forma no está del todo claro lo que encontramos. Vamos a arreglarlo
Añadir acentos
Para mejorar la obviedad de la búsqueda, usaremos la función auxiliar
SNIPPET . Se utiliza para mostrar un fragmento de texto formateado en el que se encuentra una coincidencia.
snippet(movies, '<b>', '</b>', '...', 1, 15)
- películas - nombre de la mesa;
- <b & gt y </b>: estos argumentos se utilizan para resaltar una sección de texto que se buscó;
- ... - para el diseño del texto, si el resultado fue un valor incompleto;
- 1 - número de columna de la tabla desde la cual se asignarán los fragmentos de texto;
- 15 es un número aproximado de palabras incluidas en el valor de texto devuelto.
El código es idéntico al primero, sin contar la solicitud:
SELECT id, snippet(movies, '<b>', '</b>', '...', 1, 15) title, snippet(movies, '<b>', '</b>', '...', 2, 15) overview FROM movies WHERE movies MATCH ''
Intentamos nuevamente:
Resultó más claramente que en la versión anterior. Pero este no es el final. Hagamos que nuestra búsqueda sea más "completa". Utilizaremos el análisis léxico y destacaremos las partes importantes de nuestra consulta de búsqueda.
Mejora de acabado
SQLite tiene tokens integrados que le permiten realizar análisis léxicos y transformar la consulta de búsqueda original. Si al crear la tabla no especificamos un tokenizador específico, se seleccionará "simple". De hecho, solo convierte nuestros datos en minúsculas y descarta caracteres ilegibles. No nos queda del todo bien.
Para una mejora cualitativa en la búsqueda, necesitamos utilizar la
derivación : el proceso de encontrar la base de una palabra para una palabra fuente dada.
SQLite tiene un tokenizador incorporado adicional que utiliza el algoritmo Porter Stemmer. Este algoritmo aplica secuencialmente una serie de ciertas reglas, destacando partes significativas de una palabra cortando terminaciones y sufijos. Por ejemplo, cuando buscamos "claves", podemos obtener una búsqueda donde están contenidas las palabras "clave", "claves" y "clave". Dejaré un enlace a una descripción detallada del algoritmo al final.
Desafortunadamente, el tokenizer integrado en SQLite funciona solo con inglés, por lo que para el idioma ruso debe escribir su propia implementación o utilizar desarrollos listos para usar. Tomaremos la implementación terminada del sitio
algoritmist.ru .
Transformamos nuestra consulta de búsqueda en la forma necesaria:
- Eliminar caracteres extra.
- Divide la frase en palabras.
- Salta a través del stemmer.
- Recopilar en una consulta de búsqueda.
Algoritmo de Porter object Porter { private val PERFECTIVEGROUND = Pattern.compile("((|||||)|((<=[])(||)))$") private val REFLEXIVE = Pattern.compile("([])$") private val ADJECTIVE = Pattern.compile("(|||||||||||||||||||||||||)$") private val PARTICIPLE = Pattern.compile("((||)|((?<=[])(||||)))$") private val VERB = Pattern.compile("((||||||||||||||||||||||||||||)|((?<=[])(||||||||||||||||)))$") private val NOUN = Pattern.compile("(|||||||||||||||||||||||||||||||||||)$") private val RVRE = Pattern.compile("^(.*?[])(.*)$") private val DERIVATIONAL = Pattern.compile(".*[^]+[].*?$") private val DER = Pattern.compile("?$") private val SUPERLATIVE = Pattern.compile("(|)$") private val I = Pattern.compile("$") private val P = Pattern.compile("$") private val NN = Pattern.compile("$") fun stem(words: String): String { var word = words word = word.toLowerCase() word = word.replace('', '') val m = RVRE.matcher(word) if (m.matches()) { val pre = m.group(1) var rv = m.group(2) var temp = PERFECTIVEGROUND.matcher(rv).replaceFirst("") if (temp == rv) { rv = REFLEXIVE.matcher(rv).replaceFirst("") temp = ADJECTIVE.matcher(rv).replaceFirst("") if (temp != rv) { rv = temp rv = PARTICIPLE.matcher(rv).replaceFirst("") } else { temp = VERB.matcher(rv).replaceFirst("") if (temp == rv) { rv = NOUN.matcher(rv).replaceFirst("") } else { rv = temp } } } else { rv = temp } rv = I.matcher(rv).replaceFirst("") if (DERIVATIONAL.matcher(rv).matches()) { rv = DER.matcher(rv).replaceFirst("") } temp = P.matcher(rv).replaceFirst("") if (temp == rv) { rv = SUPERLATIVE.matcher(rv).replaceFirst("") rv = NN.matcher(rv).replaceFirst("") } else { rv = temp } word = pre + rv } return word } }
Algoritmo donde dividimos la frase en palabras val words = searchString .replace("\"(\\[\"]|.*)?\"".toRegex(), " ") .split("[^\\p{Alpha}]+".toRegex()) .filter { it.isNotBlank() } .map(Porter::stem) .filter { it.length > 2 } .joinToString(separator = " OR ", transform = { "$it*" })
Después de esta conversión, la frase "patios y fantasmas" parece "patio
* O fantasma
* ".
El símbolo "
* " significa que la búsqueda se realizará por la aparición de una palabra dada en otras palabras. El operador "
OR " significa que se mostrarán resultados que contienen al menos una palabra de la frase de búsqueda. Buscamos:
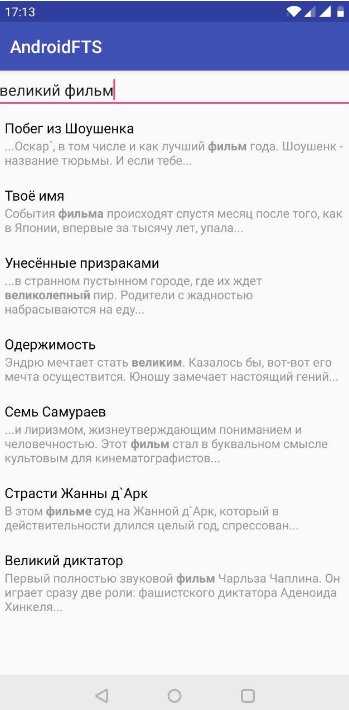
Resumen
La búsqueda de texto completo no es tan complicada como podría parecer a primera vista. Hemos analizado un ejemplo específico que puede implementar rápida y fácilmente en su proyecto. Si necesita algo más complicado, debe consultar la documentación, ya que hay una y está bastante bien escrita.
Referencias