
Hay muchos artículos con un encabezado similar, por lo que intentaré evitar los temas comunes. Espero que incluso un desarrollador con mucha experiencia encuentre algo útil aquí. Este artículo considerará solo mecanismos y enfoques de optimización simples que les permitirán aplicarse con un mínimo de esfuerzo. Y estos cambios no aumentarán la entropía de su código. El artículo no prestará atención a qué y cuándo optimizar, este artículo trata más sobre el enfoque para escribir código en general.
1. ToArray vs ToList
public IEnumerable<string> GetItems() { return _storage.Items.Where(...).ToList(); }
De acuerdo, un código muy típico para proyectos industriales. ¿Pero qué le pasa? La interfaz IEnumerable devuelve una colección que puede "revisar"; esta interfaz no implica que podamos agregar / eliminar elementos. En consecuencia, no hay necesidad de finalizar la expresión LINQ mediante la conversión a una Lista (ToList). En este caso, es preferible enviar a matriz (ToArray). Como List es un contenedor sobre Array, y todas las características adicionales proporcionadas por este contenedor, cortamos la interfaz. Una matriz consume menos memoria y el acceso a sus valores es más rápido. En consecuencia, ¿por qué pagar más? Por un lado, esta optimización no es significativa, ya que dicen "optimización en los partidos", pero esto no es del todo cierto. El hecho es que en una aplicación típica en la que los servicios devuelven modelos para la capa de presentación, puede haber una miríada de llamadas ToList. En el ejemplo descrito anteriormente, la interfaz IEnumerable se introduce solo con fines ilustrativos. Este enfoque es relevante para todos los casos en los que necesita devolver una colección que no va a cambiar más adelante.
Preveo un comentario de que Array y List no funcionarán de manera equivalente en el caso de acceso multiproceso a la colección. Realmente lo es Pero si usted, como desarrollador, está considerando la posibilidad de acceso multiproceso a dicha colección con la posibilidad de cambiarla, entonces, con un alto grado de probabilidad, ni Array ni List serán adecuados para usted.
2. El parámetro "ruta del archivo" no siempre es la mejor opción para su método
Al desarrollar una API, evite las firmas de métodos que reciben una ruta de archivo como entrada (para su posterior procesamiento por su método). En su lugar, proporcione la capacidad de pasar una matriz de bytes a la entrada, o
como un último recurso Stream. El hecho es que, con el tiempo, su método se puede aplicar no solo a un archivo del disco, sino también a un archivo transferido a través de la red, a un archivo de un archivo, a un archivo de una base de datos, a un archivo cuyo contenido se genera dinámicamente en la memoria, etc. e) Al proporcionar un método con el parámetro de entrada "ruta de archivo", obliga al usuario de su API a guardar los datos en el disco antes de leerlos nuevamente. Esta operación sin sentido afecta críticamente el rendimiento. Un viaje es algo extremadamente lento. Para mayor comodidad, puede proporcionar un método con un parámetro de entrada "ruta a un archivo", pero en el interior siempre use un método público sobrecargado con una matriz de bytes o flujo en la entrada. Hay un "marcador" que puede ayudar a encontrar operaciones adicionales de escritura / lectura de disco, intente encontrar en su proyecto utilizando métodos estándar:
Path.GetTempPath() y
Path.GetRandomFileName() (de System.IO). Con un alto grado de probabilidad, encontrará una solución alternativa al problema anterior o similar.
Un lector atento y experimentado notará que, en algunos casos, escribir en el disco puede, por el contrario, mejorar el rendimiento, por ejemplo, si se trata de archivos muy grandes. Esto es cierto, debe tenerse en cuenta, pero supongo que esta es una situación muy rara con una implementación específica.
3. Evite usar hilos como parámetros y el resultado de retorno de sus métodos
¿Cuál es el problema aquí ... cuando recibimos una transmisión de algún "recuadro negro", debemos tener en cuenta su estado. Es decir ¿Está abierta la corriente? ¿Dónde está el marcador de lectura / escritura? ¿Puede cambiar su estado independientemente de nuestro código? Si una transmisión se declara como una clase base de Transmisión, ni siquiera tenemos información sobre qué operaciones están disponibles. Todo esto se resuelve mediante controles adicionales, y esto es un código y costos adicionales. Además, repetidamente me encontré con una situación en la que, cuando recibía Stream de algún método "oscuro", el desarrollador prefería jugar de forma segura y "transferir" datos de él a un nuevo MemoryStream local completamente controlado. Aunque, la secuencia de origen podría ser bastante segura. Tal vez incluso esto ya estaba amablemente preparado para leer MemoryStream. A veces puede llegar al punto de lo absurdo: dentro de un método, se coloca una matriz de bytes en un MemoryStream, luego este MemoryStream se devuelve como resultado de un método declarado como Stream base. Afuera, este Stream se convierte en un nuevo MemoryStream, y luego ToArray () devuelve una matriz de bytes, que originalmente teníamos. Más precisamente, será su próxima copia. La ironía es que dentro y fuera de nuestro método, el código es completamente correcto. En mi opinión, este ejemplo no está fuera de mi cabeza, pero se encontró en algún lugar del código comercial.
Como resultado, si tiene la capacidad de enviar / recibir datos "limpios", no use transmisiones para esto, no cree trampas para quienes los usarán. Si su aplicación ya tiene flujos de transferencia / devolución, analice su uso en función de lo anterior.
4. Herencia de enumeraciones
Esta optimización es común, todos lo saben, incluso los estudiantes. Pero desde mi experiencia, se usa extremadamente raramente. Entonces, por defecto, enum hereda de int. Sin embargo, se puede heredar del byte, que contiene 256 valores (u 8 valores "marcables"). Que casi siempre cubre la funcionalidad de la enumeración "media". Un cambio mínimo en el código y todos los valores de su enumeración ocupan menos memoria para siempre. A continuación se muestra una ilustración de un punto de referencia para llenar una colección con valores enum heredados de int y byte.
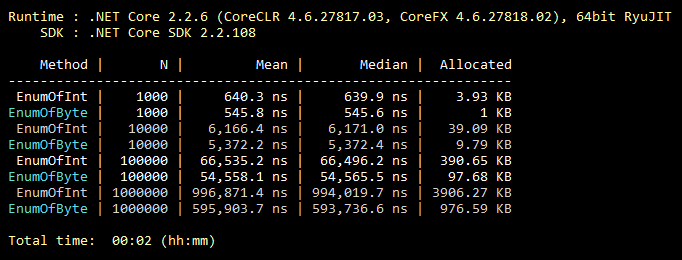
Código de referencia public class CollectEnums { [Params(1000, 10000, 100000, 1000000)] public int N; [Benchmark] public EnumFromInt[] EnumOfInt() { EnumFromInt[] results = new EnumFromInt[N]; for (int i = 0; i < N; i++) { results[i] = EnumFromInt.Value1; } return results; } [Benchmark] public EnumFromByte[] EnumOfByte() { EnumFromByte[] results = new EnumFromByte[N]; for (int i = 0; i < N; i++) { results[i] = EnumFromByte.Value1; } return results; } } public enum EnumFromInt { Value1, Value2 } public enum EnumFromByte: byte { Value1, Value2 }
5. Algunas palabras más sobre las clases Array y List
Siguiendo la lógica, iterar sobre una matriz siempre es más eficiente que iterar sobre una "hoja", ya que una "hoja" es una envoltura sobre una matriz. Además, siguiendo la lógica, "for" es siempre más rápido que "foreach", ya que "foreach" realiza muchas de las acciones requeridas por la implementación de la interfaz IEnumerable. Aquí todo es lógico, ¡pero está mal! Echemos un vistazo a los resultados de referencia:

Código de referencia public class IterationBenchmark { private List<int> _list; private int[] _array; [Params(100000, 10000000)] public int N; [GlobalSetup] public void Setup() { const int MIN = 1; const int MAX = 10; Random rnd = new Random(); _list = Enumerable.Repeat(0, N).Select(i => rnd.Next(MIN, MAX)).ToList(); _array = _list.ToArray(); } [Benchmark] public int ForList() { int total = 0; for (int i = 0; i < _list.Count; i++) { total += _list[i]; } return total; } [Benchmark] public int ForeachList() { int total = 0; foreach (int i in _list) { total += i; } return total; } [Benchmark] public int ForeachArray() { int total = 0; foreach (int i in _array) { total += i; } return total; } [Benchmark] public int ForArray() { int total = 0; for (int i = 0; i < _array.Length; i++) { total += _array[i]; } return total; } }
El hecho es que para iterar sobre una matriz, "foreach" no utiliza una implementación IEnumerable. En este caso particular, se realiza la iteración más optimizada por índice, sin verificar fuera de los límites de la matriz, ya que la construcción "foreach" no funciona con índices, por lo que el desarrollador no tiene la opción de "desordenar" el código. Tal es la excepción a la regla. Por lo tanto, si en alguna sección crítica del código reemplazó el uso de "foreach" por "for" en aras de la optimización, se disparó en el pie. Tenga en cuenta que esto
solo es relevante
para las matrices . Hay varias ramas en StackOverflow donde se discute esta característica.
6. ¿La búsqueda en una tabla hash siempre está justificada?
Todos saben que las tablas hash son muy efectivas para la búsqueda. Pero a menudo olvidan que el precio de una búsqueda rápida es una adición lenta a la tabla hash. ¿Qué se sigue de esto? Para que se justifique el uso de la tabla hash, es necesario que el número de elementos de la tabla hash sea al menos 8 (aproximadamente). Y para que el número de operaciones de búsqueda fuera al menos un orden de magnitud mayor que el número de operaciones de sumar. De lo contrario, use una colección más simple. La calidad de la función hash hará sus propios ajustes a la eficiencia, pero el significado de esto no cambiará. En mi práctica, hubo un caso en el que el mayor cuello de botella en el código cargado estaba llamando al método Dictionary.Add (). La llave era una cuerda regular, de corta longitud. Recordando esto y se convirtió en un disparador para escribir este párrafo. Para ilustrar, un ejemplo de código muy malo:
private static int GetNumber(string numberStr) { Dictionary<string, int> dictionary = new Dictionary<string, int> { {"One", 1}, {"Two", 2}, {"Three", 3} }; dictionary.TryGetValue(numberStr, out int result); return result; }
Tal vez algo similar ocurre en su proyecto?
7. Métodos de incrustación
El código se divide en métodos con mayor frecuencia por 2 razones. Asegure la reutilización y descomposición del código cuando una tarea se divide en varias subtareas. Es más fácil para una persona. La alineación es el proceso inverso de descomposición, es decir el código del método está incrustado en el lugar donde debe llamarse el método; como resultado, guardamos en la pila de llamadas y pasando parámetros. De ninguna manera recomiendo poner todo en un solo método. Pero aquellos métodos que teóricamente podríamos "en línea" pueden marcarse con el atributo correspondiente:
[MethodImpl(MethodImplOptions.AggressiveInlining)]
Este atributo le dirá al sistema que este método puede integrarse. Esto no significa que el método marcado con este atributo esté necesariamente incorporado. Por ejemplo, no es posible incrustar métodos recursivos o virtuales. También vale la pena señalar que el mecanismo de inserción es extremadamente "delicado". Hay muchas otras razones por las cuales el sistema se negará a incorporar su método. Sin embargo, el equipo de Microsoft que trabaja en .NET Core está utilizando activamente este atributo. El código fuente de .NET Core tiene muchos ejemplos de su uso.
8. Capacidad estimada
Yo (y espero que la mayoría de los desarrolladores también) hayan desarrollado un reflejo: Inicialicé la colección, pensé si es posible configurar Capacidad para ella. Sin embargo, el número exacto de elementos de colección no siempre se conoce de antemano. Pero esta no es una razón para ignorar este parámetro. Por ejemplo, si, hablando de cuántos elementos habrá en su colección, asume un borroso "par de miles", esta es una ocasión para establecer Capacidad en 1000. Una pequeña teoría, por ejemplo, para Lista por defecto, Capacidad = 16, de modo que solo Al llegar a 1000, el sistema realizará 1008 (16 + 32 + 64 + 128 + 256 + 512) copias adicionales de los elementos y creará 7 matrices temporales para la próxima llamada del GC. Es decir todo este trabajo se desperdiciará. Además, como Capacidad, nadie prohíbe usar la fórmula. Si se estima que el tamaño de su colección es un tercio de la otra colección, puede establecer la capacidad igual a otherCollection.Count / 3. Al configurar la capacidad, es bueno comprender el rango del tamaño posible de la colección y qué tan cerca se distribuye su valor. Siempre existe la posibilidad de daño, pero si se usa correctamente, una capacidad estimada le dará una buena victoria.
9. Siempre especifique su código.
Utilice activamente (a primera vista, opcional) palabras clave de C #, como: estático, constante, de solo lectura, sellado, abstracto, etc. Naturalmente, donde tienen sentido. ¿Y aquí está el rendimiento? El hecho es que cuanto más detallado describa su sistema al compilador, más óptimo será el código que puede generar. Un lector atento y experimentado puede notar que, por ejemplo, la palabra clave sellada no tiene ningún efecto en el rendimiento. Ahora esto es cierto, pero en futuras versiones todo puede cambiar. ¡Dale una oportunidad al compilador y a la máquina virtual! Obtenga una bonificación, identificando muchos errores de uso incorrecto de su código en la etapa de compilación. Regla general: cuanto más claramente se describe el sistema, más óptimo es el resultado. Aparentemente, también con personas.
La historia real confirma esta regla, pero si lees pereza, puedes saltarteUna noche, mientras participaba en su
proyecto de pasatiempo , se propuso la tarea de aumentar el rendimiento de una sección de código por encima de cierto nivel. Pero este sitio era corto y había pocas opciones sobre qué hacer con él. En la documentación encontré que, comenzando con la versión C # 7.2, la palabra clave "solo lectura" se puede usar para estructuras. Y en mi caso, se utilizaron estructuras inmutables, al agregar una sola palabra "solo lectura" obtuve lo que quería, ¡incluso con un margen! El sistema, sabiendo que mis estructuras no están destinadas a ser cambiadas, pudo generar un mejor código para mi caso.
10. Si es posible, use una versión de .NET para todos los proyectos de Solución
Debe esforzarse por asegurarse de que todos los ensamblados dentro de su aplicación pertenezcan a la misma versión de .NET. Esto se aplica tanto a los paquetes NuGet (editados en packages.config / json) como a sus propios ensamblajes (editados en las propiedades del Proyecto). Esto ahorrará RAM y acelerará el inicio "en frío", ya que en la memoria de su aplicación no habrá copias de las mismas bibliotecas para diferentes versiones de .NET. Vale la pena señalar que no en todos los casos, diferentes versiones de .NET generarán copias en la memoria. Pero suponga que una aplicación creada en la misma versión de .NET siempre es mejor. Además, esto elimina una serie de problemas potenciales que están fuera del alcance de este artículo. La consolidación de versiones de todos los paquetes NuGet que use también contribuirá a mejorar el rendimiento de su aplicación.
Algunas herramientas útiles
ILSpy es una herramienta gratuita que le permite ver el código fuente del ensamblado restaurado. Si tengo una pregunta sobre qué mecanismo .NET es más eficiente, en primer lugar, abro ILSpy (y no Google o StackOverflow), y ya veo cómo se implementa. Por ejemplo, para averiguar qué se utiliza mejor en términos de rendimiento para recibir datos a través de HTTP, la clase HttpWebRequest o WebClient, solo mire su implementación a través de ILSpy. En este caso particular, WebClient es un contenedor sobre HttpWebRequest, respectivamente, la respuesta es obvia. No vale la pena temer los códigos fuente .NET, están escritos por los mismos programadores ordinarios.
BenchmarkDotNet es una biblioteca gratuita de puntos de referencia. Hay un cronómetro simple e intuitivo (de System.Diagnostics). Pero a veces no es suficiente. Dado que, en el buen sentido, es necesario tener en cuenta no un solo resultado, sino el promedio de varias comparaciones, es mejor comparar su mediana para minimizar la influencia del sistema operativo. Además, debe tener en cuenta el "arranque en frío" y la cantidad de memoria asignada. Para pruebas tan complejas, se creó BenchmarkDotNet. Es esta biblioteca la que usan los desarrolladores de .NET Core en las pruebas oficiales. La biblioteca es fácil de usar, pero si sus autores leen de repente esta publicación, brinde una oportunidad más conveniente para influir en la estructura de la tabla de resultados.
U2U Consult Performance Analyzers es un complemento gratuito para Visual Studio que proporciona consejos para mejorar el código en términos de rendimiento. El 100% confía en los consejos de este analizador que no vale la pena. Desde que me encontré con una situación en la que un consejo me sorprendió un poco y después de un análisis detallado, resultó ser erróneo. Desafortunadamente, este ejemplo está perdido, así que tome una palabra. Sin embargo, si lo usa con cuidado, es una herramienta muy útil. Por ejemplo, sugerirá que en lugar de
myStr.Replace("*", "-") más eficiente usar
myStr.Replace('*', '-') . Y las dos expresiones Where en LINQ se combinan mejor en una. Todos estos son "optimización en coincidencias", pero son fáciles de aplicar y no conducen a un aumento en el código / complejidad.
En conclusión
Si cada décima persona que lee el artículo aplica los enfoques anteriores a su proyecto actual (o una parte crítica del mismo), y también se adhiere a estos enfoques en el futuro, ¡juntos podemos salvar todo el bosque! Bosque ??? Es decir Los recursos ahorrados de los sistemas informáticos, en forma de electricidad obtenida de la quema de madera, no se utilizarán. En este caso, el "bosque" es solo una especie de equivalente. Probablemente surgió una conclusión extraña, pero espero que te inspire el pensamiento.
Actualización de PS basada en comentarios de publicaciones
La ventaja de ToArray sobre ToList es relevante para .NET Core. Pero si usa el antiguo .NET Framework, entonces ToList probablemente será preferible para usted. El problema es que en .NET Framework, la llamada ToArray en sí es significativamente más lenta que la llamada ToList. Y estas pérdidas pueden no compensarse con accesos más rápidos a los elementos y menos almacenamiento de matriz. En general, este problema resultó ser más complicado, ya que diferentes clases que implementan IEnumerable pueden tener diferentes implementaciones de ToArray y ToList, con diferentes niveles de eficiencia.
Si la enumeración heredada del byte se usa como miembro de una clase (estructura), y no por separado, es posible que no haya ningún ahorro de memoria. Debido a la alineación de la memoria ocupada de todos los miembros de la clase (estructura). Este punto falta en el artículo. Sin embargo, la ganancia potencial es mejor que su ausencia, ya que además de la memoria ocupada, también se usan enum. Por lo tanto, el párrafo 4 sigue siendo relevante, pero con esta importante reserva.
Gracias a
KvanTTT y
epetrukhin por sus comentarios constructivos sobre estos temas.
Además, como señaló
Taritsyn , la optimización en la etapa de compilación JIT para la palabra clave "sellada" todavía existe. Pero, esto solo confirma todas las tesis del noveno párrafo.
Parece que todos los comentarios constructivos se han tenido en cuenta. Estoy muy satisfecho con estos comentarios. Como yo, como autor, recibí un comentario y también aprendí algo nuevo para mí.