Hola Habr
Este artículo es una continuación lógica del ranking de los
mejores artículos de Habr para 2018 . Y aunque el año aún no ha terminado, pero como saben, en el verano hubo cambios en las reglas, respectivamente, se hizo interesante ver si afectó algo.

Además de las estadísticas, se proporcionará una calificación actualizada de los artículos, así como algunos códigos fuente para aquellos que estén interesados en cómo funciona esto.
Para aquellos que estén interesados en lo que sucedió, continuaron bajo el corte. Aquellos que estén interesados en un análisis más detallado de las secciones del sitio también pueden ver la
siguiente parte .
Datos de origen
Esta calificación no es oficial y no tengo ningún dato interno. Como es fácil de ver, después de mirar en la barra de direcciones del navegador, todos los artículos sobre Habré tienen numeración de extremo a extremo. El siguiente es un asunto técnico, acabamos de leer todos los artículos en una fila en un ciclo (en un hilo y con pausas para no cargar el servidor). Los valores en sí se obtuvieron mediante un analizador simple en Python (el código fuente está
aquí ) y se almacenaron en un archivo csv de aproximadamente este tipo:
2019-08-11T22:36Z,https://habr.com/ru/post/463197/,"Blazor + MVVM = Silverlight , ",votes:11,votesplus:17,votesmin:6,bookmarks:40,views:5300,comments:73
2019-08-11T05:26Z,https://habr.com/ru/news/t/463199/," NASA ",votes:15,votesplus:15,votesmin:0,bookmarks:2,views:1700,comments:7Procesamiento
Para el análisis usaremos Python, Pandas y Matplotlib. Aquellos que no estén interesados en las estadísticas, pueden omitir esta parte e ir inmediatamente a los artículos.
Primero debe cargar el conjunto de datos en la memoria y seleccionar los datos para el año deseado.
import pandas as pd import datetime import matplotlib.dates as mdates from matplotlib.ticker import FormatStrFormatter from pandas.plotting import register_matplotlib_converters df = pd.read_csv("habr.csv", sep=',', encoding='utf-8', error_bad_lines=True, quotechar='"', comment='#') dates = pd.to_datetime(df['datetime'], format='%Y-%m-%dT%H:%MZ') df['datetime'] = dates year = 2019 df = df[(df['datetime'] >= pd.Timestamp(datetime.date(year, 1, 1))) & (df['datetime'] < pd.Timestamp(datetime.date(year+1, 1, 1)))] print(df.shape)
Resulta que para este año (aunque aún no está terminado) al momento de escribir, se publicaron 12715 artículos. A modo de comparación, para todo 2018 - 15904. En general, mucho: se trata de 43 artículos por día (y esto es solo con una calificación positiva, cuántos artículos se descargan que son negativos o eliminados, solo puede adivinar o calcular las omisiones entre identificadores).
Seleccione los campos necesarios del conjunto de datos. Como métricas, utilizaremos la cantidad de vistas, comentarios, valores de calificación y la cantidad de marcadores agregados.
def to_float(s):
Ahora los datos se han agregado al conjunto de datos y podemos usarlos. Agrupe los datos por día y tome los valores promediados.
g = df.groupby(['date']) days_count = g.size().reset_index(name='counts') year_days = days_count['date'].values grouped = g.median().reset_index() grouped['counts'] = days_count['counts'] counts_per_day = grouped['counts'].values counts_per_day_avg = grouped['counts'].rolling(window=20).mean() view_per_day = grouped['views'].values view_per_day_avg = grouped['views'].rolling(window=20).mean() votes_per_day = grouped['votes'].values votes_per_day_avg = grouped['votes'].rolling(window=20).mean() bookmarks_per_day = grouped['bookmarks'].values bookmarks_per_day_avg = grouped['bookmarks'].rolling(window=20).mean()
Ahora, para la parte divertida, podemos ver los gráficos.
Veamos la cantidad de publicaciones sobre Habré en 2019.
import matplotlib.pyplot as plt plt.rcParams["figure.figsize"] = (16, 8) fig, ax = plt.subplots() plt.bar(year_days, counts_per_day, label='Articles/day') plt.plot(year_days, counts_per_day_avg, 'g-', label='Articles avg/day') plt.xticks(rotation=45) ax.xaxis.set_major_formatter(mdates.DateFormatter("%d-%m-%Y")) ax.xaxis.set_major_locator(mdates.MonthLocator(interval=1)) plt.legend(loc='best') plt.tight_layout() plt.show()
El resultado es interesante. Como puede ver, Habr ligeramente "salchicha" durante el año. No sé el motivo.

A modo de comparación, 2018 se ve un poco "más suave":

En general, no vi ninguna disminución drástica en el número de artículos publicados en 2019 en el gráfico. Además, por el contrario, parece haber crecido incluso ligeramente desde el verano.
Pero los siguientes dos gráficos me deprimen un poco más.
Vistas promedio por artículo:

Valoración media por artículo:
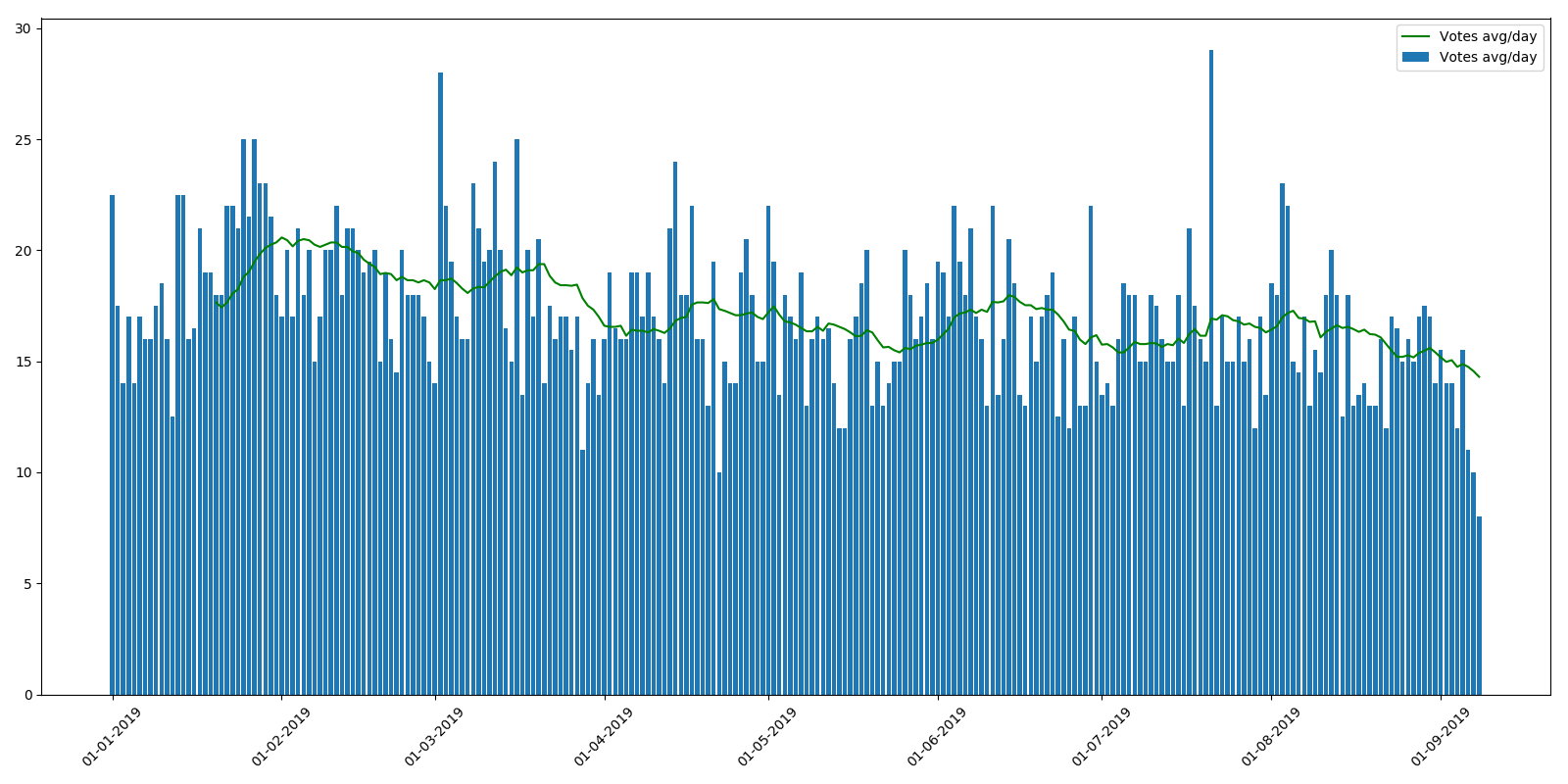
Como puede ver, el número promedio de visitas durante el año se reduce ligeramente. Esto puede explicarse por el hecho de que los nuevos artículos aún no han sido indexados por los motores de búsqueda, y no se encuentran tan a menudo. Pero la disminución en la calificación promedio por artículo es más incomprensible. La sensación es que los lectores simplemente no tienen tiempo para navegar por tantos artículos o no prestan atención a las calificaciones. Desde el punto de vista del programa de recompensas de los autores, esta tendencia es muy desagradable.
Por cierto, este no fue el caso en 2018, y el calendario es más o menos parejo.
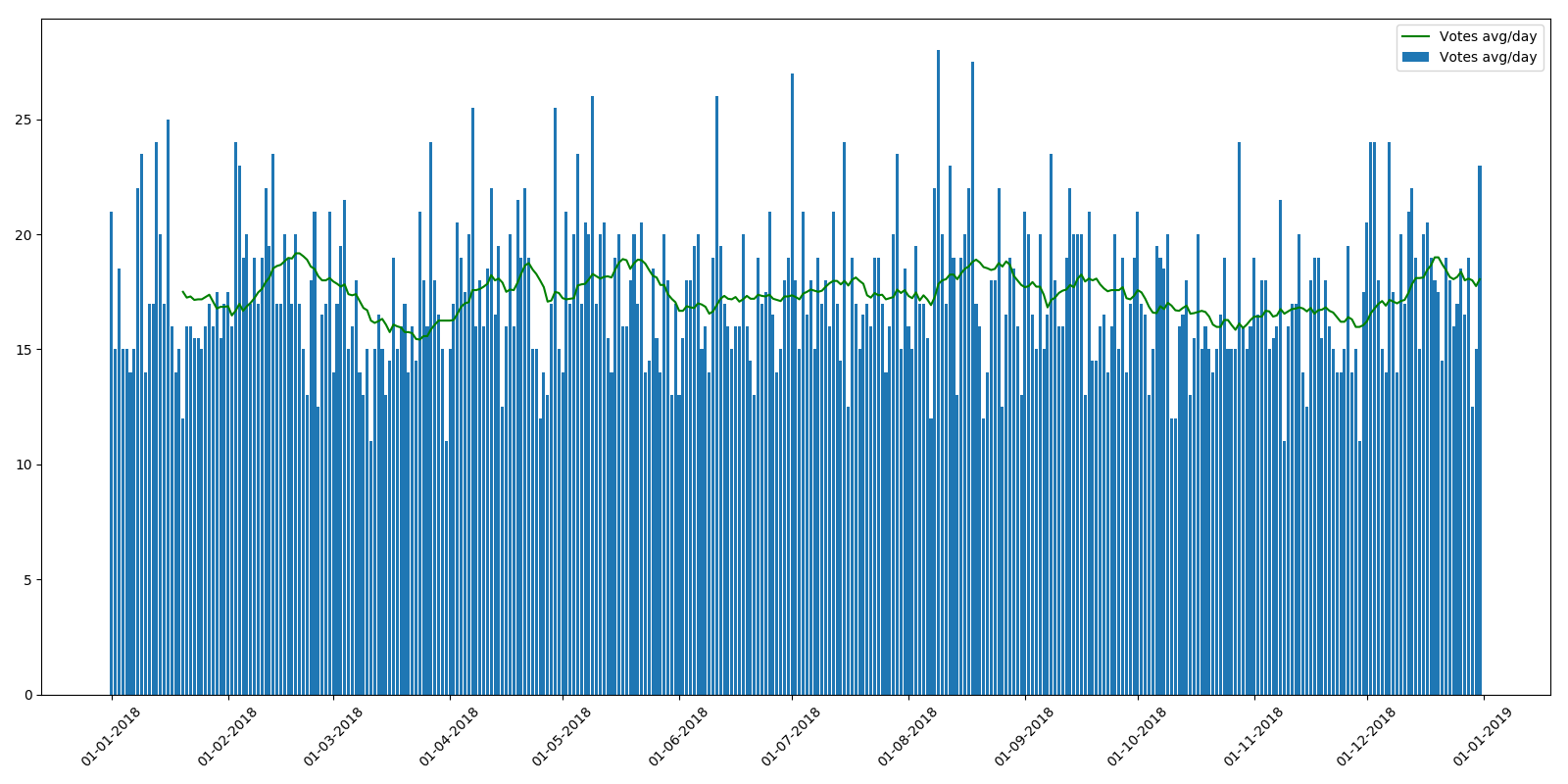
En general, los propietarios de recursos tienen algo en qué pensar.
Pero no hablemos de cosas tristes. En general, podemos decir que Habr "sobrevivió" los cambios de verano con bastante éxito, y la cantidad de artículos en el sitio no disminuyó.
Calificación
Ahora, en realidad, la calificación. Felicitaciones a quienes lo golpearon. Le recuerdo una vez más que la calificación no es oficial, tal vez me perdí algo, y si algún artículo definitivamente debería estar aquí, pero no lo está, escriba, lo agregaré manualmente. Como calificación, utilizo métricas calculadas, que, me parece, han resultado ser bastante interesantes.
Artículos más vistos- El LED miente de proporciones sin precedentes 241,000 vistas, 569 comentarios, calificación + 364.0 / -1.0
- 'Artículo de mamada': los científicos procesaron 109 horas de sexo oral para desarrollar una IA que absorbe a un miembro 236,000 vistas, 361 comentarios, calificación + 240.0 / -68.0
- Lo que el diseñador fumó: un arma de fuego inusual 235,000 vistas, 123 comentarios, calificación + 119.0 / -9.0
- Cómo no trabajé durante un año en Sberbank 233,000 vistas, 580 comentarios, calificación + 449.0 / -14.0
- Los científicos han encontrado el vertebrado vivo más antiguo de la Tierra 221000 vistas, 211 comentarios, calificación + 82.0 / -14.0
- Las bombillas inteligentes arrojadas a la basura son una valiosa fuente de información personal 219,000 vistas, 147 comentarios, calificación + 73.0 / -11.0
- Development King 178,000 vistas, 668 comentarios, calificación + 315.0 / -60.0
- Fraudes y EDS: todo es muy malo 175,000 vistas, 778 comentarios, calificación + 356.0 / -0.0
- La serie 'Chernobyl': mira y piensa 172,000 vistas, 803 comentarios, calificación + 164.0 / -25.0
- El peor control de volumen de sonido de la interfaz de usuario 166,000 vistas, 176 comentarios, calificación + 292.0 / -30.0
- Un currículum honesto de un programador 165,000 visitas, 283 comentarios, calificación + 410.0 / -40.0
- Arruino la vida de los desarrolladores con mis revisiones de código y lo siento 164,000 vistas, 12 comentarios, calificación + 33.0 / -3.0
- Cómo dormía Megafon en suscripciones móviles 162,000 vistas, 676 comentarios, calificación + 624.0 / -2.0
- Disturbios en el Picaba. Los usuarios van a Reddit en masa 160,000 vistas, 484 comentarios, calificación + 215.0 / -41.0
- Baterías AAA baratas y caras 159,000 vistas, 382 comentarios, calificación + 363.0 / -6.0
- Retirado con 22,156,000 visitas, 922 comentarios, calificación + 259.0 / -100.0
- Hombre sin teléfono inteligente 152000 visitas, 736 comentarios, calificación + 173.0 / -25.0
- ¿Quieres LED eternos? Descubra soldadores y archivos. O iluminación casera casera 149,000 vistas, 262 comentarios, calificación + 94.0 / -6.0
- Lo que no necesita hacer si le roban su teléfono 144,000 visitas, 638 comentarios, calificación + 259.0 / -27.0
- 1 de febrero de 2019 su sitio puede dejar de funcionar 143,000 visitas, 162 comentarios, calificación + 89.0 / -8.0
Artículos principales sobre la proporción de calificaciones a vistas- Debilitar las tuercas, parte 2: el plazo de votación para publicaciones y otros cambios es de 14000 visitas, calificación + 238.0 / -3.0
- Bastante fantasioso 'Comienzos' de Euclides en el TeX-e 10,800 vistas, calificación + 136.0 / -0.0
- Recompensa del usuario a los autores de Habr 26400 vistas, calificación + 320.0 / -0.0
- Envío de mensajes con errores de impresión en publicaciones 18,900 vistas, calificación + 179.0 / -2.0
- Hola mundo O Habr en inglés, v1.0 21,000 visitas, calificación + 178.0 / -2.0
- Vida en partículas 34,000 vistas, calificación + 267.0 / -2.0
- Civilization of Springs, 5/5 25800 vistas, calificación + 201.0 / -1.0
- Jugamos Tetris en la pantalla electromecánica 16300 vistas, calificación + 124.0 / -0.0
- Recreando fuentes desde una pantalla CRT 13,400 vistas, calificación + 101.0 / -0.0
- El modelo matemático del juego es Dobble 14600 vistas, calificación + 110.0 / -0.0
- Un mensaje importante sobre las invitaciones en el perfil es 18300 visitas, calificación + 137.0 / -8.0
- Debilitar las tuercas en las reglas de Habr 48300 vistas, calificación + 338.0 / -13.0
- Comparación de códec mágico callejero. Revelamos los secretos de 21,700 vistas, calificación + 144.0 / -0.0
- Analizador inteligente para números registrados en palabras 20,500 vistas, calificación + 136.0 / -1.0
- Modelos genéricos y de metaprogramación: Go, Rust, Swift, D y otras vistas de 17000, calificación + 110.0 / -2.0
- Creo una base de conocimiento global sobre baterías 22,200 vistas, calificación + 139.0 / -0.0
- Mientras escribía y publicaba un libro sobre la Universidad Estatal de Moscú, o 12 errores críticos, 21,600 vistas, calificación + 134.0 / -0.0
- Sobre kote, esposa, dos hijos, la idea ... y no solo. Una historia con una continuación de 43,000 vistas, calificación + 269.0 / -8.0
- Video computarizado en 755 megapíxeles: plenopéticos ayer, hoy y mañana 41,500 vistas, calificación + 244.0 / -0.0
- La densidad de la trama en el comercio minorista 27,500 vistas, calificación + 160.0 / -1.0
Artículos principales sobre la proporción de comentarios a vistas- Github comenzó a bloquear repositorios de usuarios de Crimea, Cuba, Irán, Corea del Norte y Siria 44,500 vistas, 1,309 comentarios, calificación + 115.0 / -6.0
- Lecciones de Ucrania 60400 vistas, 1672 comentarios, calificación + 285.0 / -41.0
- Debilitar las tuercas en las reglas de Habr 48300 visitas, 1285 comentarios, calificación + 338.0 / -13.0
- La manifestación contra el aislamiento de Runet 50,900 vistas, 923 comentarios, calificación + 204.0 / -32.0
- Cómo montar dos ruedas para trabajar 47100 vistas, 781 comentarios, calificación + 113.0 / -10.0
- Accidente de avión en Sheremetyevo: analogías históricas 82,400 vistas, 1211 comentarios, calificación + 147.0 / -11.0
- Los ingenieros salvan a las personas perdidas en el bosque, pero el bosque aún no se ha rendido 28,900 vistas, 423 comentarios, calificación + 132.0 / -1.0
- Rally contra el aislamiento del Runet 63,300 vistas, 820 comentarios, calificación + 182.0 / -20.0
- Cómo se organiza la protección de los niños de la información y la encantadora historia de dónde vino por primera vez (18+) 65,400 vistas, 811 comentarios, calificación + 175.0 / -2.0
- Hola mundo O Habr en inglés, v1.0 21,000 visitas, 249 comentarios, calificación + 178.0 / -2.0
- Cómo comprar papas correctamente si es daltónico 51,800 vistas, 607 comentarios, calificación + 135.0 / -3.0
- Cómo se siente ser un mantenedor de software libre 22,900 vistas, 259 comentarios, calificación + 129.0 / -3.0
- Debilitar las tuercas, parte 2: período de votación para publicaciones y otros cambios 14000 vistas, 158 comentarios, calificación + 238.0 / -3.0
- Producción piloto de electrónica por un precio mínimo de 34,200 vistas, 382 comentarios, calificación + 165.0 / -3.0
- ¿Cómo equipamos el megáfono 39800 vistas, 405 comentarios, calificación + 140.0 / -6.0
- ¿Guerras nucleares del pasado lejano? 83,400 vistas, 843 comentarios, calificación + 133.0 / -5.0
- Hola mundo O Habr de habla inglesa, v1.0 60,300 vistas, 591 comentarios, calificación + 268.0 / -7.0
- El espacio como un vago recuerdo 43200 vistas, 402 comentarios, calificación + 190.0 / -7.0
- Recompensa del usuario a los autores de Habr 26,400 vistas, 245 comentarios, calificación + 320.0 / -0.0
- Los principios del mercado libre en la comprensión de los Estados Unidos 56,300 vistas, 502 comentarios, calificación + 160.0 / -44.0
Los artículos más controvertidos- State and T-killers 752 comentarios, calificación + 83.0 / -80.0, 15100 visitas
- Estos chicos tóxicos: envenenan proyectos 120 comentarios, calificación + 67.0 / -51.0, 50,300 visitas
- ¿Por qué enseñas Go 70 comentarios, calificación + 76.0 / -57.0, 23100 visitas
- Leí 80 hojas de vida, tengo preguntas 635 comentarios, calificación + 135.0 / -94.0, 90700 visitas
- Por qué es realmente imposible ser vegetariano 940 comentarios, calificación + 76.0 / -52.0, 51,600 visitas
- Programación funcional: un juguete loco que mata la productividad laboral. Parte 1 394 comentarios, calificación + 100.0 / -68.0, 54000 visitas
- Escribimos el código más útil en nuestra vida, pero lo tiramos a la basura. Junto con nosotros 259 comentarios, calificación + 101.0 / -63.0, 62900 visitas
- Apelación en Apple 96 comentarios, calificación + 90.0 / -52.0, 39,300 visitas
- ¿Por qué Windows no se dirige en 2019 o CHYDNT? 881 comentarios, calificación + 123.0 / -70.0, 75,000 visitas
- No soy real 246 comentarios, calificación + 105.0 / -59.0, 63900 visitas
- Cinco tendencias aterradoras del desarrollo moderno 262 comentarios, calificación + 95.0 / -52.0, 77400 vistas
- Cuanto más rápido se olvide de OOP, mejor para usted y sus programas 1271 comentarios, calificación + 131.0 / -63.0, 128000 visitas
- Un año al volante de un vehículo eléctrico 1098 comentarios, calificación + 131.0 / -58.0, 71800 visitas
- Dejaré de patear bien para lanzar 179 comentarios, calificación + 147.0 / -62.0, 34,400 vistas
- Atrápame si puedes 215 comentarios, calificación + 141.0 / -58.0, 65,400 vistas
- Retirado con 22,922 comentarios, calificación + 259.0 / -100.0, 156,000 visitas
- Respuesta del psiquiatra al artículo 'Enfermo y saludable' 272 comentarios, calificación + 154.0 / -55.0, 43,400 visitas
- Los nuevos lenguajes de programación matan imperceptiblemente nuestra conexión con la realidad 764 comentarios, calificación + 164.0 / -52.0, 106,000 vistas
- Última etapa alcoholismo 597 comentarios, calificación + 208.0 / -60.0, 123,000 visitas
- 'Artículo de mamada': los científicos procesaron 109 horas de sexo oral para desarrollar una IA que apesta a un miembro 361 comentarios, calificación + 240.0 / -68.0, 236,000 vistas
Artículos mejor valorados- Cómo dormía Megafon en suscripciones móviles , 676 comentarios, calificación + 624.0 / -2.0, 162,000 visitas
- 'Contenido móvil' gratis, sin SMS ni registros. Detalles de fraude de megáfono , 474 comentarios, calificación + 488.0 / -8.0, 112,000 visitas
- Innovaciones en ruso , 612 comentarios, calificación + 480.0 / -33.0, 127,000 visitas
- Cómo no trabajé durante un año en Sberbank , 580 comentarios, calificación + 449.0 / -14.0, 233,000 visitas
- Cómo se bloquea Protonmail en Rusia , 398 comentarios, calificación + 418.0 / -7.0, 102,000 visitas
- 10 años en TI con un diagnóstico de esquizofrenia, consejos de supervivencia , 281 comentarios, calificación + 403.0 / -8.0, 122,000 visitas
- Un currículum honesto de un programador , 283 comentarios, calificación + 410.0 / -40.0, 165,000 visitas
- Cuando 'a' no es igual a 'a'. Después de un hack , 64 comentarios, calificación + 374.0 / -5.0, 74,600 vistas
- Aumentarlo! Aumento de resolución moderna , 214 comentarios, calificación + 366.0 / -1.0, 104000 vistas
- Mentiras LED de proporciones sin precedentes , 569 comentarios, calificación + 364.0 / -1.0, 241,000 vistas
- Baterías AAA baratas y caras , 382 comentarios, calificación + 363.0 / -6.0, 159,000 visitas
- Fraudes y EDS: todo está muy mal , 778 comentarios, calificación + 356.0 / -0.0, 175000 visitas
- Japón: un país de sentido común que en algunos lugares es irracional para nosotros , 483 comentarios, calificación + 365.0 / -12.0, 138,000 visitas
- Debilitar las tuercas en las reglas de Habr , 1285 comentarios, calificación + 338.0 / -13.0, 48300 visitas
- Recompensa del usuario a los autores de Habr , 245 comentarios, calificación + 320.0 / -0.0, 26,400 vistas
- Cómo atrapé a un hacker , 273 comentarios, calificación + 305.0 / -6.0, 110,000 visitas
- Mitos de la física popular moderna , 556 comentarios, calificación + 304.0 / -6.0, 99,600 visitas
- Ahora los buenos desarrolladores se miden por vistas y suscriptores, y esto es malo , 486 comentarios, calificación + 324.0 / -26.0, 74800 vistas
- Sobrevive en una colisión frontal y por qué la amnesia no es lo que piensas , 165 comentarios, calificación + 297.0 / -4.0, 61800 visitas
- Port scanner en la cuenta personal de Rostelecom , 194 comentarios, rating + 300.0 / -8.0, 111,000 visitas
Principales artículos favoritos- 42 operadores de búsqueda avanzada de Google (lista completa) 47.100 vistas, 917 marcadores
- Cómo convertirse en desarrollador de Java en 1.5 años 88,500 vistas, 894 marcadores
- Muestreador Utilidad de consola para visualizar el resultado de cualquier comando de shell 58.400 vistas, 801 marcadores
- HBO, gracias por recordarme ... 'Kit de primeros auxilios de Chernobyl' de un farmacéutico bielorruso 88,500 vistas, 797 marcadores
- Consejos prácticos, ejemplos y túneles SSH 40,000 vistas, 787 marcadores
- 256 líneas de C ++ desnudo: escribir un trazador de rayos desde cero en unas pocas horas 60,000 vistas, 745 marcadores
- Programación asincrónica (curso completo) 36,700 vistas, 690 marcadores
- Empleados 'quemados': ¿hay alguna salida? 116,000 vistas, 688 marcadores
- Una amplia descripción de las entrevistas de Python. Consejos y trucos 28,400 vistas, 687 marcadores
- 15 libros de aprendizaje automático para principiantes 18,700 vistas, 670 marcadores
- Conferencia sobre JavaScript y Node.js en KPI 52500 vistas, 656 marcadores
- Cómo escribo notas matemáticas en LaTeX en Vim 58100 vistas, 652 marcadores
- Lo que aprendí de mi amarga experiencia (más de 30 años en desarrollo de software) 100,000 vistas, 651 marcadores
- Una selección de diapositivas útiles de Julia Evans 41,000 vistas, 587 marcadores
- Encabezados HTTP para desarrolladores responsables 33,600 vistas, 566 marcadores
- N + 7 libros útiles 42,700 vistas, 563 marcadores
- Hackear autobus CAN. Tablero virtual 60,700 vistas, 562 marcadores
- Cuidado de mudarse a los Países Bajos con su esposa e hipoteca. Parte 1: búsqueda de trabajo 76200 vistas, 555 marcadores
- TCP vs UDP o el futuro de los protocolos de red 50,300 vistas, 538 marcadores
- Las mejores distribuciones de Linux para computadoras antiguas 66,000 vistas, 523 marcadores
Arriba por Ver relación de marcadores- 15 libros de aprendizaje automático para principiantes 670 marcadores, 18,700 vistas
- Música para sus proyectos: 12 recursos temáticos con pistas bajo licencia Creative Commons 477 marcadores, 18,100 vistas
- Una amplia descripción de las entrevistas de Python. Consejos y trucos 687 marcadores, 28,400 vistas
- Una selección de conjuntos de datos para el aprendizaje automático 455 marcadores, 19,000 vistas
- Generador de mazmorras basado en nodos de marcadores del gráfico 304, 12.700 vistas
- Una explicación simple de algoritmos de búsqueda de ruta y marcadores A * 316, 13,500 vistas
- ¿Herramientas web o dónde comenzar un pentester? 421 marcadores, 18800 vistas
- Aprendizaje Docker, Parte 2: Términos y conceptos 341 marcadores, 15,600 vistas
- Explorando Docker, Parte 3: Archivos Dockerfile 297 Marcadores, 13,800 Vistas
- Herramientas para analizar y depurar aplicaciones .NET 244 marcadores, 11,600 vistas
- Cómo depurar variables de entorno en marcadores de Linux 322, 15.900 vistas
- ¿Cómo dar los primeros pasos en robótica? 224 marcadores, 11,200 vistas
- Laberintos: clasificación, generación, búsqueda de soluciones 318 marcadores, 16,000 vistas
- Consejos prácticos, ejemplos y túneles Marcadores SSH 787, 40,000 vistas
- Conferencia Curso 'Fundamentos del procesamiento de señal digital' 418 marcadores, 21,400 vistas
- 42 operadores de búsqueda avanzada de Google (lista completa) 917 marcadores, 47,100 vistas
- 3D Game Shaders para principiantes 239 marcadores, 12,400 vistas
- El bypass de punto PKH se bloquea en un enrutador con OpenWrt usando los marcadores WireGuard y DNSCrypt 302, 15,700 vistas
- Desarrollando la habilidad de usar agrupación y visualización de datos en marcadores de Python 192, 10,000 vistas
- Otro Github 2: aprendizaje automático, conjuntos de datos y cuadernos Jupyter 265 marcadores, 13,900 vistas
Artículos más comentados- Lecciones ucranianas 1672 comentarios, 60,400 visitas
- Cohete 9M729. Algunas palabras sobre el "infractor" del Tratado INF 1371 comentarios, 83,000 visitas
- Github comenzó a bloquear repositorios de usuarios de Crimea, Cuba, Irán, Corea del Norte y Siria 1.309 comentarios, 44.500 visitas
- Debilitar las nueces en las reglas de Habr 1285 comentarios, 48300 visitas
- Cuanto más rápido se olvide de OOP, mejor para usted y sus programas 1271 comentarios, 128000 vistas
- Accidente de avión en Sheremetyevo: analogías históricas 1211 comentarios, 82,400 vistas
- ¿Cómo se convirtió la generación Y en una generación quemada? 1122 comentarios, 81,500 vistas
- El coche eléctrico no es para mí 1116 comentarios, 50,700 vistas
- 1098 , 71800
- 1021 , 27500
- 999 , 62100
- 997 , 7700
- 940 , 51600
- , 933 , 120000
- 923 , 50900
- 22 922 , 156000
- La elección de un automóvil para un especialista en TI, o consejos para teteras de una tetera 914 comentarios, 43.400 visitas
- Por qué los desarrolladores sénior no pueden obtener un trabajo 901 comentarios, 119,000 visitas
- El plan volvió a la economía 892 comentarios, 27.800 visitas
- Personal City Teleportator 889 comentarios, 40,800 vistas
Y finalmente, el último anti-stop por la cantidad de disgustos- Retirado con 22,922 comentarios, calificación + 259.0 / -100.0
- Leí 80 hojas de vida, tengo preguntas , 635 comentarios, calificación + 135.0 / -94.0
- Cariño, matamos a Internet , 933 comentarios, calificación + 392.0 / -83.0
- State and T-killers , 752 comentarios, calificación + 83.0 / -80.0
- Windows 2019 , ? , 881 , +123.0/-70.0
- : , . 1 , 394 , +100.0/-68.0
- ' ': 109 , , , 361 , +240.0/-68.0
- , . , 259 , +101.0/-63.0
- , , 1271 , +131.0/-63.0
- - , 179 , +147.0/-62.0
- , 668 , +315.0/-60.0
- , 597 , +208.0/-60.0
- , 246 , +105.0/-59.0
- , , 215 , +141.0/-58.0
- , 1098 , +131.0/-58.0
- Go , 70 , +76.0/-57.0
- '-' , 272 , +154.0/-55.0
- Apple , 96 , +90.0/-52.0
- , 764 , +164.0/-52.0
- Cinco tendencias aterradoras del desarrollo moderno , 262 comentarios, calificación + 95.0 / -52.0
Uff Tengo algunas muestras más interesantes, pero no aburriré a los lectores.Conclusión
Al construir la calificación, llamé la atención sobre dos puntos que parecían interesantes.En primer lugar, después de todo, el 60% de los mejores son artículos del género geektimes. Si habrá menos de ellos el próximo año y cómo se verá Habr sin artículos sobre cerveza, espacio, medicina, etc., no lo sé. Los lectores definitivamente perderán algo. A ver
En segundo lugar, la parte superior del marcador resultó ser inesperadamente de alta calidad. Esto es psicológicamente comprensible, los lectores pueden no prestar atención a la calificación y, si se necesita un artículo , lo agregarán a los marcadores. Y aquí está la mayor concentración de artículos útiles y serios. Creo que los propietarios del sitio deberían considerar de alguna manera la relación entre el número de marcadores y el programa de incentivos si desean aumentar esta categoría particular de artículos aquí en Habré.Algo asi.
Espero que haya sido informativo.La lista de artículos es larga, pero probablemente sea la mejor. Disfruta leyendo a todos.