Recientemente me encontré
con un conjunto de datos de
Kaggle con datos sobre 45 mil películas de Full MovieLens Dataset. Los datos contenían no solo información sobre los actores, el equipo de filmación, la trama, etc., sino también las calificaciones presentadas por los usuarios de las películas para películas (26 millones de calificaciones de 270 mil usuarios).
Una tarea estándar para tales datos es un sistema de recomendación. Pero por alguna razón, se me ocurrió
predecir la calificación de una película en función de la información disponible antes de su lanzamiento . No soy un gran conocedor del cine y, por lo tanto, generalmente me concentro en las críticas, eligiendo qué ver en las noticias. Pero los críticos también están algo sesgados: ven muchas más películas diferentes que el espectador promedio. Por lo tanto, parecía interesante predecir cómo la película sería apreciada por el público en general.
Entonces, el conjunto de datos contiene la siguiente información:
- Información sobre la película: tiempo de estreno, presupuesto, idioma, empresa y país de origen, etc. Además de la calificación promedio (y la pronosticaremos)
- Palabras clave (etiquetas) sobre la trama
- Nombres de actores y tripulantes
- Actualmente clasificaciones (estimaciones)
El código utilizado en el artículo (python) está disponible en
github .
Prefiltrado de datos
La matriz completa contiene datos sobre más de 45 mil películas, pero dado que la tarea es predecir la calificación, debe asegurarse de que las calificaciones de una película en particular sean objetivas. Por ejemplo, en el hecho de que mucha gente lo aprecia.
La mayoría de las películas tienen muy pocas calificaciones:

Por cierto, la película con el mayor número de clasificaciones (14075) me sorprendió: esto es
"Inception" . Pero los tres siguientes: "The Dark Knight", "Avatar" y "Avengers" parecen bastante lógicos.
Se espera que el número de calificaciones y el presupuesto de la película estén interconectados (presupuesto más bajo - calificaciones más bajas). Por lo tanto, la eliminación de películas con un pequeño número de clasificaciones hace que el modelo sesgado hacia películas más caras:
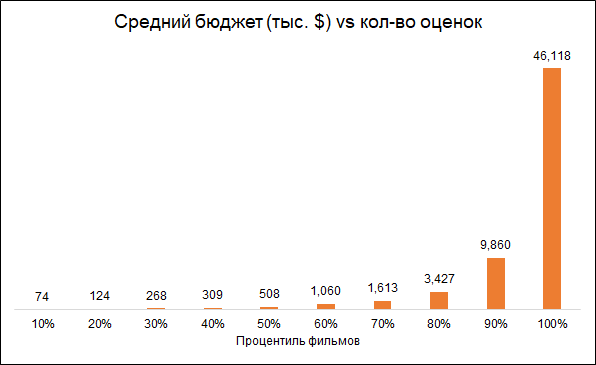
Dejamos para el análisis de películas con más de 50 clasificaciones.
Además, eliminaremos las películas lanzadas antes del inicio del servicio de calificación (1996). Aquí el problema es que las películas modernas se clasifican en promedio peor que las antiguas, simplemente porque entre las películas antiguas ven y evalúan lo mejor, y entre las modernas es todo.
Como resultado, la matriz final contiene alrededor de 6 mil películas.
Características usadas
Utilizaremos varios grupos de características:
- Metadatos de la película : si la película pertenece a la "colección" (serie de películas), país de lanzamiento, compañía fabricante, idioma de la película, presupuesto, género, año y mes de lanzamiento de la película, su duración
- Palabras clave: para cada película hay una lista de etiquetas que describen su trama. Como hay muchas palabras, se procesaron de la siguiente manera: agrupadas en grupos de similitud (por ejemplo, accidente y accidente automovilístico), en función de estos grupos y palabras individuales, se realizó un análisis de PCA y se seleccionaron los componentes más importantes de sus resultados. Esto redujo la dimensión del espacio de características.
- "Méritos" anteriores de los actores que protagonizaron la película. Para cada actor, se formó una lista de películas en las que protagonizó anteriormente y se calculó la calificación de estas películas. Entonces, para cada película se ha formado un indicador que agrega el éxito de las películas en las que los actores protagonizaron antes.
- Oscar Si los actores, director, productor, guionista o camarógrafo participaron previamente en la película, que fue nominada o recibió un Oscar por la mejor película, dirección o guión, esto se tuvo en cuenta en el modelo. Además, si los actores fueron nominados o ganadores del Premio de la Academia al Mejor Actor de Reparto o Rol de Reparto, esto también se tuvo en cuenta. Información sobre los Oscar recibida de Wikipedia.
Algunas estadísticas interesantes
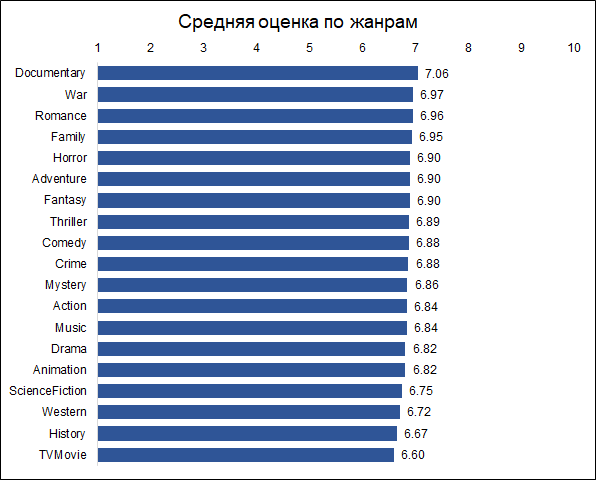
Las películas documentales reciben las calificaciones más altas. Esta es una buena razón para notar que diferentes películas son evaluadas por diferentes personas, y si los documentales fueron calificados por aficionados a la acción, entonces los resultados podrían ser diferentes. Es decir, las estimaciones están sesgadas debido a las preferencias iniciales del público. Pero para nuestra tarea esto no es importante, ya que queremos predecir una evaluación no condicionalmente objetiva (como si cada espectador hubiera visto todas las películas), es decir, la que el público le dará a la película.
Por cierto, es interesante que las películas históricas tengan una calificación mucho más baja que los documentales.
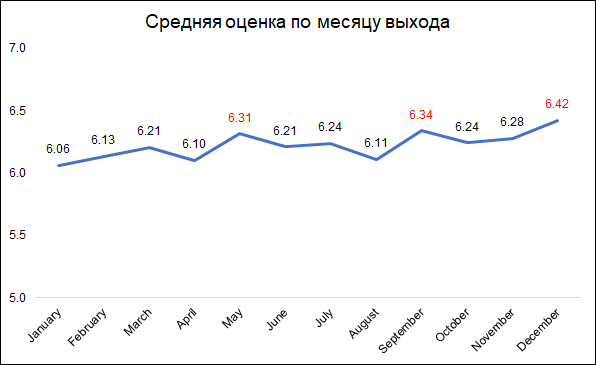
 Las calificaciones más altas se otorgan a las películas lanzadas en diciembre, septiembre y mayo.
Las calificaciones más altas se otorgan a las películas lanzadas en diciembre, septiembre y mayo.Esto probablemente puede explicarse de la siguiente manera:
- en diciembre, las compañías lanzan las mejores películas para recaudar taquilla durante las vacaciones de Navidad
- en septiembre, se estrenarán películas que participarán en la lucha por el Oscar
- Mayo es el tiempo de lanzamiento de los éxitos de taquilla de verano.
 La calificación de la película depende poco del presupuesto
La calificación de la película depende poco del presupuesto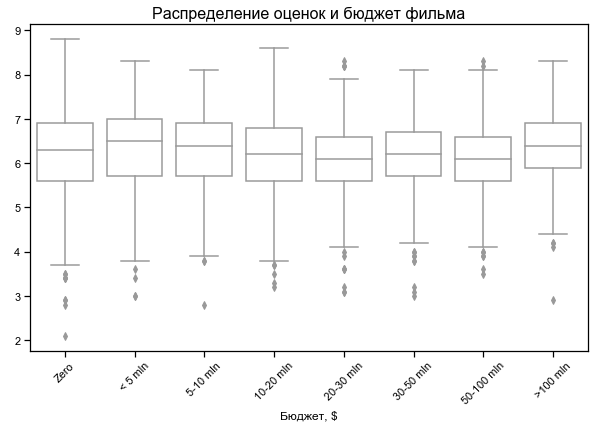
Presupuesto cero para algunas películas, probablemente sin datos
Las películas más cortas y más largas mejor valoradas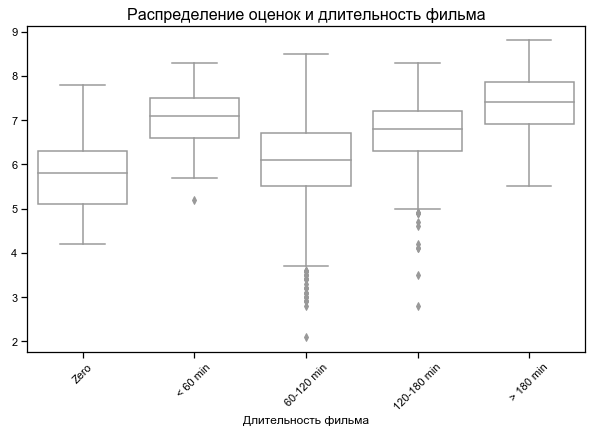
Para algunas películas, se indica la duración cero, probablemente sin datos
Resultados en diferentes conjuntos de características
Nuestra tarea - pronosticar la calificación - la tarea de regresión. Probaremos tres modelos: regresión lineal (como línea de base), SVM y XGB. Como métrica de calidad, elegimos RMSE. El gráfico a continuación muestra los valores RMSE en el conjunto de validación para diferentes modelos y diferentes conjuntos de características (quería entender si valía la pena jugar con las palabras clave y con los Oscar). Todos los modelos están construidos con hiperparámetros básicos.
Como puede ver, XGB tiene el mejor resultado con un conjunto completo de características (metadatos de película + palabras clave + Oscar).
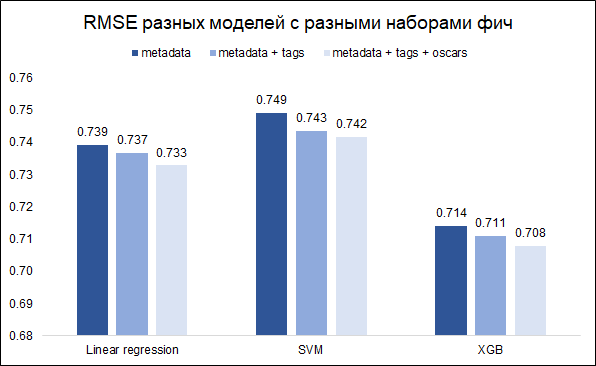
Al ajustar los hiperparámetros, fue posible reducir el RMSE de 0.708 a 0.706
Análisis de errores y comentarios finales.
Suponemos que los errores de menos del 5% son pequeños (aproximadamente un tercio) y los errores de más del 20% son grandes (aproximadamente el 10%). En otros casos (un poco más de la mitad) consideraremos el promedio de error.
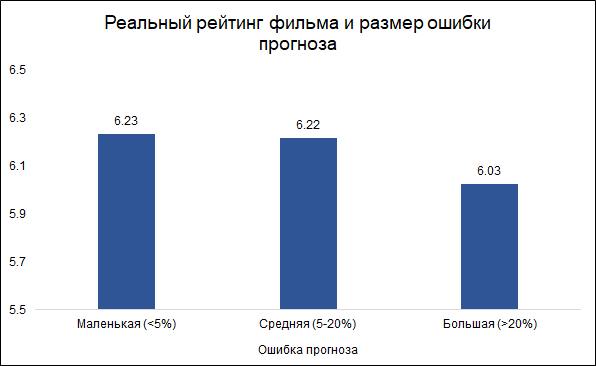
Curiosamente, el tamaño del error y la calificación de la película están relacionados:
es menos probable que el
modelo cometa errores en las películas buenas y más a menudo en las malas. Parece lógico: las buenas películas, como cualquier otro trabajo, son hechas por personas más experimentadas y profesionales. Sobre la película de Tarantino con la participación de Brad Pitt, se puede decir de antemano que lo más probable es que resulte bueno. Al mismo tiempo, una película de bajo presupuesto con actores poco conocidos puede ser buena y mala, y es difícil juzgarla sin verla.
Estas son las características más importantes del modelo (las variables PCA se refieren a palabras clave procesadas que describen la trama de la película):

Dos de estas características pertenecen a los Oscar, que fueron nominados previamente por miembros del equipo (director, productor, guionista, camarógrafo) o películas en las que protagonizaron los actores. Como se mencionó anteriormente, el error de pronóstico está asociado con la evaluación de la película, y en este sentido, las nominaciones previas para los Oscar pueden ser un buen delimitador para el modelo. De hecho, las películas que tienen al menos una nominación al Oscar (entre actores o equipos) tienen un error de pronóstico promedio de 8.3%, y las que no tienen tales nominaciones - 9.8%. De las 10 características principales utilizadas en el modelo, son las nominaciones al Oscar las que dan la mejor conexión con el tamaño del error.
Por lo tanto, surgió la idea de construir dos modelos separados: uno para películas en las que los actores o el equipo fueron nominados para un Oscar, y el segundo para el resto. La idea era que esto podría reducir el error general. Sin embargo, el experimento falló: el modelo general dio RMSE 0.706, y dos separados dieron 0.715.
Por lo tanto, dejaremos el modelo original. Los resultados de su precisión son los siguientes: RMSE en la muestra de entrenamiento - 0.688, en la muestra de validación - 0.706, y en la muestra de prueba - 0.732.
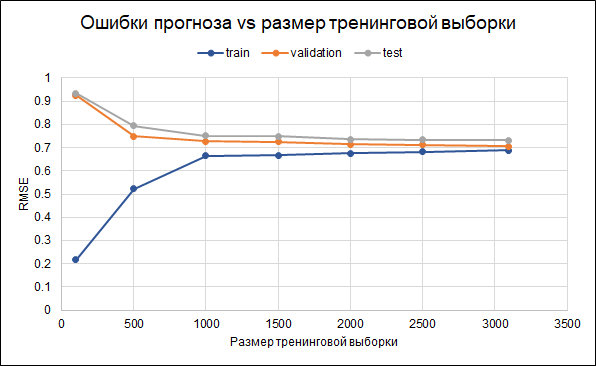
Es decir, hay algo de sobreajuste. Los parámetros de regularización ya se han establecido en el modelo mismo. Otra forma de reducir el sobreajuste podría ser recopilar más datos. Para comprender si esto ayudará, construiremos un gráfico de errores para diferentes tamaños de la muestra de entrenamiento, desde 100 hasta el máximo disponible de 3 mil. El gráfico muestra que a partir de aproximadamente 2.5 mil puntos en el conjunto de entrenamiento, errores en el entrenamiento, validación y cambio del conjunto de prueba pequeño, es decir, un aumento en la muestra no tendrá un efecto significativo.
 ¿Qué más puedes intentar para refinar el modelo?
¿Qué más puedes intentar para refinar el modelo?- Inicialmente, las películas se seleccionan de manera diferente (límite diferente en el número de votos, límites adicionales en otras variables)
- No todas las calificaciones se utilizan para calcular la calificación: es posible seleccionar usuarios más activos o eliminar a aquellos que solo dan calificaciones malas
- Pruebe diferentes formas de reemplazar los datos faltantes
Curiosamente, la película de 1997 "Batman y Robin" tuvo el mayor error de pronóstico (7 puntos de pronóstico en lugar de 4.2 puntos reales). La película con Arnold Schwarzenegger, George Clooney y Uma Thurman recibió
11 nominaciones (y una victoria) para el Premio Golden Raspberry, encabezó la
lista de las 50 peores películas de la historia de Empire, y condujo a la
cancelación de la secuela y al reinicio de toda la serie . Bueno, aquí el modelo, tal vez, se equivocó como un hombre :)