Siempre me interesó cómo distribuir mejor los libros en mi biblioteca electrónica. Como resultado, llegué a esta opción con el cálculo automático del número de páginas y otras cosas. Pido a todos los interesados bajo cat.
Parte 1. Dropbox
Todos los libros que tengo están en Dropbox. Hay 4 categorías en las que dividí todo: libro de texto, referencia, artístico, no artístico. Pero no agrego libros de referencia a la tableta.
La mayoría de los libros son .epub, el resto son .pdf. Es decir, la solución final debería cubrir de alguna manera ambas opciones.
Los caminos hacia los libros son algo como esto:
///// / .epub
Si el libro es ficción, entonces se elimina la categoría (es decir, "Diseño" en el caso anterior).
Decidí no molestarme con la API de Dropbox, afortunadamente tengo su aplicación que sincroniza la carpeta. Es decir, el plan es este: tomar libros de una carpeta, pasar cada libro por un contador de palabras, agregarlo a Notion.
Parte 2. Agregar una línea
La tabla en sí debería verse así. ATENCIÓN: los nombres de columna se hacen mejor en letras latinas.
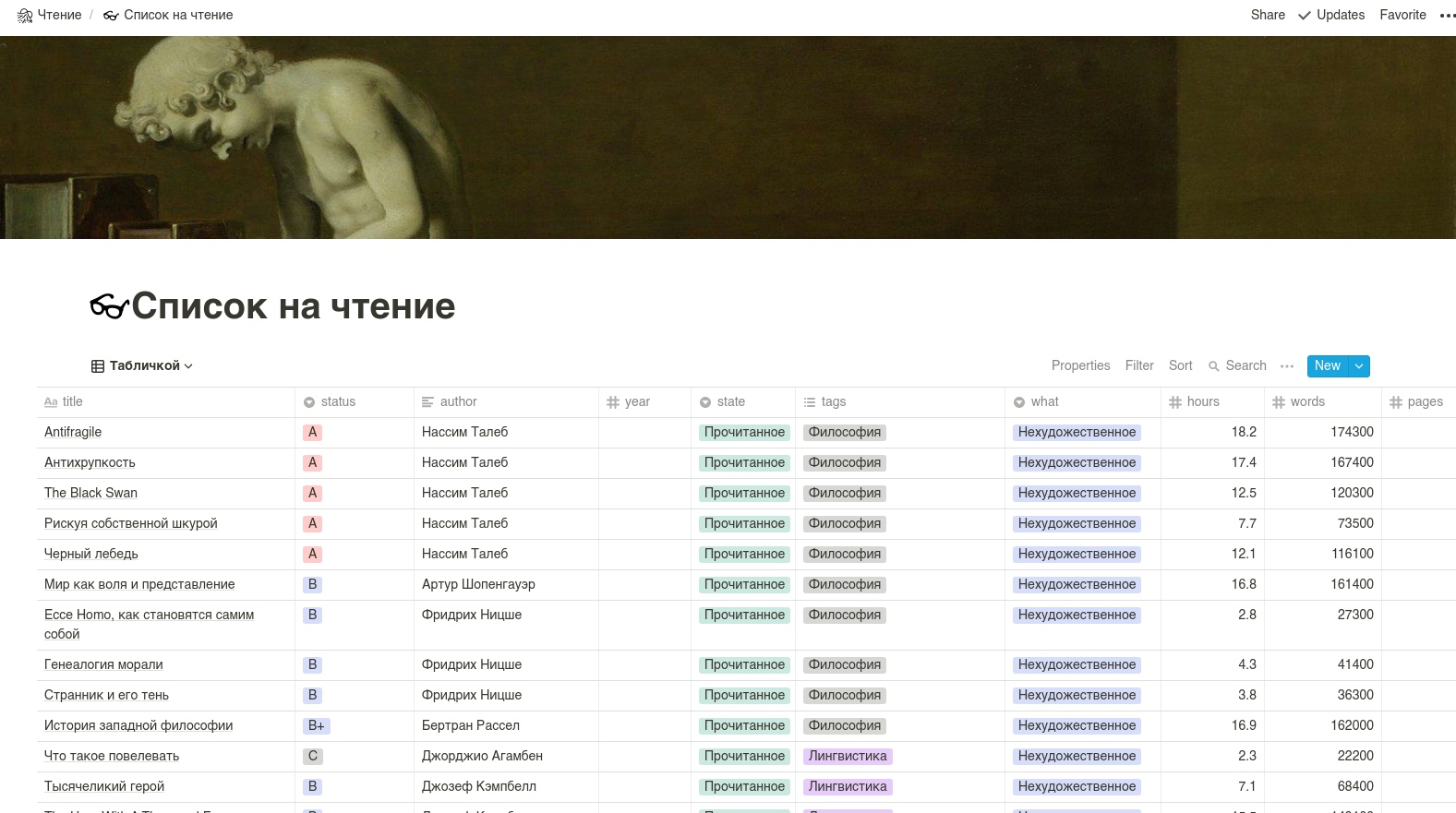
Utilizaremos Notion API no oficial, porque la oficial aún no se ha entregado.

Vaya a Notion, presione Ctrl + Shift + J, vaya a Aplicación -> Cookies, copie token_v2 y llámelo TOKEN. Luego vamos a la página que necesitamos con la placa de la biblioteca y copiamos el enlace. Llamar NOCION.
Luego escribimos el código para conectarnos a Notion.
database = client.get_collection_view(NOTION) current_rows = database.default_query().execute()
A continuación, escriba una función para agregar una línea a la etiqueta.
def add_row(path, file, words_count, pages_count, hours): row = database.collection.add_row() row.title = file tags = path.split("/") if len(tags) >= 1: row.what = tags[0] if len(tags) >= 2: row.state = tags[1] if len(tags) >= 3: if tags[0] == "": row.author = tags[2] elif tags[0] == "": row.tags = tags[2] elif tags[0] == "": row.tags = tags[2] if len(tags) >= 4: row.author = tags[3] row.hours = hours row.pages = pages_count row.words = words_count
¿Qué está pasando aquí? Tomamos y agregamos una nueva fila a la tabla en la primera fila. Luego, dividimos nuestro camino por "/" y obtenemos las etiquetas. Etiquetas: en términos de "Artístico", "Diseño", quién es el autor, etc. Luego establecemos todos los campos necesarios de la placa.
Parte 3. Contar palabras, relojes y otras delicias.
Esta es una tarea más complicada. Como recordamos, tenemos dos formatos: epab y pdf. Si todo está claro con el epab, probablemente hay palabras allí, entonces, ¿qué pasa con el pdf no es tan simple: simplemente puede consistir en imágenes pegadas.
Entonces la función para contar palabras en pdf se verá así: tomamos el número de páginas y multiplicamos por una cierta constante (número promedio de palabras por página).
Aquí esta:
def get_words_count(pages_number): return pages_number * WORDS_PER_PAGE
Esto es WORDS_PER_PAGE para la página A4 aproximadamente 300.
Ahora escribamos una función para contar las páginas. Utilizaremos PyPDF2 .
def get_pdf_pages_number(path, filename): pdf = PdfFileReader(open(os.path.join(path, filename), 'rb')) return pdf.getNumPages()
A continuación, escribiremos una cosita para contar páginas en epaba. Usamos epub_converter . Aquí tomamos un libro, lo convertimos en líneas, y para cada línea contamos palabras.
def get_epub_pages_number(path, filename): book = open_book(os.path.join(path, filename)) lines = convert_epub_to_lines(book) words_count = 0 for line in lines: words_count += len(line.split(" ")) return round(words_count / WORDS_PER_PAGE)
Ahora vamos a contar el tiempo. Tomamos nuestro número favorito de palabras y lo dividimos por su velocidad de lectura.
def get_reading_time(words_count): return round(((words_count / WORDS_PER_MINUTE) / 60) * 10) / 10
Parte 4. Conectando todas las partes
Necesitamos recorrer todos los caminos posibles en nuestra carpeta de libros. Compruebe si ya hay un libro en Notion: si lo hay, ya no necesitamos crear una línea.
Luego necesitamos determinar el tipo de archivo, dependiendo de esto, contar el número de palabras. Agrega un libro al final.
Aquí está el código que obtenemos:
for root, subdirs, files in os.walk(BOOKS_DIR): if len(files) > 0 and check_for_excusion(root): for file in files: array = file.split(".") filetype = file.split(".")[len(array) - 1] filename = file.replace("." + filetype, "") local_root = root.replace(BOOKS_DIR, "") print("Dir: {}, file: {}".format(local_root, file)) if not check_for_existence(filename): print("Dir: {}, file: {}".format(local_root, file)) if filetype == "pdf": count = get_pdf_pages_number(root, file) else: count = get_epub_pages_number(root, file) words_count = get_words_count(count) hours = get_reading_time(words_count) print("Pages: {}, Words: {}, Hours: {}".format(count, words_count, hours)) add_row(local_root, filename, words_count, count, hours)
Y la función para verificar si se agrega el libro se ve así:
def check_for_existence(filename): for row in current_rows: if row.title in filename: return True elif filename in row.title: return True return False
Conclusión
Gracias a todos los que leyeron este artículo. Espero que ella te ayude a leer más :)