En este artículo, recopilaremos un panel para el análisis de tráfico SEO. Descargaremos los datos a través de scripts de python y archivos .csv.
¿Qué descargaremos?
Para analizar la dinámica de las posiciones de las frases de búsqueda, deberá descargar desde
Yandex.Webmaster y
Google Search Console . Para evaluar la "utilidad" de bombear la posición de la frase de búsqueda, los datos de frecuencia serán útiles. Se pueden obtener de
Yandex.Direct y
Google Ads . Bueno, para analizar el comportamiento del lado técnico del sitio, utilizaremos
Page Speed Insider .
 Dinámica de tráfico SEO
Dinámica de tráfico SEOConsola de búsqueda de Google
Para interactuar con la API, utilizaremos la biblioteca
searchconsole . El github describe en detalle cómo obtener los tokens necesarios para iniciar sesión. El procedimiento para cargar datos y cargarlos en la base de datos MS SQL será el siguiente:
def google_reports():
Yandex.Webmaster
Lamentablemente, el webmaster solo puede cargar 500 frases de búsqueda. Cargue cortes por país, tipo de dispositivo, etc. él tampoco puede. Debido a estas restricciones, además de subir posiciones para 500 palabras del Webmaster, subiremos datos de Yandex.Metrica a las páginas de destino. Para aquellos que no tienen muchas frases de búsqueda, 500 palabras serán suficientes. Si su núcleo semántico según Yandex es lo suficientemente ancho, tendrá que descargar posiciones de otras fuentes o escribir su analizador de posición.
def yandex_reports(): token = "..."
Page Speed Insider
Le permite evaluar la velocidad de descarga del contenido del sitio. Si el sitio comenzó a cargar más lentamente, esto puede reducir significativamente la posición del sitio en los resultados de búsqueda.
Google Ads y Yandex Direct
Para estimar la frecuencia de las consultas de búsqueda, descargamos la frecuencia de nuestro núcleo de SEO.
 Previsión presupuestaria de Yandex
Previsión presupuestaria de Yandex Planificador de palabras clave de Google
Planificador de palabras clave de GoogleYandex Metric
Cargue datos sobre vistas y visitas a páginas de inicio de sesión del tráfico SEO.
token = token headers = {"Authorization": "OAuth " + token} now = datetime.now() fr = (now - timedelta(days = 9)).strftime("%Y-%m-%d") to = (now - timedelta(days = 3)).strftime("%Y-%m-%d") res = requests.get("https://api-metrika.yandex.net/stat/v1/data/?ids=ids&metrics=ym:s:pageviews,ym:s:visits&dimensions=ym:s:startURL,ym:s:lastsignSearchEngine,ym:s:regionCountry,ym:s:deviceCategory&date1={0}&date2={1}&group=all&filters=ym:s:lastsignTrafficSource=='organic'&limit=50000".format(fr,to), headers=headers) a = json.loads(res.text) re = pd.DataFrame(columns=['page', 'device', 'view', 'dt_from', 'dt_to', 'engine', 'visits', 'country', 'pageviews']) for i in a['data']: temp={} temp['page'] = i['dimensions'][0]['name'] temp['engine'] = i['dimensions'][1]['name'] temp['country'] = i['dimensions'][2]['name'] temp['device'] = i['dimensions'][3]['name'] temp['view'] = i['metrics'][0] temp['visits'] = i['metrics'][1] temp['pageviews'] = i['metrics'][0] temp['dt_from'] = fr temp['dt_to'] = to re=re.append(temp, ignore_index=True) to_sql_server(re, 'yandex_pages')
Adquisición de datos en Power BI
Veamos qué hemos logrado descargar:
- google_positions y yandex_positions
- google_frequency y yandex_frequency
- google_speed y yandex_speed
- yandex_metrika
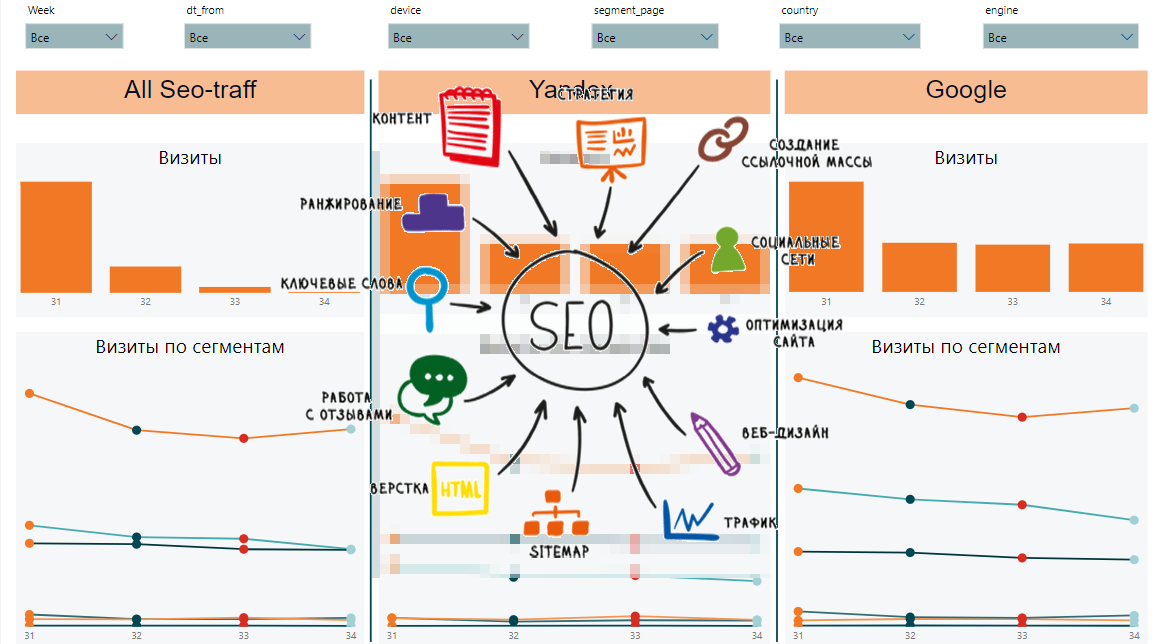
A partir de estos datos, podremos recopilar dinámicas por semana, por segmento, datos generales por segmentos y solicitudes, dinámicas y datos generales por páginas y velocidad de carga de contenido. Así es como podría verse el informe final:

Por un lado, hay muchos signos diferentes y es difícil entender cuáles son las tendencias generales. Por otro lado, cada placa muestra datos importantes sobre posiciones, impresiones, clics, CTR, velocidad de carga de la página.
Artículos del ciclo: