Por lo general, cuando alguien habla de OSM, aparece uno de los servicios web en su cabeza o una aplicación como Maps.me, basada en
datos de OSM. De hecho, el proyecto OSM es principalmente datos, todo lo demás es esencialmente un caso especial de su uso. Los servicios generalmente proporcionan solo una parte de la información obtenida de acuerdo con sus reglas.
Inicialmente, OSM es una colección de puntos, enlaces entre puntos y etiquetas para ellos. Las fuentes comunitarias tienen dos formatos. Inicialmente,
XML se utilizó como una forma prioritaria de distribuir datos, pero el archivo Planet.osm en forma no comprimida ya ha excedido los terabytes, y no veo ninguna razón para usarlo para información relativamente voluminosa.
PBF tiene una gran ventaja: es binario y el archivo Earth completo tiene un tamaño de aproximadamente 50 GB (XML comprimido aproximadamente 80 GB).
Se tratará de importar datos OSM desde el formato "nativo" utilizando la herramienta Osmosis.
También necesitamos PostgreSql con la extensión Postgis, en la que importaremos datos OSM.
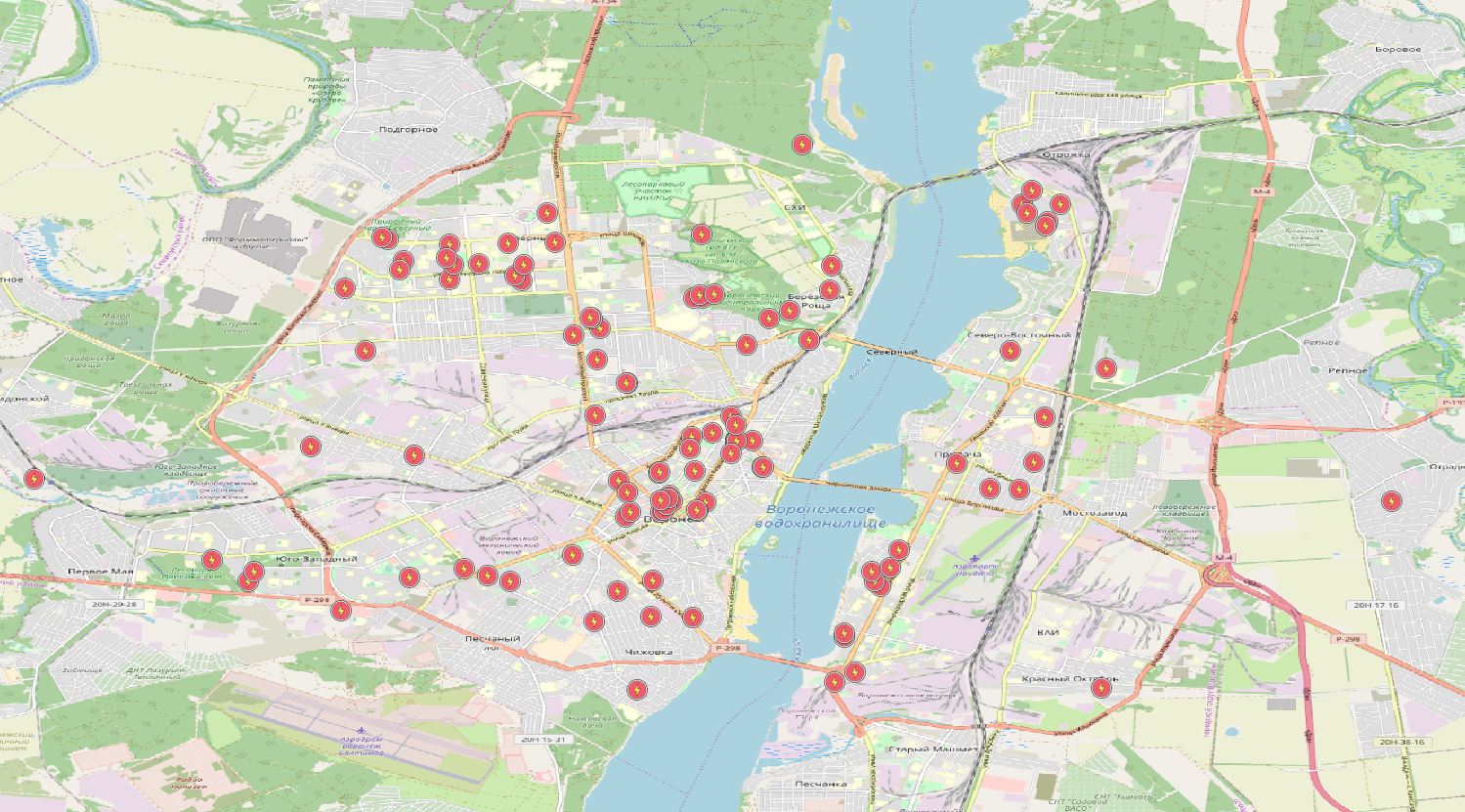
Como resultado, es posible obtener información sobre objetos
con las etiquetas enumeradas aquí en su base de datos
.
Preparación de DB.
Primero, cree una base de datos en Postgresql, el nombre realmente no importa.
psql -c "CREATE DATABASE map;"
A continuación, agregue las extensiones necesarias para seguir trabajando.
psql -d map -c "CREATE EXTENSION postgis; CREATE EXTENSION hstore; "
La extensión Postgis "conecta" a la base de datos el módulo real para trabajar con geodatos (le recuerdo que debe instalar Postgis). La extensión hstore está diseñada para funcionar con conjuntos de clave / valor, como Se incluirá una gran cantidad de información en las etiquetas OSM.
Descargar
Osmosis . En resumen, es un software para una amplia variedad de operaciones con datos OSM. Hay buena documentación sobre cómo trabajar con la línea de comando. Fuentes en Java. A continuación usaremos la línea de comando. También usé Osmosis como una biblioteca de Java, el código fuente (disponible en GitHub) me pareció lo suficientemente claro y la API fue fácil de usar.
Ahora estamos preparando la base de datos para importar. Las tablas y funciones necesarias se pueden crear utilizando scripts que se encuentran en la carpeta osmosis / script. Además del script principal, ejecutaremos código SQL que creará un campo para almacenar la geometría de las líneas. Esto se debe al hecho de que los datos de OSM se representan más probablemente como conexiones de puntos que como un conjunto de formas geométricas.
psql -d map -fc:\osmosis\script\pgsnapshot_schema_0.6.sql psql -d map -fc:\osmosis\script\pgsnapshot_schema_0.6_linestring.sql
Importar datos OSM en una base de datos
Bueno, ahora casi todo está listo. Incluso puedes ejecutar la importación. Es necesario decidir qué tomaremos como fuente. Es decir, debe elegir el formato y la fuente. Inicialmente, la comunidad OSM usó (y usa) el formato XML. Pero, la cantidad de datos está creciendo y creciendo, por lo que el formato de texto se está desplazando gradualmente. Usar PBF es algo más conveniente. La fuente central
planet.openstreetmap.org contiene datos para todo el mundo. Con un archivo, puede descargar toda la base de conocimiento del proyecto, que ya ha superado los 40 gigabytes en forma binaria. En aquellos casos en los que quería recortar un dato a partir de ahí, generalmente dejaba la computadora portátil funcionando toda la noche, proporcionándole más de 100 GB de espacio libre en el SSD para archivos temporales.
En nuestro caso, podemos comenzar usando cargas de miembros de la comunidad. Existen recursos que permiten descargar datos solo para una región específica. Por ejemplo,
download.geofabrik.de . Tome la región de Voronezh. Allí se incluye en un archivo que contiene datos para todo el distrito federal central. Puede descargar central-fed-district-latest.osm.pbf, y luego cortar la "pieza" deseada en un archivo o filtro separado por coordenadas al importar a la base de datos. Sugeriría la primera opción:
c:\osmosis\bin\osmosis.bat --read-pbf file="c:\downloads\central-fed-district-latest.osm.pbf" --bounding-box top=52.059564 left=37.92290 bottom=49.612297 right=43.225858 --write-pbf file="c:\map\voronezh.osm.pbf"
Todo es simple aquí. Leemos el archivo PBF, filtramos los resultados de lectura por el rectángulo de coordenadas y escribimos los resultados después de filtrarlos al archivo de salida. Puede filtrar por coordenadas con mayor precisión utilizando no un rectángulo, sino un polígono cuyas coordenadas están en un archivo separado.
El archivo resultante voronezh.osm.pbf se importa a la base de datos. Para conectarse, cree un archivo de propiedades con parámetros de acceso a la base de datos:
host=localhost database=map user=pguser password=pgpassword dbType=postgresql
Bueno, la importación en sí:
c:\osmosis\bin\osmosis.bat --read-pbf c:\map\voronezh.osm.pbf --write-pgsql authFile=c:\map\databaseinfo.properties
Datos importados
Ahora ya puede comenzar a estudiar lo que tenemos en la base de datos. El primer pensamiento es que hay un conjunto de cifras, pero esto no es del todo cierto. Como dije, el elemento principal es el punto. Todo lo demás se crea creando enlaces (relaciones) entre puntos. Todavía no profundizaremos, especialmente porque las manos ya están ansiosas por crear su propia tabla "plana" con algunos datos. Bueno, para líneas y puntos todo está listo, solo necesita crear una tabla con los campos necesarios e insertar las entradas necesarias allí. ¿Y qué campos tenemos? Aquí para ayudar a la wiki. Por ejemplo,
tome el par clave / valor power = line . Elija una lista de campos que usaremos, por ejemplo: nombre, voltaje, operador, cables. Resulta que queremos seleccionar las líneas que necesariamente tienen la propiedad power = line, junto con el nombre del campo, voltaje, operador, cables. Crea una tabla:
CREATE TABLE power_lines ( name varchar, voltage varchar, operator varchar, cables varchar, geom geometry )
Y la solicitud en sí para completar nuestra nueva tabla:
INSERT INTO power_lines SELECT ways.tags -> 'name' as name, ways.tags -> 'voltage' as voltage, ways.tags -> 'operator' as operator, ways.tags -> 'cables' as cables, ways.linestring as geom FROM ways WHERE ways.tags -> 'power' IN ( 'line' )
Hecho, tenemos una tabla con líneas eléctricas, ¡donde algunas líneas incluso tienen algunos de los campos llenos! Bueno, la tabla es ciertamente interesante, pero también sería bueno visualizar los datos para ver la geometría. La forma más rápida de hacer esto es con QGIS, excepto que este poderoso SIG primero debe instalarse. Allí ya agregamos una capa Postgis, use cualquier mapa como sustrato (puede usar el complemento OpenLayers). Configurado, mira:

¡Hurra! Incluso muy similar a la verdad, pensé, mirando por la ventana las líneas eléctricas.
¿Y polígonos?
La situación con los puntos es casi la misma, excepto que necesita usar la tabla de nodos. KDPV solo contiene
datos sobre subestaciones . ¿Y qué hay de los polígonos? Los polígonos también consisten en líneas (cerradas). Parece que puedes cerrar las líneas y disfrutar del resultado, pero no funciona de esa manera. Hay muchas trampas. Los polígonos pueden constar de varias líneas cerradas.
Por ejemplo, una isla puede estar en un lago. Por lo tanto, obtenemos un "agujero" en el vertedero. También tuve que aprender sobre el significado de la palabra "exclave" (para mi vergüenza, solo sabía sobre el "enclave"). Los polígonos también están agrupados. Por ejemplo, un bosque puede constar de varias "piezas". Que debemos representar como un solo objeto. Para colmo, debemos cortar los polígonos abiertos si algunos de los datos están fuera del mapa. Resolví estos y otros problemas en el script SQL, que puse en el estante de manera segura después de que funcionó. El proyecto
osmosis-multypolygon se encontró en GitHub. De mala gana, decidí que usar esta solución es una mejor opción que mi conjunto de scripts escritos en mi rodilla en un par de días. Hacemos lo que se dice en README, es decir, ejecutamos la lista de scripts, y tenemos la tabla multipolígonos, que se completa con las instrucciones de assemble.sql. Después de llenar la tabla con polígonos, puede llegar a lo que queremos obtener. ¿Elegimos el
territorio de los parques ?
Miramos la wiki y escribimos un guión:
CREATE TABLE parks ( name varchar, geom geometry ); INSERT INTO parks SELECT m.tags -> 'name' as name, m.geom FROM multipolygons m WHERE m.tags -> 'leisure' IN ( 'park' )
Ahora visualizamos:
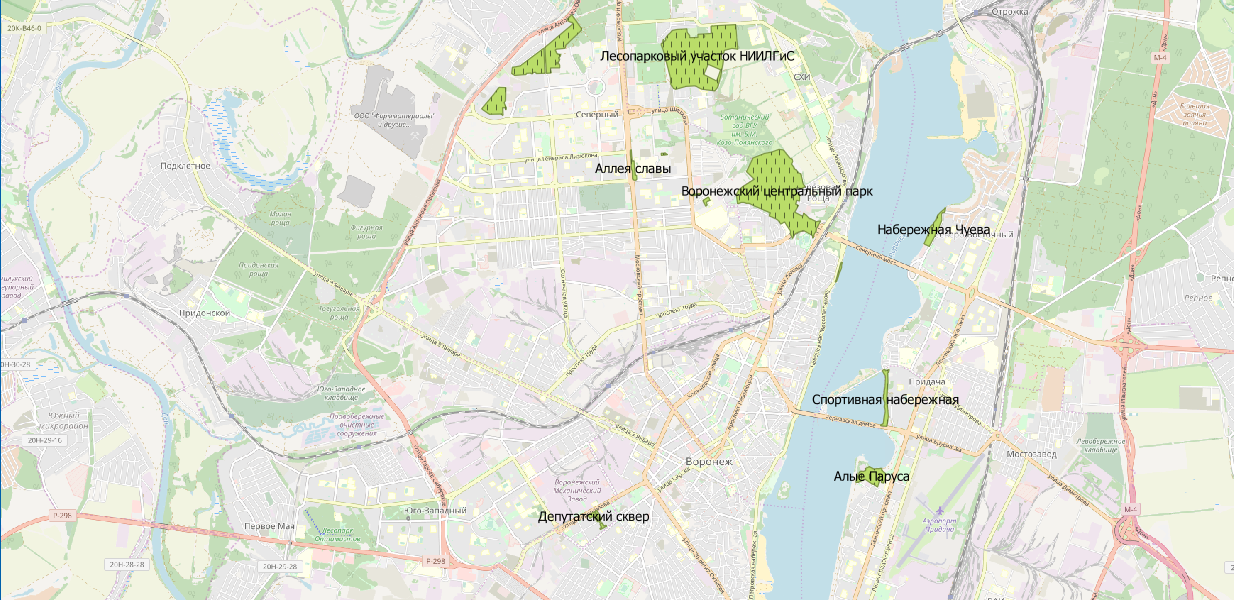
Bueno, para ser honesto, aquí puede discutir sobre la relevancia de los datos. Pero este es un tema para otra discusión.