
TL; DR
- Para lograr una alta observabilidad de contenedores y microservicios, las revistas y las métricas primarias no son suficientes.
- Para una recuperación más rápida y una mayor tolerancia a fallas, las aplicaciones deben aplicar el Principio de alta observabilidad (HOP).
- A nivel de aplicación, NRA requiere: registro adecuado, monitoreo cuidadoso, controles de salud y rastreo de rendimiento / transición.
- Utilice las comprobaciones readinessProbe y livenessProbe Kubernetes como un elemento HOP .
¿Qué es una plantilla de control de salud?
Al diseñar una aplicación de misión crítica y de alta disponibilidad, es muy importante pensar en algo como la tolerancia a fallas. Una aplicación se considera tolerante a fallas si se restaura rápidamente después de una falla. Una aplicación en la nube típica utiliza una arquitectura de microservicio, cuando cada componente se coloca en un contenedor separado. Y para asegurarse de que la aplicación en k8s sea altamente accesible, cuando diseñe un clúster, debe seguir ciertos patrones. Entre ellos se encuentra la Plantilla de control de salud. Determina cómo la aplicación informa k8s sobre su rendimiento. Esta no es solo información sobre si el pod funciona, sino también sobre cómo acepta solicitudes y responde a ellas. Cuanto más sepa Kubernetes sobre el rendimiento de un pod, más inteligentes serán las decisiones que tome sobre el enrutamiento del tráfico y el equilibrio de carga. Por lo tanto, el principio de alta observabilidad de la aplicación de manera oportuna para responder a las solicitudes.
El principio de alta observabilidad (NRA)
El principio de alta observabilidad es uno de los principios del diseño de aplicaciones en contenedores . En la arquitectura de microservicios, a los servicios no les importa cómo se procesa su solicitud (y con razón), pero es importante cómo obtener respuestas de los servicios que reciben. Por ejemplo, para autenticar a un usuario, un contenedor envía otra solicitud HTTP, esperando una respuesta en un formato específico, eso es todo. PythonJS también puede manejar la solicitud, y Python Flask puede responder. Los contenedores entre sí son como cajas negras con contenido oculto. Sin embargo, el principio de NRA requiere que cada servicio revele varios puntos finales API que muestren cuán eficiente es, así como su estado de preparación y tolerancia a fallas. Kubernetes pide a estas métricas que piensen en los siguientes pasos para el enrutamiento y el equilibrio de carga.
Una aplicación en la nube bien diseñada registra sus eventos clave utilizando los flujos estándar de E / S STDERR y STDOUT. A continuación, se ejecuta un servicio auxiliar, por ejemplo, filebeat, logstash o fluentd, que entrega los registros a un sistema de monitoreo centralizado (como Prometheus) y al sistema de recopilación de registros (paquete de software ELK). El siguiente diagrama muestra cómo funciona la aplicación en la nube de acuerdo con la Plantilla de comprobación de estado y el Principio de alta observabilidad.
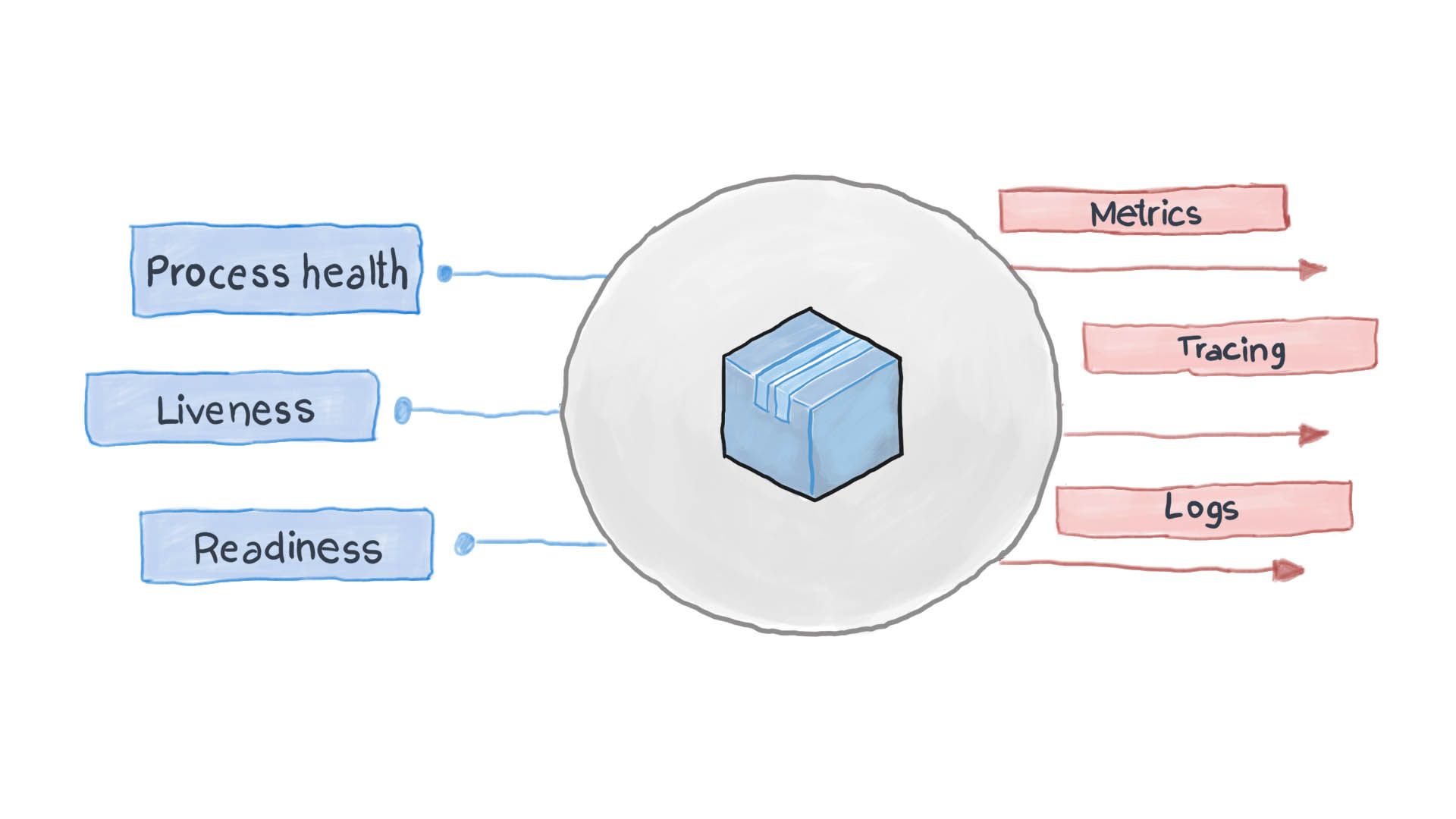
¿Cómo aplicar el patrón de control de salud en Kubernetes?
Fuera de la caja, k8s monitorea el estado de los pods utilizando uno de los controladores ( Implementaciones , ReplicaSets , DaemonSets , StatefulSets , etc., etc.). Habiendo descubierto que el pod se ha caído por alguna razón, el controlador intenta reiniciarlo o moverlo a otro nodo. Sin embargo, el pod puede informar que está en funcionamiento, mientras que en sí mismo no funciona. Aquí hay un ejemplo: su aplicación usa Apache como servidor web, instaló el componente en varios pods del clúster. Como la biblioteca no se configuró correctamente, todas las solicitudes a la aplicación responden con el código 500 (error interno del servidor). Al verificar la entrega, verificar el estado de las cápsulas da un resultado exitoso, sin embargo, los clientes piensan de manera diferente. Describimos esta situación indeseable de la siguiente manera:
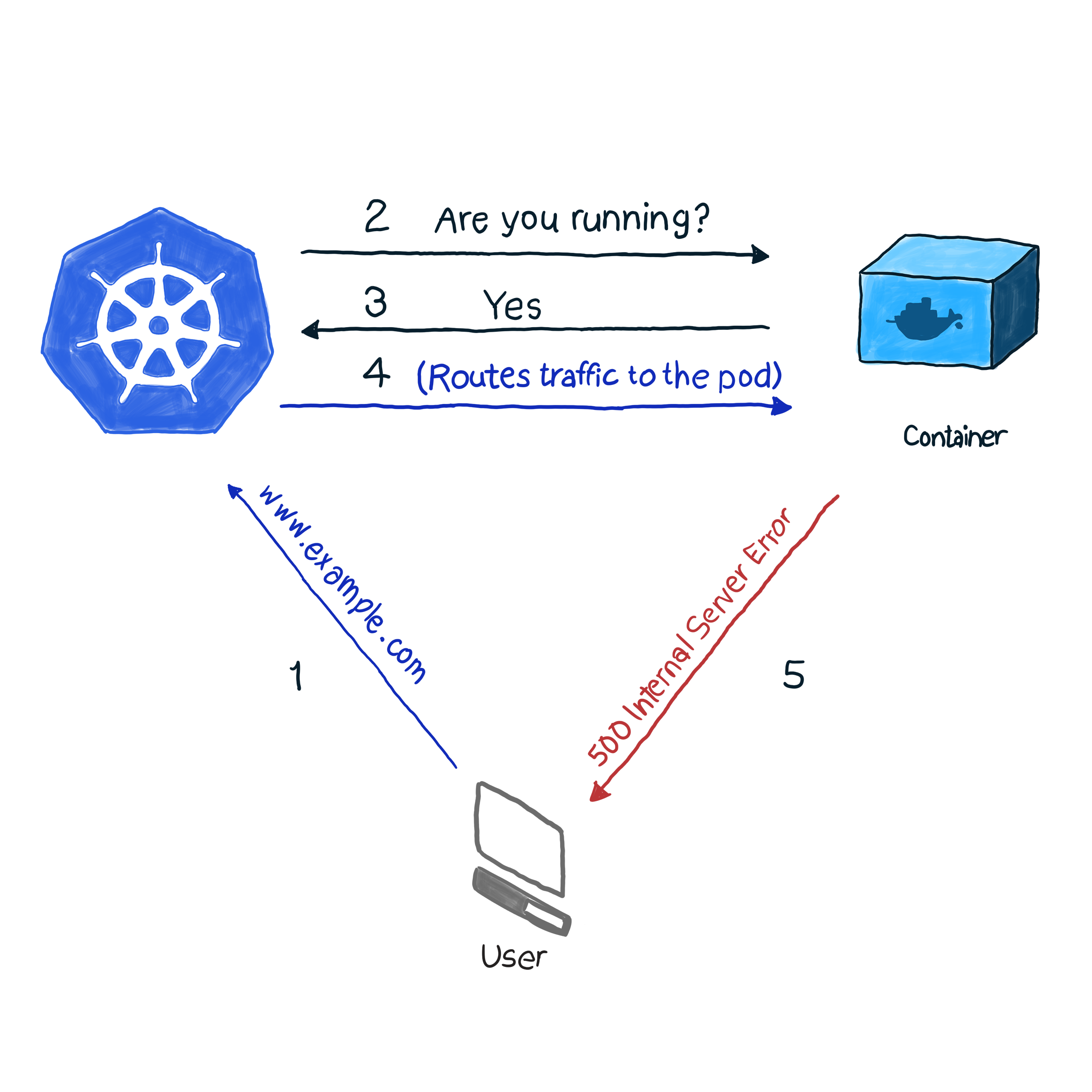
En nuestro ejemplo, k8s realiza una comprobación de estado . En este tipo de verificación, kubelet comprueba constantemente el estado del proceso en el contenedor. Una vez que comprenda que el proceso ha aumentado, lo reiniciará. Si el error se elimina simplemente reiniciando la aplicación, y el programa está diseñado para apagarse cuando hay algún error, entonces debe verificar la operatividad del proceso para seguir la NRA y la Plantilla de comprobación de estado. Es una pena que no todos los errores se eliminen reiniciando. Para este caso, k8s ofrece 2 formas más profundas de solucionar problemas de un pod : livenessProbe y readinessProbe .
LivenessProbe
Durante livenessProbe , kubelet realiza 3 tipos de comprobaciones: no solo descubre si el pod funciona, sino también si está listo para recibir y responder adecuadamente a las solicitudes:
- Establecer una solicitud HTTP para pod. La respuesta debe contener un código de respuesta HTTP en el rango de 200 a 399. Por lo tanto, los códigos 5xx y 4xx indican que el pod tiene problemas, incluso si el proceso se está ejecutando.
- Para verificar los pods con servicios que no son HTTP (por ejemplo, el servidor de correo Postfix), debe establecer una conexión TCP.
- Ejecución de un comando arbitrario para el pod (internamente). La verificación se considera exitosa si el código de salida del comando es 0.
Un ejemplo de cómo funciona esto. La definición del siguiente pod contiene una aplicación NodeJS que da un error de 500 para solicitudes HTTP. Para asegurarse de que el contenedor se reinicia después de recibir dicho error, utilizamos el parámetro livenessProbe:
apiVersion: v1 kind: Pod metadata: name: node500 spec: containers: - image: magalix/node500 name: node500 ports: - containerPort: 3000 protocol: TCP livenessProbe: httpGet: path: / port: 3000 initialDelaySeconds: 5
Esto no es diferente de ninguna otra definición de .spec.containers.livenessProbe , pero agregamos un objeto .spec.containers.livenessProbe . El parámetro httpGet acepta la ruta donde se envía la solicitud HTTP GET (en nuestro ejemplo, esto es / , pero en escenarios de batalla también puede haber algo como /api/v1/status ). Aún así, livenessProbe acepta el parámetro initialDelaySeconds , que indica a la operación de validación que espere un número específico de segundos. La demora es necesaria porque el contenedor necesita tiempo para iniciarse, y cuando se reinicia no estará disponible por un tiempo.
Para aplicar esta configuración a un clúster, use:
kubectl apply -f pod.yaml
Después de unos segundos, puede verificar el contenido del pod con el siguiente comando:
kubectl describe pods node500
Encuentre lo siguiente al final de la salida.
Como puede ver, livenessProbe inició una solicitud HTTP GET, el contenedor generó un error 500 (que fue programado para), kubelet lo reinició.
Si está interesado en cómo se programó la aplicación NideJS, aquí están los app.js y Dockerfile que se usaron:
app.js
var http = require('http'); var server = http.createServer(function(req, res) { res.writeHead(500, { "Content-type": "text/plain" }); res.end("We have run into an error\n"); }); server.listen(3000, function() { console.log('Server is running at 3000') })
Dockerfile
FROM node COPY app.js / EXPOSE 3000 ENTRYPOINT [ "node","/app.js" ]
Es importante prestar atención a esto: livenessProbe reiniciará el contenedor solo en caso de falla. Si el reinicio no soluciona el error que interfiere con el funcionamiento del contenedor, kubelet no podrá tomar medidas para eliminar el mal funcionamiento.
sonda de preparación
readinessProbe funciona de manera similar a livenessProbes (solicitudes GET, comunicaciones TCP y ejecución de comandos), con la excepción de las acciones de solución de problemas. El contenedor en el que se registra la falla no se reinicia, pero está aislado del tráfico entrante. Imagine que uno de los contenedores realiza muchos cálculos o está bajo una gran carga, lo que aumenta el tiempo de respuesta para las solicitudes. En el caso de livenessProbe, se activa una verificación de disponibilidad de respuesta (a través del parámetro de verificación timeoutSeconds), después de lo cual kubelet reinicia el contenedor. Cuando se inicia, el contenedor comienza a realizar tareas de uso intensivo de recursos y se reinicia nuevamente. Esto puede ser crítico para aplicaciones que se preocupan por la velocidad de respuesta. Por ejemplo, un automóvil en el camino espera una respuesta del servidor, la respuesta se retrasa y el automóvil se bloquea.
Escribamos una definición de readinessProbe que establezca el tiempo de respuesta para una solicitud GET en no más de dos segundos, y la aplicación responderá a una solicitud GET en 5 segundos. El archivo pod.yaml debería verse así:
apiVersion: v1 kind: Pod metadata: name: nodedelayed spec: containers: - image: afakharany/node_delayed name: nodedelayed ports: - containerPort: 3000 protocol: TCP readinessProbe: httpGet: path: / port: 3000 timeoutSeconds: 2
Expande el pod con kubectl:
kubectl apply -f pod.yaml
Espere un par de segundos y luego observe cómo funcionó readinessProbe:
kubectl describe pods nodedelayed
Al final de la conclusión, puede ver que algunos de los eventos son similares a esto .
Como puede ver, kubectl no reinició el pod cuando el tiempo de exploración excedió los 2 segundos. En cambio, canceló la solicitud. Las conexiones entrantes se redirigen a otros pods que funcionan.
Nota: ahora que se ha eliminado la carga adicional del pod, kubectl le envía solicitudes nuevamente: las respuestas a la solicitud GET ya no se retrasan.
A modo de comparación: el siguiente es el archivo app.js modificado:
var http = require('http'); var server = http.createServer(function(req, res) { const sleep = (milliseconds) => { return new Promise(resolve => setTimeout(resolve, milliseconds)) } sleep(5000).then(() => { res.writeHead(200, { "Content-type": "text/plain" }); res.end("Hello\n"); }) }); server.listen(3000, function() { console.log('Server is running at 3000') })
TL; DR
Antes del advenimiento de las aplicaciones en la nube, los registros eran el principal medio para monitorear y verificar el estado de las aplicaciones. Sin embargo, no había forma de tomar medidas de solución de problemas. Los registros son útiles hoy, deben recopilarse y enviarse al sistema de ensamblaje de registros para analizar situaciones de emergencia y tomar decisiones. [ todo esto podría hacerse sin aplicaciones en la nube usando monit, por ejemplo, pero con k8s se ha vuelto mucho más fácil :) - Ed. ]
Hoy en día, las correcciones deben hacerse casi en tiempo real, por lo que las aplicaciones ya no deberían ser cuadros negros. No, deben mostrar los puntos finales que permiten a los sistemas de monitoreo solicitar y recopilar datos valiosos sobre el estado de los procesos para que puedan responder instantáneamente si es necesario. Esto se denomina Plantilla de diseño de comprobación de estado, que sigue el Principio de alta observabilidad (NRA).
Kubernetes ofrece de forma predeterminada 2 tipos de comprobaciones de estado: readinessProbe y livenessProbe. Ambos utilizan los mismos tipos de comprobaciones (solicitudes HTTP GET, comunicaciones TCP y ejecución de comandos). Difieren en las decisiones que se toman en respuesta a los problemas en las cápsulas. livenessProbe reinicia el contenedor con la esperanza de que el error no vuelva a ocurrir, y readinessProbe aísla el pod del tráfico entrante hasta que se resuelva la causa del problema.
El diseño adecuado de la aplicación debe incluir ambos tipos de validación y que recopilen suficientes datos, especialmente cuando se crea una excepción. También debe mostrar los puntos finales API necesarios que transmiten métricas de estado de salud importantes al sistema de monitoreo (también llamado Prometheus).