IaC (Infraestructura como código) es un enfoque moderno y creo que la infraestructura es código. Significa que debemos usar la misma filosofía para la infraestructura que para el desarrollo de software. Si estamos hablando de que la infraestructura es código, entonces deberíamos reutilizar las prácticas del desarrollo para infraestructura, es decir, pruebas unitarias, programación de pares, revisión de código. Tenga en cuenta esta idea mientras lee el artículo.
Versión rusa
Es la traducción de mi discurso ( video RU ) en DevopsConf 2019-05-28 .
Infraestructura como historia bash

Imaginemos que se está incorporando a un proyecto y escucha algo como: "Usamos Infraestructura como enfoque de Código ". Desafortunadamente, lo que realmente significan es Infraestructura como historial de bash o Documentación como historial de bash . Esta es casi una situación real. Por ejemplo, Denis Lysenko describió esta situación en su discurso Cómo reemplazar la infraestructura y dejar de preocuparse (RU) . Denis compartió la historia sobre cómo convertir el historial de bash en una infraestructura de primer nivel.
Verifiquemos la definición del código fuente: a text listing of commands to be compiled or assembled into an executable computer program . Si queremos, podemos presentar Infraestructura como historial de bash como código. Este es un texto y una lista de comandos. Describe cómo se configuró un servidor. Además, es:
- Reproducible : puede obtener el historial de bash, ejecutar comandos y probablemente obtener infraestructura de trabajo.
- Versiones : sabes quién inició sesión, cuándo y qué se hizo.
Desafortunadamente, si pierde el servidor, no podrá hacer nada porque no hay historial de bash, lo perdió con el servidor.
¿Qué hay que hacer?
Infraestructura como código
Por un lado, este caso anormal, Infraestructura como historial de bash , se puede presentar como Infraestructura como Código , pero por otro lado, si desea hacer algo más complejo que el servidor LAMP, debe administrar, mantener y modificar el código . Hablemos sobre paralelismos entre Infraestructura como desarrollo de Código y desarrollo de software.
SECO
Estábamos desarrollando SDS (almacenamiento definido por software). El SDS consistía en un sistema operativo personalizado, servidores exclusivos, mucha lógica de negocios, como resultado, tenía que usar hardware real. Periódicamente, había una SDS de instalación de subtarea. Antes de publicar un nuevo lanzamiento, tuvimos que instalarlo y revisarlo. Al principio, parecía que era una tarea muy simple:
- SSH para alojar y ejecutar el comando.
- SCP un archivo.
- Modificar una configuración.
- Ejecuta un servicio.
- ...
- BENEFICIOS!
Creo que Make CM, not bash es un buen enfoque. Sin embargo, bash solo se usa en casos extremos y limitados, como al comienzo de un proyecto. Entonces, bash fue una elección bastante buena y razonable al comienzo del proyecto. El tiempo pasaba. Nos enfrentamos a diferentes solicitudes para crear nuevas instalaciones en una configuración ligeramente diferente. Estábamos introduciendo SSH en las instalaciones y ejecutando los comandos para instalar todo el software necesario, editando los archivos de configuración mediante scripts y, finalmente, configurando SDS a través de la API de descanso Web HTTP. Después de todo eso, la instalación se configuró y funcionó. Esta era una práctica bastante común, pero había muchos scripts de bash y la lógica de instalación se volvía más compleja cada día.
Desafortunadamente, cada guión era como un pequeño copo de nieve dependiendo de quién lo copiaba. También fue un verdadero dolor cuando estábamos creando o recreando la instalación.
Espero que tengas la idea principal, que en esta etapa tuvimos que modificar constantemente la lógica de los scripts hasta que el servicio estuvo bien. Pero, había una solución para eso. Estaba seco
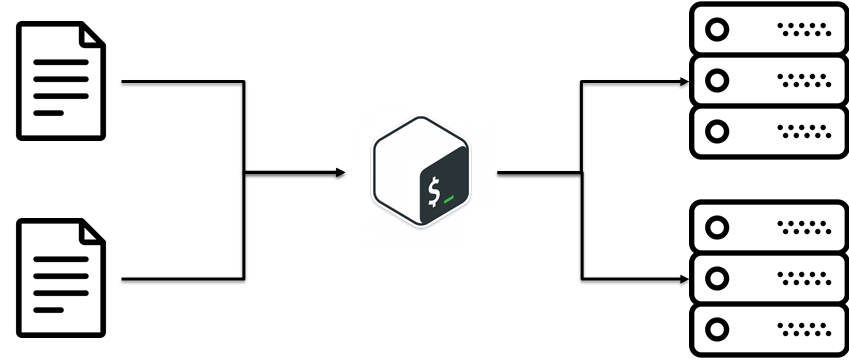
Hay un enfoque SECO (no repetir). La idea principal es reutilizar el código ya existente. Suena extremadamente simple. En nuestro caso, DRY significaba: configuraciones y scripts divididos.
SÓLIDO para CFM

El proyecto estaba creciendo, como resultado, decidimos usar Ansible. Había razones para eso:
- Bash no debe contener lógica compleja .
- Teníamos cierta experiencia en Ansible.
Había una cantidad de lógica de negocios dentro del código Ansible. Hay un enfoque para poner cosas en el código fuente durante el proceso de desarrollo de software. Se llama SÓLIDO . Desde mi punto de vista, podemos reutilizar SOLID para Infraestructura como Código . Déjame explicarte paso a paso.
El principio de responsabilidad única

Una clase solo debe tener una responsabilidad única, es decir, solo los cambios en una parte de la especificación del software deben poder afectar la especificación de la clase.
No debe crear un código de espagueti dentro de su código de infraestructura. Su infraestructura debe estar hecha de simples ladrillos predecibles. En otras palabras, podría ser una buena idea dividir el inmenso libro de jugadas de Ansible en roles independientes de Ansible. Será más fácil de mantener.
Los principios abiertos y cerrados
Las entidades de software ... deben estar abiertas para extensión, pero cerradas para modificación.
Al principio, estábamos implementando el SDS en máquinas virtuales, un poco más tarde agregamos la implementación a los servidores básicos . Lo habiamos hecho. Para nosotros fue tan fácil porque simplemente agregamos una implementación para piezas específicas de metal sin modificar la lógica de instalación de SDS.
El principio de sustitución de Liskov

Los objetos en un programa deben ser reemplazables con instancias de sus subtipos sin alterar la corrección de ese programa.
Seamos de mente abierta. SOLID es posible de usar en CFM en general, no fue un proyecto afortunado. Me gustaría describir otro proyecto. Es una solución empresarial lista para usar. Admite diferentes bases de datos, servidores de aplicaciones e interfaces de integración con sistemas de terceros. Voy a usar este ejemplo para describir el resto de SOLID
Por ejemplo, en nuestro caso, hay un acuerdo dentro del equipo de infraestructura: si implementa el rol ibm java o oracle java o openjdk, tendrá un binario ejecutable de java. Lo necesitamos porque los roles de nivel superior * Ansible dependen de eso. Además, nos permite intercambiar la implementación de Java sin modificar la lógica de instalación de la aplicación.
Desafortunadamente, no hay azúcar de sintaxis para eso en los libros de jugadas de Ansible. Significa que debe tenerlo en cuenta al desarrollar roles de Ansible.
El principio de segregación de interfaz
Muchas interfaces específicas del cliente son mejores que una interfaz de propósito general.
Al principio, estábamos poniendo la lógica de instalación de la aplicación en el libro de jugadas único, estábamos tratando de cubrir todos los casos y bordes de corte. Enfrentamos el problema que es difícil de mantener, por lo que cambiamos nuestro enfoque. Entendimos que un cliente necesita una interfaz nuestra (es decir, https en el puerto 443) y pudimos combinar nuestros roles de Ansible para cada entorno específico.
El principio de inversión de dependencia

Uno debería "depender de abstracciones, [no] concreciones".
- Los módulos de alto nivel no deberían depender de los módulos de bajo nivel. Ambos deberían depender de abstracciones (por ejemplo, interfaces).
- Las abstracciones no deberían depender de los detalles. Los detalles (implementaciones concretas) deben depender de abstracciones.
Me gustaría describir este principio a través de antipatrón.
- Había un cliente con una nube privada.
- Estábamos solicitando máquinas virtuales en la nube.
- Nuestra lógica de implementación dependía de en qué hipervisor se ubicara una máquina virtual.
En otras palabras, no pudimos reutilizar nuestro IaC en otra nube porque la lógica de implementación de nivel superior dependía de la implementación de nivel inferior. Por favor no lo hagas
Interacción

La infraestructura no es solo código, también se trata de código de interacción <-> DevOps, DevOps <-> DevOps, IaC <-> personas.
Factor de bus
Imaginemos que hay un ingeniero de DevOps, John. John sabe todo sobre su infraestructura. Si John es atropellado por un autobús, ¿qué pasará con su infraestructura? Desafortunadamente, es casi un caso real. Algunas veces suceden cosas. Si ha sucedido y no comparte conocimientos sobre IaC, la infraestructura entre los miembros de su equipo enfrentará muchas consecuencias impredecibles e incómodas. Hay algunos enfoques para lidiar con eso. Hablemos sobre ellos.
Par DevOpsing

Es como la programación en pareja. En otras palabras, hay dos ingenieros de DevOps y usan una sola computadora portátil / teclado para configurar la infraestructura: configurar un servidor, crear un rol Ansible, etc. Suena genial, sin embargo, no funcionó para nosotros. Hubo algunos casos personalizados cuando funcionó parcialmente.
- Incorporación : el mentor y la nueva persona obtienen una tarea real de un trabajo atrasado y trabajan juntos: transfieren el conocimiento del mentor a la persona.
- Llamada a incidentes : durante la resolución de problemas, hay un grupo de ingenieros que buscan una solución. El punto clave es que hay una persona que lidera este incidente. La persona comparte pantalla e ideas. Otras personas lo siguen cuidadosamente y se dan cuenta de trucos, errores, análisis de registros, etc.
Revisión de código
Desde mi punto de vista, la revisión de código es una de las formas más eficientes de compartir conocimientos dentro de un equipo sobre su infraestructura. Como funciona
- Hay un repositorio que contiene la descripción de su infraestructura.
- Todos están haciendo sus cambios en una rama dedicada.
- Durante la solicitud de fusión, puede revisar delta de cambios en su infraestructura.
Lo más interesante es que estábamos rotando un revisor. Significa que cada dos días elegimos un nuevo revisor y el revisor estaba revisando todas las solicitudes de fusión. Como resultado, teóricamente, cada persona tenía que tocar una nueva parte de la infraestructura y tenía un conocimiento promedio sobre nuestra infraestructura en general.
Estilo de código

El tiempo pasaba, a veces discutíamos durante la revisión porque el revisor y el confirmador podrían usar un estilo de código diferente: 2 espacios o 4, camelCase o snake_case . Lo implementamos, sin embargo, no fue un picnic.
- La primera idea fue recomendar el uso de linters. Todos tenían su propio entorno de desarrollo: IDE, OS ... era complicado sincronizar y unificar todo.
- La idea se convirtió en un bot flojo. Después de cada confirmación, el bot estaba revisando el código fuente y presionando mensajes flojos con una lista de problemas. Desafortunadamente, en la gran mayoría de los casos, no hubo cambios en el código fuente después de los mensajes.
Maestro de construcción verde
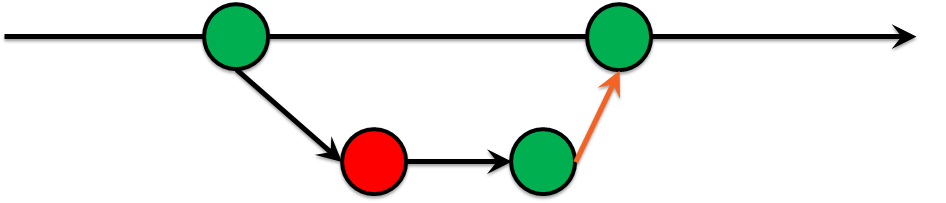
Luego, el paso más doloroso fue restringir el empuje a la rama maestra para todos. Solo a través de solicitudes de fusión y pruebas verdes tienen que estar bien. Esto se llama Green Build Master . En otras palabras, está 100% seguro de que puede implementar su infraestructura desde la rama maestra. Es una práctica bastante común en el desarrollo de software:
- Hay un repositorio que contiene la descripción de su infraestructura.
- Todos están haciendo sus cambios en una rama dedicada.
- Para cada rama, estamos ejecutando pruebas.
- No puede fusionarse en la rama maestra si las pruebas fallan.
Fue una decisión difícil. Con suerte, como resultado durante el proceso de revisión, no hubo discusión sobre el estilo del código y la cantidad de olor del código estaba disminuyendo.
Prueba IaC

Además de la verificación del estilo de código, puede verificar que puede implementar o recrear su infraestructura en un entorno limitado. Para que sirve Es una pregunta sofisticada y me gustaría compartir una historia en lugar de una respuesta. Were fue un escalador automático personalizado para AWS escrito en Powershell. El escalador automático no verificó los bordes de corte para los parámetros de entrada, como resultado, creó toneladas de máquinas virtuales y el cliente no estaba contento. Es una situación incómoda, con suerte, es posible detectarla en las primeras etapas.
Por un lado, es posible probar el script y la infraestructura, pero por otro lado, está aumentando una cantidad de código y haciendo que la infraestructura sea más compleja. Sin embargo, la verdadera razón para esto es que está poniendo a prueba su conocimiento sobre infraestructura. Estás describiendo cómo las cosas deberían funcionar juntas.
Pirámide de pruebas IaC

Prueba IaC: análisis estático
Puede crear toda la infraestructura desde cero para cada confirmación, pero, por lo general, hay algunos obstáculos:
- El precio es estratosférico.
- Requiere mucho tiempo
Con suerte, hay algunos trucos. Debe tener muchas pruebas simples, rápidas y primitivas en su base.
Bash es complicado
Echemos un vistazo a un ejemplo extremadamente simple. Me gustaría crear un script de respaldo:
- Obtenga todos los archivos del directorio actual.
- Copie los archivos en otro directorio con un nombre modificado.
La primera idea es:
for i in * ; do cp $i /some/path/$i.bak done
Bastante bien Sin embargo, ¿qué pasa si el nombre del archivo contiene espacio ? Somos tipos inteligentes, usamos citas:
for i in * ; do cp "$i" "/some/path/$i.bak" done
¿Hemos terminado? No! ¿Qué pasa si el directorio está vacío? Gloging falla en este caso.
find . -type f -exec mv -v {} dst/{}.bak \;
Hemos terminado? Todavía no ... Olvidamos que el nombre de archivo puede contener \n caracteres.
touch x mv x "$(printf "foo\nbar")" find . -type f -print0 | xargs -0 mv -t /path/to/target-dir
Puede detectar algunos problemas del ejemplo anterior a través de Shellcheck . Hay muchas herramientas como esa, se denominan linters y puede encontrar la más adecuada para su IDE, pila y entorno.
Prueba IaC: Pruebas unitarias
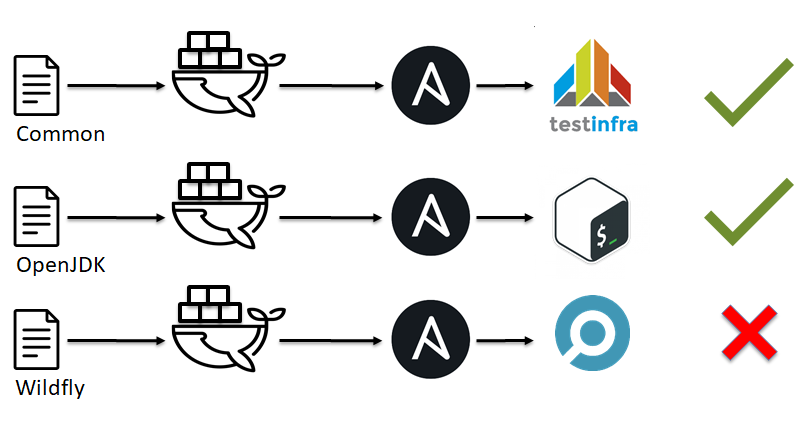
Como puede ver, las linters no pueden atrapar todo, solo pueden predecir. Si continuamos pensando en los paralelismos entre el desarrollo de software y la Infraestructura como Código, deberíamos mencionar las pruebas unitarias. Hay muchos sistemas de pruebas unitarias como shunit , JUnit , RSpec , pytest . Pero, ¿alguna vez has oído hablar de las pruebas unitarias para Ansible, Chef, Saltstack, CFengine?
Cuando hablamos de SOLID para CFM, mencioné que nuestra infraestructura debería estar hecha de simples ladrillos / módulos. Ahora ha llegado el momento:
- Dividir la infraestructura en módulos / interrupciones simples, es decir, roles Ansible.
- Cree un entorno, es decir, Docker o VM.
- Aplique su único descanso / módulo simple al medio ambiente.
- Comprueba que todo está bien o no.
... - BENEFICIOS!
¿Cuál es la prueba para CFM y su infraestructura? es decir, puede ejecutar un script o puede usar una solución lista para producción como:
Echemos un vistazo a testinfra, me gustaría comprobar que los usuarios test1 , test2 existen y son parte del grupo sshusers :
def test_default_users(host): users = ['test1', 'test2' ] for login in users: assert host.user(login).exists assert 'sshusers' in host.user(login).groups
¿Cuál es la mejor solución? No hay una respuesta única para esa pregunta, sin embargo, creé el mapa de calor y comparé los cambios en estos proyectos durante 2018-2019:

Marcos de prueba de IaC
Después de eso, puede enfrentarse a una pregunta sobre cómo ejecutarlo todo junto. Por un lado, puede hacer todo por su cuenta si tiene suficientes ingenieros excelentes, pero por otro lado, puede usar soluciones listas para producción de código abierto:
Creé el mapa de calor y comparé los cambios en estos proyectos durante 2018-2019:

Molécula vs. Testkitchen

Al principio, intentamos probar roles ansibles a través de testkitchen dentro de hyper-v :
- Crear máquinas virtuales.
- Aplicar roles de Ansible.
- Ejecute Inspec.
Tomó 40-70 minutos para 25-35 roles de Ansible. Fue demasiado largo para nosotros.
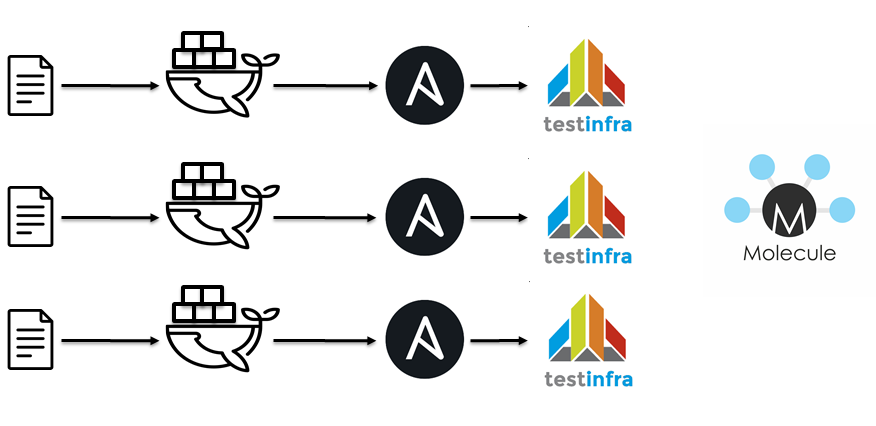
El siguiente paso fue usar Jenkins / docker / Ansible / molécula. Es aproximadamente la misma idea:
- Lint Ansible playbooks.
- Lint Roles de Ansible.
- Ejecute un contenedor acoplable.
- Aplicar roles de Ansible.
- Ejecute testinfra.
- Verifica la idempotencia.
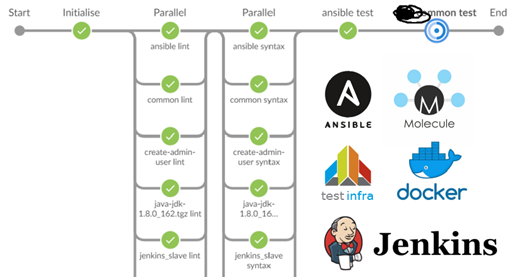
La selección de 40 roles y la evaluación de diez de ellos tomó aproximadamente 15 minutos.

¿Cuál es la mejor solución? Por un lado, no quiero ser la autoridad final, pero por otro lado, me gustaría compartir mi punto de vista. No existe una bala de plata, sin embargo, en el caso de la molécula Ansible es una solución más adecuada que testkitchen.
Pruebas IaC: Pruebas de integración
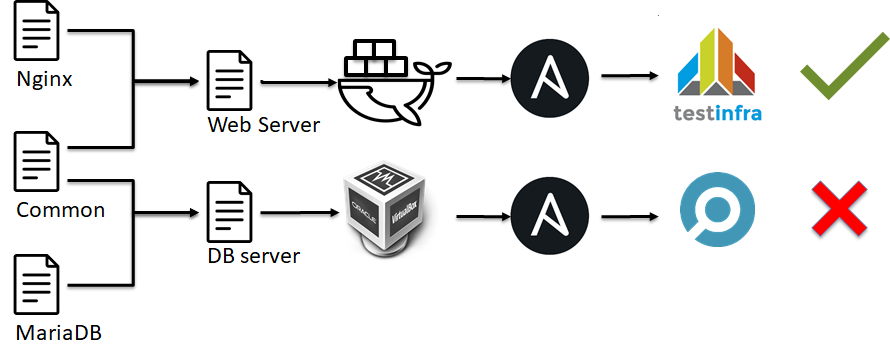
En el siguiente nivel de la pirámide de pruebas de IaC , hay pruebas de integración . Las pruebas de integración para infraestructura se parecen a las pruebas unitarias:
- Dividir la infraestructura en módulos / interrupciones simples, es decir, roles Ansible.
- Cree un entorno, es decir, Docker o VM.
- Aplique una combinación de descanso / módulo simple al entorno.
- Comprueba que todo está bien o no.
... - BENEFICIOS!
En otras palabras, durante las pruebas unitarias, verificamos un módulo simple (es decir, rol Ansible, script de Python, módulo Ansible, etc.) de una infraestructura, pero en el caso de las pruebas de integración, verificamos la configuración completa del servidor.
Pruebas IaC: pruebas de extremo a extremo
En la parte superior de la pirámide de pruebas de IaC , hay pruebas de extremo a extremo . En este caso, no verificamos el servidor dedicado, el script, el módulo de nuestra infraestructura; Verificamos que toda la infraestructura en conjunto funciona correctamente. Desafortunadamente, no hay una solución inmediata para eso o no he oído hablar de ellos (por favor, márqueme si los conoce). Por lo general, las personas reinventan la rueda porque hay demanda de pruebas de infraestructura de extremo a extremo. Entonces, me gustaría compartir mi experiencia, espero que sea útil para alguien.
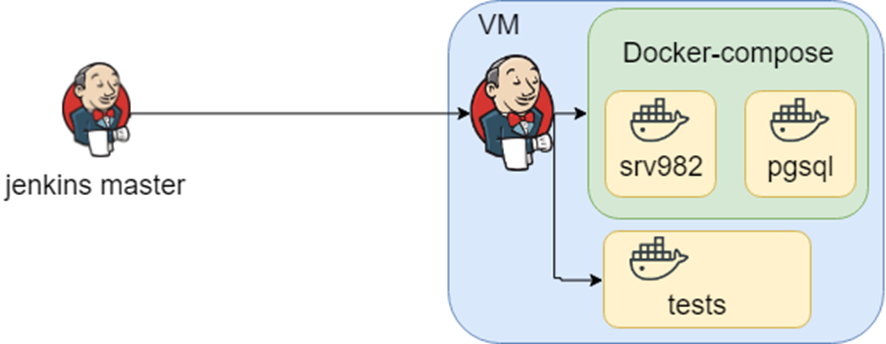
En primer lugar, me gustaría describir el contexto. Es una solución empresarial lista para usar, admite diferentes bases de datos, servidores de aplicaciones e interfaces de integración con sistemas de terceros. Por lo general, nuestros clientes son una empresa inmensa con un entorno completamente diferente. Tenemos conocimiento sobre diferentes combinaciones de entornos y lo almacenamos como diferentes archivos docker-compose. Además, si hay coincidencias entre los archivos de compilación de docker y las pruebas, lo almacenamos como trabajos de Jenkins.
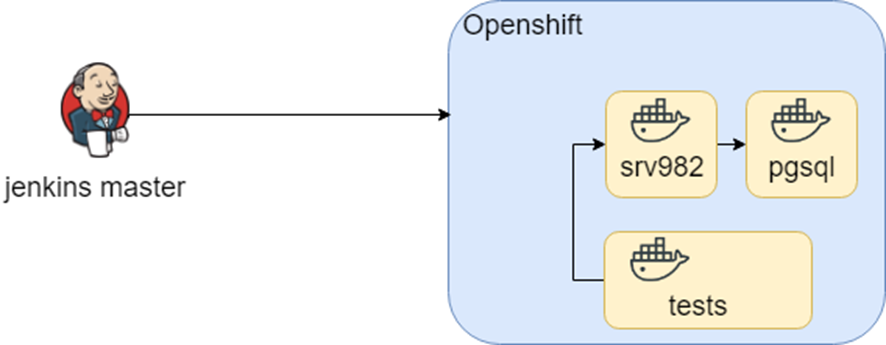
Este esquema había estado funcionando durante un período de registro silencioso cuando durante la investigación de OpenShift intentamos migrarlo a OpenShift. Utilizamos aproximadamente los mismos contenedores (otra vez SECO) y solo cambiamos el entorno.
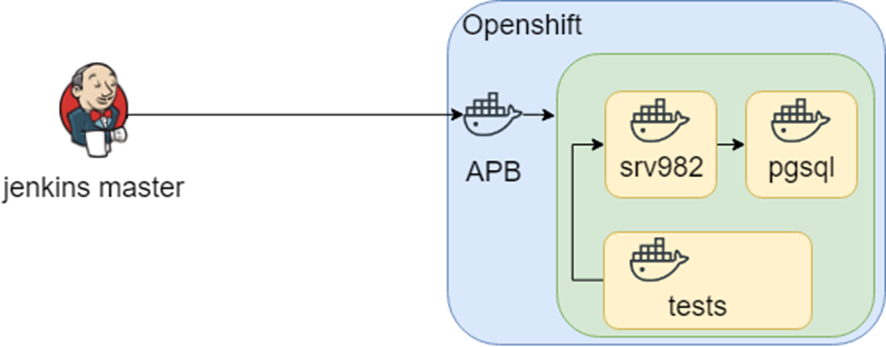
Continuamos investigando y encontramos APB (Ansible Playbook Bundle). La idea principal es empacar todas las cosas necesarias en un contenedor y ejecutar el contenedor dentro de Openshift. Significa que tiene una solución reproducible y comprobable.

Todo estuvo bien hasta que enfrentamos un problema más: tuvimos que mantener una infraestructura heterogénea para los entornos de prueba. Como resultado, almacenamos nuestro conocimiento sobre cómo crear infraestructura y ejecutar pruebas en los trabajos de Jenkins.
Conclusión
Infraestructura como Código es una combinación de:
- Código
- Interacción de personas.
- Pruebas de infraestructura.