El enfoque de IaC (Infraestructura como código) consiste no solo en el código que se almacena en el repositorio, sino también en las personas y los procesos que rodean este código. ¿Es posible reutilizar enfoques desde el desarrollo de software hasta la gestión y la descripción de la infraestructura? No será superfluo tener esta idea en mente mientras lees el artículo.
Versión rusa
Esta es una transcripción de mi actuación en DevopsConf 2019-05-28 .
Infraestructura como historia bash

Supongamos que viene a un nuevo proyecto y le dicen: "tenemos Infraestructura como Código ". En realidad, resulta que la Infraestructura como bash history o, por ejemplo, la Documentación como bash history . Esta es una situación muy real, por ejemplo, Denis Lysenko describió un caso similar en su discurso Cómo reemplazar toda la infraestructura y comenzar a dormir en paz , contó cómo, desde la historia de Bash, obtuvieron una infraestructura delgada en el proyecto.
Si lo desea, puede decir que Infraestructura como historial de bash es como el código:
- reproducibilidad : puede tomar el historial de bash, ejecutar comandos desde allí, tal vez, por cierto, obtendrá una configuración de trabajo en la salida.
- versionado : sabes quién entró y qué hizo, una vez más, no el hecho de que esto te llevará a una configuración de trabajo en la salida.
- historia : historia de quién hizo qué. solo que no puedes usarlo si pierdes el servidor.
Que hacer
Infraestructura como código
Incluso un caso tan extraño como Infraestructura como bash history puede ser arrastrado por los oídos a Infraestructura como Código , pero cuando queremos hacer algo más complicado que el antiguo servidor LAMP, llegaremos a la conclusión de que este código necesita ser modificado, modificado, modificado de alguna manera . Además, nos gustaría considerar paralelos entre Infraestructura como Código y desarrollo de software.
SECO
En el proyecto de desarrollo de almacenamiento, había una subtarea para configurar periódicamente SDS : estamos lanzando una nueva versión: debe implementarse para realizar más pruebas. La tarea es extremadamente simple:
- ven aquí por ssh y ejecuta el comando.
- copia el archivo allí.
- Aquí hay un ajuste a la configuración.
- comenzar el servicio allí
- ...
- BENEFICIOS!
Bash es más que suficiente para la lógica descrita, especialmente en las primeras etapas de un proyecto cuando recién comienza. No está mal que uses bash , pero con el tiempo se te pedirá que implementes algo similar, pero ligeramente diferente. Lo primero que viene a la mente: copiar y pegar. Y ahora tenemos dos scripts muy similares que hacen casi lo mismo. Con el tiempo, el número de scripts ha crecido, y nos enfrentamos al hecho de que existe una cierta lógica comercial para implementar la instalación, que debe sincronizarse entre diferentes scripts, es bastante difícil.
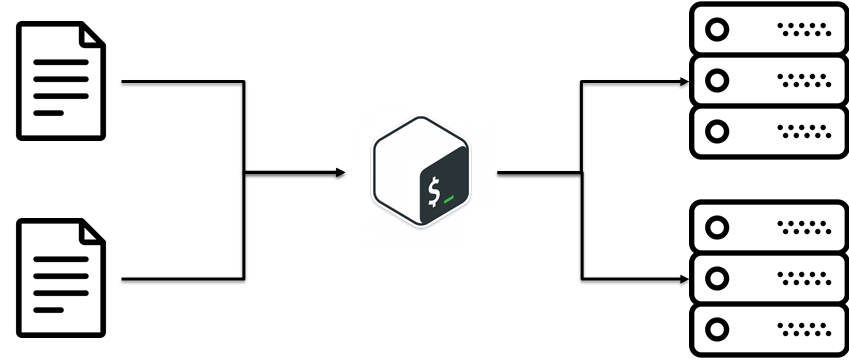
Resulta que hay una práctica SECA (No te repitas). La idea es reutilizar el código existente. Suena simple, pero no llegó a esto de inmediato. En nuestro caso, era una idea común: separar las configuraciones de los scripts. Es decir La lógica de negocios de cómo la instalación se implementa por separado, las configuraciones por separado.
SÓLIDO para CFM

Con el tiempo, el proyecto creció y una extensión natural fue la aparición de Ansible. La razón principal de su aparición es la presencia de experiencia en el equipo y que bash no está destinado a una lógica compleja. Ansible también comenzó a contener una lógica compleja. Para que la lógica compleja no se convierta en caos, existen principios para organizar el código SOLID en el desarrollo de software. Por ejemplo, Grigory Petrov en su informe "¿Por qué necesita una marca personal?" Planteó la pregunta de que una persona está diseñada de tal manera que es más fácil operar con algún tipo de entidades sociales, en el desarrollo de software estos son objetos. Si combina estas dos ideas y continúa desarrollándolas, notará que también puede usar SOLID en la descripción de la infraestructura para que sea más fácil mantener y modificar esta lógica en el futuro.
El principio de responsabilidad única

Cada clase realiza solo una tarea.
No es necesario mezclar código y hacer monstruos monolíticos de pasta divina. La infraestructura debe consistir en ladrillos simples. Resulta que si divide el libro de jugadas de Ansible en pequeñas piezas, lee los roles de Ansible, entonces son más fáciles de mantener.
Los principios abiertos y cerrados
El principio de apertura / cierre.
- Abierto para expansión: significa que el comportamiento de una entidad puede expandirse creando nuevos tipos de entidades.
- Cerrado por cambio: como resultado de expandir el comportamiento de una entidad, no se deben realizar cambios en el código que utiliza estas entidades.
Inicialmente, implementamos la infraestructura de prueba en máquinas virtuales, pero debido al hecho de que la lógica de implementación del negocio era independiente de la implementación, agregamos fácilmente un rollo a bare-metall.
El principio de sustitución de Liskov

El principio de sustitución de Barbara Liskov. los objetos en el programa deben ser reemplazables con instancias de sus subtipos sin cambiar la corrección del programa
Si observa de manera más amplia, no es una característica de ningún proyecto en particular que puede aplicar SOLID , generalmente se trata de CFM, por ejemplo, en otro proyecto que necesita implementar una aplicación Java en caja sobre varios Java, servidores de aplicaciones, bases de datos, SO, etc. Para este ejemplo, consideraré otros principios SÓLIDOS .
En nuestro caso, como parte del equipo de infraestructura, existe un acuerdo de que si instalamos el rol de imbjava u oraclejava, entonces tenemos un ejecutable binario de Java. Esto es necesario porque los roles superiores dependen de este comportamiento; esperan que Java esté presente. Al mismo tiempo, esto nos permite reemplazar una implementación / versión de java con otra sin cambiar la lógica de implementación de la aplicación.
El problema aquí radica en el hecho de que en Ansible es imposible implementar tales, como resultado, algunos acuerdos aparecen dentro del equipo.
El principio de segregación de interfaz
El principio de separación de interfaz “muchas interfaces diseñadas específicamente para clientes son mejores que una única interfaz de uso general.
Inicialmente, intentamos poner toda la variación en la implementación de la aplicación en un libro de jugadas Ansible, pero fue difícil de admitir, y el enfoque cuando tenemos una interfaz fuera (el cliente espera el puerto 443) se especifica, luego, para una implementación específica, puede construir la infraestructura a partir de ladrillos separados.
El principio de inversión de dependencia

El principio de inversión de dependencia. Los módulos de nivel superior no deben depender de los módulos de nivel inferior. Ambos tipos de módulos deberían depender de abstracciones. Las abstracciones no deberían depender de los detalles. Los detalles deben depender de las abstracciones.
Aquí el ejemplo se basará en antipatrón.
- Uno de los clientes tenía una nube privada.
- Dentro de la nube, pedimos máquinas virtuales.
- Pero en vista de las características de la nube, la implementación de la aplicación estaba vinculada a qué hipervisor estaba la VM.
Es decir lógica de implementación de aplicaciones de alto nivel, las dependencias fluyeron a los niveles inferiores del hipervisor, y esto significó problemas al reutilizar esta lógica. No hagas eso.
Interacción

La infraestructura como código no solo se trata del código, sino también de la relación entre el código y una persona, sobre las interacciones entre los desarrolladores de la infraestructura.
Factor de bus
Supongamos que tienes a Vasya en el proyecto. Vasya sabe todo sobre su infraestructura, ¿qué sucederá si Vasya desaparece repentinamente? Esta es una situación muy real, porque puede ser atropellada por un autobús. A veces esto sucede. Si esto sucede y el conocimiento sobre el código, su estructura, cómo funciona, las apariencias y las contraseñas no se distribuyen en el equipo, puede encontrar una serie de situaciones desagradables. Se pueden usar varios enfoques para minimizar estos riesgos y distribuir el conocimiento dentro del equipo.
Par devopsing

No es como una broma que los administradores bebieron cerveza, cambiaron las contraseñas, sino un análogo de la programación de pares. Es decir dos ingenieros se sientan en una computadora, un teclado y comienzan a configurar su infraestructura juntos: configurar el servidor, escribir el rol Ansible, etc. Suena bien, pero no funcionó para nosotros. Pero los casos especiales de esta práctica funcionaron. Llegó un nuevo empleado, su mentor toma una tarea real con él, trabaja, transfiere conocimiento.
Otro caso especial es una llamada de incidente. Durante el problema, un grupo de personas en servicio e involucradas se reúne, se nombra a un líder, que comparte su pantalla y expresa el tren del pensamiento. Otros participantes siguen el pensamiento del líder, espían trucos desde la consola, verifican que no hayan perdido una línea en el registro y aprenden cosas nuevas sobre el sistema. Este enfoque funcionó en lugar de no.
Revisión de código
Subjetivamente, de manera más eficiente, la difusión del conocimiento sobre la infraestructura y cómo se organizó se llevó a cabo mediante la revisión del código:
- La infraestructura se describe por código en el repositorio.
- Los cambios ocurren en una rama separada.
- Con una solicitud de fusión, puede ver el delta de cambios en la infraestructura.
Lo más destacado aquí fue que los revisores fueron seleccionados por turnos, de acuerdo con el cronograma, es decir, con cierta probabilidad subirás a una nueva pieza de infraestructura.
Estilo de código

Con el tiempo, las disputas comenzaron a aparecer durante la revisión, ya que los revisores tenían su propio estilo y la capacidad de rotación de los revisores los apilaron con diferentes estilos: 2 espacios o 4, camelCase o snake_case. Implementar esto no funcionó de inmediato.
- La primera idea fue recomendar el uso de linter, porque todos los mismos ingenieros, todos inteligentes. Pero diferentes editores, sistema operativo, no es conveniente
- Esto se convirtió en un bot, que para cada commit se comprometió con la problemática escrita en holgura y aplicó la salida de linter. Pero en la mayoría de los casos, se encontraron asuntos más importantes y el código no se solucionó.
Maestro de construcción verde
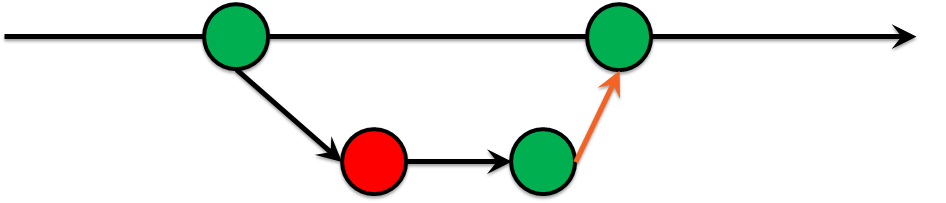
El tiempo pasa y llegamos a la conclusión de que no debe permitir confirmaciones que no pasen ciertas pruebas al maestro. Voila! inventamos el Green Build Master, que se ha practicado durante mucho tiempo en el desarrollo de software:
- El desarrollo está en una rama separada.
- Las pruebas se ejecutan en este hilo.
- Si las pruebas fallan, el código no entrará en el asistente.
Tomar esta decisión fue muy doloroso porque causó mucha controversia, pero valió la pena, porque Las solicitudes de fusiones comenzaron a llegar a la revisión sin desacuerdos en cuanto al estilo y con el tiempo, el número de áreas problemáticas comenzó a disminuir.
Prueba IaC

Además de la verificación de estilo, puede usar otras cosas, por ejemplo, para verificar que su infraestructura realmente se pueda implementar. O compruebe que los cambios en la infraestructura no provocarán una pérdida de dinero. ¿Por qué podría ser necesario? La pregunta es compleja y filosófica, es mejor responder con la historia de que de alguna manera hubo un autoescalador en Powershell que no verificó las condiciones límite => se crearon más máquinas virtuales de las necesarias => el cliente gastó más dinero de lo planeado. No es lo suficientemente agradable, pero sería bastante realista detectar este error en etapas anteriores.
Uno puede preguntar, ¿por qué hacer que la infraestructura compleja sea aún más difícil? Las pruebas para la infraestructura, así como para el código, no se tratan de simplificación, sino de saber cómo debería funcionar su infraestructura.
Pirámide de pruebas IaC

Prueba IaC: análisis estático
Si despliega de inmediato toda la infraestructura y verifica que funciona, puede resultar que toma mucho tiempo y requiere mucho tiempo. Por lo tanto, la base debe ser algo que funcione rápidamente, es mucho y cubre muchos lugares primitivos.
Bash es complicado
Aquí hay un ejemplo trivial. seleccione todos los archivos en el directorio actual y cópielos en otra ubicación. Lo primero que viene a la mente:
for i in * ; do cp $i /some/path/$i.bak done
Pero, ¿qué pasa si hay un espacio en el nombre del archivo? Bueno, de acuerdo, somos inteligentes, podemos usar comillas:
for i in * ; do cp "$i" "/some/path/$i.bak" ; done
Bien hecho? no! ¿Qué pasa si no hay nada en el directorio, es decir? Globbing no funcionará.
find . -type f -exec mv -v {} dst/{}.bak \;
Ahora bien hecho? no ... Olvidé que el nombre del archivo puede ser \n .
touch x mv x "$(printf "foo\nbar")" find . -type f -print0 | xargs -0 mv -t /path/to/target-dir
El problema del paso anterior podría detectarse cuando olvidamos las comillas, para esto en la naturaleza hay muchas herramientas de Shellcheck , hay muchas de ellas, y lo más probable es que pueda encontrar un revestimiento para su pila bajo su IDE.
Prueba IaC: Pruebas unitarias
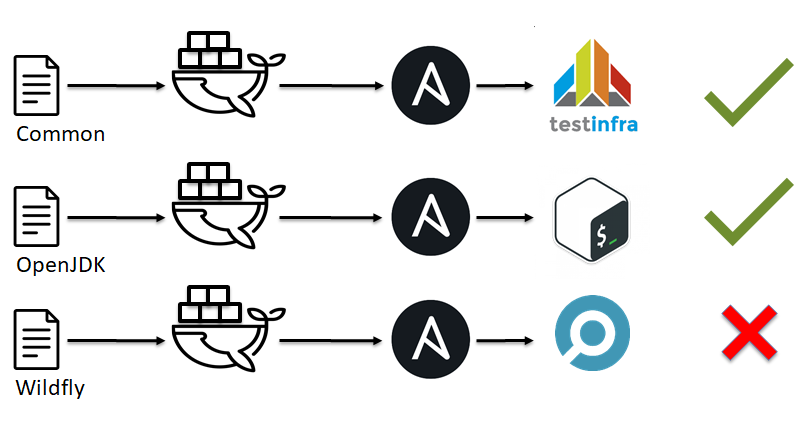
Como vimos en el ejemplo anterior, linter no es omnipotente y no puede señalar todas las áreas problemáticas. Además, por analogía con las pruebas en el desarrollo de software, podemos recordar pruebas unitarias. Entonces shunit , junit , rspec , pytest vienen inmediatamente a la mente. ¿Pero qué hacer con ansible, chef, saltstack y otros como ellos?
Al principio, hablamos de SOLID y del hecho de que nuestra infraestructura debería consistir en pequeños ladrillos. Su hora ha llegado.
- La infraestructura se tritura en pequeños ladrillos, por ejemplo, roles Ansible.
- Se está desarrollando algún tipo de entorno, ya sea Docker o VM.
- Aplicamos nuestro rol Ansible a este entorno de prueba.
- Verificamos que todo funcionó como esperamos (ejecutamos las pruebas).
- Decidimos ok o no ok.
La pregunta es, ¿qué son las pruebas para CFM? puede ejecutar el script cursi, o puede usar soluciones preparadas para esto:
Ejemplo para testinfra, verificamos que los usuarios test1 , test2 existen y están en el grupo sshusers :
def test_default_users(host): users = ['test1', 'test2' ] for login in users: assert host.user(login).exists assert 'sshusers' in host.user(login).groups
Que elegir La pregunta es compleja y ambigua, aquí hay un ejemplo de un cambio en los proyectos en github para 2018-2019:

Marcos de prueba de IaC
¿Hay cómo poner todo junto y correr? Puede tomar y hacer todo usted mismo si tiene un número suficiente de ingenieros. Y puede tomar soluciones preparadas, aunque no hay muchas:
Un ejemplo de cambio en proyectos en github para 2018-2019:

Molécula vs. Testkitchen

Inicialmente, intentamos usar testkitchen :
- Crear máquinas virtuales en paralelo.
- Aplicar Roles Ansibles.
- Alejar la inspección.
Para 25-35 roles, esto funcionó durante 40-70 minutos, que fue mucho tiempo.
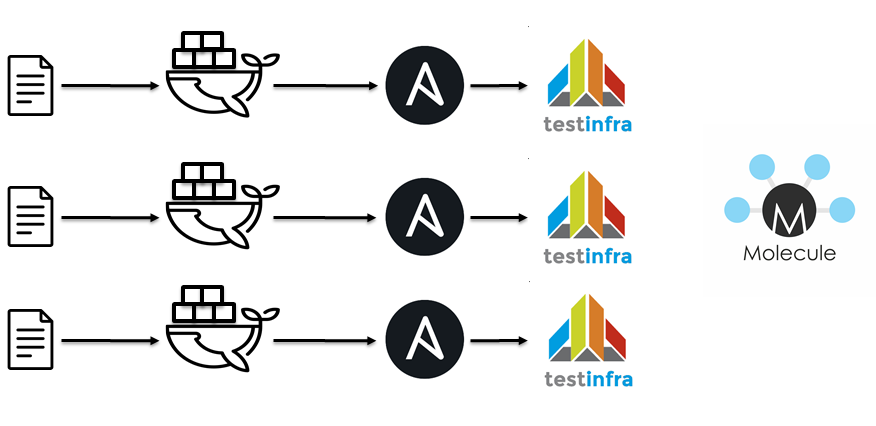
El siguiente paso fue cambiar a jenkins / docker / ansible / molécula. Idiológicamente, todo es igual
- Playbooks de pelusa.
- Derramar roles.
- Ejecutar contenedor
- Aplicar Roles Ansibles.
- Aleja a testinfra.
- Verifica la idempotencia.
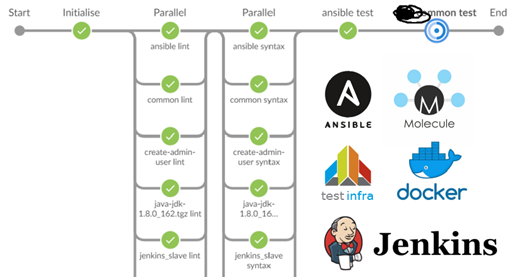
Una regla para 40 roles y pruebas para una docena comenzó a tomar unos 15 minutos.

Lo que debe elegir depende de muchos factores, como la pila utilizada, la experiencia en el equipo, etc. aquí todos deciden cómo cerrar el problema de las pruebas unitarias
Pruebas IaC: Pruebas de integración
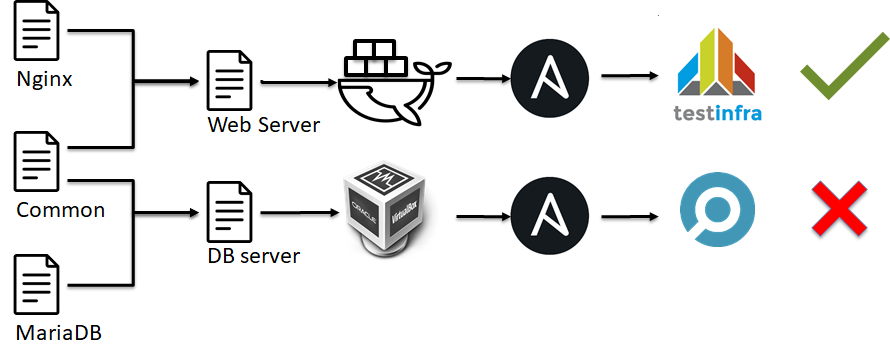
En la siguiente etapa de la pirámide de pruebas de infraestructura, aparecerán pruebas de integración. Son similares a las pruebas unitarias:
- La infraestructura se aplasta en pequeños ladrillos, como los roles de Ansible.
- Se está desarrollando algún tipo de entorno, ya sea Docker o VM.
- Hay muchos roles de Ansible aplicados a este entorno de prueba.
- Verificamos que todo funcionó como esperamos (ejecutamos las pruebas).
- Decidimos ok o no ok.
En términos generales, no verificamos la operabilidad de un elemento individual del sistema como en las pruebas unitarias, verificamos cómo se configura el servidor en su conjunto.
Pruebas IaC: pruebas de extremo a extremo
En la parte superior de la pirámide nos encontramos con las pruebas de extremo a extremo. Es decir no verificamos la operación de un servidor separado, un script separado, un ladrillo separado de nuestra infraestructura. Verificamos que muchos servidores estén combinados, nuestra infraestructura funciona como esperamos. Desafortunadamente, no vi ninguna solución de caja preparada, probablemente porque la infraestructura es a menudo única y difícil de crear y crea un marco para probarla. Como resultado, todos crean su propia solución. Hay demanda, pero no hay respuesta. Por lo tanto, les diré lo que hay para motivar a otros a sonar pensamientos o meterme la nariz, que todo fue inventado mucho antes que nosotros.
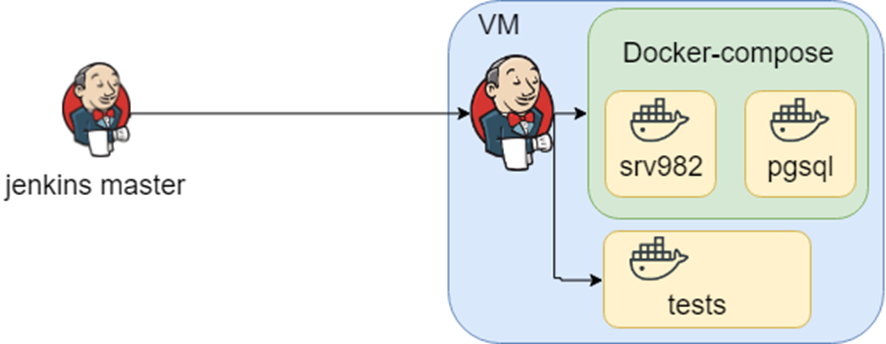
Un proyecto con una rica historia. Usado en grandes organizaciones y probablemente cada uno de ustedes se cruza indirectamente. La aplicación admite muchas bases de datos, integraciones, etc., etc. Saber cómo puede verse la infraestructura de esta manera es una gran cantidad de archivos compuestos por docker, y saber qué pruebas ejecutar en qué entorno es jenkins.
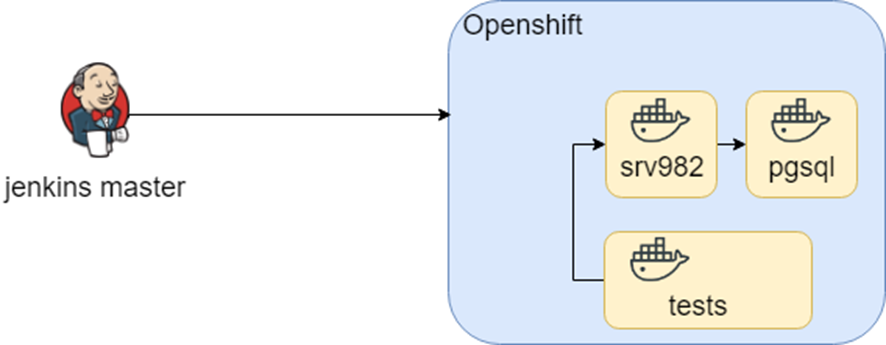
Este esquema funcionó durante mucho tiempo, hasta que, como parte del estudio , intentamos transferirlo a Openshift. Los contenedores se mantuvieron igual, pero el entorno de lanzamiento ha cambiado (hola DRY nuevamente).
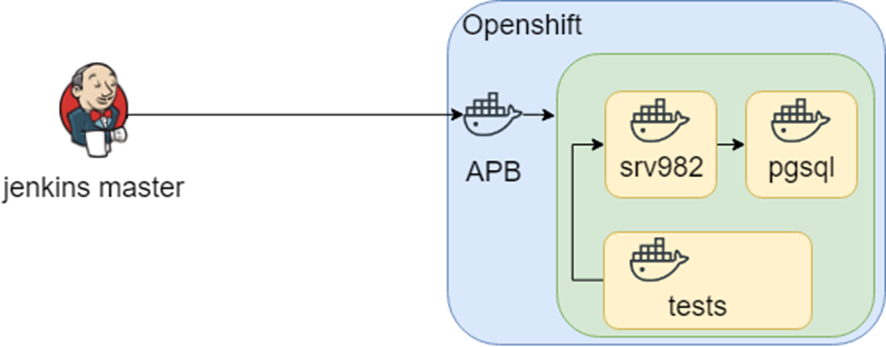
La idea de la investigación fue más allá, y en OpenShift existió tal cosa de APB (Ansible Playbook Bundle) que le permite acumular conocimiento en el contenedor sobre cómo implementar la infraestructura. Es decir Hay un punto de conocimiento reproducible y comprobable de cómo implementar la infraestructura.

Todo esto sonaba bien, hasta que nos enterramos en una infraestructura heterogénea: necesitábamos Windows para las pruebas. Como resultado, el conocimiento sobre dónde implementar y probar está en jenkins.
Conclusión
Infraestructura como Código es
- El código en el repositorio.
- La interacción de las personas.
- Pruebas de infraestructura.