En el
primer artículo de la serie, promoví activamente la idea de que el desarrollo de código para Redd es secundario, y el proyecto principal es primario. Redd es una herramienta auxiliar, por lo que dedicar mucho tiempo a ello es incorrecto. Es decir, el desarrollo para ello debería ir rápidamente. Pero esto no significa en absoluto que los programas resultantes no sean óptimos. En realidad, si no están optimizados en absoluto, entonces solo la potencia del equipo no será suficiente para implementar el sistema de prueba deseado. Por lo tanto, el proceso, como dije, debe ser rápido y fácil, pero el desarrollador siempre debe tener en cuenta algunos principios de optimización.
Se han publicado libros gruesos sobre optimización. Algunos de estos libros son útiles, algunos ya están desactualizados, ya que los principios descritos en ellos han migrado durante mucho tiempo a la etapa de optimización automática al crear código ... Pero hay algunas cosas que no tienen valor al desarrollar programas ordinarios para procesadores ordinarios, por lo que los libros típicos generalmente no describen . Ahora comenzaremos a considerarlos.
Introduccion
Hasta ahora, escribí sobre el principio de "un problema: un artículo". Y los artículos se obtuvieron en el formato de conferencias, afectando varios temas a la vez, unidos por un problema común. Pero algunos lectores dijeron que dichos artículos no podían leerse de una vez. Por lo tanto, ahora trataremos de hablar sobre un solo tema en un artículo. También es más fácil para mí escribir así. Veamos, de repente será más conveniente para todos.
Además, deleita a los misteriosos mineros. Si un artículo se publica por la mañana, entonces el primer inconveniente llega después de un período de tiempo durante el cual es imposible leer el texto completo. Alguien hace esto puramente desde el principio, ahorrando solo temas sobre UDB y balalaika. Si la publicación no fue en la mañana, sino en la tarde, entonces arroja un signo negativo con retraso. El segundo menos llega durante el día (y ese amigo, por cierto, también se salvó de temas sobre UDB y sobre balalaika). Habrá más artículos en el nuevo formato, lo que significa que habrá momentos más agradables para esta pareja (aunque, personalmente para mí, como autor, se vuelve triste e insultante por sus acciones).
Artículos anteriores de la serie:
- Desarrollo del "firmware" más simple para FPGAs instalados en Redd, y depuración utilizando la prueba de memoria como ejemplo.
- Desarrollo del "firmware" más simple para FPGAs instalados en Redd. Parte 2. Código del programa.
- Desarrollo de su propio núcleo para incrustar en un sistema de procesador basado en FPGA.
- Desarrollo de programas para el procesador central Redd sobre el ejemplo de acceso a la FPGA.
- Los primeros experimentos utilizando el protocolo de transmisión en el ejemplo de la conexión de la CPU y el procesador en el FPGA del complejo Redd.
- Merry Quartusel, o cómo el procesador ha llegado a tal vida.
Comportamiento misterioso de un sistema típico.
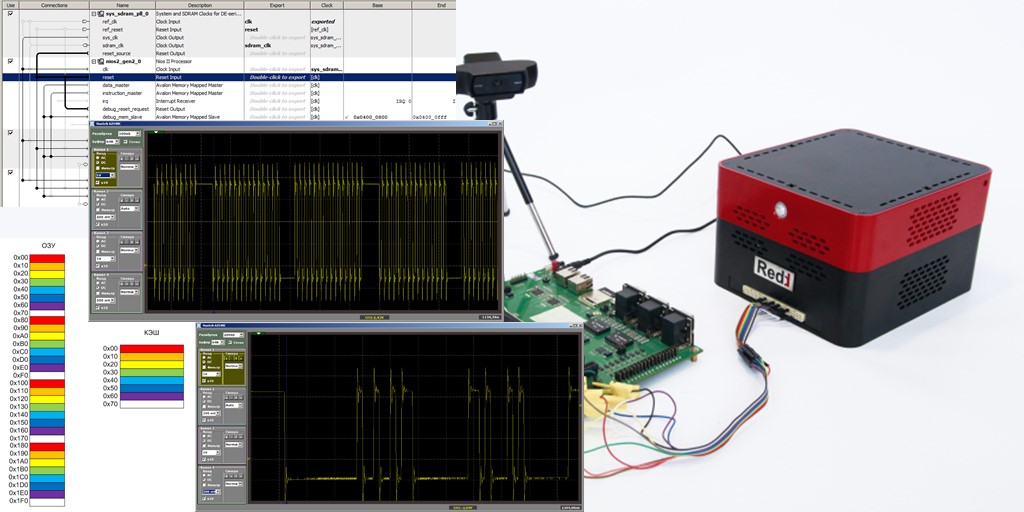
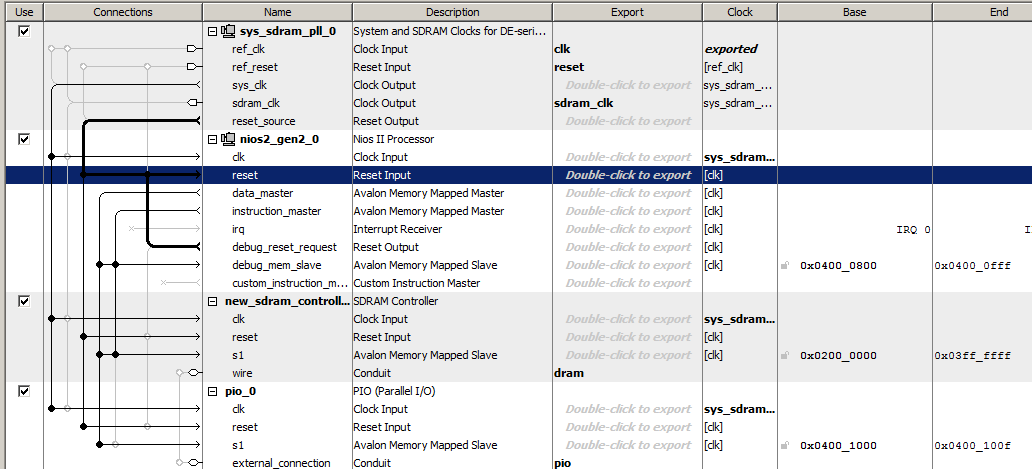
Hagamos el sistema de procesador más simple al incluir un reloj, un procesador Nios II / f, un controlador SDRAM y un puerto de salida. Así es como se ve este sistema Spartan en Platform Designer
El código del programa contendrá solo una función, cuyo cuerpo parece algo extraño, ya que contiene muchas líneas repetidas, pero esto nos será útil.
El código está oculto porque es demasiado estricto.extern "C" { #include "sys/alt_stdio.h" #include <system.h> #include <io.h> } void MagicFunction() { while (1) { IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); } } int main() { MagicFunction(); /* Event loop never exits. */ while (1); return 0; }
Pon un punto de interrupción en la última de las líneas:
IOWR (PIO_0_BASE,0,0);
en
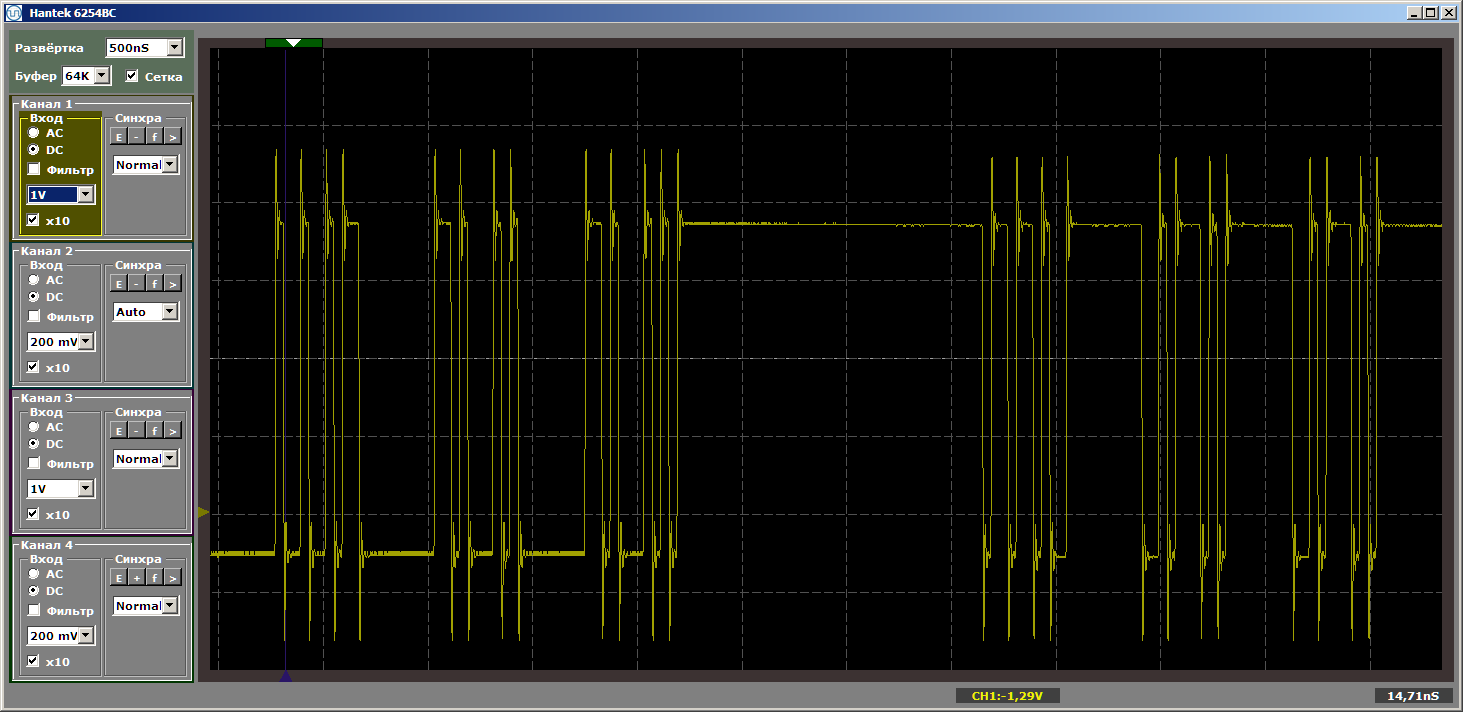
MagicFunction y ejecuta el programa. ¿Qué obtuvimos a la salida del puerto? Impulsos muy desiguales:
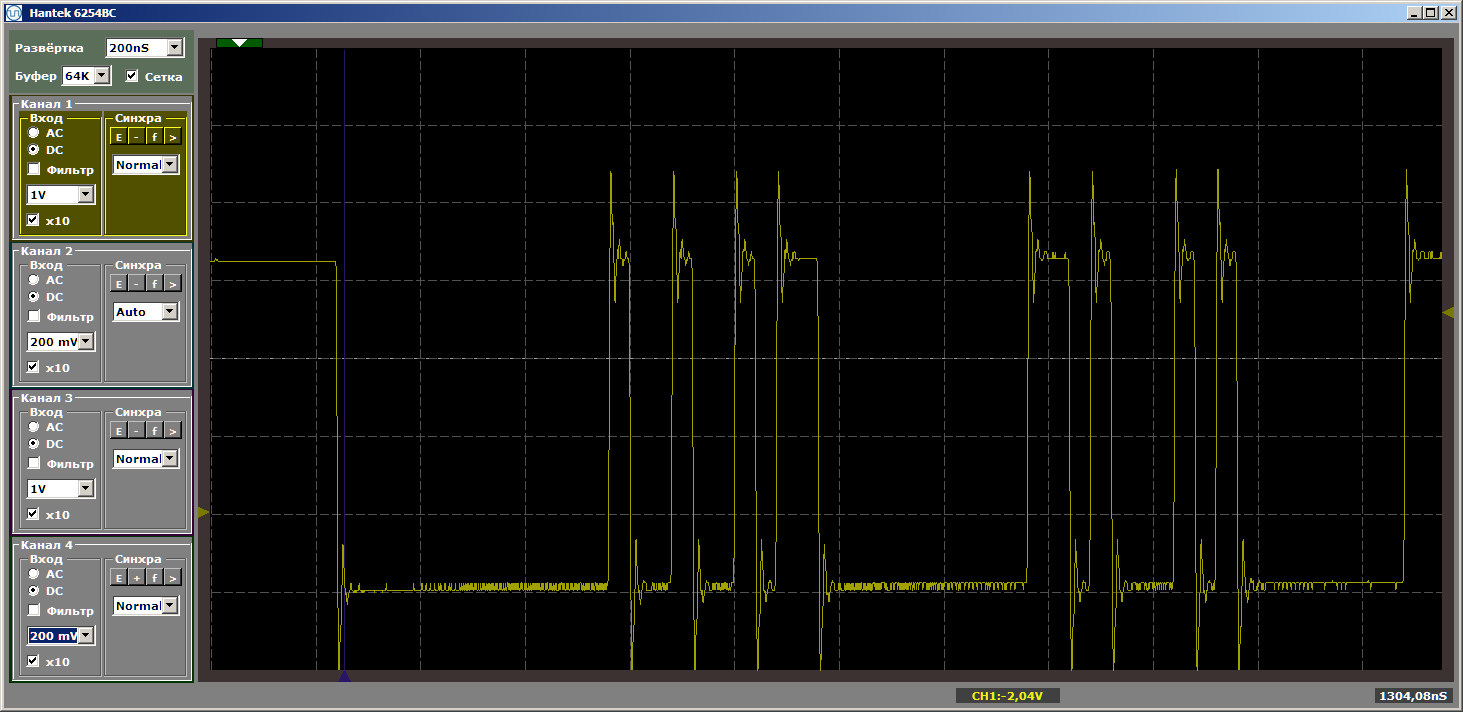
El horror Pues si. Sin embargo, haga clic en "iniciar" nuevamente para completar otra iteración del ciclo. Y ahora a la salida vemos un hermoso meandro suave:
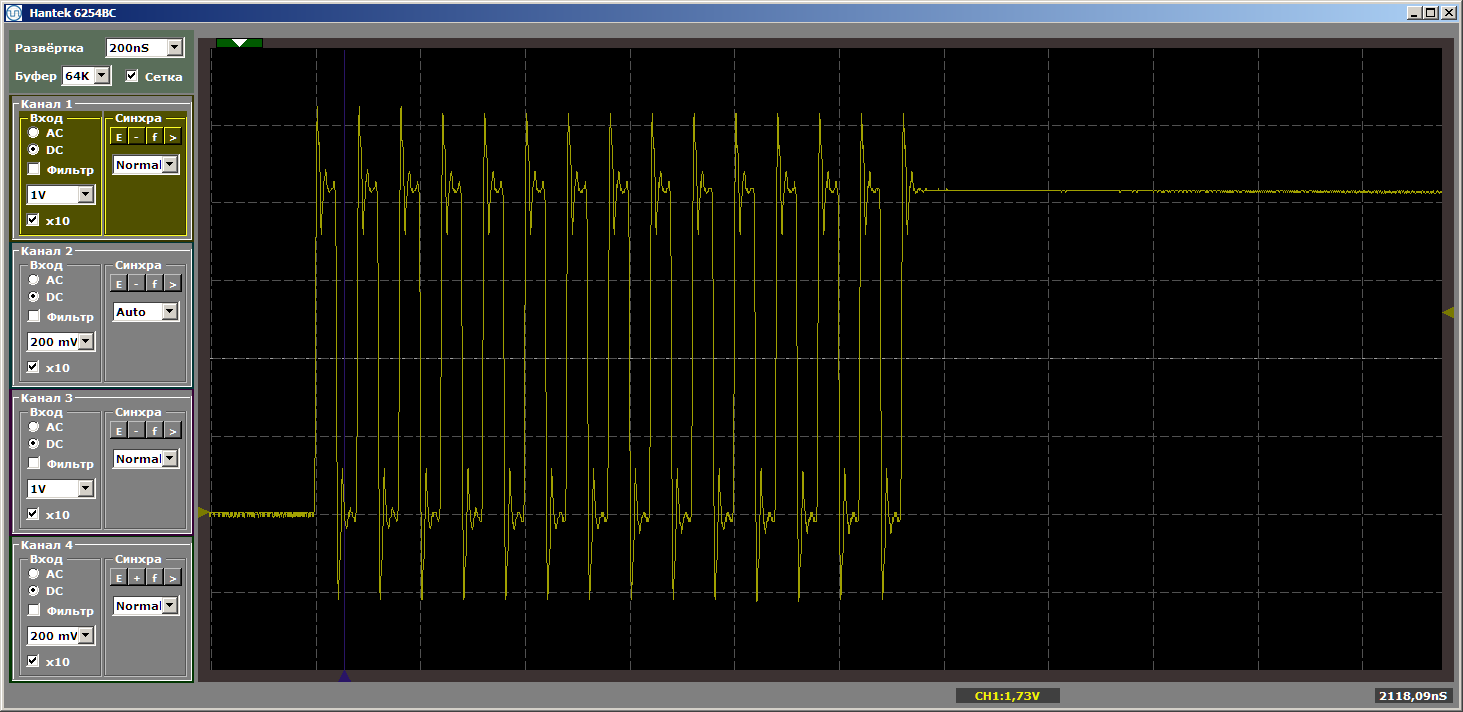
Otra iteración. Y uno más ... Meandro estable. Eliminamos el punto de interrupción y observamos el trabajo en dinámica: ya no hay tales interrupciones. Hay ráfagas interminables de pulsos.
¿Por qué tuvimos impulsos rotos en el primer pase? Un accidente? No Dejamos de depurar y lo iniciamos nuevamente. Y nuevamente tenemos impulsos desgarrados. Las brechas siempre surgen a la entrada del programa.
La pista está en el caché
En realidad, la solución a este comportamiento radica en el caché. Nuestro programa está almacenado en SDRAM. Obtener código de SDRAM no es rápido. Es necesario dar un comando de lectura, es necesario dar una dirección, y la dirección consta de dos partes. Tienes que esperar un poco. Solo entonces el microcircuito dará los datos. Para evitar tales demoras cada vez, el microcircuito puede emitir no una, sino varias palabras consecutivas. No consideraremos los gráficos de tiempo hoy, lo pospondremos para los siguientes artículos.
Bueno, en el lado del núcleo del procesador, se creó un caché de forma predeterminada. Aquí están sus configuraciones:
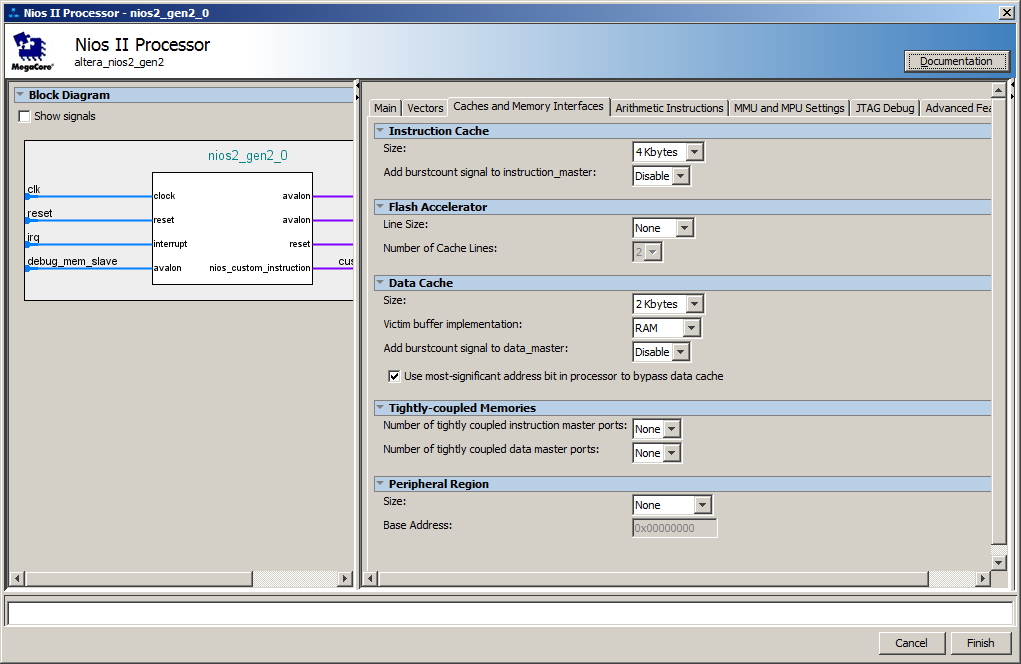
En realidad, los retrasos ocurren en el momento en que se está cargando por lotes las instrucciones de SDRAM a la caché. En las próximas iteraciones, el código ya está en la memoria caché, por lo que ya no es necesario cargarlo.
El oscilograma muestra un promedio de 8 entradas por puerto (una unidad se escribe 4 veces y cero se escribe 4 veces) por operación de carga. Un registro: un comando de ensamblador, que se puede encontrar eligiendo el elemento del menú Ventana-> Mostrar vista-> Otro:
y luego Depuración-> Desmontaje:
Aquí están nuestras cadenas y el código de ensamblaje correspondiente:
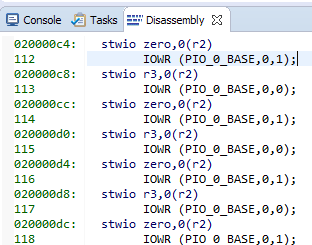
8 equipos de 4 bytes cada uno. Obtenemos 32 bytes por línea de caché ... Miramos nuestro archivo de ayuda favorito C: \ Work \ CachePlay \ software \ CachePlay_bsp \ system.h y vemos:
#define ALT_CPU_ICACHE_LINE_SIZE 32 #define ALT_CPU_ICACHE_LINE_SIZE_LOG2 5
Los datos prácticamente calculados coincidieron con la teoría. Además, de la documentación se deduce que el tamaño de la cadena no se puede cambiar. Siempre es igual a treinta y dos bytes.
Un experimento un poco más complicado
Intentemos provocar un caché para reiniciar durante el trabajo establecido. Cambiemos un poco el programa de prueba. Hacemos dos funciones y las llamamos desde la función
main () , colocando un bucle en ella. No estableceré un punto de interrupción. Por cierto, si hace que las funciones sean completamente idénticas, el optimizador lo notará y eliminará una de ellas, por lo que al menos una línea, y deberían diferir ... Esto es lo que escribí al principio: los optimizadores son muy inteligentes ahora.
Código de programa de prueba modificado. extern "C" { #include "sys/alt_stdio.h" #include <system.h> #include <io.h> } void MagicFunction1() { IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); } void MagicFunction2() { IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); } int main() { while (1) { MagicFunction1(); MagicFunction2(); } /* Event loop never exits. */ while (1); return 0; }
Obtenemos un resultado bastante hermoso, filmado ya en el modo establecido del programa.
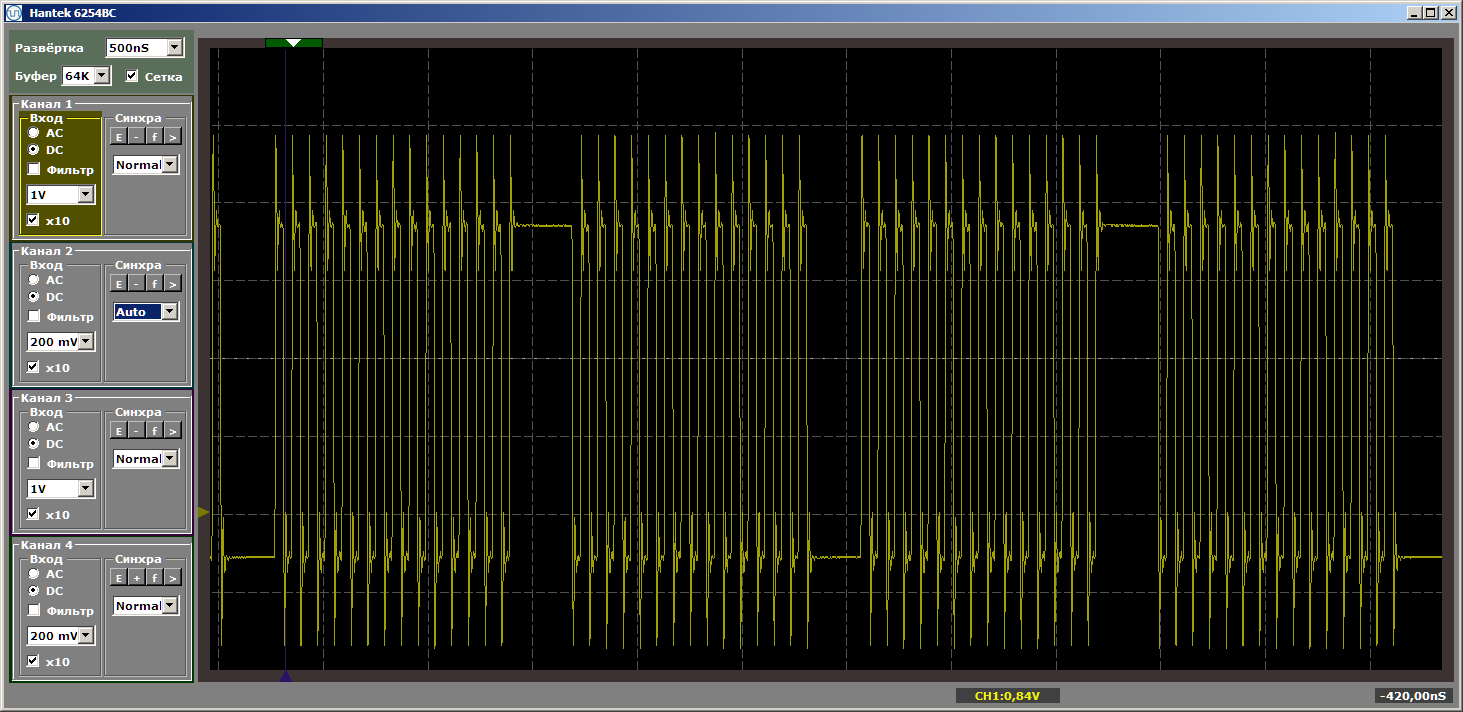
Y ahora colocaremos alguna función nueva entre este par de funciones, y no la llamaremos, solo se colocará entre ellas en la memoria. Ahora intentaré hacer que ocupe más espacio ... El tamaño del caché es de 4 kilobytes, por lo que lo haremos igual a cuatro kilobytes ... Simplemente inserte 1024 NOP, cada uno de los cuales tiene un tamaño de 4 bytes. Mostraré el final de la primera función, la nueva función y el comienzo de la segunda, para que quede claro cómo cambia el programa:
... IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); } #define Nops4 __asm__ volatile ("nop");__asm__ volatile ("nop");__asm__ volatile ("nop");__asm__ volatile ("nop"); #define Nops16 Nops4 Nops4 Nops4 Nops4 #define Nops64 Nops16 Nops16 Nops16 Nops16 #define Nops256 Nops64 Nops64 Nops64 Nops64 #define Nops1024 Nops256 Nops256 Nops256 Nops256 volatile void FuncBetween() { Nops1024 } void MagicFunction2() { IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); ...
La lógica del programa no ha cambiado, pero cuando se ejecuta ahora tenemos pulsos rotos
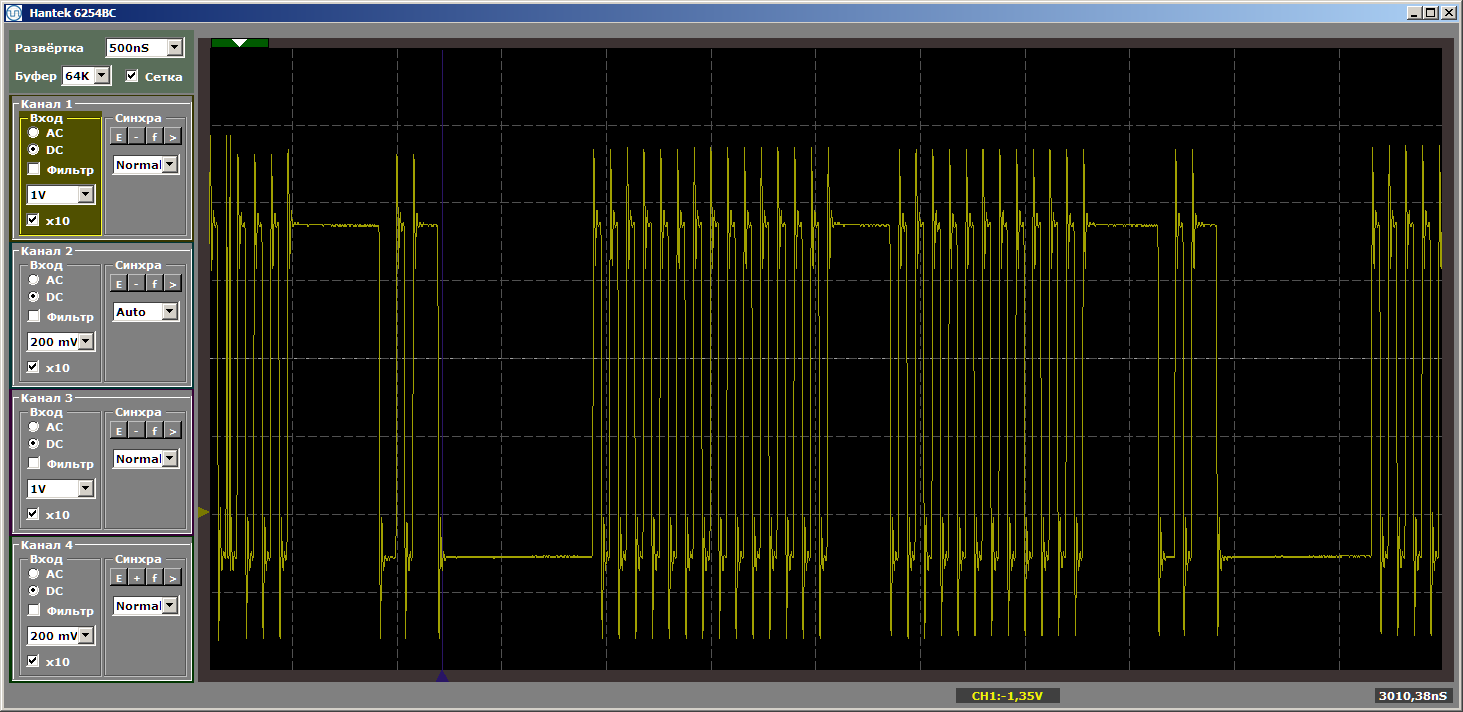
Haré una pregunta ingenua: salimos volando del caché y ahora, a medida que se amplía la brecha, ¿siempre habrá carga? ¡Para nada! Cambie el tamaño de la función "mala", haciéndola igual a, digamos, cinco kilobytes. Cinco más que cuatro, ¿seguimos volando? O no? Reemplace el inserto con esto:
volatile void FuncBetween() { Nops1024 Nops256 }
Y de nuevo obtenemos la belleza:
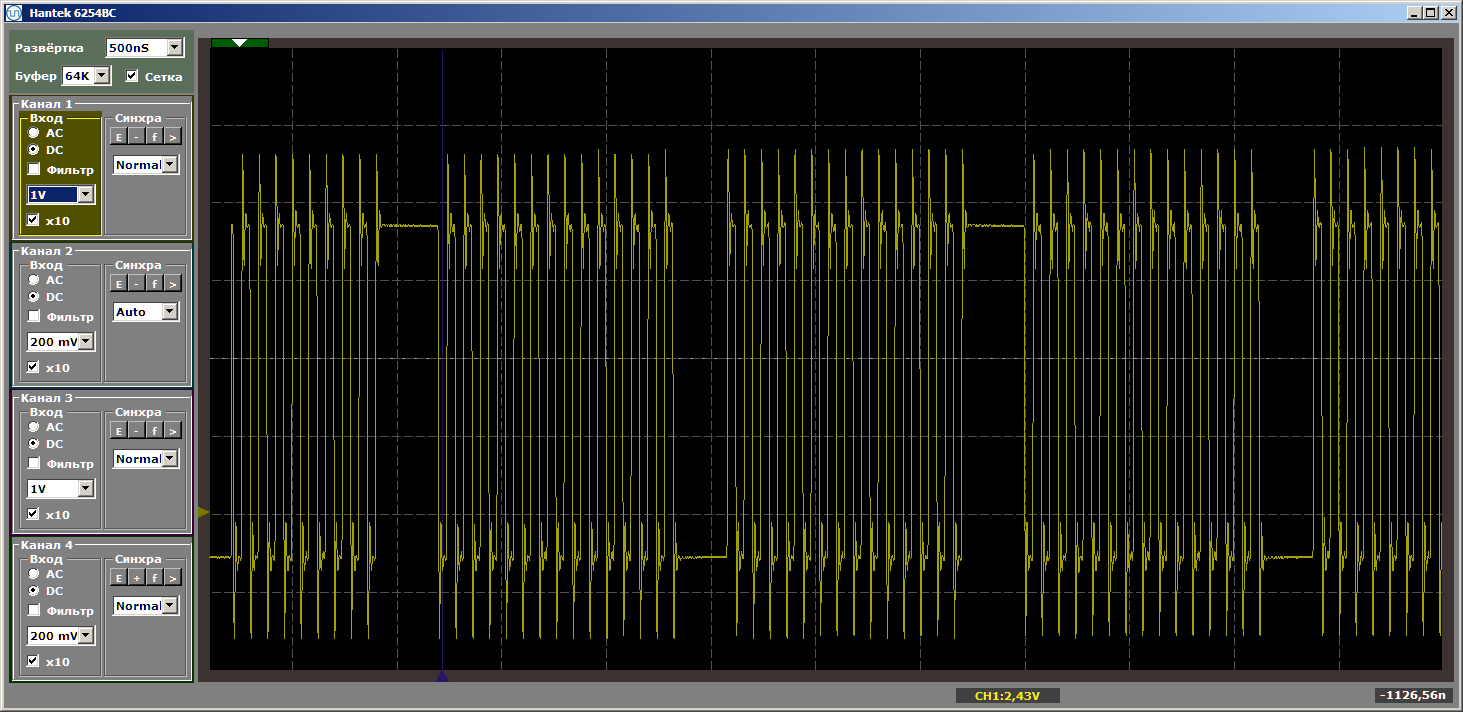
Entonces, ¿qué determina la necesidad de cargar código en el caché? ¿Podemos predecir algo, o cada vez que necesitamos mirar el hecho? Profundicemos en la teoría, con la que nos ayuda la
Guía de referencia del procesador Nios II .
Poco de teoría
Así es como se divide el campo de dirección en el procesador:
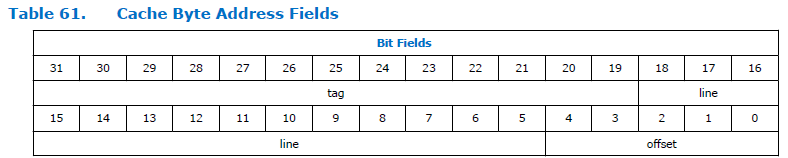
Como puede ver, la dirección se divide en tres partes. Etiqueta, línea y offset. La dimensión del campo de desplazamiento es constante para el procesador Nios II y siempre es de cinco bits, es decir, puede direccionar 32 bytes. La dimensión del campo "línea" depende del tamaño de la memoria caché especificada al configurar el procesador. En la figura anterior, es bastante grande. No sé por qué el documento tiene una dimensión tan grande. Tenemos un tamaño de caché de 4 kilobytes, lo que significa que la profundidad total de bits y el desplazamiento son de 12 bits. 5 bits toman un desplazamiento, para una línea queda 12-5 = 7 bits.
Obtenemos una cierta tabla de 128 filas, cada una de 32 bytes de longitud. Daré, digamos, las primeras 6 líneas:
Y entonces recurrimos a la dirección 0x123
004 . Si descarta la parte "no importante", el par "línea + desplazamiento" es 0x004. Este es el rango de fila cero. Los datos se cargarán en esta línea. Y el trabajo adicional con datos del rango 0x123
000 a 0x123
01F funcionará a través de la memoria caché. ¿En qué condiciones se sobrecargará la cadena? Al acceder a cualquier otra dirección que termine en el rango de 0x000 a 0x01F. Bueno, es decir, si recurrimos a la dirección 0xABC
204 , todo permanecerá en su lugar, porque el rango de direcciones más bajas no se superpone con el nuestro. Y 0xABC
804 no arruinará nada. Pero al ejecutar el código desde la dirección 0xABC
004, se cargarán nuevos contenidos en la línea de caché. Y ya la transición a la dirección 0x123
004 nuevamente conducirá a una sobrecarga. Si salta constantemente entre 0xABC
004 y 0x123
004 , se producirá una sobrecarga continua.
Tratemos de representar esto en forma de una imagen. Supongamos que solo tenemos 8 líneas en el caché, es más conveniente colorearlas en diferentes colores. Haré que el tamaño de línea sea 0x10, es más conveniente pintar las direcciones en la imagen (recuerde que en Nios II real el tamaño de línea siempre es 0x20 bytes). La memoria late en páginas condicionales que son del mismo tamaño que las líneas de caché. La página roja de la memoria siempre irá a la línea roja de la memoria caché, de naranja a naranja, y así sucesivamente. En consecuencia, los contenidos antiguos se descargarán.

Bueno, en realidad, el comportamiento del programa durante el experimento ahora está claro. Cuando las funciones se separaron estrictamente por 4 kilobytes, llegaron a páginas de colores similares. Por lo tanto el código
while (1) { MagicFunction1(); MagicFunction2(); }
condujo a la carga de la memoria caché por el bien de uno, luego por otra función. Y cuando el espacio no era 4, sino 5 kilobytes, las funciones se espaciaban en bloques de diferentes colores. No hubo conflicto, todo funcionó sin demora.
Conclusiones
Cuando leí hace muchos años que hay líneas de núcleos Cortex A, Cortex R y Cortex M diseñados para cosas productivas, para trabajar en tiempo real y para trabajar en sistemas baratos, respectivamente, al principio no entendí, pero cuál es, de hecho, la diferencia . No, los sistemas baratos son comprensibles, pero los dos primeros son ¿cuáles son las diferencias? Sin embargo, después de jugar el núcleo Cortex A9 disponible en el FPGA Cyclone V SoC, sentí todos los inconvenientes del caché cuando trabajaba con hierro. Hay muchos cachés en el núcleo de Cortex A ... Y la previsibilidad del comportamiento del sistema es casi nula. Pero el caché mejora el rendimiento. A veces es mejor si todo funciona no predeciblemente preciso al ritmo, pero rápido que previsiblemente lento. Esto es especialmente cierto para la informática o, por ejemplo, para mostrar gráficos.
Pero el problema principal no es que surjan las cosas descritas en el artículo, sino que el comportamiento del sistema cambiará de un ensamblaje a otro, ya que nadie sabe en qué direcciones caerá la función después de agregar o eliminar código. Hace 15 años, en el proyecto del emulador de consola de juegos Sega para un decodificador de televisión por cable, tuvimos que hacer un preprocesador completo que, después de cada edición, moviera las funciones que emulaban los comandos del ensamblador de Motorola en el núcleo SPARC-8 para que su tiempo de ejecución fuera siempre el mismo (allí debido a la caché, de lo contrario todo nadó mucho).
Pero, ¿cuándo necesitamos previsibilidad? Por supuesto, al crear diagramas de tiempo mediante programación (recuerde que, en general, en los FPGA también es posible confiar esto al hardware, pero hay algunos detalles con un desarrollo rápido). Pero cuando se trabaja con algoritmos computacionales, no es tan importante. A menos que el algoritmo sea complejo, debe asegurarse de que las secciones críticas no causen una sobrecarga constante de caché. En la mayoría de los casos, el caché no crea problemas y aumenta la productividad.
En el próximo artículo, veremos cómo predecir funciones críticas en la memoria no almacenable en caché, que siempre se ejecuta a la velocidad máxima, y discutiremos las ventajas implícitas de los FPGA sobre los sistemas estándar que surgen de las tecnologías utilizadas en este proceso.
Para los mas atentos
Un lector corrosivo puede preguntar: "¿Por qué el oscilograma no se rasgó lo suficiente al insertar cuatro kilobytes de código?" Todo es simple Si inserta exactamente 4 kilobytes, obtenemos las siguientes direcciones para colocar funciones en la memoria:
MagicFunction1(): 0200006c: movhi r2,1024 02000070: movi r4,1 02000074: addi r2,r2,4096 02000078: stwio r4,0(r2) 92 IOWR (PIO_0_BASE,0,0); 0200007c: mov r3,zero 02000080: stwio r3,0(r2) 93 IOWR (PIO_0_BASE,0,1); ... 120 IOWR (PIO_0_BASE,0,0); 020000f0: stwio r3,0(r2) 020000f4: ret 131 Nops1024 FuncBetween(): 020000f8: nop 020000fc: nop 02000100: nop 02000104: nop ... 020010ec: nop 020010f0: nop 020010f4: nop 020010f8: ret 135 IOWR (PIO_0_BASE,0,0); MagicFunction2(): 020010fc: movhi r2,1024 02001100: mov r4,zero 02001104: addi r2,r2,4096
Para una forma de onda idealmente mala, debe insertar NOP para que 4 kilobytes sea su volumen junto con la longitud de la función
MagicFunction1 () . No importa lo que vaya para una hermosa foto! Cambie la inserción a esto:
volatile void FuncBetween() { Nops256 Nops256 Nops256 Nops64 Nops64 Nops64 Nops16 Nops16 }
Una y otra vez presto atención a que el inserto no recibe control. Simplemente cambia la posición de las funciones en la memoria entre sí. Con este inserto, obtenemos el terrible horror deseado:
Me pareció que esos detalles insertados en el texto principal distraerían a todos del texto principal, así que los puse en una posdata.