¡Saludo, Khabrovites! Felicitaciones a todos en el día del programador y comparta la traducción del artículo, que fue especialmente preparado para los estudiantes del curso "Arquitecto de alta carga" . "Fragmentos. O no lo rompas. Sin intentarlo ".
"Fragmentos. O no lo rompas. Sin intentarlo ".
- YodaHoy nos sumergiremos en la separación de datos entre varios servidores MySQL. Terminamos de fragmentar a principios de 2012, y este sistema todavía se usa para almacenar nuestros datos básicos.
Antes de discutir cómo compartir datos, vamos a conocerlos mejor. Enciende una luz agradable, consigue fresas con chocolate, recuerda las citas de Star Trek ...
Pinterest es un motor de búsqueda para todo lo que te interesa. En términos de datos, Pinterest es el gráfico más grande de intereses humanos en todo el mundo. Contiene más de 50 mil millones de pines que los usuarios han guardado en más de mil millones de tableros. Las personas guardan algunos pines para sí mismos y, al igual que otros pines, se suscriben a otros pines, tableros e intereses, ven el feed de inicio de todos los pines, tableros e intereses a los que están suscritos. Genial ¡Ahora hagámoslo escalable!
Crecimiento doloroso
En 2011, comenzamos a ganar impulso. Según algunas
estimaciones , crecimos más rápido que cualquier startup conocida en ese momento. Alrededor de septiembre de 2011, todos los componentes de nuestra infraestructura se sobrecargaron. Teníamos varias tecnologías NoSQL a nuestra disposición, y todas fallaron catastróficamente. También teníamos muchos esclavos MySQL, que solíamos leer, lo que causaba muchos errores extraordinarios, especialmente al almacenar en caché. Reconstruimos todo nuestro modelo de almacenamiento. Para trabajar de manera eficiente, nos acercamos cuidadosamente al desarrollo de requisitos.
Requisitos
- Todo el sistema debe ser muy estable, fácil de usar y escalar desde el tamaño de una caja pequeña hasta el tamaño de la luna a medida que el sitio crece.
- Todo el contenido generado por el marcador debe estar disponible en el sitio en cualquier momento.
- El sistema debe admitir la solicitud de N pines en el tablero en un orden determinista (por ejemplo, en el orden inverso del tiempo de creación o en el orden especificado por el usuario). Lo mismo es para pinners, pin, etc.
- Para simplificar, debe buscar actualizaciones de todas las formas posibles. Para obtener la consistencia necesaria, se necesitarán juguetes adicionales, como un diario de transacciones distribuidas. ¡Es divertido y (no demasiado) fácil!
Filosofía de la arquitectura y notas
Debido a que queríamos que estos datos abarcasen múltiples bases de datos, no podríamos usar solo una combinación, claves externas e índices para recopilar todos los datos, aunque pueden usarse para subconsultas que no abarcan la base de datos.
También necesitábamos mantener el equilibrio de carga en los datos. Decidimos que mover datos, elemento por elemento, haría que el sistema fuera innecesariamente complejo y causaría muchos errores. Si necesitáramos mover datos, era mejor mover todo el nodo virtual a otro nodo físico.
Para que nuestra implementación entre rápidamente en circulación, necesitábamos la solución más simple y conveniente y nodos muy estables en nuestra plataforma de datos distribuidos.
Todos los datos tuvieron que replicarse en la máquina esclava para crear una copia de seguridad, con alta disponibilidad y volcado a S3 para MapReduce. Interactuamos con master solo en producción. En producción, no querrá escribir ni leer en esclavo. Retraso esclavo, y causa errores extraños. Si se realiza el fragmentación, no tiene sentido interactuar con un esclavo en la producción.
Finalmente, necesitamos una buena forma de generar identificadores únicos universales (UUID) para todos nuestros objetos.
Cómo hicimos sharding
Lo que íbamos a crear, tenía que cumplir con los requisitos, trabajar de manera estable, en general, ser viable y mantenible. Es por eso que hemos elegido la
tecnología MySQL ya bastante madura como la tecnología subyacente. Intentamos desconfiar de las nuevas tecnologías para el escalado automático de MongoDB, Cassandra y Membase, porque estaban lo suficientemente lejos de la madurez (¡y en nuestro caso se rompieron de manera impresionante!)
Además: todavía recomiendo startups para evitar nuevas cosas extrañas, solo trate de usar MySQL. Confía en mi Puedo probarlo con cicatrices.
MySQL: la tecnología está probada, es estable y simple: funciona. No solo lo usamos, es popular en otras compañías con escalas aún más impresionantes. MySQL satisface plenamente nuestra necesidad de optimizar las consultas de datos, seleccionando rangos de datos específicos y transacciones a nivel de fila. De hecho, en su arsenal hay muchas más oportunidades, pero no todas las necesitamos. Pero MySQL es una solución "en caja", por lo que los datos tuvieron que ser fragmentados. Aquí está nuestra solución:
Comenzamos con ocho servidores EC2, una instancia de MySQL en cada uno:
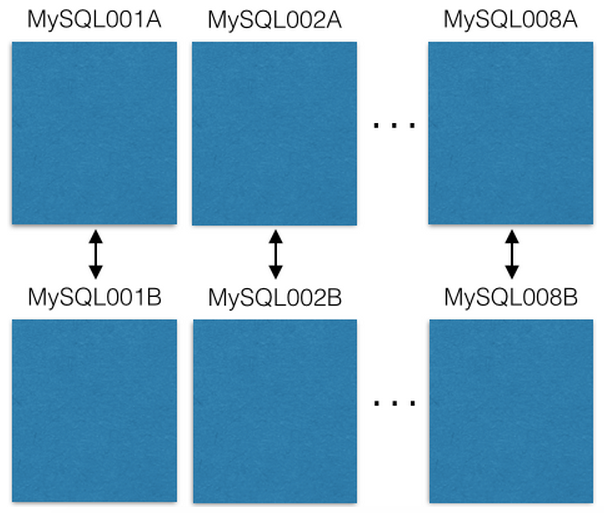
Cada servidor maestro-maestro MySQL se replica al host de respaldo en caso de una falla primaria. Nuestros servidores de producción solo leen o escriben en master. Te recomiendo que también lo hagas. Esto simplifica enormemente y evita errores con retrasos en la replicación.
Cada entidad MySQL tiene muchas bases de datos:

Tenga en cuenta que cada base de datos tiene un nombre exclusivo: db00000, db00001 a dbNNNNN. Cada base de datos es un fragmento de nuestros datos. Tomamos una decisión arquitectónica, sobre la base de la cual solo una parte de los datos cae en el fragmento, y nunca va más allá de este fragmento. Sin embargo, puede obtener más capacidad moviendo fragmentos a otras máquinas (hablaremos de eso más adelante).
Trabajamos con una tabla de configuración que indica qué máquinas tienen fragmentos:
[{“range”: (0,511), “master”: “MySQL001A”, “slave”: “MySQL001B”}, {“range”: (512, 1023), “master”: “MySQL002A”, “slave”: “MySQL002B”}, ... {“range”: (3584, 4095), “master”: “MySQL008A”, “slave”: “MySQL008B”}]
Esta configuración solo cambia cuando necesitamos mover fragmentos o reemplazar el host. Si el
master muere, podemos usar el
slave existente y luego elegir uno nuevo. La configuración se encuentra en
ZooKeeper y, cuando se actualiza, se envía a los servicios que sirven al fragmento de MySQL.
Cada fragmento tiene el mismo conjunto de tablas:
pins ,
boards ,
users_has_pins ,
users_likes_pins ,
pin_liked_by_user , etc. Hablaré de esto un poco más tarde.
¿Cómo distribuimos los datos para estos fragmentos?
Creamos una ID de 64 bits que contiene la ID del fragmento, el tipo de datos que contiene y el lugar donde se encuentran estos datos en la tabla (ID local). La identificación del fragmento consta de 16 bits, la identificación del tipo es de 10 bits y la identificación local es de 36 bits. Los matemáticos avanzados notarán que solo hay 62 bits. Mi experiencia pasada como compilador y desarrollador de placas de circuitos me ha enseñado que los bits de respaldo valen su peso en oro. Entonces, tenemos dos de esos bits (establecidos en cero).
ID = (shard ID << 46) | (type ID << 36) | (local ID<<0)
Tomemos este pin:
https://www.pinterest.com/pin/241294492511762325/ , analicemos su ID 241294492511762325:
Shard ID = (241294492511762325 >> 46) & 0xFFFF = 3429 Type ID = (241294492511762325 >> 36) & 0x3FF = 1 Local ID = (241294492511762325 >> 0) & 0xFFFFFFFFF = 7075733
Por lo tanto, el objeto pin vive en el fragmento 3429. Su tipo es "1" (es decir, "Pin"), y está en la línea 7075733 en la tabla de pin. Por ejemplo, imaginemos que este fragmento está en MySQL012A. Podemos llegar a esto de la siguiente manera:
conn = MySQLdb.connect(host=”MySQL012A”) conn.execute(“SELECT data FROM db03429.pins where local_id=7075733”)
Hay dos tipos de datos: objetos y asignaciones. Los objetos contienen partes, como datos de pin.
Tablas de objetos
Las tablas de objetos como Pines, usuarios, tableros y comentarios tienen una ID (ID local, con una clave primaria que aumenta automáticamente) y un blob que contiene JSON con todos los datos del objeto.
CREATE TABLE pins ( local_id INT PRIMARY KEY AUTO_INCREMENT, data TEXT, ts TIMESTAMP DEFAULT CURRENT_TIMESTAMP ) ENGINE=InnoDB;
Por ejemplo, los objetos pin se ven así:
{“details”: “New Star Wars character”, “link”: “http://webpage.com/asdf”, “user_id”: 241294629943640797, “board_id”: 241294561224164665, …}
Para crear un nuevo pin, recopilamos todos los datos y creamos un blob JSON. Luego seleccionamos la ID de fragmento (preferimos elegir la misma ID de fragmento que el tablero en el que se coloca, pero esto no es necesario). Para el tipo de pin 1. Nos conectamos a esta base de datos e insertamos JSON en la tabla de pin. MySQL devolverá una identificación local aumentada automáticamente. ¡Ahora tenemos un fragmento, un tipo y una nueva ID local, por lo que podemos compilar un identificador completo de 64 bits!
Para editar el pin, leemos, modificamos y escribimos JSON usando la
transacción MySQL :
> BEGIN > SELECT blob FROM db03429.pins WHERE local_id=7075733 FOR UPDATE [Modify the json blob] > UPDATE db03429.pins SET blob='<modified blob>' WHERE local_id=7075733 > COMMIT
Para eliminar un pin, puede eliminar su fila en MySQL. Sin embargo, es mejor agregar el campo
"activo" en JSON y establecerlo en
"falso" , así como filtrar los resultados en el lado del cliente.
Tablas de mapeo
La tabla de mapeo vincula un objeto a otro, por ejemplo, un tablero con alfileres. La tabla MySQL para mapeos contiene tres columnas: 64 bits para la ID "de", 64 bits para la ID "donde" y la ID de secuencia. En este triple (de dónde, dónde, secuencia) hay claves de índice, y están en el fragmento del identificador "from".
CREATE TABLE board_has_pins ( board_id INT, pin_id INT, sequence INT, INDEX(board_id, pin_id, sequence) ) ENGINE=InnoDB;
Las tablas de mapeo son unidireccionales, por ejemplo, como la tabla
board_has_pins . Si necesita la dirección opuesta, necesitará una tabla
pin_owned_by_board separada. La ID de secuencia define la secuencia (nuestras ID no se pueden comparar entre fragmentos, porque las nuevas ID locales son diferentes). Por lo general, insertamos nuevos pines en una nueva placa con una ID de secuencia igual al tiempo en unix (marca de tiempo de unix). Cualquier número puede estar en la secuencia, pero el tiempo unix es una buena manera de almacenar nuevos materiales de forma secuencial, ya que este indicador aumenta de forma monótona. Puede echar un vistazo a los datos en la tabla de mapeo:
SELECT pin_id FROM board_has_pins WHERE board_id=241294561224164665 ORDER BY sequence LIMIT 50 OFFSET 150
Esto le dará más de 50 pin_id, que luego puede usar para buscar objetos de pin.
Lo que acabamos de hacer es una combinación de capa de aplicación (board_id -> pin_id -> pin objects). Una de las increíbles propiedades de las conexiones a nivel de aplicación es que puede almacenar en caché la imagen por separado del objeto. Almacenamos pin_id en el caché del objeto pin en el clúster de memcache, sin embargo, guardamos board_id en pin_id en el clúster redis. Esto nos permite elegir la tecnología correcta que mejor se adapte al objeto en caché.
Aumentar la capacidad
Hay tres formas principales de aumentar la capacidad en nuestro sistema. La forma más fácil de actualizar la máquina (para aumentar el espacio, poner discos duros más rápidos, más RAM).
La siguiente forma de aumentar la capacidad es abrir nuevas gamas. Inicialmente, creamos un total de 4096 fragmentos, a pesar de que la identificación del fragmento consistía en 16 bits (un total de 64k fragmentos). Solo se pueden crear nuevos objetos en estos primeros fragmentos de 4k. En algún momento, decidimos crear nuevos servidores MySQL con fragmentos de 4096 a 8191 y comenzamos a llenarlos.
La última forma en que aumentamos la capacidad es mover algunos fragmentos a nuevas máquinas. Si queremos aumentar la capacidad de MySQL001A (con fragmentos de 0 a 511), creamos un nuevo par maestro-maestro con los siguientes nombres máximos posibles (digamos MySQL009A y B) e iniciamos la replicación desde MySQL001A.
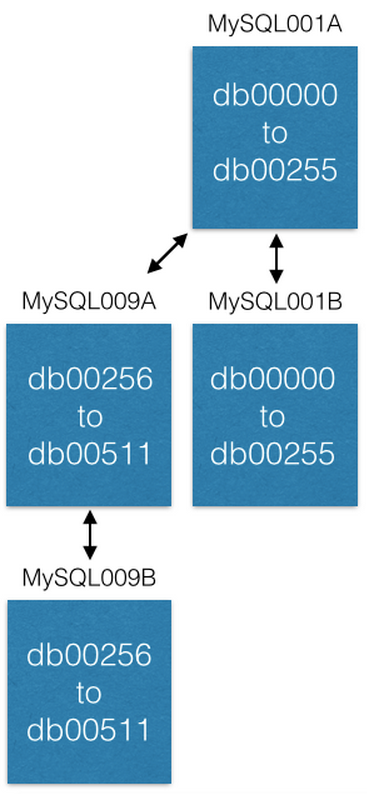
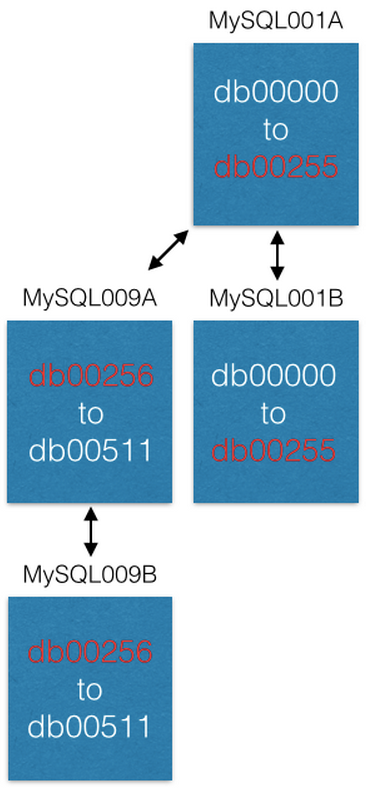
Tan pronto como se completa la replicación, cambiamos nuestra configuración para que en MySQL001A solo haya fragmentos de 0 a 255, y en MySQL009A de 256 a 511. Ahora cada servidor debe procesar solo la mitad de los fragmentos que procesó antes.
Algunas características geniales
¡Aquellos que ya tenían sistemas para generar nuevos
UUID entenderán que en este sistema los obtenemos sin costo! Cuando crea un nuevo objeto e lo inserta en la tabla de objetos, devuelve un nuevo identificador local. Esta ID local, combinada con la ID de fragmento y la ID de tipo, le proporciona un UUID.
Aquellos de ustedes que han realizado ALTERS para agregar más columnas a las tablas de MySQL saben que pueden trabajar extremadamente lentamente y convertirse en un gran problema. Nuestro enfoque no requiere ningún cambio en el nivel de MySQL. En Pinterest, probablemente solo hicimos un ALTER en los últimos tres años. Para agregar nuevos campos a los objetos, solo dígale a sus servicios que hay varios campos nuevos en el esquema JSON. Puede cambiar el valor predeterminado para que cuando deserialice JSON de un objeto sin un nuevo campo, obtenga el valor predeterminado. Si necesita una tabla de mapeo, cree una nueva tabla de mapeo y comience a llenarla cuando lo desee. Y cuando haya terminado, puede enviar!
Fragmento de mod
Es casi como un
escuadrón de mods , solo que completamente diferente.
Algunos objetos deben encontrarse sin una identificación. Por ejemplo, si un usuario inicia sesión con una cuenta de Facebook, necesitamos mapear desde la ID de Facebook a la ID de Pinterest. Para nosotros, los ID de Facebook son solo bits, por lo que los almacenamos en un sistema de fragmentos separado llamado mod shard.
Otros ejemplos incluyen direcciones IP, nombre de usuario y dirección de correo electrónico.
Mod Shard es muy similar al sistema de fragmentación descrito en la sección anterior, con la única diferencia de que puede buscar datos utilizando datos de entrada arbitrarios. Esta entrada se codifica y modifica de acuerdo con el número total de fragmentos en el sistema. Como resultado, se obtendrá un fragmento en el que los datos estarán o ya están ubicados. Por ejemplo:
shard = md5(“1.2.3.4") % 4096
En este caso, el fragmento será igual a 1524. Procesamos el archivo de configuración correspondiente a la ID del fragmento:
[{“range”: (0, 511), “master”: “msdb001a”, “slave”: “msdb001b”}, {“range”: (512, 1023), “master”: “msdb002a”, “slave”: “msdb002b”}, {“range”: (1024, 1535), “master”: “msdb003a”, “slave”: “msdb003b”}, …]
Por lo tanto, para encontrar datos en la dirección IP 1.2.3.4, necesitaremos hacer lo siguiente:
conn = MySQLdb.connect(host=”msdb003a”) conn.execute(“SELECT data FROM msdb001a.ip_data WHERE ip='1.2.3.4'”)
Está perdiendo algunas buenas propiedades de la ID del fragmento, como la localidad espacial. Tendrá que comenzar con todos los fragmentos creados al principio y crear la clave usted mismo (no se generará automáticamente). Siempre es mejor representar objetos en su sistema con ID inmutables. Por lo tanto, no necesita actualizar muchos enlaces cuando, por ejemplo, el usuario cambia su "nombre de usuario".
Últimos pensamientos
Este sistema ha estado produciendo en Pinterest durante 3.5 años, y es probable que permanezca allí para siempre. Implementarlo fue relativamente simple, pero ponerlo en funcionamiento y mover todos los datos de las máquinas antiguas fue difícil. Si encuentra un problema cuando acaba de crear un nuevo fragmento, considere crear un grupo de máquinas de procesamiento de datos en segundo plano (sugerencia: use
piras ) para mover sus datos con scripts de bases de datos antiguas a su nuevo fragmento. Le garantizo que algunos de los datos se perderán, no importa cuánto lo intente (es todo gremlins, lo juro), así que repita la transferencia de datos una y otra vez hasta que la cantidad de información nueva en el fragmento se vuelva muy pequeña o no sea nada.
Se ha hecho todo lo posible para este sistema. Pero no proporciona atomicidad, aislamiento o coherencia de ninguna manera. Wow! Eso suena mal! Pero no te preocupes. Seguramente, te sentirás excelente sin ellos. Siempre puede construir estas capas con otros procesos / sistemas, si es necesario, pero de manera predeterminada y sin costo ya obtiene bastante: capacidad de trabajo. ¡Fiabilidad lograda a través de la simplicidad, e incluso funciona rápido!
¿Pero qué hay de la tolerancia a fallas? Creamos un servicio para el mantenimiento de fragmentos de MySQL, guardamos la tabla de configuración de fragmentos en ZooKeeper. Cuando el servidor maestro falla, levantamos la máquina esclava y luego levantamos la máquina que la reemplazará (siempre actualizada). No utilizamos el procesamiento automático de fallas hasta el día de hoy.