Hola Habr
En la
parte anterior , la asistencia de Habr fue analizada por los parámetros principales: la cantidad de artículos, sus opiniones y calificaciones. Sin embargo, no se consideró la cuestión de la popularidad de las secciones del sitio. Se volvió interesante examinar esto con más detalle y encontrar los centros más populares y más impopulares. Finalmente, examinaré el "efecto geektimes" con más detalle, y al final, los lectores recibirán una nueva selección de los mejores artículos sobre las nuevas calificaciones.
A quién le importa lo que pasó, continuó bajo el corte.
Les recuerdo una vez más que las estadísticas y calificaciones no son oficiales, no tengo ninguna información privilegiada. Tampoco está garantizado que no me haya equivocado en alguna parte o que no me haya perdido algo. Pero aún así, creo que resultó interesante. Primero comenzaremos con el código, para quien esto es irrelevante, se pueden omitir las primeras secciones.
Recogida de datos
En la primera versión del analizador, solo se tuvo en cuenta el número de vistas, comentarios y la calificación de los artículos. Esto ya es bueno, pero no le permite hacer consultas más complejas. Es hora de analizar las secciones temáticas del sitio, esto le permitirá hacer una investigación bastante interesante, por ejemplo, ver cómo la popularidad de la sección "C ++" ha cambiado durante varios años.
Se ha mejorado el analizador del artículo, ahora devuelve los centros a los que pertenece el artículo, así como el apodo del autor y su calificación (aquí también puede hacer muchas cosas interesantes, pero esto más adelante). Los datos se guardan en un archivo csv de aproximadamente el siguiente tipo:
2018-12-18T12:43Z,https://habr.com/ru/post/433550/," Slack — , , ",votes:7,votesplus:8,votesmin:1,bookmarks:32, views:8300,comments:10,user:ReDisque,karma:5,subscribers:2,hubs:productpm+soft ...
Obtenga una lista de los principales centros temáticos del sitio.
def get_as_str(link: str) -> Str: try: r = requests.get(link) return Str(r.text) except Exception as e: return Str("") def get_hubs(): hubs = [] for p in range(1, 12): page_html = get_as_str("https://habr.com/ru/hubs/page%d/" % p)
La función find_between y la clase Str resaltan una línea entre dos etiquetas, las usé
antes . Los centros temáticos están marcados con "*", para que sean fáciles de resaltar, también puede descomentar las líneas correspondientes para obtener secciones de otras categorías.
En la salida de la función get_hubs, obtenemos una lista bastante impresionante, que guardamos como diccionario. Cito especialmente la lista completa para que se pueda estimar su volumen.
hubs_profile = {'infosecurity', 'programming', 'webdev', 'python', 'sys_admin', 'it-infrastructure', 'devops', 'javascript', 'open_source', 'network_technologies', 'gamedev', 'cpp', 'machine_learning', 'pm', 'hr_management', 'linux', 'analysis_design', 'ui', 'net', 'hi', 'maths', 'mobile_dev', 'productpm', 'win_dev', 'it_testing', 'dev_management', 'algorithms', 'go', 'php', 'csharp', 'nix', 'data_visualization', 'web_testing', 's_admin', 'crazydev', 'data_mining', 'bigdata', 'c', 'java', 'usability', 'instant_messaging', 'gtd', 'system_programming', 'ios_dev', 'oop', 'nginx', 'kubernetes', 'sql', '3d_graphics', 'css', 'geo', 'image_processing', 'controllers', 'game_design', 'html5', 'community_management', 'electronics', 'android_dev', 'crypto', 'netdev', 'cisconetworks', 'db_admins', 'funcprog', 'wireless', 'dwh', 'linux_dev', 'assembler', 'reactjs', 'sales', 'microservices', 'search_technologies', 'compilers', 'virtualization', 'client_side_optimization', 'distributed_systems', 'api', 'media_management', 'complete_code', 'typescript', 'postgresql', 'rust', 'agile', 'refactoring', 'parallel_programming', 'mssql', 'game_promotion', 'robo_dev', 'reverse-engineering', 'web_analytics', 'unity', 'symfony', 'build_automation', 'swift', 'raspberrypi', 'web_design', 'kotlin', 'debug', 'pay_system', 'apps_design', 'git', 'shells', 'laravel', 'mobile_testing', 'openstreetmap', 'lua', 'vs', 'yii', 'sport_programming', 'service_desk', 'itstandarts', 'nodejs', 'data_warehouse', 'ctf', 'erp', 'video', 'mobileanalytics', 'ipv6', 'virus', 'crm', 'backup', 'mesh_networking', 'cad_cam', 'patents', 'cloud_computing', 'growthhacking', 'iot_dev', 'server_side_optimization', 'latex', 'natural_language_processing', 'scala', 'unreal_engine', 'mongodb', 'delphi', 'industrial_control_system', 'r', 'fpga', 'oracle', 'arduino', 'magento', 'ruby', 'nosql', 'flutter', 'xml', 'apache', 'sveltejs', 'devmail', 'ecommerce_development', 'opendata', 'Hadoop', 'yandex_api', 'game_monetization', 'ror', 'graph_design', 'scada', 'mobile_monetization', 'sqlite', 'accessibility', 'saas', 'helpdesk', 'matlab', 'julia', 'aws', 'data_recovery', 'erlang', 'angular', 'osx_dev', 'dns', 'dart', 'vector_graphics', 'asp', 'domains', 'cvs', 'asterisk', 'iis', 'it_monetization', 'localization', 'objectivec', 'IPFS', 'jquery', 'lisp', 'arvrdev', 'powershell', 'd', 'conversion', 'animation', 'webgl', 'wordpress', 'elm', 'qt_software', 'google_api', 'groovy_grails', 'Sailfish_dev', 'Atlassian', 'desktop_environment', 'game_testing', 'mysql', 'ecm', 'cms', 'Xamarin', 'haskell', 'prototyping', 'sw', 'django', 'gradle', 'billing', 'tdd', 'openshift', 'canvas', 'map_api', 'vuejs', 'data_compression', 'tizen_dev', 'iptv', 'mono', 'labview', 'perl', 'AJAX', 'ms_access', 'gpgpu', 'infolust', 'microformats', 'facebook_api', 'vba', 'twitter_api', 'twisted', 'phalcon', 'joomla', 'action_script', 'flex', 'gtk', 'meteorjs', 'iconoskaz', 'cobol', 'cocoa', 'fortran', 'uml', 'codeigniter', 'prolog', 'mercurial', 'drupal', 'wp_dev', 'smallbasic', 'webassembly', 'cubrid', 'fido', 'bada_dev', 'cgi', 'extjs', 'zend_framework', 'typography', 'UEFI', 'geo_systems', 'vim', 'creative_commons', 'modx', 'derbyjs', 'xcode', 'greasemonkey', 'i2p', 'flash_platform', 'coffeescript', 'fsharp', 'clojure', 'puppet', 'forth', 'processing_lang', 'firebird', 'javame_dev', 'cakephp', 'google_cloud_vision_api', 'kohanaphp', 'elixirphoenix', 'eclipse', 'xslt', 'smalltalk', 'googlecloud', 'gae', 'mootools', 'emacs', 'flask', 'gwt', 'web_monetization', 'circuit-design', 'office365dev', 'haxe', 'doctrine', 'typo3', 'regex', 'solidity', 'brainfuck', 'sphinx', 'san', 'vk_api', 'ecommerce'}
A modo de comparación, las secciones geektimes parecen más modestas:
hubs_gt = {'popular_science', 'history', 'soft', 'lifehacks', 'health', 'finance', 'artificial_intelligence', 'itcompanies', 'DIY', 'energy', 'transport', 'gadgets', 'social_networks', 'space', 'futurenow', 'it_bigraphy', 'antikvariat', 'games', 'hardware', 'learning_languages', 'urban', 'brain', 'internet_of_things', 'easyelectronics', 'cellular', 'physics', 'cryptocurrency', 'interviews', 'biotech', 'network_hardware', 'autogadgets', 'lasers', 'sound', 'home_automation', 'smartphones', 'statistics', 'robot', 'cpu', 'video_tech', 'Ecology', 'presentation', 'desktops', 'wearable_electronics', 'quantum', 'notebooks', 'cyberpunk', 'Peripheral', 'demoscene', 'copyright', 'astronomy', 'arvr', 'medgadgets', '3d-printers', 'Chemistry', 'storages', 'sci-fi', 'logic_games', 'office', 'tablets', 'displays', 'video_conferencing', 'videocards', 'photo', 'multicopters', 'supercomputers', 'telemedicine', 'cybersport', 'nano', 'crowdsourcing', 'infographics'}
Del mismo modo, los centros restantes se guardaron. Ahora es fácil escribir una función que devuelva el resultado, el artículo hace referencia a geektimes o a un centro de perfiles.
def is_geektimes(hubs: List) -> bool: return len(set(hubs) & hubs_gt) > 0 def is_geektimes_only(hubs: List) -> bool: return is_geektimes(hubs) is True and is_profile(hubs) is False def is_profile(hubs: List) -> bool: return len(set(hubs) & hubs_profile) > 0
Se hicieron funciones similares para otras secciones ("desarrollo", "administración", etc.).
Procesamiento
Es hora de comenzar el análisis. Cargamos el conjunto de datos y procesamos los datos de los centros.
def to_list(s: str) -> List[str]:
Ahora podemos agrupar los datos por día y mostrar el número de publicaciones por diferentes centros.
g = df.groupby(['date']) days_count = g.size().reset_index(name='counts') year_days = days_count['date'].values grouped = g.sum().reset_index() profile_per_day_avg = grouped['is_profile'].rolling(window=20, min_periods=1).mean() geektimes_per_day_avg = grouped['is_geektimes'].rolling(window=20, min_periods=1).mean() geektimesonly_per_day_avg = grouped['is_geektimes_only'].rolling(window=20, min_periods=1).mean() admin_per_day_avg = grouped['is_admin'].rolling(window=20, min_periods=1).mean() develop_per_day_avg = grouped['is_develop'].rolling(window=20, min_periods=1).mean()
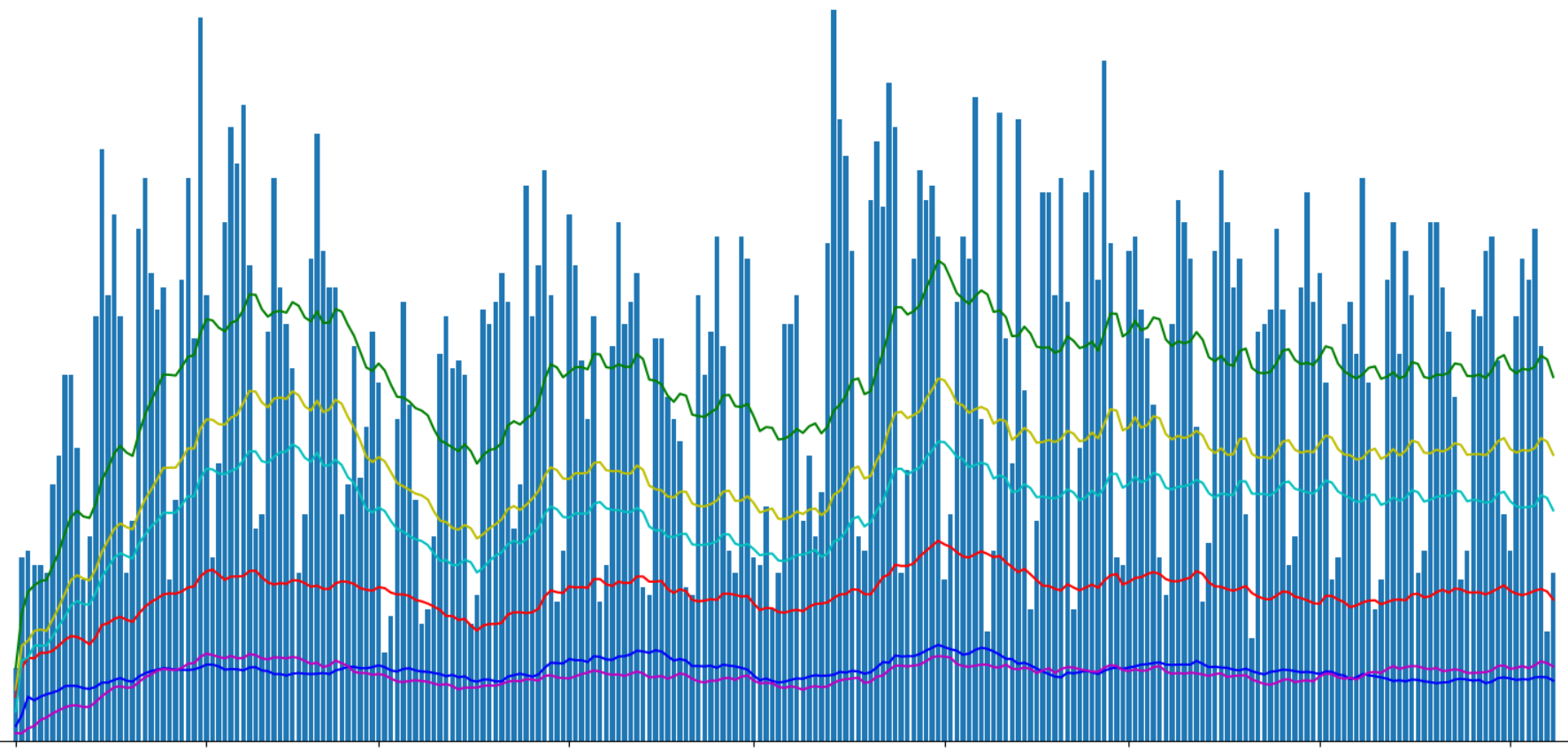
Muestre la cantidad de artículos publicados con Matplotlib:

Dividí los artículos "geektimes" y "geektimes only" en el gráfico, porque un artículo puede pertenecer a ambas secciones simultáneamente (por ejemplo, "DIY" + "microcontroladores" + "C ++"). Con la designación "perfil", destaqué los artículos de perfil del sitio, aunque es posible que el término inglés perfil no sea del todo correcto para esto.
En la parte anterior, preguntamos sobre el "efecto geektimes" asociado con el cambio en las reglas para pagar artículos por geektimes de este verano. Derivamos artículos geektimes separados:
df_gt = df[(df['is_geektimes_only'] == True)] group_gt = df_gt.groupby(['date']) days_count_gt = group_gt.size().reset_index(name='counts') grouped = group_gt.sum().reset_index() year_days_gt = days_count_gt['date'].values view_gt_per_day_avg = grouped['views'].rolling(window=20, min_periods=1).mean()
El resultado es interesante. La proporción aproximada de vistas de artículos geektimes al total en algún lugar alrededor de 1: 5. Pero si el número total de visitas fluctuaba notablemente, la visualización de artículos "entretenidos" se mantuvo aproximadamente al mismo nivel.

También puede observar que, sin embargo, el número total de vistas de artículos en la sección "geektimes" después de cambiar las reglas disminuyó, pero "a simple vista", en no más del 5% de los valores totales.
Es interesante ver el número promedio de visitas por artículo:

Para los artículos "entretenidos", es aproximadamente un 40% superior al promedio. Esto probablemente no sea sorprendente. El fracaso a principios de abril no está claro para mí, tal vez lo fue, o es algún tipo de error de análisis, o tal vez uno de los autores geektime se fue de vacaciones;).
Por cierto, en el gráfico hay dos picos más notables en el número de vistas de artículos: vacaciones de año nuevo y mayo.
Hubs
Pasemos al análisis prometido de los centros. Mostraremos los 20 centros principales según la cantidad de vistas:
hubs_info = [] for hub_name in hubs_all: mask = df['hubs'].apply(lambda x: hub_name in x) df_hub = df[mask] count, views = df_hub.shape[0], df_hub['views'].sum() hubs_info.append((hub_name, count, views))
Resultado:

Sorprendentemente, el centro de "Seguridad de la información" resultó ser el más popular en términos de visualización, también "Programación" y "Ciencia popular" se encuentran entre los 5 principales líderes.
Antitope toma Gtk y Cocoa.

Te diré un secreto, los principales centros también se pueden ver
aquí , aunque la cantidad de vistas no se muestra allí.
Calificación
Y finalmente, la calificación prometida. Usando los datos del análisis de los centros, podemos mostrar los artículos más populares sobre los centros más populares para este año 2019.
Seguridad de la información- Cómo no trabajé durante un año en Sberbank 304000 vistas, 599 comentarios, calificación + 457.0 / -14.0
- Las bombillas inteligentes arrojadas a la basura son una valiosa fuente de información personal 232,000 vistas, 147 comentarios, calificación + 75.0 / -11.0
- Fraudes y EDS: todo es muy malo 176,000 vistas, 778 comentarios, calificación + 356.0 / -0.0
- Cómo dormía Megafon en suscripciones móviles 166,000 vistas, 676 comentarios, calificación + 624.0 / -2.0
- Hackeando VK, la autenticación de dos factores no ahorrará 148,000 vistas, 332 comentarios, calificación + 124.0 / -17.0
- Cómo ayuda el navegador al Camarada Major 132,000 vistas, 321 comentarios, calificación + 246.0 / -19.0
- El vertedero más grande de la historia: 2.700 millones de cuentas, de las cuales 773 millones de 123.000 visitas únicas , 154 comentarios, calificación + 86.0 / -5.0
- Cariño, matamos a Internet 121,000 visitas, 933 comentarios, calificación + 392.0 / -83.0
- 'Contenido móvil' gratis, sin SMS ni registros. El fraude de Megafon detalla 114,000 visitas, 478 comentarios, calificación + 488.0 / -8.0
- Escáner de puertos en la cuenta personal de Rostelecom 111,000 vistas, 194 comentarios, calificación + 300.0 / -8.0
Programacion- Acerca de un hombre 167,000 vistas, 249 comentarios, calificación + 239.0 / -33.0
- Cuanto más rápido se olvide de OOP, mejor para usted y sus programas 129,000 vistas, 1271 comentarios, calificación + 131.0 / -63.0
- Por qué los desarrolladores senior no pueden conseguir un trabajo 119,000 visitas, 901 comentarios, calificación + 151.0 / -14.0
- ¿Las personas mayores no pertenecen aquí? Programamos después de treinta y cinco 116,000 vistas, 649 comentarios, calificación + 222.0 / -16.0
- Los nuevos lenguajes de programación matan imperceptiblemente nuestra conexión con la realidad 106,000 vistas, 764 comentarios, calificación + 164.0 / -52.0
- Lo que aprendí de mi amarga experiencia (más de 30 años en desarrollo de software) 101,000 visitas, 128 comentarios, calificación + 178.0 / -9.0
- Los lenguajes de programación más raros y caros 82900 vistas, 119 comentarios, calificación + 38.0 / -10.0
- Conferencia en JavaScript y Node.js en el KPI 80300 vistas, 14 comentarios, calificación + 34.0 / -2.0
- Términos de TI sobre el ejemplo del proceso de cultivo de papas 78000 vistas, 86 comentarios, calificación + 84.0 / -14.0
- 256 líneas de C ++ simple: escribir un trazador de rayos desde cero en unas pocas horas 77600 vistas, 124 comentarios, calificación + 241.0 / -0.0
Ciencia popular- Lo que el diseñador fumó: un arma de fuego inusual 236,000 vistas, 123 comentarios, calificación + 119.0 / -9.0
- Los científicos han encontrado el vertebrado vivo más antiguo de la Tierra 234,000 vistas, 212 comentarios, calificación + 82.0 / -14.0
- La serie 'Chernobyl': mira y piensa 173,000 vistas, 803 comentarios, calificación + 164.0 / -25.0
- Un adolescente de 12 años realizó una reacción de fusión nuclear en el laboratorio de su casa 145,000 visitas, 280 comentarios, calificación + 126.0 / -29.0
- The Tale of the Rose Alloy and the Fallen Krenka 134,000 vistas, 244 comentarios, calificación + 217.0 / -1.0
- Aumentarlo! Aumento moderno en la resolución 134000 vistas, 235 comentarios, calificación + 377.0 / -1.0
- El software para el Boeing-737 Max fue escrito por subcontratistas que ganan $ 9 por hora ; 126,000 visitas; 560 comentarios; calificación + 153.0 / -6.0
- No se ponga nervioso, no se apresure, no interrumpa: la historia de una tragedia 121,000 vistas, 384 comentarios, calificación + 242.0 / -4.0
- Los matemáticos han encontrado la manera perfecta de multiplicar números 108,000 vistas, 222 comentarios, calificación + 173.0 / -10.0
- Los nuevos lenguajes de programación matan imperceptiblemente nuestra conexión con la realidad 106,000 vistas, 764 comentarios, calificación + 164.0 / -52.0
Carrera- Cómo no trabajé durante un año en Sberbank 304000 vistas, 599 comentarios, calificación + 457.0 / -14.0
- Arruino la vida de los desarrolladores con mis revisiones de código y lo siento 187,000 visitas, 21 comentarios, calificación + 37.0 / -3.0
- Development King 179,000 vistas, 668 comentarios, calificación + 315.0 / -60.0
- Acerca de un hombre 167,000 vistas, 249 comentarios, calificación + 239.0 / -33.0
- Retirado con 22,158,000 visitas, 927 comentarios, calificación + 259.0 / -100.0
- ¿Cómo reemplazar una bombilla en el lugar de trabajo para que no te despidan? 139000 visitas, 762 comentarios, calificación + 200.0 / -20.0
- Innovación en ruso 128,000 visitas, 612 comentarios, calificación + 480.0 / -33.0
- Por qué los desarrolladores senior no pueden conseguir un trabajo 119,000 visitas, 901 comentarios, calificación + 151.0 / -14.0
- Empleados 'quemados': ¿hay alguna salida? 117000 visitas, 398 comentarios, calificación + 210.0 / -14.0
- ¿Las personas mayores no pertenecen aquí? Programamos después de treinta y cinco 116,000 vistas, 649 comentarios, calificación + 222.0 / -16.0
Legislación en TI- Fraudes y EDS: todo es muy malo 176,000 vistas, 778 comentarios, calificación + 356.0 / -0.0
- Cómo dormía Megafon en suscripciones móviles 166,000 vistas, 676 comentarios, calificación + 624.0 / -2.0
- Innovación en ruso 128,000 visitas, 612 comentarios, calificación + 480.0 / -33.0
- 'Contenido móvil' gratis, sin SMS ni registros. El fraude de Megafon detalla 114,000 visitas, 478 comentarios, calificación + 488.0 / -8.0
- Mientras las autoridades de Kazajstán intentan ocultar su fracaso con la introducción del certificado, 111,000 visitas, 77 comentarios, calificación + 122.0 / -14.0
- Cómo se bloquea Protonmail en Rusia 102000 visitas, 398 comentarios, calificación + 418.0 / -7.0
- La Ley sobre el aislamiento de los Runet fue adoptada por la Duma del Estado en tres lecturas, 88.200 vistas, 878 comentarios, calificación + 73.0 / -18.0
- Como programador, el banco eligió y leyó el contrato 87,200 visitas, 611 comentarios, calificación + 166.0 / -9.0
- El Ministerio de Comunicaciones y Medios de Comunicación ha aprobado el proyecto de ley sobre aislamiento de Runet 83600 vistas, 364 comentarios, calificación + 79.0 / -9.0
- Una respuesta detallada al comentario, así como un poco sobre la vida de los proveedores en la Federación de Rusia, 74700 visitas, 389 comentarios, calificación + 290.0 / -1.0
Desarrollo web- ¿Las personas mayores no pertenecen aquí? Programamos después de treinta y cinco 116,000 vistas, 649 comentarios, calificación + 222.0 / -16.0
- Cómo hacer sitios en 2019 110,000 vistas, 278 comentarios, calificación + 233.0 / -11.0
- Learning Docker, Parte 1: Conceptos básicos 91300 vistas, 24 comentarios, calificación + 52.0 / -10.0
- Conferencia en JavaScript y Node.js en el KPI 80300 vistas, 14 comentarios, calificación + 34.0 / -2.0
- El aprendiz Vasya y sus historias sobre idempotencia API 68900 vistas, 160 comentarios, calificación + 216.0 / -3.0
- La comprensión de las uniones está rota. Definitivamente, esta no es la intersección de círculos, sinceramente 65,900 vistas, 223 comentarios, calificación + 138.0 / -41.0
- Por qué no necesita gastar su tiempo creando sitios temáticos de nicho 62700 vistas, 243 comentarios, calificación + 179.0 / -13.0
- Hacemos una aplicación web moderna desde cero 62200 vistas, 122 comentarios, calificación + 56.0 / -8.0
- Un día oscuro para Vue.js 60,800 vistas, 133 comentarios, calificación + 77.0 / -6.0
- ¿Por qué el desarrollo web moderno es tan complicado? Parte 1,577,700 vistas, 319 comentarios, calificación + 101.0 / -6.0
GTKY finalmente, para no ofender a nadie, le daré la calificación del centro "gtk" menos visitado. En él,
un artículo fue publicado durante el año, también ocupa "automáticamente" la primera línea de la calificación.
Conclusión
No habrá conclusión. Disfruta leyendo a todos.