
Hoy, miércoles, se realizará el próximo lanzamiento de Kubernetes: 1.16. De acuerdo con la tradición que se ha desarrollado para nuestro blog, por décimo aniversario, estamos hablando de los cambios más significativos en la nueva versión.
La información utilizada para preparar este material se toma de
la tabla de seguimiento de mejoras de Kubernetes ,
CHANGELOG-1.16 y cuestiones relacionadas, solicitudes de extracción, así como las Propuestas de mejora de Kubernetes (KEP). ¡Entonces vamos! ..
Nudos
Un número realmente grande de innovaciones notables (en el estado de versión alfa) se presentan en el lado de los nodos de los grupos K8s (Kubelet).
En primer lugar, se presentan los llamados
" contenedores efímeros " (Contenedores efímeros ) , diseñados para simplificar el proceso de depuración en pods . El nuevo mecanismo le permite ejecutar contenedores especiales que comienzan en el espacio de nombres de los pods existentes y viven por un corto tiempo. Su propósito es interactuar con otros pods y contenedores para resolver cualquier problema y depuración. Para esta característica, se
kubectl debug un nuevo
kubectl debug , similar en esencia a
kubectl exec : solo que en lugar de iniciar el proceso en el contenedor (como en el caso de
exec ), inicia el contenedor en el pod. Por ejemplo, dicho comando conectará un nuevo contenedor al pod:
kubectl debug -c debug-shell --image=debian target-pod -- bash
Los detalles sobre contenedores efímeros (y ejemplos de su uso) se pueden encontrar en el
KEP correspondiente . La implementación actual (en K8s 1.16) es la versión alfa, y entre los criterios para su transferencia a la versión beta está "probar la API de Contenedores Efímeros para al menos 2 lanzamientos [Kubernetes]".
NB : en esencia, incluso el nombre de la característica se asemeja al plugin kubectl-debug ya existente, sobre el que ya escribimos . Se supone que con la llegada de los contenedores efímeros, se detendrá el desarrollo de un complemento externo separado.Otra innovación,
PodOverhead está diseñada para proporcionar un
mecanismo para calcular los costos generales de las cápsulas , que pueden variar mucho según el tiempo de ejecución utilizado. Como ejemplo, los autores de
esta KEP citan Kata Containers, que requieren el lanzamiento del kernel invitado, el agente kata, el sistema init, etc. Cuando los gastos generales se vuelven tan grandes, no se pueden ignorar, lo que significa que se necesita una forma de tenerlo en cuenta para nuevas cuotas, planificación, etc. Para implementarlo, el campo
Overhead *ResourceList se ha agregado a
PodSpec (en comparación con los datos en
RuntimeClass , si se usa uno).
Otra innovación notable es el
Node Topology Manager , diseñado para unificar el enfoque para ajustar la asignación de recursos de hardware para varios componentes en Kubernetes. Esta iniciativa es causada por la creciente demanda de varios sistemas modernos (del campo de las telecomunicaciones, el aprendizaje automático, los servicios financieros, etc.) de computación paralela de alto rendimiento y minimizando los retrasos en la ejecución de operaciones, para lo cual utilizan las capacidades avanzadas de aceleración de CPU y hardware. Tales optimizaciones en Kubernetes se han logrado hasta ahora gracias a componentes dispares (administrador de CPU, administrador de dispositivos, CNI), y ahora agregarán una única interfaz interna que unifica el enfoque y simplifica la conexión de nuevos componentes similares, los llamados conscientes de la topología, en el lado de Kubelet. Los detalles están en el
KEP correspondiente .
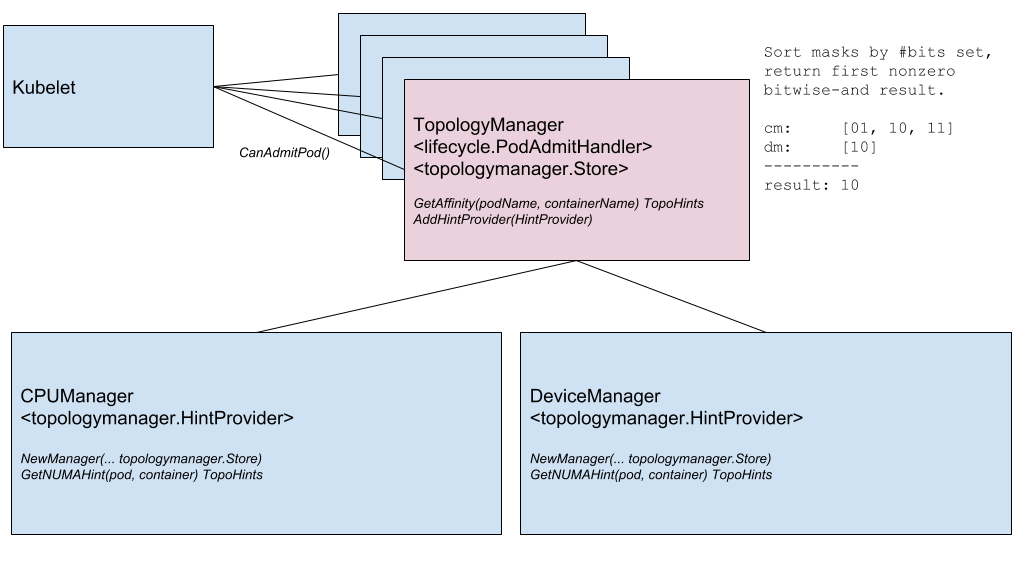 Diagrama de componentes del administrador de topología
Diagrama de componentes del administrador de topologíaLa siguiente característica es
verificar los contenedores durante el inicio ( sonda de inicio ) . Como ya sabe, para los contenedores que se ejecutan durante mucho tiempo, es difícil obtener el estado actual: se los "mata" antes del inicio real de la operación o terminan en un punto muerto durante mucho tiempo. Una nueva verificación (habilitada a través de la puerta de funciones llamada
StartupProbeEnabled ) cancela, o más bien
StartupProbeEnabled , la acción de cualquier otra verificación hasta el momento en que el pod ha terminado su lanzamiento. Por esta razón, la característica originalmente se llamaba
espera de inicio de prueba de podness de inicio de pod . Para los pods que tardan mucho en iniciarse, puede sondear el estado en intervalos de tiempo relativamente cortos.
Además, inmediatamente en estado beta se agrega una mejora para RuntimeClass, agregando soporte para "clústeres heterogéneos". Con
RuntimeClass Scheduling, ahora no es necesario que cada nodo tenga soporte para cada RuntimeClass: para los pods, puede elegir RuntimeClass sin pensar en la topología del clúster. Anteriormente, para lograr esto, para que los pods aparecieran en nodos con soporte para todo lo que necesitaban, tenían que asignar reglas apropiadas a NodeSelector y tolerancias.
KEP habla sobre ejemplos de uso y, por supuesto, detalles de implementación.
Red
Dos características importantes de la red que aparecieron por primera vez (en la versión alfa) en Kubernetes 1.16 son:
- Soporte para una pila de red dual - IPv4 / IPv6 - y su correspondiente "comprensión" a nivel de pods, nodos, servicios. Incluye la interacción de IPv4 a IPv4 e IPv6 a IPv6 entre pods, desde pods a servicios externos, implementaciones de referencia (en el marco de los complementos Bridge CNI, PTP CNI y Host-Local IPAM), así como a la inversa Compatible con clústeres de Kubernetes que funcionan solo a través de IPv4 o IPv6. Los detalles de implementación están en KEP .
Un ejemplo de la salida de dos tipos de direcciones IP (IPv4 e IPv6) en la lista de pods:
kube-master
- La nueva API para Endpoint es la API EndpointSlice . Resuelve los problemas de la API de Endpoint existente con rendimiento / escalabilidad que afecta a varios componentes en el plano de control (apiserver, etcd, endpoints-controller, kube-proxy). La nueva API se agregará al grupo Discovery API y podrá servir decenas de miles de puntos finales de back-end en cada servicio en un clúster que consta de mil nodos. Para hacer esto, cada Servicio se asigna a N objetos de
EndpointSlice , cada uno de los cuales por defecto no tiene más de 100 puntos finales (el valor es configurable). La API EndpointSlice también brindará oportunidades para su desarrollo futuro: soporte para muchas direcciones IP para cada pod, nuevos estados para puntos finales (no solo Ready y NotReady ), subconjunto dinámico para puntos finales.
El
finalizador presentado en la última versión llamada
service.kubernetes.io/load-balancer-cleanup y adjuntado a cada servicio con el tipo
LoadBalancer avanzado a la versión beta. En el momento de la eliminación de dicho servicio, evita la eliminación real del recurso hasta que se complete la "limpieza" de todos los recursos correspondientes del equilibrador.
Maquinaria API
El verdadero "hito de estabilización" se fija en el área del servidor API de Kubernetes y la interacción con él. En muchos aspectos, esto sucedió debido a la
transferencia al estado estable de CustomResourceDefinitions (CRD) que
no necesitaba una presentación especial , que tenía un estado beta desde el distante Kubernetes 1.7 (¡y esto es junio de 2017!). La misma estabilización llegó a las características relacionadas con ellos:
- "Subresources" con
/status y /scale para CustomResources; - conversión de versión para CRD, basada en un webhook externo;
- valores predeterminados recientemente introducidos (en K8s 1.15) ( valores predeterminados ) y eliminación automática de campos (poda) para CustomResources;
- La posibilidad de utilizar el esquema OpenAPI v3 para crear y publicar la documentación de OpenAPI utilizada para validar los recursos CRD en el lado del servidor.
Otro mecanismo que ha sido familiar para los administradores de Kubernetes: el
webhook de admisión , también ha estado en estado beta durante mucho tiempo (desde K8s 1.9) y ahora se ha declarado estable.
Otras dos características llegaron a beta:
aplicar en el lado del servidor y
mirar marcadores .
Y la única innovación significativa en la versión alfa fue el
rechazo de SelfLink , un URI especial que representa el objeto especificado y es parte de
ObjectMeta y
ListMeta (es decir, parte de cualquier objeto en Kubernetes). ¿Por qué rechazarlo? La motivación "simple"
suena como la ausencia de razones reales (insuperables) para que este campo continúe existiendo. Las razones más formales son para optimizar el rendimiento (eliminar un campo innecesario) y simplificar el trabajo del genérico-apiserver, que se ve obligado a procesar dicho campo de una manera especial (este es el único campo que se establece justo antes de que el objeto se serialice). La verdadera "obsolescencia" (en la versión beta) de
SelfLink pasará a la versión 1.20 de Kubernetes, y la versión final - 1.21.
Almacenamiento de datos
El trabajo principal en el campo del almacenamiento, como en versiones anteriores, se observa en el campo de
soporte para CSI . Los principales cambios aquí son:
- por primera vez (en la versión alfa) , ha aparecido la compatibilidad con los complementos CSI para los nodos de trabajo de Windows : la forma actual de trabajar con repositorios reemplazará los complementos en árbol en el núcleo Kubernetes y los complementos FlexVolume basados en Powershell de Microsoft;
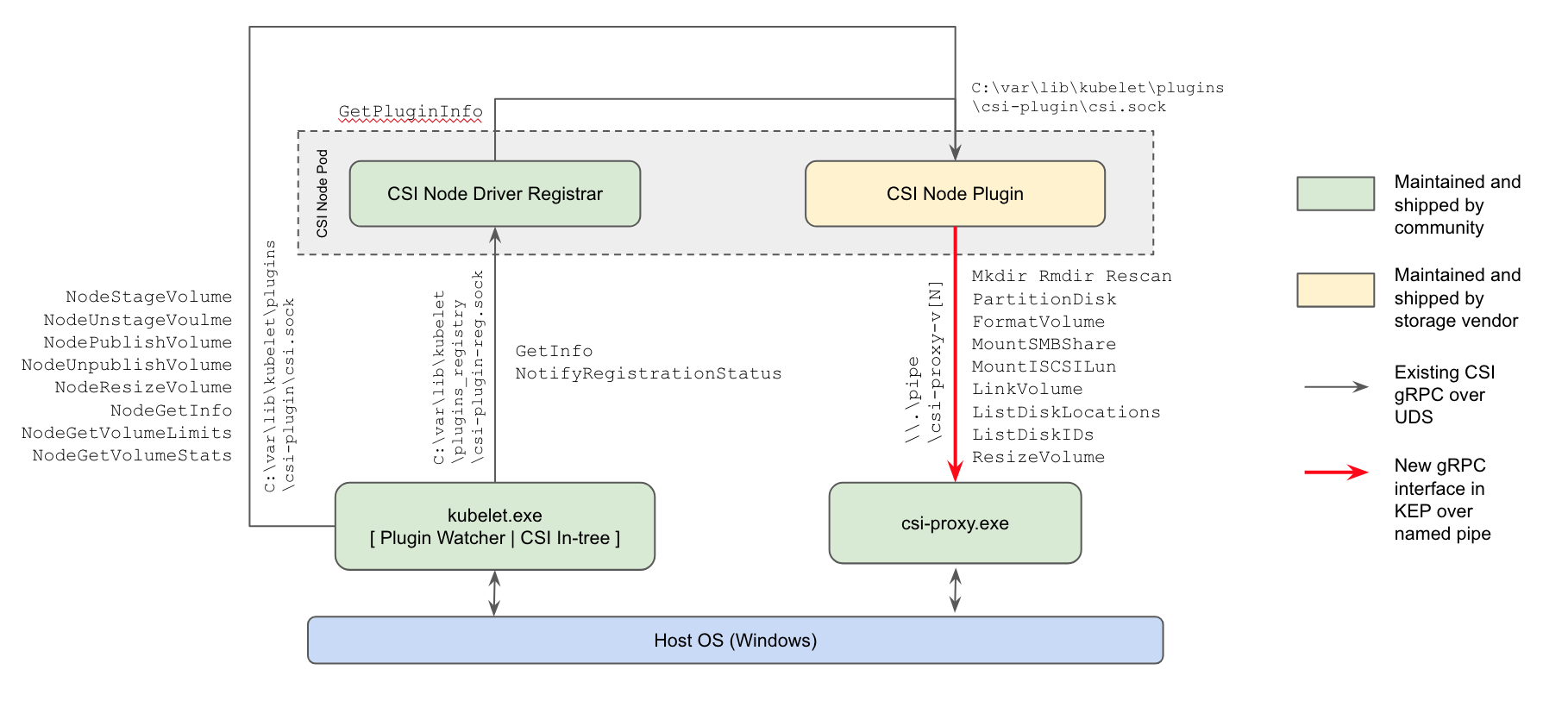
Esquema de implementación del complemento Kubernetes Windows CSI
- la capacidad de cambiar el tamaño de los volúmenes CSI , introducida en K8s 1.12, ha crecido a una versión beta;
- La posibilidad de utilizar CSI para crear volúmenes efímeros locales ( Soporte de volumen en línea CSI ) ha alcanzado un "aumento" similar (de alfa a beta).
La
función para clonar volúmenes que aparecieron en la versión anterior de Kubernetes (usando PVC existentes como
DataSource para crear nuevos PVC) ahora también ha recibido el estado beta.
Planificador
Dos cambios notables en la planificación (ambos en versión alfa):
EvenPodsSpreading es la capacidad de usar EvenPodsSpreading para "distribuir equitativamente" cargas de cargas en lugar de unidades lógicas de aplicación (como Deployment y ReplicaSet) y ajustar esta distribución (como un requisito estricto o como una condición leve, es decir, prioridad). La función ampliará las capacidades de distribución existentes de los pods planificados, ahora limitados por las PodAntiAffinity PodAffinity y PodAntiAffinity , brindando a los administradores más control sobre este problema, lo que significa una mejor accesibilidad y un consumo de recursos optimizado. Los detalles están en el KEP .- Uso de la política de BestFit en la función de prioridad RequestedToCapacityRatio durante la programación del pod, que permite que el empaquetado bin ("empaquetado en contenedores") se use tanto para recursos centrales (procesador, memoria) como extendido (como GPU). Ver KEP para más detalles.

Programación de pod: antes de usar la política de mejor ajuste (directamente a través del planificador predeterminado) y usarla (a través del extensor del planificador)
Además,
se presenta la oportunidad de crear sus propios complementos para el planificador fuera del árbol de desarrollo principal de Kubernetes (fuera del árbol).
Otros cambios
También en la versión 1.16 de Kubernetes, puede observar la
iniciativa de poner las métricas existentes en orden completo , o más precisamente, de acuerdo con los
requisitos oficiales para la instrumentación de K8. Básicamente se basan en la
documentación relevante de
Prometheus . Las inconsistencias se formaron por varias razones (por ejemplo, algunas métricas simplemente se crearon antes de que aparecieran las instrucciones actuales), y los desarrolladores decidieron que era hora de poner todo en un solo estándar, "en línea con el resto del ecosistema Prometheus". La implementación actual de esta iniciativa tiene el estado de la versión alfa, que aumentará gradualmente en futuras versiones de Kubernetes a beta (1.17) y estable (1.18).
Además, se pueden observar los siguientes cambios:
- Desarrollo de soporte de Windows con el advenimiento de la utilidad Kubeadm para este sistema operativo (versión alfa), la posibilidad de
RunAsUserName para contenedores de Windows (versión alfa), mejora del soporte para la Cuenta de servicio administrado grupal (gMSA) a la versión beta, soporte de montaje / conexión para volúmenes vSphere. - Mecanismo de compresión de datos rediseñado en respuestas API . Anteriormente, se usaba un filtro HTTP para estos fines, que imponía una serie de restricciones que impedían su inclusión por defecto. Ahora funciona la "compresión transparente de solicitudes": los clientes que envían
Accept-Encoding: gzip en el encabezado reciben una respuesta comprimida en GZIP si su tamaño supera los 128 Kb. Los clientes en Go admiten automáticamente la compresión (envíe el encabezado deseado), por lo que notan inmediatamente una disminución en el tráfico. (Para otros idiomas, pueden ser necesarias modificaciones menores). - Se hizo posible escalar HPA de / a cero pods en función de métricas externas . Si el escalado se basa en objetos / métricas externas, cuando las cargas de trabajo estén inactivas, puede escalar automáticamente a 0 réplicas para ahorrar recursos. Esta característica debería ser especialmente útil para los casos en que los trabajadores solicitan recursos de GPU, y la cantidad de diferentes tipos de trabajadores inactivos excede la cantidad de GPU disponibles.
- Un nuevo cliente -
k8s.io/client-go/metadata.Client - para el acceso "generalizado" a los objetos. Está diseñado para obtener fácilmente metadatos (es decir, la subsección de metadata ) de los recursos del clúster y realizar operaciones con ellos desde la categoría de recolección de basura y cuotas. - Kubernetes ahora se puede construir sin proveedores de nube desactualizados ("incorporado" en el árbol) (versión alfa).
- La capacidad experimental (versión alfa) para aplicar parches de kustomize durante las operaciones de
init , join y upgrade se ha agregado a la utilidad kubeadm. Para obtener detalles sobre cómo usar la --experimental-kustomize , consulte KEP . - El nuevo punto final para apiserver es
readyz , que le permite exportar información de preparación. El servidor API también tiene un indicador: --maximum-startup-sequence-duration , que le permite ajustar sus reinicios. - Dos características para Azure se declaran estables: Soporte para zonas de disponibilidad y grupo de recursos cruzados (RG). Además, Azure agregó:
- AWS tiene soporte para EBS en Windows y llamadas de API EC2 optimizadas
DescribeInstances . - Kubeadm ahora migra su configuración CoreDNS por sí solo cuando se actualiza a CoreDNS.
- Los archivos binarios, etc., en la imagen de Docker correspondiente se hicieron ejecutables en todo el mundo, lo que le permite ejecutar esta imagen sin la necesidad de privilegios de root. Además, la imagen de migración de etcd dejó de ser compatible con la versión de etcd2.
- Cluster Autoscaler 1.16.0 cambió a usar distroless como imagen base, mejor rendimiento y nuevos proveedores de nube (DigitalOcean, Magnum, Packet).
- Actualizaciones en el software usado / dependiente: Go 1.12.9, etcd 3.3.15, CoreDNS 1.6.2.
PS
Lea también en nuestro blog: