CQM es una mirada diferente en el aprendizaje profundo para optimizar las búsquedas en lenguaje natural
Descripción breve: La malla cuántica calibrada (CQM) es el siguiente paso de RNN / LSTM (redes neuronales recurrentes) / memoria a largo plazo (LSTM). Hay un nuevo algoritmo llamado Calibrated Quantum Mesh (CQM), que promete aumentar la precisión de las búsquedas en lenguaje natural sin el uso de datos de entrenamiento etiquetados.
Se ha creado un algoritmo completamente nuevo de búsqueda del lenguaje natural (NLS) y comprensión del lenguaje natural (NLU), que no solo supera los algoritmos tradicionales RNN / LSTM o incluso CNN, sino que también es de autoaprendizaje y no requiere datos marcados para el entrenamiento.
Parece demasiado bueno para ser verdad, pero los resultados iniciales son impresionantes. CQM - desarrollado por Praful Krishna y su equipo en Coseer (San Francisco).
Aunque la compañía aún es pequeña, trabajan con varias compañías de Fortune 500 y han comenzado a celebrar conferencias técnicas.
Aquí es donde esperan demostrar su valía:
Precisión: según Krishna, la función NLS promedio en un chatbot menos serio, por regla general, tiene una precisión de solo un 70%.
Las aplicaciones iniciales de Coseer lograron una precisión de más del 95% al devolver la información relevante correcta. No se requieren palabras clave.
No se requieren datos de entrenamiento etiquetados: Todos sabemos que los datos de entrenamiento etiquetados son un gasto financiero y de tiempo que limita la precisión de nuestros bots de chat.
Hace unos años M.D. Anderson abandonó su costoso experimento de años con IBM Watson para la oncología debido a la precisión.
Lo que frenaba la precisión era la necesidad de investigadores de cáncer con mucha experiencia para anotar documentos en el recinto. Deberían haber hecho esto en lugar de hacer su investigación.
Velocidad de implementación: Coseer dice que sin datos de capacitación, la mayoría de las implementaciones pueden iniciarse dentro de 4 a 12 semanas. Esto es mucho menor que cuando el usuario comienza a usar un sistema pre-entrenado, cuya operación comienza con la carga preliminar de documentos marcados.
Además, a diferencia de los grandes proveedores actuales que utilizan algoritmos tradicionales de aprendizaje profundo, Coseer prefiere implementarlos en una nube segura y privada para garantizar la seguridad de los datos.
Toda la "evidencia" utilizada para llegar a una conclusión se almacena en una revista que se puede utilizar para demostrar la transparencia y el cumplimiento de las normas de seguridad de datos, como el RGPD.
Como funciona
Coseer habla sobre los tres principios que definen CQM:
1. Las palabras (variables) tienen diferentes significados.
Considere la palabra "horno", que puede ser un sustantivo o un verbo. Por ejemplo, "verso", que puede significar "poema" o el verbo "viento de verso", estas son las palabras homónimas.
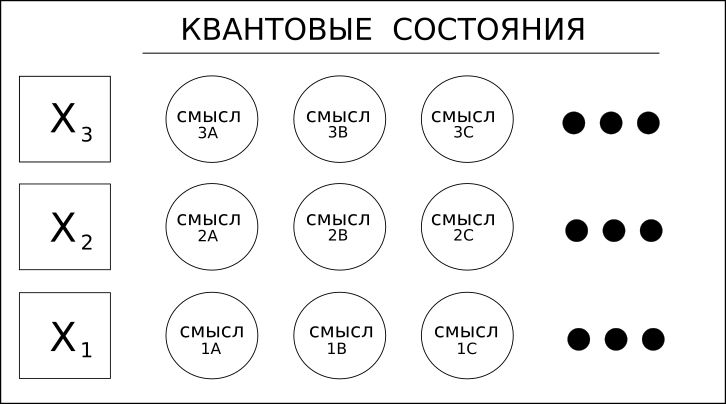
Las soluciones de aprendizaje profundo, que incluyen RNN / LSTM o incluso CNN para texto, solo pueden mirar hacia adelante o hacia atrás para determinar el "contexto" de una palabra y así determinar su significado.
Coseer tiene en cuenta todos los significados posibles de la palabra y aplica probabilidad estadística a cada uno de ellos en función de todo el documento o corpus.
El uso del término "cuántico" en este caso se refiere solo a la posibilidad de múltiples valores, y no a una superposición más exótica de la computación cuántica.
2. Todo está interconectado en una cuadrícula de valores:
Extraer de todas las palabras disponibles (variables) todas sus posibles relaciones es el segundo principio.
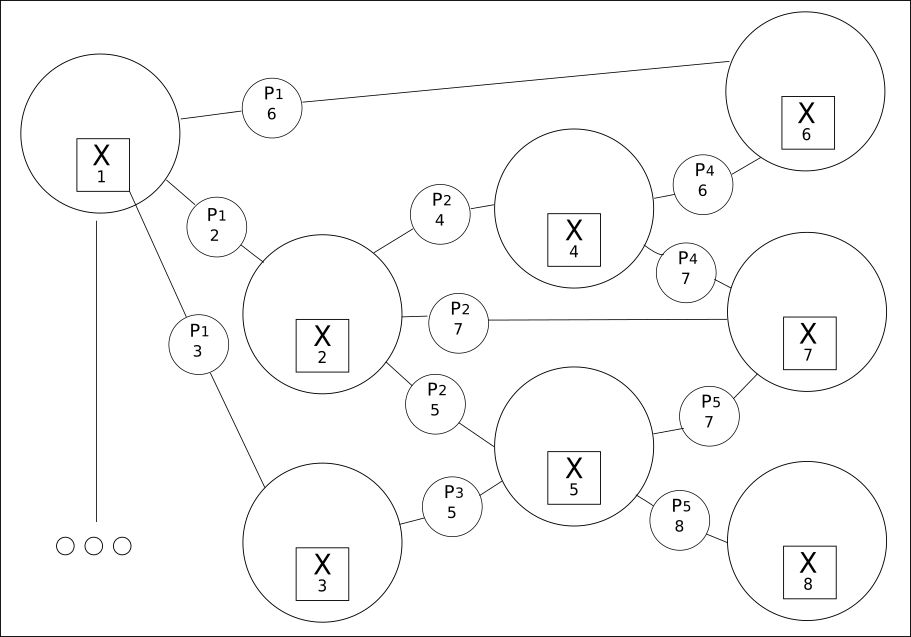
CQM crea una cuadrícula de valores posibles, entre los cuales se encontrará un valor real. El uso de este enfoque revela una relación mucho más amplia entre las frases anteriores o posteriores que la que ofrece Deep Learning tradicional.
Aunque el número de palabras puede ser limitado, sus relaciones pueden ser de cientos de miles.
3. Toda la información disponible se utiliza secuencialmente para combinar la cuadrícula en un solo valor. Este proceso de calibración identifica rápidamente las palabras o conceptos faltantes y proporciona una capacitación muy rápida y precisa.
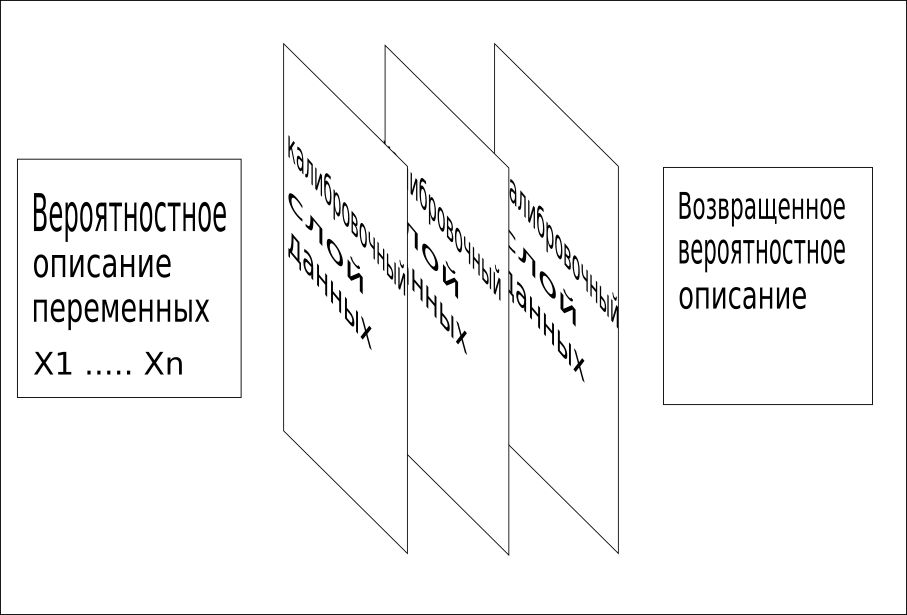
Los modelos CQM utilizan datos de capacitación, datos de contexto, datos de referencia y otros hechos conocidos sobre el problema para identificar estas capas de datos de calibración.
Desafortunadamente, Coseer ha publicado muy poco en el dominio público para explicar los aspectos técnicos del algoritmo.
Cualquier avance en la eliminación de datos marcados durante el entrenamiento debe ser bienvenido y, por supuesto, mejorar la precisión conducirá al hecho de que los clientes mucho más satisfechos usarán su bot de chat.