Hola Me llamo Nikita Uchetelev. Represento a Lamoda Research & Development. Somos más de 20 personas y estamos trabajando en varias recomendaciones en el sitio y en las aplicaciones, estamos desarrollando una búsqueda, determinamos la clasificación de los productos en los catálogos, brindamos la posibilidad de realizar pruebas AB de diversas funcionalidades y también apoyamos varios desarrollos internos como un sistema para pronosticar la elasticidad de la demanda y optimizar la logística de entrega.
Una de las principales direcciones de desarrollo de toda la empresa para los próximos años es la personalización de nuestros productos y servicios. Dichas iniciativas se prueban e implementan en todas partes, desde compilar selecciones de productos personales hasta elegir un representante de ventas específico que le entregará nuestros productos. Como parte del proceso de personalización de productos de I + D, actúo como líder de equipo y en este artículo quiero hablar sobre la plataforma que yo y mi equipo hemos estado diseñando y desarrollando durante el último año, así como sobre los primeros productos de I + D personalizados que actualmente se someten a pruebas AB.
Ideología de recomendaciones de productos.
El atributo de cualquier tienda en línea familiar para todos es la página del producto. Por lo general, ofrece una descripción detallada, varias fotos grandes, reseñas de clientes, el botón "Agregar al carrito" y otros elementos de navegación familiares. En la parte inferior de dichas páginas hay uno o más estantes con otros productos llamados "Productos relacionados", "Comprar con este producto" o algo más. Cada estante tiene su propio propósito.
Por ejemplo, un estante con productos similares está diseñado para ofrecer al usuario una variedad adicional de productos en el contexto actual de elección. Esto puede ser útil si no hay un tamaño de usuario en el stock, o si está en la etapa de selección y quiere el mismo producto, pero "con botones de perlas". Al mismo tiempo, el estante aleja al comprador de la página del producto, a la que ya no puede regresar y, en consecuencia, no lo compra.
Hay un segundo estante en el sitio web y en las aplicaciones de Lamoda, que llamamos el estante de recomendaciones cruzadas . Está ubicado inmediatamente debajo del estante con productos similares, y tratamos de colocar en él productos diferentes que se encuentran con mayor frecuencia en los carritos de compras junto con el SKU actual (Unidad de mantenimiento de existencias o, más simplemente, artículo). Entonces, por ejemplo, se recomiendan pantalones y zapatos para chaquetas, bufandas y sombreros para suéteres. Hay un grupo de bienes económicos que se compran con mayor frecuencia. Como regla general, estos son calcetines y ropa interior, por lo que a menudo se pueden ver en este estante.
Esta técnica de venta es similar al upsale . Estamos tratando de vender algunos productos complementarios grandes, siempre que al usuario le guste el producto actual. Al mismo tiempo, este es uno de los pocos lugares donde los clientes pueden conocer nuestra gama. Por ejemplo, para ver una marca o subcategoría, cuya presencia no conocían antes. Lo llamamos inspiración y descubrimiento : cuando inspiramos a los clientes para que realicen nuevas compras y nos dicen cuán amplio es nuestro rango, mostramos precios y descuentos.

Históricamente, el llenado de estos estantes se calcula fuera de línea (con un margen, en caso de que algunos bienes se agoten antes del siguiente cálculo) junto con la clasificación por alguna conversión de métrica o condicional de similitud. Por lo tanto, todos los usuarios ven allí aproximadamente lo mismo durante el día. Decidimos comenzar experimentos con personalización precisamente desde estos estantes, porque en las páginas de productos tenemos suficiente tráfico para realizar experimentos de calidad. Desde un punto de vista técnico, este resultó ser uno de los lugares más convenientes para la implementación en nuestra infraestructura (marcado en rojo en el diagrama).

La idea es esta : entrenamos un modelo que puede asignar los pares "usuario + producto" a la probabilidad de conversión o simplemente un clic, y luego mostrarlos en el estante de izquierda a derecha en orden descendente de esta probabilidad. Dado que solo se muestran de 4 a 6 SKU en la primera pantalla del carrusel, dependiendo de la resolución de la pantalla, y en total podemos calcularlos, digamos, hasta cientos, se logra una "profundidad" de personalización bastante aceptable.
Resolvemos el problema desde el final
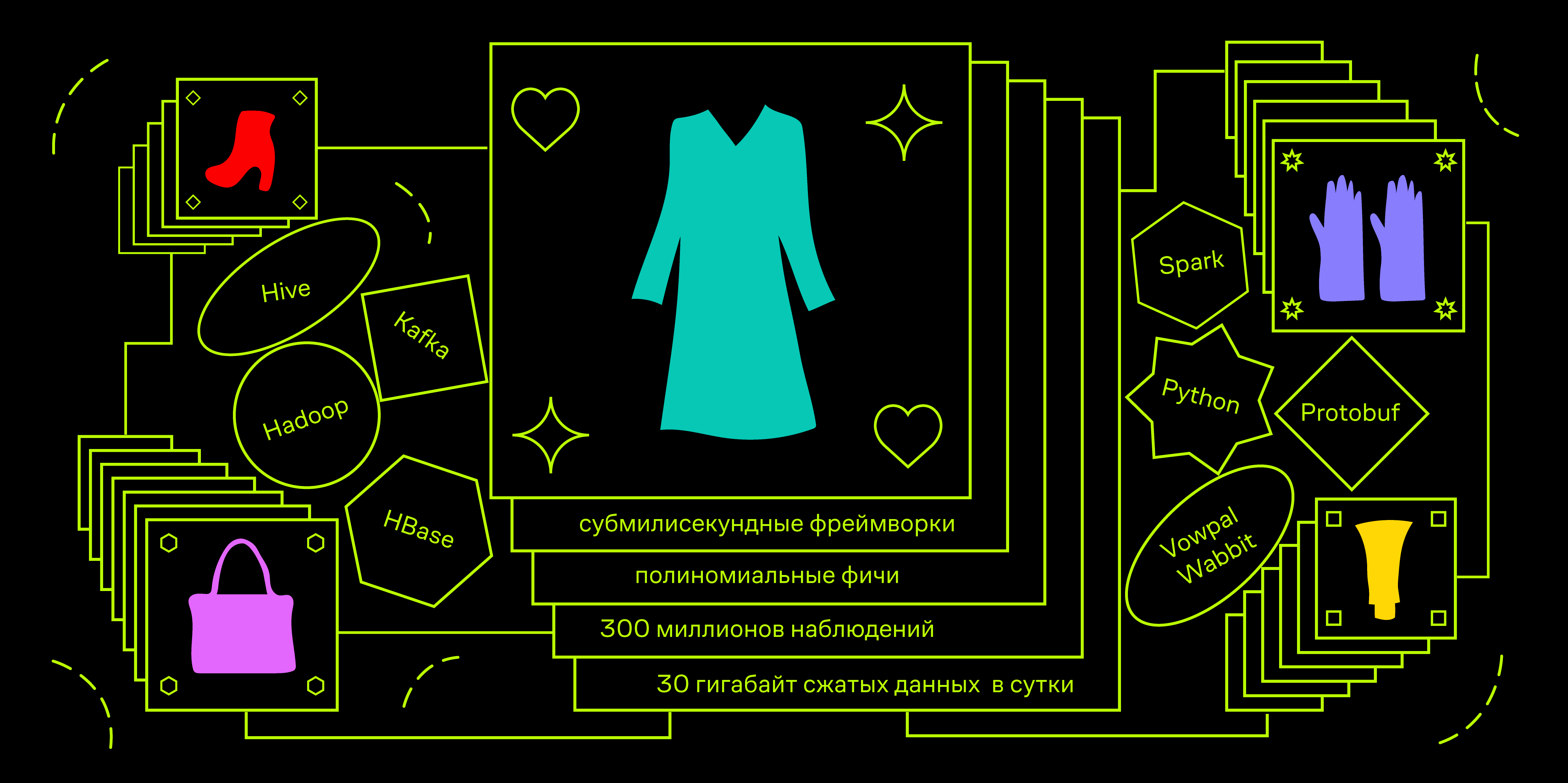
Pasemos a la parte técnica. Tenemos limitaciones en el tiempo de respuesta de la API. Por ejemplo, en aplicaciones, el servicio futuro deberá estar a tiempo para ser responsable de 100 ms. Durante este tiempo, debe ir a diferentes bases de datos para datos de usuarios y productos, organizar cientos de ejemplos con una carga de hasta 100 QPS en el pico. Esto nos lleva a la necesidad de usar marcos de aprendizaje automático por debajo de milisegundos. Uno de los más famosos es Vowpal Wabbit.
Un campo de aplicación típico para este marco es adtech, es decir, predecir el CTR de un anuncio cuando se optimiza una oferta para una subasta RTB. Desde un punto de vista matemático, podemos plantear un problema similar. Supongamos que queremos predecir la probabilidad de un clic entrenando un modelo en las pantallas de productos. La carga en el modelo de hasta 10k QPS es comparable al rendimiento publicitario y, en general, justifica la necesidad de limitarse solo a algoritmos lineales en la etapa de creación de prototipos y MVP.
Ahora pensemos en qué datos del usuario pueden contener la señal que necesitamos y distingamos bien entre los usuarios. Como estamos hablando de recomendaciones de productos y la página del producto que visita el usuario, lo más probable es que esté en la etapa de selección. Tiene en su cabeza cierta imagen de "zapatos perfectos" con la que compara todos los productos que llaman su atención. Primero, vaya al catálogo de productos de la categoría deseada y comience la búsqueda haciendo clic en todo lo que más o menos se parezca a su presentación. Por lo tanto, el usuario se reserva un "rastro digital" de los productos vistos. Según la unidad en este camino, haremos personalización.
Representaciones vectoriales de objetos.
Todos los productos difieren entre sí con valores tabulares de algunos atributos: color, materiales, telas, tipo de impresión, longitud de la manga, presencia de una capucha, altura del talón, etc. En consecuencia, es posible codificar cualquier rastro digital con fracciones de ocurrencia de cada uno de los valores de estos atributos. Supongamos que tenemos productos en tres colores y tres marcas que puede ver y poner en la cesta. Luego, tomando el historial de las acciones de un usuario, puede hacer coincidir un vector de la siguiente forma:

En este caso, el usuario miró 10 productos: 5 dorados, 2 negros y 3 rojos. Y agregó 2 rojos y 2 negros a la canasta, no agregó oro. De manera similar con las marcas A, B y C, así como con cualquier valor de atributo. Además, dicho vector se puede concatenar con un vector codificado en caliente de valores de atributo para un producto particular.
Por lo tanto, podemos vectorizar un evento específico. Un usuario que, en el marco de la sesión actual, ha examinado una serie de productos con una distribución de colores dada, se está preparando para ver algún producto nuevo, por ejemplo, el rojo. Utilizando datos históricos sobre impresiones y clics, puede crear un modelo que prediga la probabilidad de un clic en un producto rojo, siempre que tenga una distribución de color existente para los productos vistos anteriormente.
Si observa el espacio en el que hemos aprendido a mostrar camarillas históricas, puede ver que una parte está ocupada por un subespacio binario y la otra es real, y no están conectadas entre sí. Nuestro modelo lineal en este caso es una combinación lineal (suma ponderada) de las coordenadas de puntos en este espacio. Si ella aprende de tales ejemplos, simplemente aprenderá las probabilidades a priori. Por ejemplo, el peso frente a la coordenada correspondiente al color rojo de los productos será un valor directamente proporcional al CTR de los productos rojos. Por lo tanto, las coordenadas específicas del usuario serán ponderadas por las características de frecuencia de los clics de diferentes usuarios para cualquier producto del catálogo. Pero esto no es exactamente lo que nos gustaría.
Las características polinomiales vienen al rescate: el resultado de la multiplicación de todas las cantidades binarias con todas las reales. El marco Vowpal Wabbit tiene una herramienta poderosa para generar características de poder a partir de espacios de nombres. Intentemos componer una cadena en formato vw para nuestro ejemplo, distribuyendo las características de usuario y de productos básicos en diferentes espacios de nombres.
|user_color :0.5 :0.2 :0.3 |product_color
Ahora, si durante el entrenamiento agregamos el modificador -q pu , aparecerán tales características cuadráticas distintas de cero:
user_color^ * product_color^ = 0.5 user_color^ * product_color^ = 0.2 user_color^ * product_color^ = 0.3
Por lo tanto, el modelo está buscando una señal no solo de cómo los usuarios hacen clic con una alta proporción de productos rojos vistos, sino también de cómo hacen clic en los productos rojos. El peso de tal característica en el modelo entrenado debe ser positivo y bastante grande.
Este enfoque de la ingeniería de características aumenta dramáticamente la dimensión del espacio en el que se lleva a cabo la capacitación. En una situación en la que solo tenemos 4 colores, la dimensión de este espacio es 8 (4 colores para el producto y 4 para el usuario). Con la adición de 16 atributos cuadráticos, aumenta a 24. En la producción, además de los colores, utilizamos 13 atributos más de los productos, incluida, por ejemplo, la marca. Por lo tanto, la dimensión total del espacio en el que trabajan nuestros modelos puede ser de hasta 3 millones de características. Al mismo tiempo, queremos mantener la relación entre el número de ejemplos de entrenamiento y la dimensión del espacio en el nivel de 1: 100. Para hacer esto, necesitamos generar un total de aproximadamente 300 millones de observaciones.
Almacenamos el flujo de clics de nuestros usuarios en Hadoop (Spark Streaming de Apache Kafka a una tabla Hive). Por lo general, recibimos alrededor de 30 gigabytes de datos comprimidos por día; esto es más de cien tipos diferentes de acciones que los usuarios pueden realizar en el sitio y en las aplicaciones, incluida la exhibición de productos en varias ubicaciones.
También para los estantes de recomendaciones hay información sobre qué productos se mostraron y dónde se hizo el clic. Nuestra tarea para cada clic en el pasado es calcular el estado del usuario en términos de las proporciones de las fracciones de los valores de los atributos de los productos vistos en el momento anterior al clic dado. Luego, la concatenación del par de vectores “usuario” + “producto en el que se hizo clic” dará un ejemplo de entrenamiento positivo, y pares similares con productos mostrados al lado en el estante, pero sin clics, serán ejemplos negativos. Es importante que los productos se muestren cerca. Entonces podemos estar seguros de que el usuario los vio, pero no hizo clic. Como beneficio adicional, con tales mecanismos podemos controlar la proporción de clases en el problema.
Nuestra solución es la agregación diaria de datos de usuario utilizando Spark y la carga incremental de estos datos en HBase. Considere la estructura de tal agregado.
Entonces, el objeto principal en esta tarea es el usuario. Las sesiones están asociadas con él, que consisten en una secuencia de acciones, cada una de las cuales tiene ciertas características dependiendo del tipo de acción. Por ejemplo, si se trata de ver una página de producto, el número de artículo y el tiempo de visualización del producto pertenecen a los atributos que necesitamos. Como reserva para el futuro, escribimos inmediatamente en el registro la disponibilidad de bienes en stock y dos precios: el base y teniendo en cuenta las existencias y los cupones personales. No necesitamos impresiones por separado, por lo tanto, sobre la marcha en el momento de la agregación, se atribuyen a los clics y generan un nuevo tipo de evento en el que, además del campo con el número de artículo del producto donde se realizó el clic, también hay una variedad de varios artículos que lo rodean en el momento de la visualización.
HBase es una base de datos de columnas versionadas con una interfaz nativa para conectarse a Spark para el procesamiento por lotes y con la capacidad de acceder a los datos por clave. Otra característica es que HBase carece del concepto de circuito. Solo puede almacenar bytes, o más bien compensaciones, dentro de HFiles especiales que están adaptados a la estructura de bloques HDFS.
Algunos pueden encontrar controvertido elegir un repositorio, pero tuve una buena experiencia trabajando con HBase en proyectos similares. Además, en Lamoda esta base de datos ya se usa activamente, por lo que no nos cuesta nada usar un sistema ya implementado para MVP. No usamos la funcionalidad de versiones en este momento, pero el acceso por clave parecía útil para la posibilidad de capacitación multiproceso de modelos en el futuro y la organización de la arquitectura lambda para cargar datos y otros casos en tiempo real.
Como no hay ningún esquema en HBase, necesitamos nuestro propio contenedor de datos. Podrías usar lambda x: json.dumps (x) .encode () , pero quería algo más rápido. Una solución completamente estándar es usar recipientes protobuf. Dado que el desarrollo de todo el proyecto se lleva a cabo en python, es más habitual que use la biblioteca pyrobuf personalizada de AppNexus en lugar de la oficial de Google. Por puntos de referencia, el rendimiento de la funcionalidad básica de protobuffs es varias veces mayor que el original. El esquema aproximado de nuestro protobuff es el siguiente:
enum Location { ru = 1; by = 2; ua = 3; kz = 4; special = 5; } enum Platform { desktop = 1; mobile = 2; a_phone = 3; a_tablet = 4; iphone = 5; ipad = 6; } message Action { enum ActionType { pageview = 1; quickview = 2; rec_click = 3; catalog_click = 4; fav_add = 5; cart_add = 6; order_submit = 7; } required uint64 ts = 1; required ActionType action_type = 2; optional string sku = 3; required bool is_office = 4; repeated string skus = 5; optional uint32 delta = 6; optional string sku_source = 7; optional bool stock = 8; optional uint32 base_price = 9; optional uint32 price = 10; optional string type = 11; } message Session { required string session_id = 1; repeated Action actions = 2; required uint64 session_start = 3; required uint64 session_end = 4; optional uint32 actions_count = 5; } message LID { required string uid = 1; repeated Session sessions = 2; required Location location = 3; required Platform platform = 4; optional uint32 sessions_count = 5; }
En resumen, hay un objeto "Usuario" (LID, ID de Lamoda). En su interior hay una matriz de objetos "Sesión", cada uno de los cuales es una matriz de objetos "Acción". Dividimos las acciones por tipo y las almacenamos en diferentes familias de columnas, lo que nos permite optimizar un poco la lectura cuando solo necesitamos eventos de ciertos tipos (vistas de productos, clics atribuidos a diferentes tipos de recomendaciones, etc.).
Prueba
Durante tres semanas realizamos una prueba AB en el sitio de escritorio lamoda.ru con el siguiente diseño:
- Control: las recomendaciones de API se refieren al servicio de personalización, espera el resultado, pero entrega los productos en el orden original, lo mismo para todos.
- Prueba: los productos se muestran de izquierda a derecha en orden descendente de pronóstico de probabilidad de clics.
La división en dos opciones se basa en la LID del usuario, esencialmente por su cookie. Nuestra plataforma experimental garantiza que las observaciones recopiladas en dos versiones sean independientes y estén distribuidas de manera uniforme, y los cambios métricos se evalúan con un nivel de significación del 5% (valor p 0.05). Como resultado, recibimos + 10% CTR de todo el estante y un cambio positivo significativo en los ingresos. La semana pasada, implementamos esta funcionalidad para todos los usuarios del sitio.
Para verificar la personalización de usted mismo, simplemente mire varios productos diferentes y luego compare la clasificación de las recomendaciones en uno de los estantes "Ellos compran este producto" en dos navegadores diferentes o use el modo "Incógnito". Por supuesto, si no ha visitado nuestro sitio antes, todavía hay pocos datos sobre usted en la plataforma. Intente elegir una chaqueta de invierno y compare el orden de los productos nuevamente después de un tiempo.
Así que obtuvimos una plataforma completa: un conjunto de herramientas de software que agregan datos y los almacenan, así como un marco para vectorizar objetos de negocios en un punto arbitrario en el pasado, que le permite construir modelos de puntaje para evaluar la probabilidad de varias acciones. La interferencia del modelo se proporciona a través de un servicio web que puede recopilar vectores relevantes de varias fuentes de datos y ejecutarlos a través del modelo. Acepta el LID (identificador de usuario), la lista de SKU que deben escanearse y diversa información adicional, devolviendo la misma lista de productos a las predicciones con muchos clics. A continuación se muestra un diagrama de la arquitectura conceptual de nuestra plataforma:

El elemento ML Core es un conjunto de máquinas virtuales en las que están instalados los clientes de Hadoop y los trabajadores de Airflow. Establecemos la configuración, con qué parámetros entrenar el modelo, dónde obtener datos históricos, etc. Como resultado, el modelo se entrena y se publica en artefactos, y la información sobre el proceso de aprendizaje y las métricas de calidad que nos interesan se almacenan en el meta repositorio.
Ya estamos probando o preparando pruebas del sistema de personalización de recomendaciones en las listas de correo, en las páginas principales y en el estante con recomendaciones para productos similares, segmentos similares para dirigir publicidad interna y externa y mucho más.
Este fue un artículo introductorio. En publicaciones posteriores, puedo concentrarme en los aspectos técnicos de la arquitectura y hablar sobre su desarrollo o, por el contrario, expandir el componente del producto de manera más amplia y decir cómo usamos y evaluamos el LD en las tareas del producto. Escriba en los comentarios sus deseos sobre esto.