Recientemente, VTB ha cambiado algunos de los componentes de hardware y software del sistema de flujo de trabajo. Los cambios fueron demasiado significativos para continuar trabajando sin pruebas de carga a gran escala: cualquier problema con el sistema de soporte de documentos (LMS) está plagado de grandes pérdidas.

Los especialistas de Intertrust probaron VTB SDO en equipos Huawei: un complejo de granja de servidores, red de datos y almacenamiento basado en unidades de estado sólido. Para las pruebas, creamos un entorno que reproducía escenarios reales con la carga máxima posible. Resultados y conclusiones - debajo del corte.
¿Por qué necesitamos un sistema de flujo de trabajo en un banco y por qué probarlo?
LMS en VTB es un paquete de software complejo, en el que están vinculados todos los procesos de gestión de claves. El sistema proporciona servicios de documentación general, interacción electrónica, análisis. Una circulación de documentos debidamente organizada acelera las decisiones de gestión, hace que el proceso de su adopción sea transparente y controlado, mejora la calidad de la gestión y mejora la competitividad del banco.
El LMS debe garantizar una implementación clara de las decisiones de acuerdo con las regulaciones establecidas. Esto requiere alto rendimiento, tolerancia a fallas, escalado flexible. El sistema tiene altos requisitos para el control de acceso, el volumen de documentos procesados simultáneamente y la cantidad de usuarios. Ahora hay 65 mil de ellos en VTB SDO, y este número continúa creciendo.
El sistema está en constante evolución: la arquitectura está cambiando, las tecnologías obsoletas están siendo reemplazadas por otras modernas. Y recientemente, algunos de los componentes del sistema fueron reemplazados por componentes independientes de importación, sin software propietario. ¿La nueva arquitectura SDO basada en el software CompanyMedia y el complejo de hardware de Huawei manejarán el aumento de carga? Responda inequívocamente a esta pregunta, sin esperar una situación similar en la realidad, solo fue posible con la ayuda de pruebas de estrés.
Además de probar el nuevo producto de software para la resistencia al estrés, tuvimos las siguientes tareas:
- determinar los parámetros exactos del tamaño horizontal y vertical de los servidores para el perfil de carga bancaria;
- verificar los componentes para tolerancia a fallas bajo condiciones de alta carga;
- para identificar el coeficiente de entropía de interacción entre grupos con escala horizontal;
- intente escalar solicitudes de lectura cuando use el equilibrador de plataforma;
- determinar el coeficiente de escala horizontal de todos los nodos y componentes del sistema;
- determinar los parámetros de hardware máximos posibles de los servidores para diversos fines funcionales (escala vertical);
- estudiar el perfil de carga de la aplicación en la infraestructura técnica, para aproximar los resultados para planificar el desarrollo del sistema de información;
- Investigue el impacto de la consolidación de datos de aplicaciones en un único sistema de almacenamiento de datos en la optimización de recursos, mejorando la confiabilidad y el rendimiento.
Metodología y equipamiento
Las pruebas de carga de los sistemas de gestión de documentos electrónicos a menudo se llevan a cabo de acuerdo con escenarios simplificados. Simulan la búsqueda rápida y la apertura de tarjetas de documentos que no están asociadas con otros archivos y que no tienen un historial de ciclo de vida. En este caso, por regla general, nadie tiene en cuenta los derechos de acceso y otros factores que consumen recursos característicos de las condiciones reales.
A menudo, estas pruebas de divorcio son realizadas por proveedores de soluciones. Es comprensible: es importante que un proveedor demuestre a un cliente potencial el alto rendimiento y la velocidad del sistema. No es sorprendente que los modelos de prueba simplificados muestren tiempos de respuesta récord del sistema, incluso si el número de usuarios y documentos aumenta significativamente.
Necesitábamos reproducir las condiciones operativas reales. Por lo tanto, al principio, recopilamos estadísticas durante un mes: registramos la actividad del usuario, observamos el trabajo de fondo de todos los servicios. Los sistemas de monitoreo integrados en el LMS se convirtieron en una gran ayuda en este asunto. Los empleados del banco ayudaron a corregir los datos resultantes en los flujos de documentos, mientras que realizamos ajustes para el crecimiento proyectado en los flujos.
El resultado fue una metodología de prueba, con la ayuda de la cual fue posible simular los procesos que ocurren en el sistema, teniendo en cuenta todas las cargas reales. En el banco de pruebas, reprodujimos, individualmente y en varias combinaciones, las operaciones comerciales más comunes, así como las solicitudes que requieren más tiempo. Durante las pruebas de rendimiento, todos los componentes fueron sometidos a estrés. Se realizaron operaciones para calcular los derechos de acceso de los usuarios a los objetos del sistema, abrir documentos con una jerarquía ramificada compleja y una gran cantidad de enlaces, buscar en el sistema, etc.
Perfil de prueba de carga:
- usuarios registrados: 65 mil con un aumento de hasta 150 mil;
- frecuencia de inicios de sesión de usuarios (autenticaciones): 50 mil por hora;
- usuarios que trabajan simultáneamente en el sistema: 10 mil;
- documentos registrados: 10 millones por año;
- volumen de archivos adjuntos: 1 TB por año;
- procesos de aprobación de documentos: 1,5 millones por año;
- visas de las partes del acuerdo: 7.5 millones por año;
- resoluciones e instrucciones: 15 millones por año;
- informes sobre resoluciones e instrucciones: 15 millones por año;
- tareas de usuario: 18 millones por año.
Estas aplicaciones se consolidaron en un solo sistema de almacenamiento Huawei OceanStor Dorado 6000 V3 con 117 unidades SSD de 3.6 TB cada una, el volumen total utilizable es más de 300 TB. La potencia de cálculo se colocó en el sistema de servidor modular de Huawei E9000, y los datos se transmitieron a través de la red en función de los conmutadores del nivel del centro de datos de la serie Huawei CE. Durante la prueba, observamos durante todo el día todos los indicadores del sistema. Todos los resultados, incluidos los datos históricos, se registraron en forma de gráficos y tablas para su posterior análisis.
Servidores de infraestructura de hardware de prueba de carga
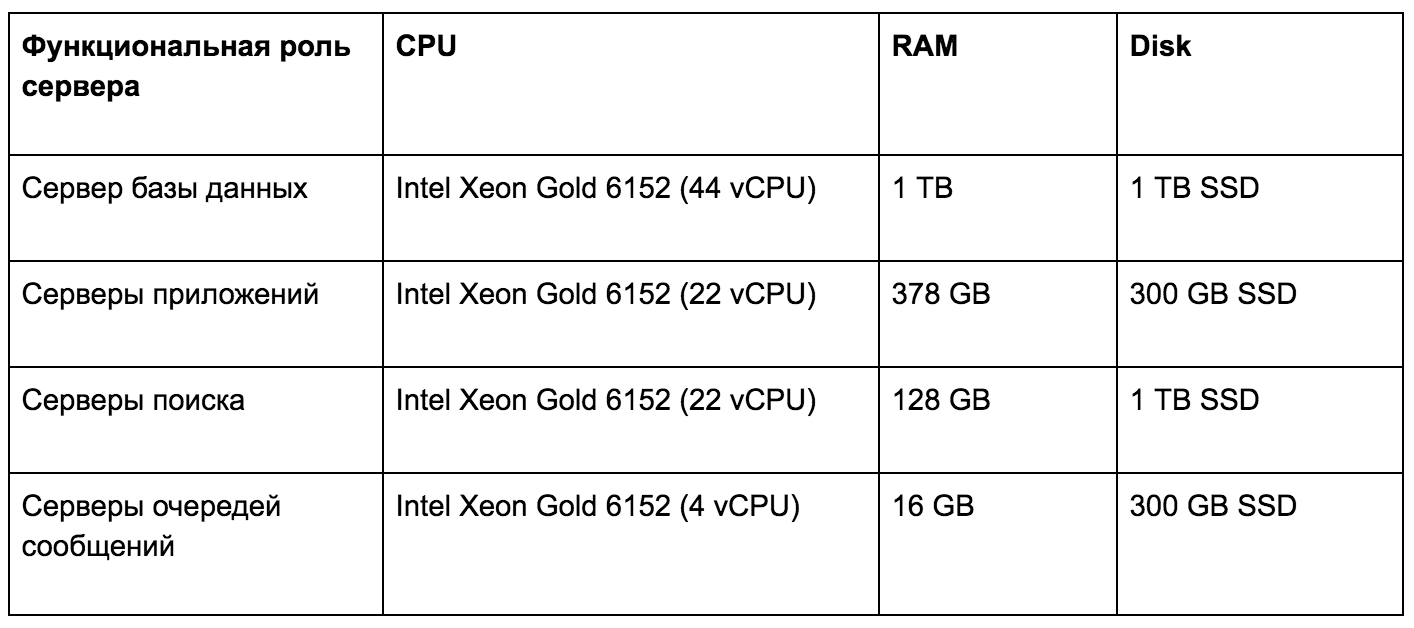

Debido al alto rendimiento del sistema de almacenamiento Huawei OceanStor Dorado 6000 V3, los retrasos al realizar cualquier solicitud del usuario rara vez superan 1 ms. Esta velocidad del subsistema de disco de la aplicación nos inspiró a seguir investigando. Decidimos, al analizar datos históricos, determinar el efecto de varios tipos de cargas de trabajo en la infraestructura técnica. Los resultados obtenidos nos permiten planificar de manera flexible y precisa el desarrollo del sistema de acuerdo con los requisitos para la plataforma de hardware.
En términos de escala, verificamos:
- límite de escalado vertical del servidor de aplicaciones (CMJ) , recursos críticos: número de núcleos y frecuencia, cantidad de RAM;
- soporte para escalado horizontal del servidor de aplicaciones (CMJ) mediante la duplicación de servicios funcionalmente idénticos y el equilibrio entre ellos;
- límites de escala vertical y horizontal del servidor del cliente (Web-GUI) ;
- límites de escala vertical del almacenamiento de archivos (FS) , recursos críticos: ancho de banda de red, velocidad de disco;
- soporte para escalado horizontal del almacenamiento de archivos (FS) debido al sistema de archivos distribuido - CEPH, GLUSTERFS;
- límites de escalado vertical de la base de datos (PostgreSQL) , recursos según el grado de criticidad: capacidad de RAM, velocidad de disco, número de núcleos y frecuencia;
- soporte para el escalado horizontal de la base de datos (PostgreSQL) : escalar la carga de lectura en servidores esclavos, escalar la carga de escritura según el principio de dividir en módulos funcionales;
- límites de escala vertical y horizontal del intermediario de mensajes (Apache Artemis) ;
- límites de escala vertical y horizontal del servidor de búsqueda (Apache Solr) .
Problemas y soluciones
Una de las tareas principales era identificar posibles problemas con el rendimiento del LMS. Durante el trabajo, se identificaron los siguientes cuellos de botella y se encontraron formas de abordarlos.
Bloquea el registro sincrónico. Las operaciones de registro en la configuración estándar de WildFly se realizan sincrónicamente y afectan en gran medida el rendimiento. Se decidió cambiar a un registrador asíncrono y, al mismo tiempo, escribir no en un disco, sino en el sistema de agregación de registros ELK.
Inicialización de sesiones innecesarias cuando se trabaja con un almacén de datos. Cada subproceso que recibió datos del repositorio inicializó dos veces una sesión para autenticación en modo SSO. Esta operación requiere muchos recursos y aumenta en gran medida el tiempo de ejecución de la solicitud del usuario, y también reduce el rendimiento general del servidor.
Se bloquea al trabajar con objetos de caché de aplicaciones. La aplicación usó bloqueos reentrantLock bastante pesados (Java 7), que afectaron negativamente la velocidad de ejecución de la consulta. El tipo de bloqueo se cambió a stampedLock, lo que redujo significativamente el tiempo dedicado a trabajar con objetos de caché.
Después de eso, nuevamente lanzamos pruebas de carga para determinar el tiempo promedio de operaciones típicas en el sistema LMS con almacenamiento relacional en el perfil del banco. Obtuvimos los siguientes resultados:
- autorización de usuario en el sistema - 400 ms;
- viendo el progreso en promedio - 2.5 s;
- creación de una tarjeta de registro y control - 1.4 s;
- registro y registro de tarjeta de control - 600 ms;
- creación de una resolución - 1 p.
Conclusiones
Además de identificar problemas, las pruebas de estrés han confirmado algunos de nuestros supuestos.
- El sistema funciona mucho mejor en la familia de sistemas operativos Linux.
- Los principios declarados para garantizar la tolerancia a fallos funcionan a nivel de cada componente en modo "activo".
- Un componente clave, el servicio de lógica de negocios (que acepta las solicitudes de los usuarios), tiene una escala horizontal "espejo" y una escala de rendimiento casi lineal con un aumento en el número de instancias.
- Dimensionamiento óptimo del servicio de lógica de negocios para 1200 usuarios simultáneos: 8 vCPU para el servicio y 1.5 vCPU para el DBMS.
- La consolidación de los datos de la aplicación en un solo sistema de almacenamiento aumenta significativamente la productividad y la confiabilidad, aumenta la escalabilidad.
Estaremos encantados de responder sus preguntas en los comentarios; tal vez le interese aprender más sobre algunos aspectos de las pruebas.