Introduccion
Hace unos años, decidimos que era hora de admitir el código SIMD en .NET . Introdujimos el espacio de nombres System.Numerics con los tipos Vector2 , Vector3 , Vector4 y Vector<T> . Estos tipos representan una API de propósito general para crear, acceder y manipular instrucciones vectoriales siempre que sea posible. También proporcionan compatibilidad de software para aquellos casos en los que el hardware no admite instrucciones adecuadas. Esto permitió, con una refactorización mínima, vectorizar varios algoritmos. Sea como fuere, la generalidad de este enfoque hace que sea difícil de aplicar para aprovechar al máximo todas las instrucciones vectoriales disponibles en el hardware moderno. Además, el hardware moderno proporciona una serie de instrucciones especializadas, no vectoriales, que pueden mejorar significativamente el rendimiento. En este artículo, hablaré sobre cómo eludimos estas limitaciones en .NET Core 3.0.

Nota: Todavía no hay un término establecido para la traducción de Intrisics . Al final del artículo hay un voto para la opción de traducción. Si elegimos una buena opción, cambiaremos el artículo.
¿Cuáles son las funciones integradas?
En .NET Core 3.0, agregamos una nueva funcionalidad llamada funciones integradas específicas de hardware (WF lejano). Esta funcionalidad proporciona acceso a muchas instrucciones de hardware específicas que no pueden representarse simplemente mediante mecanismos de propósito más general. Se diferencian de las instrucciones SIMD existentes en que no tienen un propósito general (los nuevos WF no son multiplataforma y su arquitectura no proporciona compatibilidad de software). En cambio, proporcionan directamente la plataforma y la funcionalidad específica del hardware para los desarrolladores de .NET. Las funciones SIMD existentes, por ejemplo, multiplataforma, proporcionan compatibilidad de software, y se abstraen ligeramente del hardware subyacente. Esta abstracción puede ser costosa, además, puede evitar la divulgación de alguna funcionalidad (cuando, por ejemplo, la funcionalidad no existe o es difícil de emular en todas las plataformas de destino).
Las nuevas funciones integradas y los tipos compatibles se encuentran en el System.Runtime.Intrinsics . Para .NET Core 3.0, por el momento, hay un System.Runtime.Intrinsics.X86 . Estamos trabajando para admitir funciones integradas para otras plataformas como System.Runtime.Intrinsics.Arm .
Bajo espacios de nombres específicos de la plataforma, los WF se agrupan en clases que representan grupos de instrucciones de hardware lógicamente integradas (a menudo llamadas arquitectura de conjunto de instrucciones (ISA)). Cada clase proporciona una propiedad IsSupported indica si el hardware en el que se ejecuta el código admite este conjunto de instrucciones. Además, cada clase contiene un conjunto de métodos asignados a un conjunto correspondiente de instrucciones. A veces hay una subclase adicional que corresponde a una parte del mismo conjunto de instrucciones, que puede estar limitada (admitida) por hardware específico. Por ejemplo, la clase Lzcnt proporciona acceso a instrucciones para contar los ceros a la izquierda . Tiene una subclase llamada X64 , que contiene la forma de estas instrucciones utilizadas solo en máquinas con arquitectura de 64 bits.
Algunas de estas clases son naturalmente de naturaleza jerárquica. Por ejemplo, si Lzcnt.X64.IsSupported devuelve verdadero, entonces Lzcnt.IsSupported también debería devolver verdadero, ya que esta es una subclase explícita. O, por ejemplo, si Sse2.IsSupported devuelve verdadero, entonces Sse.IsSupported debería devolver verdadero, porque Sse2 hereda explícitamente de Sse . Sin embargo, vale la pena señalar que la similitud de los nombres de clase no es un indicador de su pertenencia a la misma jerarquía de herencia. Por ejemplo, Bmi2 no se hereda de Bmi1 , por lo que los valores devueltos por IsSupported para estos dos conjuntos de instrucciones serán diferentes. El principio fundamental en el desarrollo de estas clases fue la presentación explícita de las especificaciones ISA. SSE2 requiere soporte para SSE1, por lo que las clases que los representan están relacionadas por herencia. Al mismo tiempo, BMI2 no requiere soporte para BMI1, por lo que no utilizamos la herencia. El siguiente es un ejemplo de la API anterior.
namespace System.Runtime.Intrinsics.X86 { public abstract class Sse { public static bool IsSupported { get; } public static Vector128<float> Add(Vector128<float> left, Vector128<float> right); // Additional APIs public abstract class X64 { public static bool IsSupported { get; } public static long ConvertToInt64(Vector128<float> value); // Additional APIs } } public abstract class Sse2 : Sse { public static new bool IsSupported { get; } public static Vector128<byte> Add(Vector128<byte> left, Vector128<byte> right); // Additional APIs public new abstract class X64 : Sse.X64 { public static bool IsSupported { get; } public static long ConvertToInt64(Vector128<double> value); // Additional APIs } } }
Puede ver más en el código fuente en los siguientes enlaces source.dot.net o dotnet / coreclr en GitHub
IsSupported compilador JIT procesa las comprobaciones IsSupported como constantes de tiempo de ejecución (cuando la optimización está habilitada), por lo que no necesita compilación cruzada para admitir múltiples ISA, plataformas o arquitecturas. En cambio, solo necesita escribir el código usando expresiones if , como resultado de las ramas de código no utilizadas (es decir, aquellas ramas a las que no se puede acceder debido al valor de la variable en la declaración condicional) se descartarán cuando se genere el código nativo.
Es importante que la verificación del IsSupported correspondiente preceda al uso de los comandos de hardware integrados. Si no hay tal verificación, entonces el código que usa comandos específicos de plataforma que se ejecutan en plataformas / arquitecturas donde estos comandos no son compatibles generará una excepción de tiempo de ejecución PlatformNotSupportedException .
¿Qué beneficios brindan?
Por supuesto, las funciones integradas específicas del hardware no son para todos, pero pueden usarse para mejorar el rendimiento en operaciones cargadas de cálculos. CoreFX y ML.NET utilizan estos métodos para acelerar operaciones como copiar en la memoria, buscar el índice de un elemento en una matriz o cadena, cambiar el tamaño de una imagen o trabajar con vectores / matrices / tensores. La vectorización manual de algún código que resultó ser un cuello de botella también puede ser más simple de lo que parece. La vectorización del código, de hecho, es realizar varias operaciones a la vez, en general, utilizando instrucciones SIMD (un flujo de instrucciones, flujo de datos múltiples).
Antes de decidirse a vectorizar algún código, debe llevar a cabo la creación de perfiles para asegurarse de que este código sea realmente parte del "punto caliente" (y, por lo tanto, su optimización dará un aumento significativo en el rendimiento). También es importante llevar a cabo la creación de perfiles en cada etapa de la vectorización, ya que la vectorización de no todo el código conduce a una mayor productividad.
Vectorización de un algoritmo simple
Para ilustrar el uso de funciones incorporadas, tomamos el algoritmo para sumar todos los elementos de una matriz o rango. Este tipo de código es un candidato ideal para la vectorización, porque en cada iteración, se realiza la misma operación trivial.
Un ejemplo de implementación de dicho algoritmo puede tener el siguiente aspecto:
public int Sum(ReadOnlySpan<int> source) { int result = 0; for (int i = 0; i < source.Length; i++) { result += source[i]; } return result; }
Este código es bastante simple y directo, pero al mismo tiempo lo suficientemente lento para datos de entrada grandes, como realiza solo una operación trivial por iteración.
BenchmarkDotNet=v0.11.5, OS=Windows 10.0.18362 AMD Ryzen 7 1800X, 1 CPU, 16 logical and 8 physical cores .NET Core SDK=3.0.100-preview9-013775 [Host] : .NET Core 3.0.0-preview9-19410-10 (CoreCLR 4.700.19.40902, CoreFX 4.700.19.40917), 64bit RyuJIT [AttachedDebugger] DefaultJob : .NET Core 3.0.0-preview9-19410-10 (CoreCLR 4.700.19.40902, CoreFX 4.700.19.40917), 64bit RyuJIT
Aumente la productividad a través de los ciclos de implementación
Los procesadores modernos tienen varias opciones para mejorar el rendimiento del código. Para aplicaciones de subproceso único, una de esas opciones es realizar varias operaciones primitivas en un solo ciclo de procesador.
La mayoría de los procesadores modernos pueden realizar cuatro operaciones de adición en un ciclo de reloj (en condiciones óptimas), como resultado de lo cual, con el "diseño" correcto del código, a veces puede mejorar el rendimiento, incluso en una implementación de subproceso único.
Aunque JIT puede realizar el desenrollado de bucles por sí solo, JIT es conservador al tomar este tipo de decisión, debido al tamaño del código generado. Por lo tanto, puede ser ventajoso implementar un bucle, en código, manualmente.
Puede expandir el bucle en el código anterior de la siguiente manera:
public unsafe int SumUnrolled(ReadOnlySpan<int> source) { int result = 0; int i = 0; int lastBlockIndex = source.Length - (source.Length % 4); // Pin source so we can elide the bounds checks fixed (int* pSource = source) { while (i < lastBlockIndex) { result += pSource[i + 0]; result += pSource[i + 1]; result += pSource[i + 2]; result += pSource[i + 3]; i += 4; } while (i < source.Length) { result += pSource[i]; i += 1; } } return result; }
Este código es un poco más complicado, pero hace un mejor uso de las características del hardware.
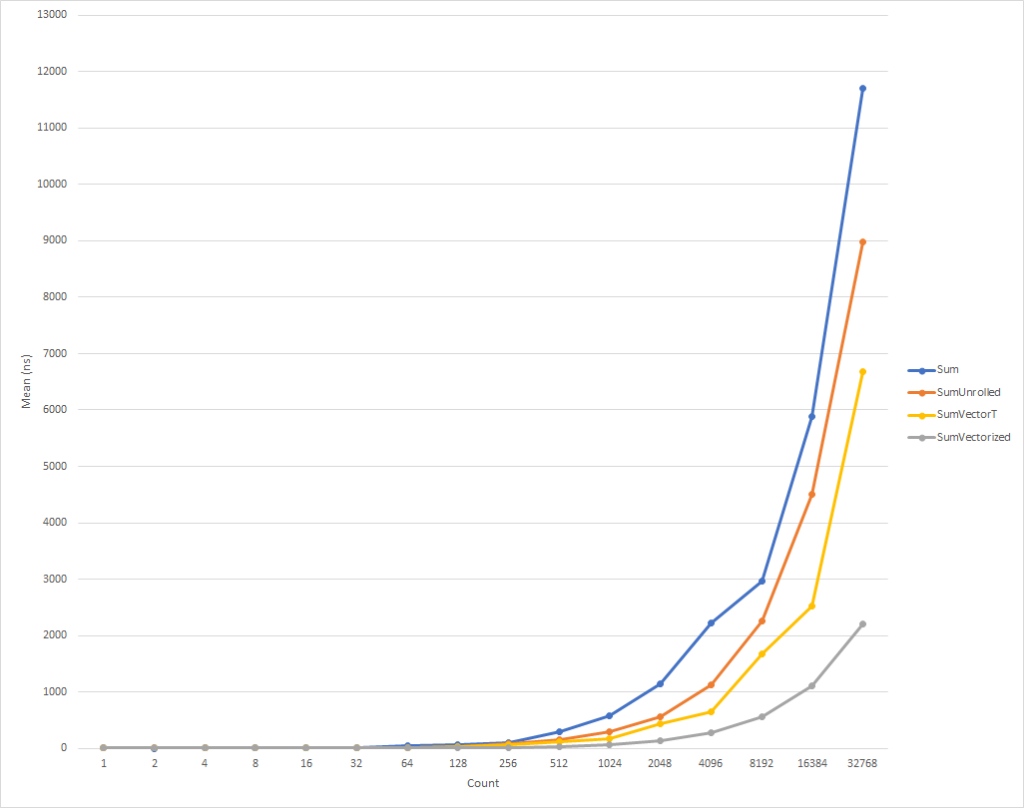
Para bucles realmente pequeños, este código se ejecuta un poco más lento. Pero esta tendencia ya está cambiando para los datos de entrada de ocho elementos, después de lo cual la velocidad de ejecución comienza a aumentar (el tiempo de ejecución del código optimizado, para 32 mil elementos, es un 26% menor que el tiempo de la versión original). Vale la pena señalar que dicha optimización no siempre aumenta la productividad. Por ejemplo, cuando se trabaja con colecciones con elementos de tipo float versión "implementada" del algoritmo tiene casi la misma velocidad que la original. Por lo tanto, es muy importante llevar a cabo la creación de perfiles.

Aumente la productividad a través de la vectorización de bucle
Sea como fuere, pero aún podemos optimizar ligeramente este código. Las instrucciones SIMD son otra opción proporcionada por los procesadores modernos para mejorar el rendimiento. Usando una sola instrucción, le permiten realizar varias operaciones en un solo ciclo de reloj. Esto puede ser mejor que el despliegue de bucle directo, porque, de hecho, se hace lo mismo, pero con una menor cantidad de código generado.
Para aclarar, cada operación de adición, en un ciclo desplegado, toma 4 bytes. Por lo tanto, necesitamos 16 bytes para 4 operaciones de suma en forma expandida. Al mismo tiempo, la instrucción de adición SIMD también realiza 4 operaciones de adición, pero solo toma 4 bytes. Esto significa que tenemos menos instrucciones para la CPU. Además de esto, en el caso de una instrucción SIMD, la CPU puede hacer suposiciones y realizar optimizaciones, pero esto está más allá del alcance de este artículo. Lo que es aún mejor es que los procesadores modernos pueden ejecutar más de una instrucción SIMD a la vez, es decir, en algunos casos, puede aplicar una estrategia mixta, al mismo tiempo realizar una exploración de ciclo parcial y vectorización.
En general, debe comenzar mirando la clase de propósito general de Vector<T> para sus tareas. Él, como los nuevos WF , incorporará instrucciones SIMD, pero al mismo tiempo, dada la versatilidad de esta clase, puede reducir la cantidad de codificación "manual".
El código podría verse así:
public int SumVectorT(ReadOnlySpan<int> source) { int result = 0; Vector<int> vresult = Vector<int>.Zero; int i = 0; int lastBlockIndex = source.Length - (source.Length % Vector<int>.Count); while (i < lastBlockIndex) { vresult += new Vector<int>(source.Slice(i)); i += Vector<int>.Count; } for (int n = 0; n < Vector<int>.Count; n++) { result += vresult[n]; } while (i < source.Length) { result += source[i]; i += 1; } return result; }
Este código funciona más rápido, pero nos vemos obligados a referirnos a cada elemento por separado al calcular la cantidad final. Además, Vector<T> no tiene un tamaño definido con precisión y puede variar, dependiendo del equipo en el que se ejecuta el código. Las funciones integradas específicas del hardware proporcionan una funcionalidad adicional que puede mejorar ligeramente este código y hacerlo un poco más rápido (a costa de la complejidad del código adicional y los requisitos de mantenimiento).

NOTA Para este artículo, COMPlus_SIMD16ByteOnly=1 tamaño del Vector<T> igual a 16 bytes usando el parámetro de configuración interna ( COMPlus_SIMD16ByteOnly=1 ). Este ajuste normalizó los resultados al comparar SumVectorT con SumVectorizedSse , y nos permitió mantener el código simple. En particular, evitó escribir un salto condicional if (Avx2.IsSupported) { } . Este código es casi idéntico al código para Sse2 , pero trata con Vector256<T> (32 bytes) y procesa aún más elementos en una iteración del bucle.
Por lo tanto, utilizando las nuevas funciones integradas , el código puede reescribirse de la siguiente manera:
public int SumVectorized(ReadOnlySpan<int> source) { if (Sse2.IsSupported) { return SumVectorizedSse2(source); } else { return SumVectorT(source); } } public unsafe int SumVectorizedSse2(ReadOnlySpan<int> source) { int result; fixed (int* pSource = source) { Vector128<int> vresult = Vector128<int>.Zero; int i = 0; int lastBlockIndex = source.Length - (source.Length % 4); while (i < lastBlockIndex) { vresult = Sse2.Add(vresult, Sse2.LoadVector128(pSource + i)); i += 4; } if (Ssse3.IsSupported) { vresult = Ssse3.HorizontalAdd(vresult, vresult); vresult = Ssse3.HorizontalAdd(vresult, vresult); } else { vresult = Sse2.Add(vresult, Sse2.Shuffle(vresult, 0x4E)); vresult = Sse2.Add(vresult, Sse2.Shuffle(vresult, 0xB1)); } result = vresult.ToScalar(); while (i < source.Length) { result += pSource[i]; i += 1; } } return result; }
Este código, una vez más, es un poco más complicado, pero es significativamente más rápido para todos, excepto para los conjuntos de entrada más pequeños. Para 32 mil elementos, este código se ejecuta un 75% más rápido que el ciclo expandido y un 81% más rápido que el código fuente del ejemplo.
Notó que escribimos algunos controles IsSupported . El primero verifica si el hardware actual es compatible con el conjunto requerido de funciones incorporadas ; de lo contrario, la optimización se realiza mediante una combinación de barrido y Vector<T> . La última opción se seleccionará para plataformas como ARM / ARM64 que no admiten el conjunto de instrucciones requerido, o si el conjunto se ha deshabilitado para la plataforma. La segunda prueba IsSupported , en el método SumVectorizedSse2 , se utiliza para una optimización adicional si el hardware admite el Ssse3 instrucciones Ssse3 .
De lo contrario, la mayor parte de la lógica es esencialmente la misma que para el bucle expandido. Vector128<T> es un tipo de 128 bits que contiene elementos Vector128<T>.Count . En este caso, uint , que en sí mismo es de 32 bits, puede tener 4 elementos (128/32), así es como lanzamos el bucle.
Conclusión
Las nuevas funciones integradas le brindan la oportunidad de aprovechar la funcionalidad específica del hardware de la máquina en la que ejecuta el código. Hay aproximadamente 1,500 API para X86 y X64 distribuidas en 15 conjuntos, hay demasiadas para describir en un artículo. Al perfilar el código para identificar cuellos de botella, puede determinar la parte del código que se beneficia de la vectorización y observar un aumento de rendimiento bastante bueno. Hay muchos escenarios en los que se puede aplicar la vectorización y el despliegue de bucles es solo el comienzo.
Cualquiera que quiera ver más ejemplos puede buscar el uso de funciones integradas en el marco (ver dotnet y aspnet ), o en otros artículos de la comunidad. Y aunque los WF actuales son vastos, todavía hay mucha funcionalidad que debe introducirse. Si tiene la funcionalidad que desea presentar, no dude en registrar su solicitud de API a través de dotnet / corefx en GitHub . El proceso de revisión de API se describe aquí y hay un buen ejemplo de una plantilla de solicitud de API especificada en el paso 1.
Agradecimiento especial
Me gustaría expresar un agradecimiento especial a los miembros de nuestra comunidad Fei Peng (@fiigii) y Jacek Blaszczynski (@ 4creators) por su ayuda en la implementación del WF , así como a todos los miembros de la comunidad por sus valiosos comentarios sobre el desarrollo, implementación y facilidad de uso de esta funcionalidad.
Epílogo de la traducción
Me gusta observar el desarrollo de la plataforma .NET y, en particular, el lenguaje C #. Viniendo del mundo de C ++, y con poca experiencia en desarrollo en Delphi y Java, me sentí muy cómodo comenzando a escribir programas en C #. En 2006, este lenguaje de programación (el lenguaje en sí) me pareció más conciso y práctico que Java en el mundo de la recolección de basura administrada y multiplataforma. Por lo tanto, mi elección recayó en C #, y no me arrepentí. La primera etapa en la evolución de un lenguaje fue simplemente su apariencia. Para 2006, C # absorbió todo lo mejor que había en ese momento en los mejores lenguajes y plataformas: C ++ / Java / Delphi. En 2010, F # se hizo público. Era una plataforma experimental para estudiar el paradigma funcional con el objetivo de introducirlo en el mundo de .NET. El resultado de los experimentos fue la siguiente etapa en la evolución de C #: la expansión de sus capacidades hacia el FP, a través de la introducción de funciones anónimas, expresiones lambda y, en última instancia, LINQ. Esta extensión del lenguaje convirtió a C # en el lenguaje de propósito general más avanzado, desde mi punto de vista. El siguiente paso evolutivo se relacionó con el apoyo a la concurrencia y la asincronía. Tarea / Tarea <T>, todo el concepto de TPL, el desarrollo de LINQ - PLINQ y, por último, asíncrono / espera. , - , .NET C# — . Span<T> Memory<T>, ValueTask/ValueTask<T>, IAsyncDispose, ref readonly struct in, foreach, IO.Streams. GC . , — . , .NET C#, , . ( ) .