
Al reconocer la importancia de la inteligencia artificial, Intel está dando otro paso en esa dirección. Hace un mes, en la conferencia Hot Chips 2019, la compañía presentó oficialmente dos chips especializados diseñados para el entrenamiento y la inferencia de redes neuronales. Los chips se llamaron Intel Nervana NNP-
T (procesador de red neuronal) e Intel Nervana NNP-
I, respectivamente. Debajo del corte encontrará las características y esquemas de nuevos productos.
Intel Nervana NNP-T (Cresta de primavera)
El tiempo de entrenamiento de la red neuronal, junto con la eficiencia energética, es uno de los parámetros clave del sistema de IA, que determina el alcance de su aplicación. La potencia informática utilizada en los modelos y conjuntos de entrenamiento más grandes se duplica cada tres meses. Al mismo tiempo, se utiliza un conjunto limitado de cálculos en redes neuronales, principalmente convoluciones y multiplicación de matrices, lo que abre un gran margen para las optimizaciones. Idealmente, el dispositivo que necesitamos debe estar equilibrado en términos de consumo, comunicaciones, potencia informática y escalabilidad.
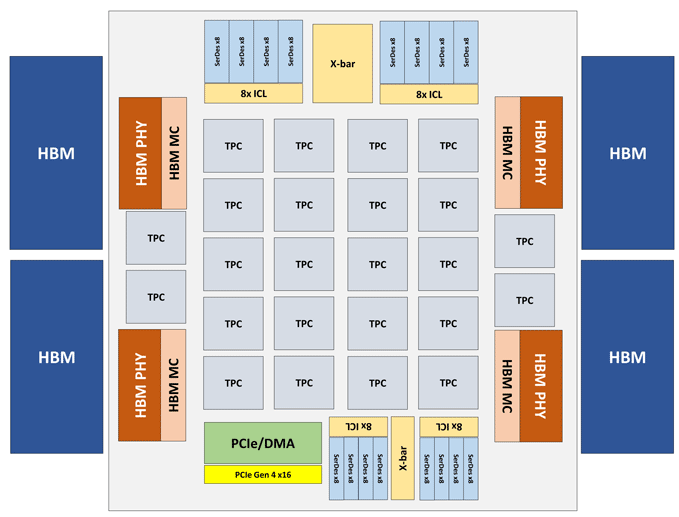
El módulo Intel Nervana NNP-T está hecho en forma de una tarjeta PCIe 4.0 x16 o OAM. El principal elemento informático de NNP-T es el Cluster de procesamiento de tensor (TPC) de 24 piezas, que proporciona hasta 119 TOPS de rendimiento. Se conecta un total de 32 GB de memoria HBM2-2400 a través de 4 puertos HBM. A bordo también hay una unidad de serialización / deserialización en 64 líneas, SPI, I2C, interfaces GPIO. La cantidad de memoria distribuida en el chip es de 60 MB (2.5 MB por TPC).
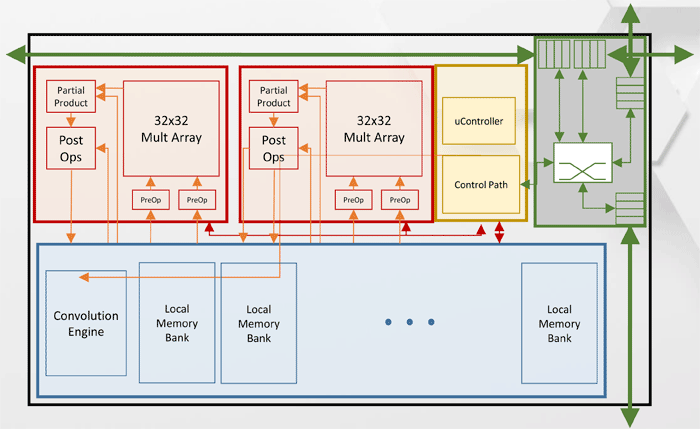 Arquitectura del clúster de procesamiento de tensor (TPC)
Arquitectura del clúster de procesamiento de tensor (TPC)Otras especificaciones de rendimiento Intel Nervana NNP-T.
Como puede ver en el diagrama, cada TPC tiene dos núcleos de multiplicación de matriz de 32x32 con soporte BFloat16. Otras operaciones se realizan en formato BFloat16 o FP32. En total, se pueden instalar hasta 8 tarjetas en un host, la escalabilidad máxima: hasta 1024 nodos.
Intel Nervana NNP-I (Spring Hill)
Al diseñar Intel Nervana NNP-I, el objetivo era proporcionar la máxima eficiencia energética con inferencia en la escala de grandes centros de datos, alrededor de 5 TOP / W.
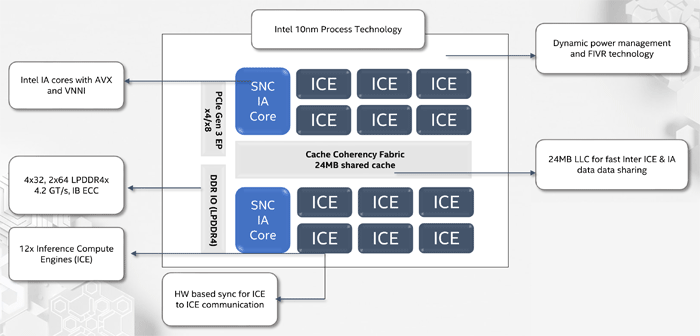
NNP-I es un SoC, fabricado de acuerdo con la tecnología de proceso de 10 nm e incluye dos núcleos x86 estándar con soporte para AVX y VNNI, así como 12 núcleos especializados de Inference Compute Engine (ICE). El rendimiento máximo es 92 TORS, TDP - 50 vatios. La cantidad de memoria interna es de 75 MB. Estructuralmente, el dispositivo está hecho en forma de una tarjeta de expansión M.2.
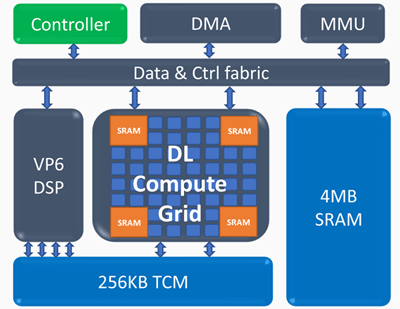 Arquitectura del motor de cálculo de inferencia (ICE)
Arquitectura del motor de cálculo de inferencia (ICE)Elementos clave del motor de cálculo de inferencia:
Cuadrícula de cálculo de aprendizaje profundo- 4k MAC (int8) por ciclo
- soporte escalable para FP16, INT8, INT 4/2/1
- gran cantidad de memoria interna
- operaciones no lineales y agrupación
Procesador vectorial programable- alto rendimiento - 5 VLIW 512 b
- Soporte NN extendido - FP16 / 16b / 8b
Se obtuvieron los siguientes indicadores de rendimiento de Intel Nervana NNP-I: en una red ResNet de 50 capas, se logró una velocidad de 3600 inferencias por segundo con un consumo de energía de 10 W, es decir, la eficiencia energética es de 360 imágenes por segundo en términos de vatios.