El artículo anterior analizó la arquitectura de una red virtualizada, la superposición subyacente, la ruta del paquete entre máquinas virtuales y más.
Roman Gorge se inspiró en ella y decidió escribir un artículo de revisión sobre la virtualización en general.
En este artículo, abordaremos (o trataremos de tocar) las preguntas: cómo se produce realmente la virtualización de las funciones de red, cómo se implementa el back-end de los principales productos para lanzar y administrar máquinas virtuales, y cómo funciona la conmutación virtual (OVS y el puente de Linux).
El tema de la virtualización es amplio y profundo, es imposible explicar todos los detalles del trabajo del hipervisor (y no es necesario). Nos limitaremos al conjunto mínimo de conocimientos necesarios para comprender el funcionamiento de cualquier solución virtualizada, no necesariamente Telco.

Contenido
- Introducción y una breve historia de la virtualización.
- Tipos de recursos virtuales: computación, almacenamiento, red
- Conmutación virtual
- Herramientas de virtualización: libvirt, virsh y más
- Conclusión
Introducción y una breve historia de la virtualización.
La historia de las tecnologías modernas de virtualización se remonta a 1999, cuando la joven empresa VMware lanzó un producto llamado VMware Workstation. Este era un producto de virtualización para aplicaciones de escritorio / cliente. La virtualización del lado del servidor llegó un poco más tarde en la forma del producto ESX Server, que luego evolucionó a ESXi (es decir, integrado): este es el mismo producto que se usa universalmente en TI y Telco como hipervisor de aplicaciones de servidor.
En el lado de Opensource, dos proyectos importantes han traído la virtualización a Linux:
- KVM (máquina virtual basada en kernel) es un módulo de kernel de Linux que permite que el kernel funcione como un hipervisor (crea la infraestructura necesaria para iniciar y administrar máquinas virtuales). Fue agregado en la versión del kernel 2.6.20 en 2007.
- QEMU (emulador rápido): emula directamente el hardware de una máquina virtual (CPU, disco, RAM, cualquier cosa, incluido un puerto USB) y se utiliza junto con KVM para lograr un rendimiento casi "nativo".
De hecho, en este momento, toda la funcionalidad de KVM está disponible en QEMU, pero esto no es importante, ya que la mayoría de los usuarios de virtualización de Linux no usan directamente KVM / QEMU, sino que acceden a ellos a través de al menos un nivel de abstracción, pero más sobre eso más adelante.
Hoy, VMware ESXi y Linux QEMU / KVM son los dos hipervisores principales que dominan el mercado. También son representantes de dos tipos diferentes de hipervisores:
- Tipo 1: el hipervisor se ejecuta directamente en el hardware (bare-metal). Esto es VMware ESXi, Linux KVM, Hyper-V
- Tipo 2: el hipervisor se inicia dentro del sistema operativo host (sistema operativo). Esta es VMware Workstation u Oracle VirtualBox.
Una discusión sobre qué es mejor y qué es peor está más allá del alcance de este artículo.

Los productores de hierro también tuvieron que hacer su parte para garantizar un rendimiento aceptable.
Quizás el más importante y el más utilizado es Intel VT (Tecnología de virtualización), un conjunto de extensiones desarrolladas por Intel para sus procesadores x86 que se utilizan para el funcionamiento efectivo del hipervisor (y en algunos casos son necesarios, por ejemplo, KVM no funcionará sin VT activado) -x y sin él, el hipervisor se ve obligado a realizar una emulación puramente de software, sin aceleración de hardware).
Dos de estas extensiones son más conocidas: VT-x y VT-d. El primero es importante para mejorar el rendimiento de la CPU durante la virtualización, ya que proporciona soporte de hardware para algunas de sus funciones (con el código VT-x 99.9% Guest OS se ejecuta directamente en el procesador físico, haciendo salidas para la emulación solo en los casos más necesarios), el segundo es para conectar dispositivos físicos directamente a una máquina virtual (para funciones virtuales de reenvío (VF) SRIOV, por ejemplo, VT-d
debe estar habilitado ).
El siguiente concepto importante es la diferencia entre virtualización completa y para-virtualización.
La virtualización completa es buena, le permite ejecutar cualquier sistema operativo en cualquier procesador, sin embargo, es extremadamente ineficiente y absolutamente no es adecuado para sistemas altamente cargados.
Paravirtualización, en resumen, es cuando Guest OS entiende que se está ejecutando en un entorno virtual y coopera con el hipervisor para lograr una mayor eficiencia. Es decir, aparece la interfaz del hipervisor invitado.
La gran mayoría de los sistemas operativos utilizados hoy en día tienen soporte para para-virtualización; en el kernel de Linux, esto ha aparecido desde la versión 2.6.20 del kernel.
Para que una máquina virtual funcione, no solo se necesitan un procesador virtual (vCPU) y una memoria virtual (RAM); también se requiere la emulación de dispositivos PCI. Es decir, de hecho, se requiere un conjunto de controladores para administrar interfaces de red virtual, discos, etc.
En el hipervisor KVM de Linux, esta tarea se resolvió implementando
virtio , un marco para desarrollar y usar dispositivos de E / S virtualizados.
Virtio es un nivel adicional de abstracción, que le permite emular varios dispositivos de E / S en un hipervisor para-virtualizado, proporcionando una interfaz unificada y estandarizada al lado de la máquina virtual. Esto le permite reutilizar el código del controlador virtio para varios dispositivos inherentes. Virtio consiste en:
- Controlador de front-end: qué hay en la máquina virtual
- Controlador de fondo: qué hay en el hipervisor
- Conductor de transporte: lo que conecta el backend y la interfaz
Esta modularidad le permite cambiar las tecnologías utilizadas en el hipervisor sin afectar los controladores en la máquina virtual (este punto es muy importante para las tecnologías de aceleración de red y las soluciones de nube en general, pero más sobre eso más adelante).
Es decir, hay una conexión de hipervisor invitado cuando el SO huésped "sabe" que se está ejecutando en un entorno virtual.
Si alguna vez escribió una pregunta en RFP o respondió una pregunta en RFP "¿Se admite virtio en su producto?" Se trataba solo de soportar el controlador virtio front-end.
Tipos de recursos virtuales: computación, almacenamiento, red
¿En qué consiste una máquina virtual?
Hay tres tipos principales de recursos virtuales:
- calcular - procesador y RAM
- almacenamiento: disco del sistema de máquina virtual y almacenamiento en bloque
- red - tarjetas de red y dispositivos de entrada / salida
Calcular
CPU
Teóricamente, QEMU es capaz de emular cualquier tipo de procesador y sus correspondientes banderas y funcionalidades; en la práctica, usan el modelo host y apagan las banderas de forma puntual antes de transferirlas al sistema operativo invitado, o toman el modelo con nombre y activan / desactivan las banderas de manera puntual.
De forma predeterminada, QEMU emulará un procesador que el SO huésped reconocerá como CPU virtual QEMU. Este no es el tipo de procesador más óptimo, especialmente si una aplicación que se ejecuta en una máquina virtual utiliza indicadores de CPU para su trabajo.
Obtenga más información sobre los diferentes modelos de CPU en QEMU .
QEMU / KVM también le permite controlar la topología del procesador, la cantidad de subprocesos, el tamaño de la memoria caché, vincular vCPU al núcleo físico y mucho más.
Si esto es necesario para una máquina virtual o no, depende del tipo de aplicación que se ejecute en el SO invitado. Por ejemplo, es un hecho bien conocido que para las aplicaciones que procesan paquetes con un alto PPS, es importante hacer
la fijación de la CPU , es decir, no permitir que el procesador físico se transfiera a otras máquinas virtuales.
Memoria
El siguiente en la línea es la RAM. Desde el punto de vista de Host OS, una máquina virtual lanzada usando QEMU / KVM no es diferente de cualquier otro proceso que se ejecute en el espacio de usuario del sistema operativo. En consecuencia, el proceso de asignación de memoria a una máquina virtual se realiza mediante las mismas llamadas en el sistema operativo host del núcleo, como si se iniciara, por ejemplo, un navegador Chrome.
Antes de continuar con la historia de RAM en máquinas virtuales, debe desviarse y explicar el término NUMA - Acceso no uniforme a la memoria.
La arquitectura de los servidores físicos modernos implica la presencia de dos o más procesadores (CPU) y está asociada con la memoria de acceso aleatorio (RAM). Tal grupo de procesador + memoria se llama nodo o nodo. La comunicación entre varios nodos NUMA se realiza a través de un bus especial: QPI (QuickPath Interconnect)
El nodo NUMA local se asigna: cuando el proceso que se ejecuta en el sistema operativo usa el procesador y la RAM ubicados en el mismo nodo NUMA, y el nodo NUMA remoto, cuando el proceso que se ejecuta en el sistema operativo usa el procesador y la RAM ubicados en diferentes nodos NUMA, es decir, para la interacción del procesador y la memoria, se requiere la transferencia de datos a través del bus QPI.
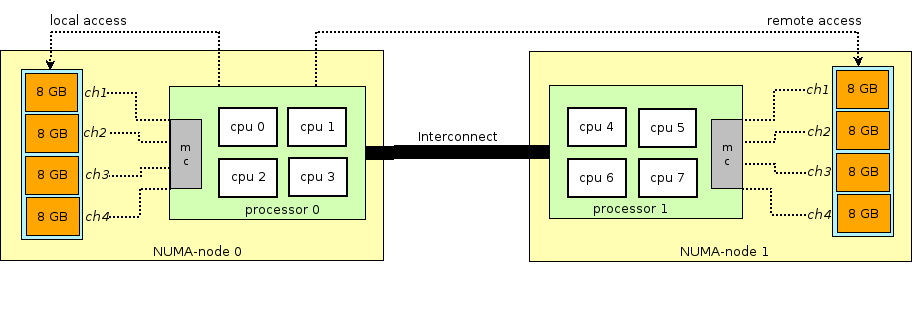
Desde el punto de vista de la máquina virtual, la memoria ya estaba asignada al momento de su lanzamiento, pero en realidad no es así, y el sistema operativo host del núcleo asigna nuevas secciones de memoria al proceso QEMU / KVM ya que la aplicación en el sistema operativo invitado solicita memoria adicional (aunque también puede haber una excepción si especifica directamente QEMU / KVM para asignar toda la memoria a la máquina virtual directamente al inicio).
La memoria se asigna no byte a byte, sino por un tamaño determinado de
página . El tamaño de la página es configurable y, en teoría, puede ser cualquiera, pero en la práctica el tamaño es de 4 KB (predeterminado), 2 MB y 1 GB. Los dos últimos tamaños se denominan
HugePages y a menudo se utilizan para asignar memoria para máquinas virtuales con uso intensivo de memoria. La razón para usar HugePages en el proceso de encontrar una coincidencia entre la dirección virtual de la página y la memoria física en
Translation Lookaside Buffer (
TLB ), que a su vez es limitada y almacena información solo sobre las últimas páginas utilizadas. Si no hay información sobre la página deseada en el TLB, se produce un proceso llamado
miss TLB , y debe utilizar el procesador Host OS para encontrar la celda de memoria física correspondiente a la página deseada.
Este proceso es ineficiente y lento, por lo que se utilizan menos páginas de mayor tamaño.
QEMU / KVM también le permite emular varias topologías NUMA para SO invitado, tomar memoria para una máquina virtual solo desde un SO host de nodo NUMA específico, y así sucesivamente. La práctica más común es tomar memoria para una máquina virtual desde un nodo NUMA local a los procesadores asignados a la máquina virtual. La razón es el deseo de evitar cargas innecesarias en el bus
QPI que conecta los zócalos de la CPU del servidor físico (por supuesto, esto es lógico si su servidor tiene 2 o más zócalos).
Almacenamiento
Como sabe, la RAM se llama memoria operativa porque su contenido desaparece cuando se apaga o se reinicia el sistema operativo. Para almacenar información, necesita un dispositivo de almacenamiento persistente (ROM) o
almacenamiento persistente .
Hay dos tipos principales de almacenamiento persistente:
- Almacenamiento en bloque: un bloque de espacio en disco que se puede utilizar para instalar el sistema de archivos y crear particiones. Si es grosero, puede tomarlo como un disco normal.
- Almacenamiento de objetos: la información solo se puede guardar como un objeto (archivo), accesible a través de HTTP / HTTPS. Ejemplos típicos de almacenamiento de objetos son AWS S3 o Dropbox.
La máquina virtual necesita
almacenamiento persistente , sin embargo, ¿cómo hacer esto si la máquina virtual "vive" en la RAM del sistema operativo host? En resumen, cualquier llamada del SO invitado al controlador de disco virtual es interceptada por QEMU / KVM y se transforma en un registro en el disco físico del SO host. Este método es ineficiente y, por lo tanto, aquí, así como para dispositivos de red, se usa el controlador virtio en lugar de emular completamente un dispositivo IDE o iSCSI. Lea más sobre esto
aquí . Por lo tanto, la máquina virtual accede a su disco virtual a través de un controlador virtio, y luego QEMU / KVM hace que la información transferida se escriba en el disco físico. Es importante comprender que en el sistema operativo host, un backend de disco se puede implementar como un estante CEPH, NFS o iSCSI.
La forma más fácil de emular el almacenamiento persistente es usar el archivo en algún directorio del sistema operativo host como el espacio en disco de una máquina virtual. QEMU / KVM admite muchos formatos diferentes de este tipo de archivo: raw, vdi, vmdk y otros. Sin embargo, el formato más utilizado es
qcow2 (QEMU copy-on-write versión 2). En general, qcow2 es un archivo estructurado de cierta manera sin ningún sistema operativo. Una gran cantidad de máquinas virtuales se distribuyen en forma de imágenes qcow2 (imágenes) y son una copia del disco del sistema de una máquina virtual, empaquetada en formato qcow2. Esto tiene varias ventajas: la codificación qcow2 ocupa mucho menos espacio que una copia sin formato de un disco byte a byte, QEMU / KVM puede cambiar el tamaño de un archivo qcow2, lo que significa que es posible cambiar el tamaño del disco de una máquina virtual, también se admite el cifrado AES qcow2 (Esto tiene sentido, ya que la imagen de una máquina virtual puede contener propiedad intelectual).
Además, cuando se inicia la máquina virtual, QEMU / KVM utiliza el archivo qcow2 como un disco del sistema (omito el proceso de carga de la máquina virtual aquí, aunque también es una tarea interesante), y la máquina virtual tiene la capacidad de leer / escribir datos en el archivo qcow2 a través de virtio conductor Por lo tanto, el proceso de tomar imágenes de máquinas virtuales funciona, ya que en cualquier momento el archivo qcow2 contiene una copia completa del disco del sistema de la máquina virtual, y la imagen se puede usar para hacer una copia de seguridad, transferirla a otro host, etc.
En general, este archivo qcow2 se definirá en el SO invitado como un
dispositivo / dev / vda , y el SO invitado dividirá el espacio en disco en particiones e instalará el sistema de archivos. De manera similar, los siguientes archivos qcow2 conectados por QEMU / KVM como dispositivos
/ dev / vdX se pueden usar como
almacenamiento en
bloque en una máquina virtual para almacenar información (así es exactamente como funciona el componente Openstack Cinder).
Red
Los últimos en nuestra lista de recursos virtuales son las tarjetas de red y los dispositivos de E / S. Una máquina virtual, como un host físico, necesita un
bus PCI / PCIe para conectar dispositivos de E / S. QEMU / KVM puede emular diferentes tipos de conjuntos de chips: q35 o i440fx (el primero es compatible con PCIe, el segundo es compatible con PCI heredado), así como varias topologías de PCI, por ejemplo, crear buses PCI separados (bus de expansión PCI) para los nodos NUMA del sistema operativo invitado.
Después de crear el bus PCI / PCIe, debe conectarle un dispositivo de E / S. En general, puede ser cualquier cosa, desde una tarjeta de red a una GPU física. Y, por supuesto, una tarjeta de red, tanto virtualizada (interfaz virtualizada completamente e1000, por ejemplo) como para-virtualizada (virtio, por ejemplo) o una NIC física. La última opción se usa para máquinas virtuales de plano de datos donde necesita obtener velocidades de paquetes de velocidad de línea: enrutadores, firewalls, etc.
Aquí hay dos enfoques principales:
PCI passthrough y
SR-IOV . La principal diferencia entre ellos es que para PCI-PT, el controlador se usa solo dentro del sistema operativo invitado, y para SRIOV, el controlador del sistema operativo host (para crear
VF - Funciones virtuales ) y el controlador del sistema operativo invitado se usan para controlar SR-IOV VF.
Juniper escribió excelentes detalles sobre PCI-PT y SRIOV.

Para aclarar, vale la pena señalar que el paso de PCI y SR-IOV son tecnologías complementarias. SR-IOV está dividiendo una función física en funciones virtuales. Esto se hace a nivel del sistema operativo host. Al mismo tiempo, Host OS ve las funciones virtuales como otro dispositivo PCI / PCIe. Lo que haga después con ellos no es importante.
Y PCI-PT es un mecanismo para reenviar cualquier dispositivo PCI del sistema operativo host en el sistema operativo invitado, incluida la función virtual creada por el dispositivo SR-IOV
Por lo tanto, examinamos los principales tipos de recursos virtuales y el siguiente paso es comprender cómo la máquina virtual se comunica con el mundo exterior a través de una red.
Conmutación virtual
Si hay una máquina virtual y hay una interfaz virtual en ella, entonces, obviamente, surge el problema de transferir un paquete de una VM a otra. En los hipervisores basados en Linux (KVM, por ejemplo), este problema se puede resolver utilizando el puente de Linux, sin embargo, el proyecto
Open vSwitch (OVS) ha ganado una amplia aceptación.
Existen varias funcionalidades centrales que han permitido que OVS se extienda ampliamente y se convierta en el método de conmutación de paquetes primario de facto utilizado en muchas plataformas de computación en la nube (como Openstack) y soluciones virtualizadas.
- Transferencia de estado de red: al migrar una VM entre hipervisores, surge la tarea de transferir ACL, QoS, tablas de reenvío L2 / L3 y más. Y OVS puede hacerlo.
- Implementación del mecanismo de transferencia de paquetes (ruta de datos) tanto en el núcleo como en el espacio de usuario
- Arquitectura CUPS (Control / Separación del plano de usuario): le permite transferir la funcionalidad del procesamiento de paquetes a un conjunto de chips especializado (el conjunto de chips Broadcom y Marvell, por ejemplo, puede hacer esto), controlándolo a través del OVS del plano de control.
- Soporte para métodos de control de tráfico remoto: protocolo OpenFlow (hola, SDN).
La arquitectura OVS a primera vista parece bastante aterradora, pero es solo a primera vista.
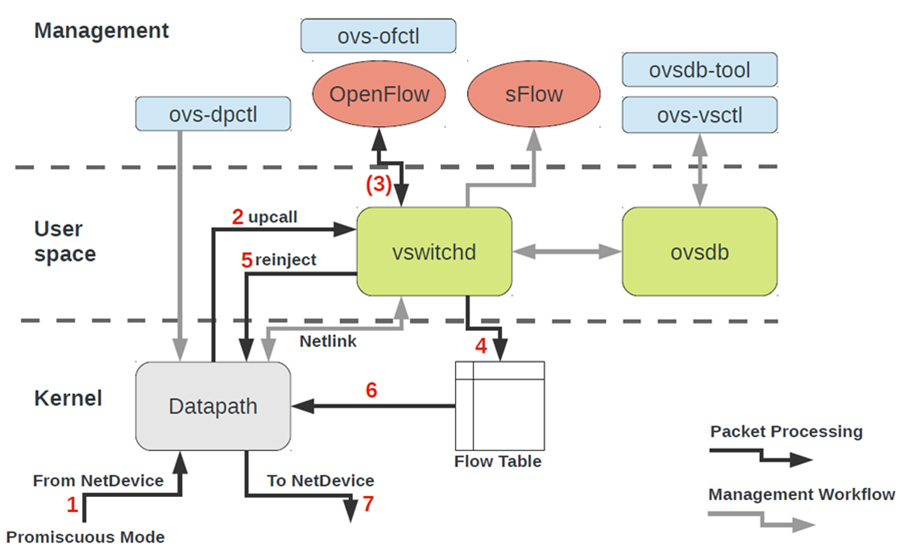
Para trabajar con OVS, debe comprender lo siguiente:
- Ruta de datos : los paquetes se procesan aquí. La analogía es la estructura del interruptor de un interruptor de hierro. Datapath incluye recibir paquetes, procesar encabezados, coincidencias coincidentes en la tabla de flujo, que ya está programada en Datapath. Si OVS se ejecuta en el núcleo, se implementa como un módulo del núcleo. Si OVS se ejecuta en espacio de usuario, entonces este es un proceso en Linux de espacio de usuario.
- vswitchd y ovsdb son demonios en el espacio del usuario, que implementa directamente la funcionalidad del conmutador, almacena la configuración, establece el flujo a la ruta de datos y la programa.
- Un conjunto de herramientas para configurar y solucionar problemas de OVS: ovs-vsctl, ovs-dpctl, ovs-ofctl, ovs-appctl . Todo lo que se necesita para registrar la configuración del puerto en ovsdb, registrar a qué flujo se debe cambiar, recopilar estadísticas, etc. Las buenas personas escribieron un artículo sobre esto.
¿Cómo termina el dispositivo de red de una máquina virtual en OVS?Para resolver este problema, necesitamos interconectar de alguna manera la interfaz virtual ubicada en el espacio de usuario del sistema operativo con la ruta de datos OVS ubicada en el núcleo.
En el sistema operativo Linux, los paquetes se transfieren entre el núcleo y los procesos de espacio de usuario a través de dos interfaces especiales.
Ambas interfaces usan escritura / lectura de un paquete a / desde un archivo especial para transferir paquetes del proceso de espacio de usuario al kernel y viceversa - descriptor de archivo (FD) (esta es una de las razones del bajo rendimiento de conmutación virtual si datapath OVS está en el kernel - cada paquete necesita escribir / leer a través de FD)- TUN (túnel): un dispositivo que funciona en modo L3 y le permite escribir / leer solo paquetes IP a / desde FD.
- TAP (red tap): lo mismo que la interfaz tun + puede realizar operaciones con tramas Ethernet, es decir trabajar en modo L2.
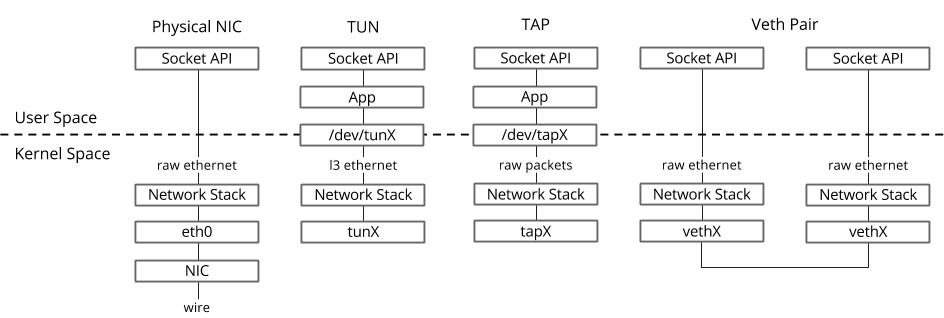 Es por eso que cuando la máquina virtual se ejecuta en el sistema operativo host, puede ver las interfaces TAP creadas con el enlace ip o el comando ifconfig : esta es la parte de "respuesta" de virtio, que es "visible" en el sistema operativo host del núcleo. También vale la pena señalar que la interfaz TAP tiene la misma dirección MAC que la interfaz virtio en la máquina virtual.La interfaz TAP se puede agregar a OVS utilizando los comandos ovs-vsctl ; luego, cualquier paquete que OVS cambie a la interfaz TAP se transferirá a la máquina virtual mediante un descriptor de archivo.
Es por eso que cuando la máquina virtual se ejecuta en el sistema operativo host, puede ver las interfaces TAP creadas con el enlace ip o el comando ifconfig : esta es la parte de "respuesta" de virtio, que es "visible" en el sistema operativo host del núcleo. También vale la pena señalar que la interfaz TAP tiene la misma dirección MAC que la interfaz virtio en la máquina virtual.La interfaz TAP se puede agregar a OVS utilizando los comandos ovs-vsctl ; luego, cualquier paquete que OVS cambie a la interfaz TAP se transferirá a la máquina virtual mediante un descriptor de archivo.El procedimiento real para crear una máquina virtual puede ser diferente, es decir. Primero, puede crear un puente OVS, luego decirle a la máquina virtual que cree una interfaz conectada a este OVS, o viceversa.
Ahora, si necesitamos poder transferir paquetes entre dos o más máquinas virtuales que se ejecutan en el mismo hipervisor, solo necesitamos crear un puente OVS y agregarle interfaces TAP usando los comandos ovs-vsctl. Los equipos que se necesitan para esto se pueden buscar fácilmente en Google.Puede haber varios puentes OVS en el hipervisor, por ejemplo, así es como funciona Openstack Neutron, o las máquinas virtuales pueden estar en diferentes espacios de nombres para implementar la tenencia múltiple.¿Y si las máquinas virtuales están en diferentes puentes OVS?Para resolver este problema, hay otra herramienta: veth pair. El par Veth se puede representar como un par de interfaces de red conectadas por un cable: todo lo que "vuela" en una interfaz, "vuela" desde otra. El par Veth se utiliza para conectar varios puentes OVS o puentes Linux entre sí. Otro punto importante es que partes del par veth pueden estar en un sistema operativo Linux de espacio de nombres diferente, es decir, el par veth también se puede usar para comunicar el espacio de nombres entre sí a nivel de red.Herramientas de virtualización: libvirt, virsh y más
En los capítulos anteriores examinamos los fundamentos teóricos de la virtualización, en este capítulo hablaremos sobre las herramientas que están disponibles para el usuario directamente para iniciar y cambiar máquinas virtuales en el hipervisor KVM.Consideremos tres componentes principales que cubren el 90 por ciento de todo tipo de operaciones con máquinas virtuales:- libvirt
- virsh CLI
- virt-install
, CLI-, , , qemu_system_x86_64 virt manager, . Cloud-, Openstack, , libvirt.
libvirt
libvirt es un proyecto de código abierto a gran escala que desarrolla un conjunto de herramientas y controladores para administrar hipervisores. No solo admite QEMU / KVM, sino también ESXi, LXC y mucho más.La razón principal de su popularidad es una interfaz estructurada e intuitiva para interactuar a través de un conjunto de archivos XML, además de la capacidad de automatizar a través de una API. Cabe señalar que libvirt no describe todas las funciones posibles del hipervisor, solo proporciona una interfaz conveniente para usar las funciones del hipervisor que son útiles , desde el punto de vista de los participantes del proyecto.Y sí, libvirt es el estándar de facto en el mundo de la virtualización actual. Solo eche un vistazo a la lista de aplicaciones que usan libvirt. La buena noticia sobre libvirt es que todos los paquetes necesarios ya están preinstalados en todos los sistemas operativos host más utilizados: Ubuntu, CentOS y RHEL, por lo que es probable que no tenga que compilar los paquetes necesarios y compilar libvirt. En el peor de los casos, tendrá que usar el instalador por lotes apropiado (apt, yum y similares).Tras la instalación inicial y el inicio, libvirt crea Linux bridge virbr0 y su configuración mínima de forma predeterminada.
La buena noticia sobre libvirt es que todos los paquetes necesarios ya están preinstalados en todos los sistemas operativos host más utilizados: Ubuntu, CentOS y RHEL, por lo que es probable que no tenga que compilar los paquetes necesarios y compilar libvirt. En el peor de los casos, tendrá que usar el instalador por lotes apropiado (apt, yum y similares).Tras la instalación inicial y el inicio, libvirt crea Linux bridge virbr0 y su configuración mínima de forma predeterminada.Es por eso que al instalar Ubuntu Server, por ejemplo, verá en la salida del comando ifconfig Linux bridge virbr0: este es el resultado de ejecutar el demonio libvirtd
Este puente de Linux no se conectará a ninguna interfaz física, sin embargo, se puede usar para comunicar máquinas virtuales dentro de un único hipervisor. Libvirt ciertamente se puede usar junto con OVS, sin embargo, para esto, el usuario debe crear puentes OVS de forma independiente utilizando los comandos OVS apropiados.Cualquier recurso virtual necesario para crear una máquina virtual (cómputo, red, almacenamiento) se representa como un objeto en libvirt. Un conjunto de archivos XML diferentes es responsable del proceso de describir y crear estos objetos.No tiene mucho sentido describir el proceso de creación de redes virtuales y almacenamientos virtuales en detalle, ya que esta aplicación está bien descrita en la documentación de libvirt:La máquina virtual en sí con todos los dispositivos PCI conectados se llama dominio en la terminología de libvirt. Este también es un objeto dentro de libvirt , que se describe en un archivo XML separado.Este archivo XML es, estrictamente hablando, una máquina virtual con todos los recursos virtuales: RAM, procesador, dispositivos de red, discos y más. A menudo, este archivo XML se llama libvirt XML o dump XML.Es poco probable que haya una persona que comprenda todos los parámetros de libvirt XML, sin embargo, esto no es necesario cuando hay documentación.En general, libvirt XML para Ubuntu Desktop Guest OS será bastante simple: 40-50 líneas. Como toda la optimización del rendimiento también se describe en libvirt XML (topología NUMA, topologías de CPU, fijación de CPU, etc.), para funciones de red, libvirt XML puede ser muy complejo y contener varios cientos de líneas. Cualquier fabricante de dispositivos de red que envíe su software como máquinas virtuales ha recomendado ejemplos de libvirt XML.virsh CLI
La utilidad virsh es una línea de comando "nativa" para administrar libvirt. Su objetivo principal es administrar los objetos libvirt descritos como archivos XML. Los ejemplos típicos son iniciar, detener, definir, destruir, etc. Es decir, el ciclo de vida de los objetos: gestión del ciclo de vida.Una descripción de todos los comandos e indicadores de virsh también está disponible en la documentación de libvirt .virt-install
Otra utilidad que se utiliza para interactuar con libvirt. Una de las principales ventajas es que no tiene que lidiar con el formato XML, sino con los indicadores disponibles en virsh-install. El segundo punto importante es el mar de ejemplos e información en la Web.Por lo tanto, no importa qué utilidad utilice, en última instancia, será libvirt lo que controlará el hipervisor, por lo que es importante comprender la arquitectura y los principios de su funcionamiento.
Conclusión
En este artículo, examinamos el conjunto mínimo de conocimientos teóricos necesarios para trabajar con máquinas virtuales. Intencionalmente no di ejemplos prácticos y conclusiones de los equipos, ya que se pueden encontrar tantos ejemplos como desee en la Web, y no me propuse escribir una "guía paso a paso". Si está interesado en un tema o tecnología específicos, deje sus comentarios y escriba preguntas.
Enlaces utiles
Gracias
- Alexander Shalimov , mi colega y experto en el desarrollo de redes virtuales. Para comentarios y ediciones.
- Yevgeny Yakovlev, mi colega y experto en el campo de la virtualización, para comentarios y correcciones.