
Los problemas en el entorno laboral son siempre un desastre. Ocurre cuando vas a casa, y la razón siempre parece estúpida. Recientemente, nos hemos quedado sin memoria en los nodos del clúster de Kubernetes, aunque el nodo se recuperó de inmediato, sin interrupciones visibles. Hoy hablaremos sobre este caso, sobre qué daño sufrimos y cómo pretendemos evitar un problema similar en el futuro.
Caso uno
Sábado 15 de junio de 2019 5:12 p.m.
Blue Matador (sí, ¡nos monitoreamos a nosotros mismos!) Genera una alerta: un evento en uno de los nodos del clúster de producción de Kubernetes: SystemOOM.
17:16
Blue Matador genera una advertencia: EBS Burst Balance es bajo en el volumen raíz del nodo, el lugar donde tuvo lugar el evento SystemOOM. Aunque se produjo una advertencia sobre el Saldo de ráfaga después de una notificación sobre SystemOOM, los datos reales de CloudWatch muestran que el Saldo de ráfaga ha alcanzado un nivel mínimo a las 17:02. La razón de la demora es que las métricas de EBS están constantemente atrasadas entre 10 y 15 minutos, y nuestro sistema no detecta todos los eventos en tiempo real.
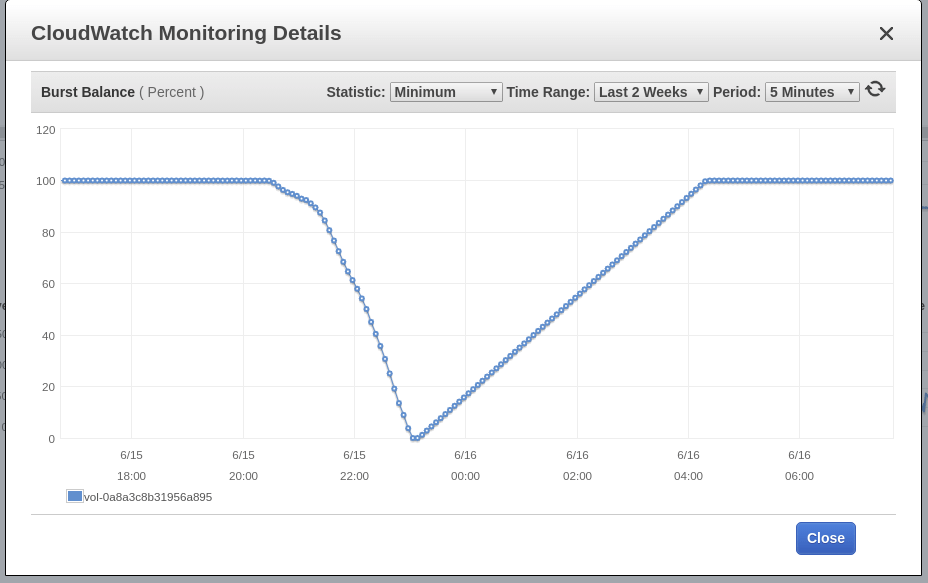
17:18
En este momento vi una alerta y una advertencia. Rápidamente ejecuto kubectl get pods para ver qué daño sufrimos, y me sorprende descubrir que los pods en la aplicación murieron exactamente 0. Realizo nodos superiores de kubectl , pero esta comprobación también muestra que el nodo sospechoso tiene un problema de memoria; Es cierto que ya se ha recuperado y utiliza aproximadamente el 60% de su memoria. Son las 5 p.m., y la cerveza artesanal ya se está calentando. Después de asegurarme de que el nodo funcionara y no se dañara una sola cápsula, decidí que había ocurrido un accidente. En todo caso, lo resolveré el lunes.
Aquí está nuestra correspondencia con la estación de servicio en Slack esa noche:

Caso dos
Sábado 16 de junio de 2019 6:02 p.m.
Blue Matador genera una alerta: el evento ya está en otro nodo, también SystemOOM. Debe haber sido que la estación de servicio en ese momento solo estaba mirando la pantalla del teléfono inteligente porque me escribió y me hizo tomar el evento de inmediato, yo mismo no puedo encender la computadora (¿es hora de reinstalar Windows nuevamente?). Y de nuevo, todo parece normal. No se mata ni una sola cápsula, y el nodo apenas consume el 70% de la memoria.
18:06
Blue Matador genera una advertencia nuevamente: EBS Burst Balance. La segunda vez en un día, lo que significa que no puedo liberar este problema en los frenos. Con CloudWatch sin cambios, Burst Balance se desvió de la norma 2 horas o más antes de que se identificara el problema.
18:11
Voy al registro de datos y miro los datos sobre el consumo de memoria. Veo que justo antes del evento SystemOOM, el nodo sospechoso realmente tomó mucha memoria. El sendero conduce a nuestras vainas de fluidos sumológicos.

Puede ver claramente una desviación brusca en el consumo de memoria, aproximadamente al mismo tiempo que ocurrieron los eventos de SystemOOM. Mi conclusión: fueron estos pods los que tomaron toda la memoria, y cuando sucedió SystemOOM, Kubernetes se dio cuenta de que estos pods podían ser eliminados y reiniciados para devolver la memoria necesaria sin afectar mis otros pods. ¡Bien hecho, Kubernetes!
Entonces, ¿por qué no vi esto el sábado cuando descubrí qué cápsulas se reiniciaron? El hecho es que ejecuto cápsulas de suma fluida en un espacio de nombres separado y con prisa simplemente no pensé en investigarlo.
Conclusión 1: cuando busque pods reiniciados, verifique todos los espacios de nombres.
Habiendo recibido estos datos, calculé que al día siguiente la memoria en otros nodos no terminaría, sin embargo, seguí adelante y reinicié todos los pods sumológicos para que comenzaran a trabajar con un bajo consumo de memoria. A la mañana siguiente, planeo preparar cómo integrar el trabajo sobre el problema en un plan para la semana y no cargar demasiado el domingo por la noche.
23:00
Vi la próxima serie de "Black Mirror" (por cierto, me gustó Miley) y decidí ver cómo estaba el grupo. El consumo de memoria es normal, así que siéntete libre de dejar todo como está por la noche.
Arreglar
El lunes, hice tiempo para este problema. No está de más cazar con ella todas las noches. Lo que sé en este momento:
- Los contenedores con suma fluidez engullen una tonelada de memoria;
- El evento SystemOOM está precedido por una alta actividad de disco, pero no sé cuál.
Al principio, pensé que los contenedores de sumología fluida son aceptados para comer memoria ante una afluencia repentina de troncos. Sin embargo, después de verificar Sumologic, vi que los registros se usaron de manera estable y, al mismo tiempo, cuando hubo problemas, no hubo un aumento en estos registros.
Un poco en Google, encontré esta tarea en github , que sugiere ajustar algunas configuraciones de Ruby, para reducir el consumo de memoria. Decidí probarlo, agregar una variable de entorno a la especificación del pod y ejecutarlo:
env: - name: RUBY_GC_HEAP_OLDOBJECT_LIMIT_FACTOR value: "0.9"
Mirando a través del manifiesto fluentd-sumologic, noté que no definía las solicitudes y restricciones de recursos. Estoy empezando a sospechar que la solución RUBY_GCP_HEAP hará algún tipo de milagro, por lo que ahora tiene sentido establecer límites de consumo de memoria. Incluso si no soluciono el problema de memoria, al menos será posible limitar su consumo a este conjunto de pods. Usando kubectl top pods | grep fluentd-sumologic , ya sé cuántos recursos solicitar:
resources: requests: memory: "128Mi" cpu: "100m" limits: memory: "1024Mi" cpu: "250m"
Conclusión 2: Establezca límites de recursos, especialmente para aplicaciones de terceros.
Verificación de ejecución
Después de unos días, confirmo que el método anterior funciona. El consumo de memoria fue estable y no hubo problemas con ningún componente de Kubernetes, EC2 y EBS. Ahora está claro lo importante que es determinar las solicitudes y restricciones de recursos para todos los pods que ejecuto, y esto es lo que hay que hacer: aplicar una combinación de límites de recursos predeterminados y cuotas de recursos .
El último misterio sin resolver es EBS Burst Balance, que coincidió con el evento SystemOOM. Sé que cuando hay poca memoria, el sistema operativo utiliza el espacio de intercambio para no quedarse completamente sin memoria. Pero no nací ayer y soy consciente de que Kubernetes ni siquiera se iniciará en los servidores donde se activa el archivo de página. Solo queriendo asegurarme, subí a mis nodos a través de SSH, para verificar si el archivo de página estaba activado; Utilicé tanto la memoria libre como la del área de intercambio. El archivo no fue activado.
Y dado que el intercambio no funciona, tengo más pistas sobre qué causó el crecimiento de los flujos de E / S, por lo que el nodo casi se quedó sin memoria, no. En realidad, tengo un presentimiento: el módulo de sumología fluida estaba escribiendo una tonelada de mensajes de registro en este momento, posiblemente incluso un mensaje de registro relacionado con la configuración de Ruby GC. También es posible que haya otras fuentes de mensajes de Kubernetes o de diario que se vuelvan excesivamente productivos cuando se agote la memoria, y los eliminé al configurar con fluidez. Desafortunadamente, ya no tengo acceso a los archivos de registro grabados inmediatamente antes del mal funcionamiento, y ahora no puedo profundizar más.
Conclusión 3: Si bien existe una oportunidad, profundice al analizar las causas raíz, sea cual sea el problema.
Conclusión
Y aunque no llegué a la raíz de las causas, estoy seguro de que no son necesarias para evitar el mismo mal funcionamiento en el futuro. El tiempo es dinero, pero he estado ocupado durante demasiado tiempo, y después de eso también escribí esta publicación para ti. Y como usamos Blue Matador , tratamos con tales fallas con gran detalle, así que me permito liberar algo en los frenos sin distraerme del proyecto principal.