Habr, hola.
Esta publicación es una breve descripción de los algoritmos generales de aprendizaje automático. Cada uno está acompañado de una breve descripción, guías y enlaces útiles.
Método de componente principal (PCA) / SVD
Este es uno de los algoritmos básicos de aprendizaje automático. Le permite reducir la dimensionalidad de los datos, perdiendo la menor cantidad de información. Se utiliza en muchos campos, como el reconocimiento de objetos, la visión por computadora, la compresión de datos, etc. El cálculo de los componentes principales se reduce al cálculo de los vectores propios y los valores propios de la matriz de covarianza de los datos de origen o a la descomposición singular de la matriz de datos.
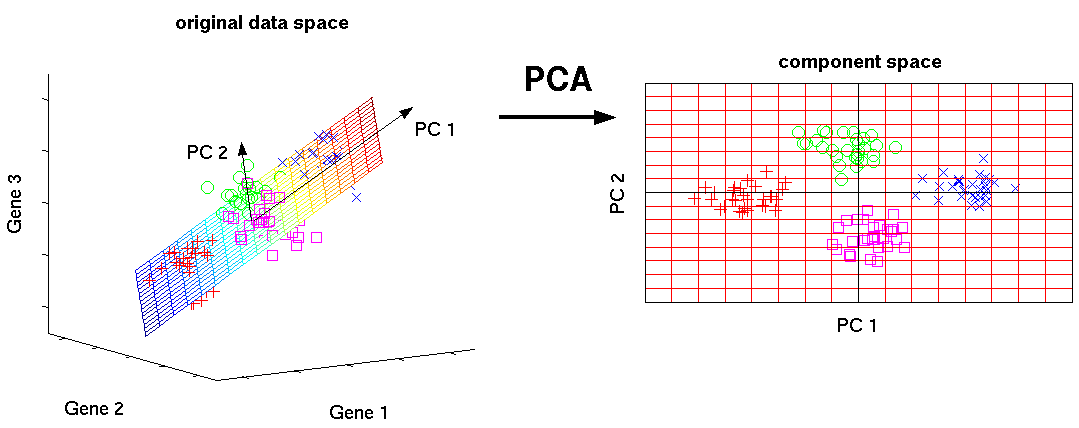
SVD es una forma de calcular componentes ordenados.
Enlaces utiles:
Guía introductoria
Método de mínimos cuadrados
El método de mínimos cuadrados es un método matemático utilizado para resolver varios problemas, basado en minimizar la suma de los cuadrados de las desviaciones de algunas funciones de las variables deseadas. Se puede usar para "resolver" sistemas de ecuaciones sobredeterminados (cuando el número de ecuaciones excede el número de incógnitas), para encontrar una solución en el caso de sistemas de ecuaciones no lineales ordinarios (no redefinidos) y también para aproximar los valores de puntos de una función.
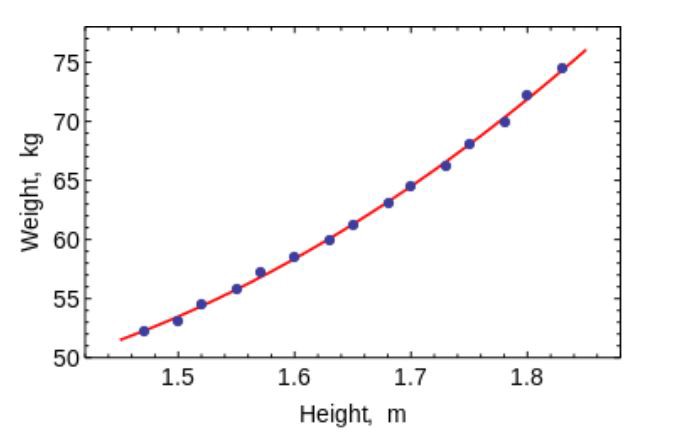
Use este algoritmo para ajustar curvas / regresiones simples.
Enlaces utiles:
Guía introductoria
Regresión lineal limitada
El método de mínimos cuadrados puede confundir valores atípicos, campos falsos, etc. Se necesitan restricciones para reducir la varianza de la línea que colocamos en el conjunto de datos. La solución correcta es ajustar un modelo de regresión lineal que garantice que los pesos no se comporten "mal". Los modelos pueden tener la norma L1 (LASSO) o L2 (Regresión de cresta) o ambas (regresión elástica).
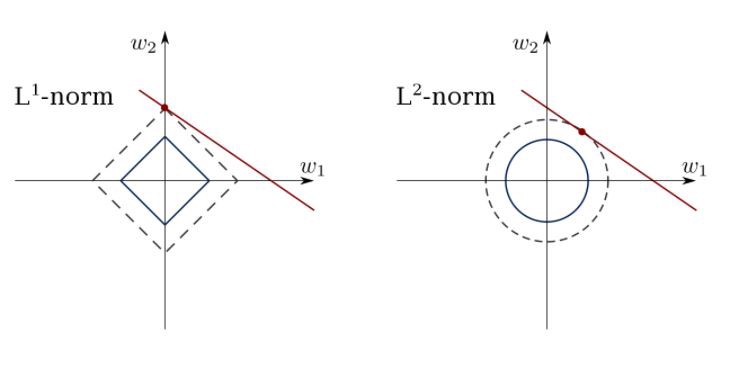
Use este algoritmo para hacer coincidir las líneas de regresión restringidas, evitando la anulación.
Enlace útil:
Guías introductorias:
Método K-means
El algoritmo de agrupamiento incontrolado favorito de todos. Dado un conjunto de datos en forma de vectores, podemos crear grupos de puntos basados en las distancias entre ellos. Este es uno de los algoritmos de aprendizaje automático que mueve secuencialmente los centros de los grupos y luego agrupa los puntos con cada centro del grupo. La entrada es el número de clústeres que se crearán y el número de iteraciones.
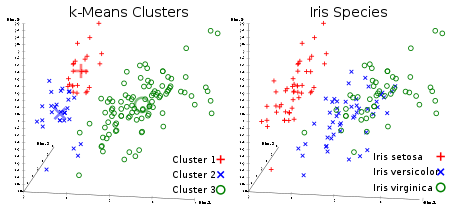
Enlace útil:
Guías introductorias:
Regresión logística
La regresión logística está limitada por la regresión lineal con no linealidad (principalmente utilizando la función sigmoide o tanh) después de aplicar pesos, por lo tanto, la limitación de salida está cerca de las clases +/- (que es 1 y 0 en el caso de un sigmoide). Las funciones de pérdida de entropía cruzada se optimizan utilizando el método de descenso de gradiente.
Nota para principiantes: la regresión logística se utiliza para la clasificación, no para la regresión. En general, es similar a una red neuronal de capa única. Entrenado utilizando técnicas de optimización como el descenso de gradiente o L-BFGS. Los desarrolladores de PNL a menudo lo usan, llamándolo "clasificación de entropía máxima".

Use LR para entrenar clasificadores simples pero muy "fuertes".
Enlace útil:
Guía introductoria
SVM (Método de vector de soporte)
SVM es un modelo lineal como la regresión lineal / logística. La diferencia es que tiene una función de pérdida basada en el margen. Puede optimizar la función de pérdida utilizando métodos de optimización como L-BFGS o SGD.

Una cosa única que SVM puede hacer es aprender clasificadores de clases.
SVM puede usarse para entrenar clasificadores (incluso regresores).
Enlace útil:
Guías introductorias:
Redes neuronales de distribución directa.
Básicamente, estos son clasificadores multinivel de regresión logística. Muchas capas de pesos están separadas por no linealidades (sigmoide, tanh, relu + softmax y cool selu nuevo). También se les llama perceptrones multicapa. Los FFNN se pueden utilizar para la clasificación y la "capacitación sin maestros" como codificadores automáticos.

FFNN se puede utilizar para entrenar el clasificador o extraer funciones como codificadores automáticos.
Enlaces utiles:
Guías introductorias:
Redes neuronales convolucionales
Casi todos los logros modernos en el campo del aprendizaje automático se lograron utilizando redes neuronales convolucionales. Se utilizan para clasificar imágenes, detectar objetos o incluso segmentar imágenes. Inventado por Jan Lekun a principios de los 90, las redes tienen capas convolucionales que actúan como extractores jerárquicos de objetos. Puede usarlos para trabajar con texto (e incluso para trabajar con gráficos).
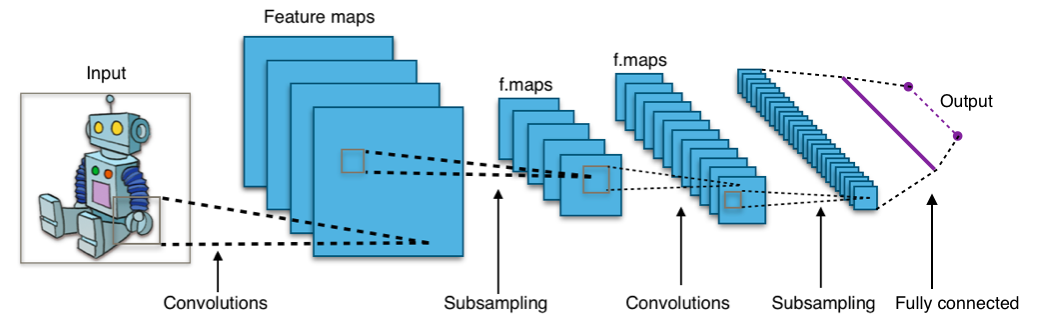
Enlaces utiles:
Guías introductorias:
Redes neuronales recurrentes (RNN)
Las secuencias de modelo de RNNs aplican el mismo conjunto de pesos de forma recursiva al estado del agregador en el tiempo ty la entrada en el tiempo t. Los RNN puros rara vez se usan ahora, pero sus contrapartes, como LSTM y GRU, son los más avanzados en la mayoría de las tareas de modelado de secuencias. LSTM, que se utiliza en lugar de una simple capa densa en RNN puro.

Use RNN para cualquier tarea de clasificación de texto, traducción automática, modelado de idiomas.
Enlaces utiles:
Guías introductorias:
Campos aleatorios condicionales (CRF)
Se usan para el modelado de secuencias, como los RNN, y se pueden usar en combinación con los RNN. También se pueden usar en otras tareas de pronóstico estructurado, por ejemplo, en la segmentación de imágenes. El CRF modela cada elemento de la secuencia (por ejemplo, una oración), de modo que los vecinos influyan en la etiqueta del componente en la secuencia, y no todas las etiquetas que sean independientes entre sí.
Use CRF para vincular secuencias (en texto, imagen, series de tiempo, ADN, etc.).
Enlace útil:
Guías introductorias:
Árboles de decisión y bosques al azar
Uno de los algoritmos de aprendizaje automático más comunes. Utilizado en estadísticas y análisis de datos para modelos de pronóstico. La estructura es "hojas" y "ramas". Los atributos de los que depende la función objetivo se registran en las "ramas" del árbol de decisión, los valores de la función objetivo se escriben en las "hojas", y los atributos que distinguen los casos se registran en los nodos restantes.
Para clasificar un nuevo caso, debe bajar del árbol a la hoja y emitir el valor correspondiente. El objetivo es crear un modelo que prediga el valor de la variable objetivo en función de varias variables de entrada.
Enlaces utiles:
Guías introductorias:
Aprenderá más información sobre aprendizaje automático y ciencia de datos suscribiéndose a mi cuenta en
Habré y el canal de Telegram
Neuron . No te saltes futuros artículos.
Todo el conocimiento!