Durante casi un año he estado usando el servicio Yandex Music y todo me conviene. Pero hay una página interesante en este servicio: la historia. Almacena todas las pistas que se han escuchado en orden cronológico. Y, por supuesto, quería descargarlo y analizar lo que había escuchado allí todo el tiempo.

Primeros intentos
Comenzando a lidiar con esta página, inmediatamente me encontré con un problema. El servicio no descarga todas las pistas a la vez, sino solo a medida que se desplaza. No quería descargar el sniffer y comprender el tráfico, y no tenía habilidades en este asunto en ese momento. Por lo tanto, decidí ir más simplemente emulando el navegador usando selenio.
El guión fue escrito. Pero trabajó muy inestable y durante mucho tiempo. Pero se las arregló para cargar la historia. Después de un análisis simple, dejé el guión sin modificaciones, hasta que después de un tiempo nuevamente no quise descargar la historia. Con la esperanza de lo mejor, lo lancé. Y, por supuesto, dio un error. Entonces me di cuenta de que era hora de hacer todo humanamente.
Opción de trabajo
Para el análisis del tráfico, elegí Fiddler para mí debido a una interfaz más poderosa para el tráfico http, a diferencia de wireshark. Al ejecutar el sniffer, esperaba ver solicitudes de API con un token. Pero no Nuestro objetivo fue en music.yandex.ru/handlers/library.jsx . Y las solicitudes a la misma requirieron autorización completa en el sitio. Comenzaremos con ella.
Iniciar sesión
Nada complicado aquí. Vamos a passport.yandex.ru/auth , buscamos los parámetros para las solicitudes y hacemos dos solicitudes de autorización.
auth_page = self.get('/auth').text csrf_token, process_uuid = self.find_auth_data(auth_page) auth_login = self.post( '/registration-validations/auth/multi_step/start', data={'csrf_token': csrf_token, 'process_uuid': process_uuid, 'login': self.login} ).json() auth_password = self.post( '/registration-validations/auth/multi_step/commit_password', data={'csrf_token': csrf_token, 'track_id': auth_login['track_id'], 'password': self.password} ).json()
Y entonces iniciamos sesión.
Descargar historial
A continuación, vamos a music.yandex.ru/user/<user>/history , donde también recogemos un par de parámetros que nos son útiles cuando recibimos información sobre las pistas. Ahora puedes descargar la historia. Obtenemos las music.yandex.ru/handlers/library.jsx las music.yandex.ru/handlers/library.jsx en music.yandex.ru/handlers/library.jsx con los parámetros {'owner': <user>, 'filter': 'history', 'likeFilter': 'favorite', 'lang': 'ru', 'external-domain': 'music.yandex.ru', 'overembed': 'false', 'ncrnd': '0.9546193023464256'} . Estaba interesado en el parámetro ncrnd aquí. Al realizar solicitudes, Yandex siempre asigna valores diferentes a este parámetro, pero todo funciona igual. De vuelta obtenemos el historial en forma de pistas de identificación e información detallada sobre las diez pistas principales. A partir de la información detallada de la pista, puede guardar una gran cantidad de datos interesantes para su posterior análisis. Por ejemplo, año de lanzamiento, duración de la pista y género. La información sobre el resto de las pistas se obtiene de music.yandex.ru/handlers/track-entries.jsx . Guardamos todo este negocio en csv y lo pasamos al análisis.
Análisis
Para el análisis, utilizamos herramientas estándar en forma de pandas y matplotlib.
import pandas as pd import matplotlib.pyplot as plt df = pd.read_csv('statistics.csv') df.head(3)
Cambie None de Python por NaN y deséchelos.
df = df.replace('None', pd.np.nan).dropna()
Comencemos con uno simple. Veamos el tiempo que pasamos escuchando todas las pistas.
duration_sec = df['duration_sec'].astype('int64').sum() ss = duration_sec % 60 m = duration_sec // 60 mm = m % 60 h = m // 60 hh = h % 60 f'{h // 24} {hh}:{mm}:{ss}'
'15 15:30:14'
Pero aquí puedes discutir sobre la precisión de esta figura, porque no está claro qué parte de la pista necesitas escuchar, Yandex la agregó a la historia.
Ahora veamos la distribución de pistas por año de lanzamiento.
plt.rcParams['figure.figsize'] = [15, 5] plt.hist(df['year'].sort_values(), bins=len(df['year'].unique())) plt.xticks(rotation='vertical') plt.show()
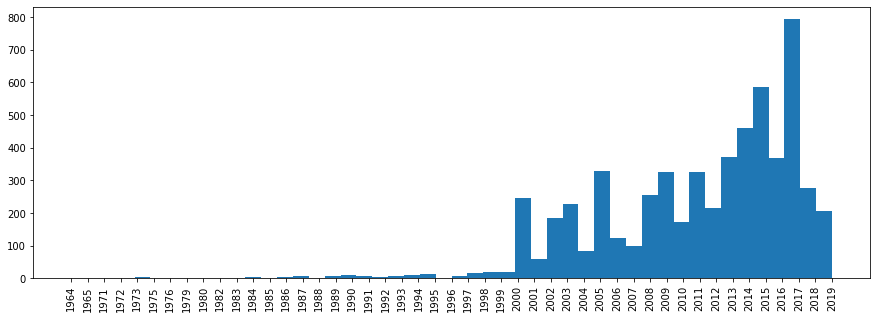
Aquí, lo mismo no es tan simple, ya que las diversas colecciones de "Best Hits" tendrán un año posterior.
Otras estadísticas se construirán sobre un principio muy similar. Daré un ejemplo de las pistas más escuchadas
df.groupby(['track_id', 'artist','track'])['track_id'].count().sort_values(ascending=False).head()
y pistas más reproducidas del artista
artist_name = 'Coldplay' df.groupby([ 'artist_id', 'track_id', 'artist', 'track' ])['artist_id'].count().sort_values(ascending=False)[:,:,artist_name].head(5)
El código completo se puede encontrar aquí.