
Con la llegada de los teléfonos móviles con cámaras de alta calidad, comenzamos a tomar más y más fotos y videos de momentos brillantes y memorables en nuestras vidas. Muchos de nosotros tenemos archivos de fotos que se extienden por décadas y comprenden miles de imágenes, lo que hace que sea cada vez más difícil navegar por ellas. Solo recuerde cuánto tiempo tardó en encontrar una imagen de interés hace solo unos años.
Uno de los objetivos de Mail.ru Cloud es proporcionar los medios más útiles para acceder y buscar sus propios archivos de fotos y videos. Para este propósito, nosotros en Mail.ru Computer Vision Team hemos creado e implementado sistemas para el procesamiento inteligente de imágenes: búsqueda por objeto, por escena, por cara, etc. Otra tecnología espectacular es el reconocimiento histórico. Hoy les voy a contar cómo hicimos esto realidad usando Deep Learning.
Imagina la situación: regresas de tus vacaciones con un montón de fotos. Hablando con tus amigos, se te pide que muestres una imagen de un lugar que valga la pena ver, como palacio, castillo, pirámide, templo, lago, cascada, montaña, etc. Te apresuras a desplazarte por la carpeta de tu galería tratando de encontrar una que sea realmente buena. Lo más probable es que se pierda entre cientos de imágenes, y usted dice que lo mostrará más tarde.
Resolvemos este problema agrupando las fotos de los usuarios en álbumes. Esto le permitirá encontrar las imágenes que necesita con solo unos pocos clics. Ahora tenemos álbumes compilados por cara, por objeto y por escena, y también por hito.
Las fotos con puntos de referencia son esenciales porque a menudo capturan lo más destacado de nuestras vidas (viajes, por ejemplo). Estas pueden ser imágenes con alguna arquitectura o desierto en el fondo. Es por eso que buscamos localizar tales imágenes y ponerlas a disposición de los usuarios.
Peculiaridades del reconocimiento histórico
Aquí hay un matiz: uno no solo enseña un modelo y hace que reconozca los puntos de referencia de inmediato, hay una serie de desafíos.
Primero, no podemos decir claramente qué es realmente un "hito". No podemos decir por qué un edificio es un hito, mientras que otro al lado no lo es. No es un concepto formalizado, lo que hace que sea más complicado establecer la tarea de reconocimiento.
En segundo lugar, los puntos de referencia son increíblemente diversos. Estos pueden ser edificios de valor histórico o cultural, como un templo, palacio o castillo. Alternativamente, estos pueden ser todo tipo de monumentos. O características naturales: lagos, cañones, cascadas, etc. Además, hay un modelo único que debería poder encontrar todos esos puntos de referencia.
Tercero, las imágenes con puntos de referencia son extremadamente pocas. Según nuestras estimaciones, representan solo del 1 al 3 por ciento de las fotos de los usuarios. Es por eso que no podemos permitirnos cometer errores en el reconocimiento porque si le mostramos a alguien una fotografía sin un hito, será bastante obvio y causará una reacción adversa. O, por el contrario, imagine que muestra una foto con un lugar de interés en Nueva York a una persona que nunca ha estado en los Estados Unidos. Por lo tanto, el modelo de reconocimiento debe tener una FPR baja (tasa de falsos positivos).
Cuarto, alrededor del 50% de los usuarios o incluso más suelen deshabilitar el almacenamiento de datos geográficos. Necesitamos tener esto en cuenta y usar solo la imagen en sí para identificar la ubicación. Hoy en día, la mayoría de los servicios capaces de manejar puntos de referencia de alguna manera usan geodatos de propiedades de imagen. Sin embargo, nuestros requisitos iniciales fueron más estrictos.
Ahora déjame mostrarte algunos ejemplos.
Aquí hay tres objetos parecidos, tres catedrales góticas en Francia. A la izquierda está la catedral de Amiens, la del medio es la catedral de Reims y Notre-Dame de Paris a la derecha.

Incluso un humano necesita algo de tiempo para mirar de cerca y ver que se trata de catedrales diferentes, pero el motor debería ser capaz de hacer lo mismo, e incluso más rápido que un humano.
Aquí hay otro desafío: las tres fotos aquí muestran la toma de Notre-Dame de Paris desde diferentes ángulos. Las fotos son bastante diferentes, pero aún deben reconocerse y recuperarse.

Las características naturales son completamente diferentes de la arquitectura. A la izquierda está Cesarea en Israel, a la derecha está Englischer Garten en Munich.

Estas fotos le dan al modelo muy pocas pistas para adivinar.
Nuestro metodo
Nuestro método se basa completamente en redes neuronales convolucionales profundas. La estrategia de capacitación que elegimos fue el llamado aprendizaje curricular, que significa aprender en varios pasos. Para lograr una mayor eficiencia con y sin datos geográficos disponibles, hicimos una inferencia específica. Déjame contarte sobre cada paso con más detalle.
Conjunto de datos
Los datos son el combustible del aprendizaje automático. En primer lugar, tuvimos que reunir un conjunto de datos para enseñar el modelo.
Dividimos el mundo en 4 regiones, cada una de las cuales se usa en un paso específico del proceso de aprendizaje. Luego, seleccionamos países en cada región, seleccionamos una lista de ciudades para cada país y recopilamos un banco de fotos. A continuación hay algunos ejemplos.

Primero, intentamos que nuestro modelo aprendiera de la base de datos obtenida. Los resultados fueron pobres. Nuestro análisis mostró que los datos estaban sucios. Había demasiado ruido interfiriendo con el reconocimiento de cada punto de referencia. ¿Qué íbamos a hacer? Sería costoso, engorroso y no demasiado sabio revisar manualmente la mayor parte de los datos. Por lo tanto, diseñamos un proceso para la limpieza automática de la base de datos donde el manejo manual se usa solo en un paso: seleccionamos de 3 a 5 fotografías de referencia para cada punto de referencia que definitivamente mostraban el objeto deseado en un ángulo más o menos adecuado. Funciona lo suficientemente rápido porque la cantidad de dichos datos de referencia es pequeña en comparación con toda la base de datos. Luego se realiza una limpieza automática basada en redes neuronales convolucionales profundas.
Más adelante, voy a utilizar el término "incrustación" con el que me refiero a lo siguiente. Tenemos una red neuronal convolucional. Lo entrenamos para clasificar objetos, luego cortamos la última capa de clasificación, seleccionamos algunas imágenes, las analizamos por la red y obtuvimos un vector numérico en la salida. Esto es lo que llamaré incrustación.
Como dije antes, organizamos nuestro proceso de aprendizaje en varios pasos correspondientes a partes de nuestra base de datos. Entonces, primero, tomamos la red neuronal del paso anterior o la red de inicialización.
Tenemos fotos de referencia de un hito, las procesamos por la red y obtenemos varias incrustaciones. Ahora podemos proceder a la limpieza de datos. Tomamos todas las imágenes del conjunto de datos para el punto de referencia y también procesamos cada una por la red. Obtenemos algunas incrustaciones y determinamos la distancia a las incrustaciones de referencia para cada una. Luego, determinamos la distancia promedio y, si excede algún umbral que es un parámetro del algoritmo, tratamos el objeto como un no hito. Si la distancia promedio es menor que el umbral, conservamos la fotografía.
Como resultado, teníamos una base de datos que contenía más de 11 mil puntos de referencia de más de 500 ciudades en 70 países, más de 2.3 millones de fotos. Recuerde que la mayor parte de las fotografías no tiene puntos de referencia. Necesitamos decírselo a nuestros modelos de alguna manera. Por esta razón, agregamos 900 mil fotos sin puntos de referencia a nuestra base de datos y capacitamos a nuestro modelo con el conjunto de datos resultante.
Introdujimos una prueba fuera de línea para medir la calidad del aprendizaje. Dado que los puntos de referencia ocurren solo en 1 a 3% de todas las fotos, compilamos manualmente un conjunto de 290 imágenes que mostraban un punto de referencia. Esas fotos eran bastante diversas y complejas, con una gran cantidad de objetos tomados desde diferentes ángulos para hacer la prueba lo más difícil posible para el modelo. Siguiendo el mismo patrón, seleccionamos 11 mil fotografías sin puntos de referencia, también bastante complicadas, e intentamos encontrar objetos que se parecieran mucho a los puntos de referencia en nuestra base de datos.
Para evaluar la calidad del aprendizaje, medimos la precisión de nuestro modelo utilizando fotos con y sin puntos de referencia. Estas son nuestras dos métricas principales.
Enfoques existentes
Hay relativamente poca información sobre el reconocimiento de puntos de referencia en la literatura. La mayoría de las soluciones se basan en características locales. La idea principal es que tenemos una imagen de consulta y una imagen de la base de datos. Las características locales (puntos clave) se encuentran y luego se combinan. Si el número de coincidencias es lo suficientemente grande, concluimos que hemos encontrado un punto de referencia.
Actualmente, el mejor método es DELF (características locales profundas) que ofrece Google, que combina características locales que coinciden con el aprendizaje profundo. Al tener una imagen de entrada procesada por la red convolucional, obtenemos algunas características DELF.
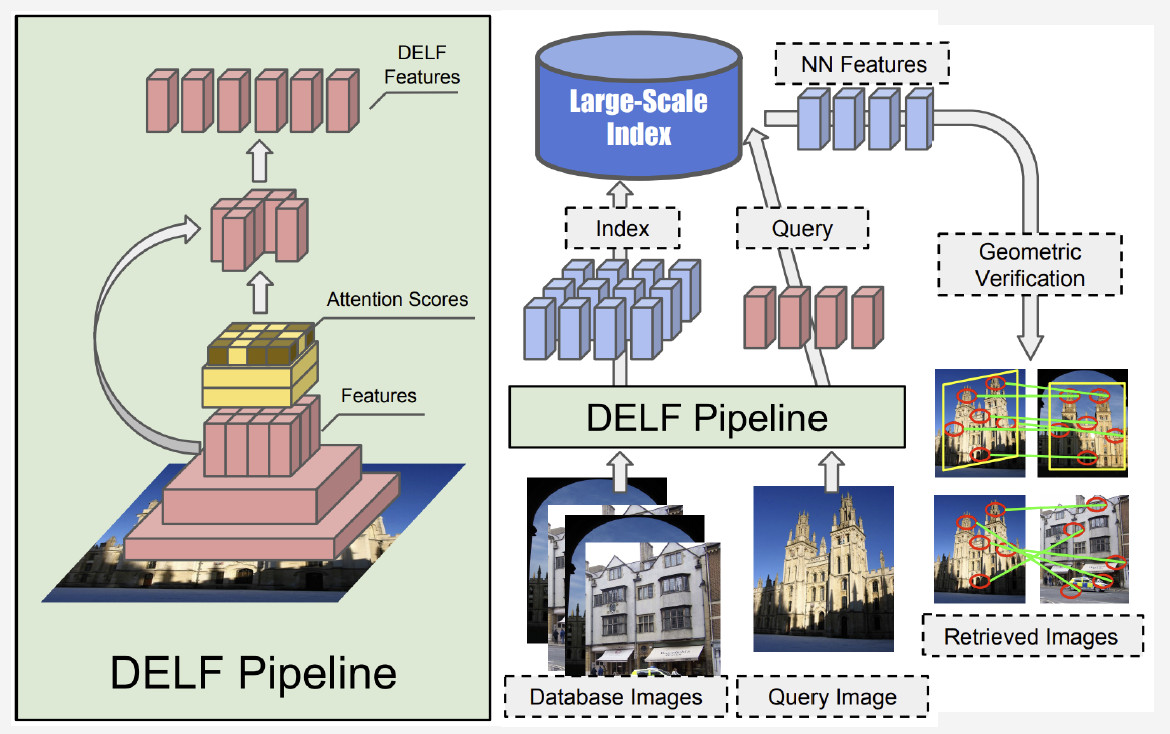
¿Cómo funciona el reconocimiento de puntos de referencia? Tenemos un banco de fotos y una imagen de entrada, y queremos saber si muestra un hito o no. Al ejecutar la red DELF de todas las fotos, se pueden obtener las características correspondientes para la base de datos y la imagen de entrada. Luego realizamos una búsqueda por el método de vecino más cercano y obtenemos imágenes candidatas con características en la salida. Utilizamos la verificación geométrica para que coincida con las características: si tiene éxito, concluimos que la imagen muestra un hito.
Red neuronal convolucional
La capacitación previa es crucial para el aprendizaje profundo. Entonces utilizamos una base de datos de escenas para entrenar previamente nuestra red neuronal. ¿Por qué de esta manera? Una escena es un objeto múltiple que comprende una gran cantidad de otros objetos. Landmark es una instancia de una escena. Al entrenar previamente el modelo con dicha base de datos, podemos darle una idea de algunas características de bajo nivel que luego se pueden generalizar para un reconocimiento exitoso de puntos de referencia.
Utilizamos una red neuronal de la familia de redes residuales como modelo. La diferencia crítica de tales redes es que usan un bloque residual que incluye una conexión de salto que permite que una señal salte sobre capas con pesos y pase libremente. Dicha arquitectura permite entrenar redes profundas con un alto nivel de calidad y controlar el efecto de gradiente de fuga, que es esencial para el entrenamiento.
Nuestro modelo es Wide ResNet-50-2, una versión de ResNet-50 donde el número de convoluciones en el bloque de cuello de botella interno se duplica.

La red funciona muy bien. Lo probamos con nuestra base de datos de escenas, y aquí están los resultados:
Wide ResNet funcionó casi el doble de rápido que ResNet-200. Después de todo, la velocidad de funcionamiento es crucial para la producción. Dadas todas estas consideraciones, elegimos Wide ResNet-50-2 como nuestra red neuronal principal.
Entrenamiento
Necesitamos una función de pérdida para entrenar nuestra red. Decidimos utilizar un enfoque de aprendizaje métrico para elegirlo: se entrena una red neuronal para que los elementos de la misma clase se agrupen en un grupo, mientras que los grupos para diferentes clases se deben separar tanto como sea posible. Para los puntos de referencia, utilizamos la pérdida de centro que arrastra elementos de una clase hacia algún centro. Una característica importante de este enfoque es que no requiere muestreo negativo, lo que se convierte en algo bastante difícil de hacer en épocas posteriores.
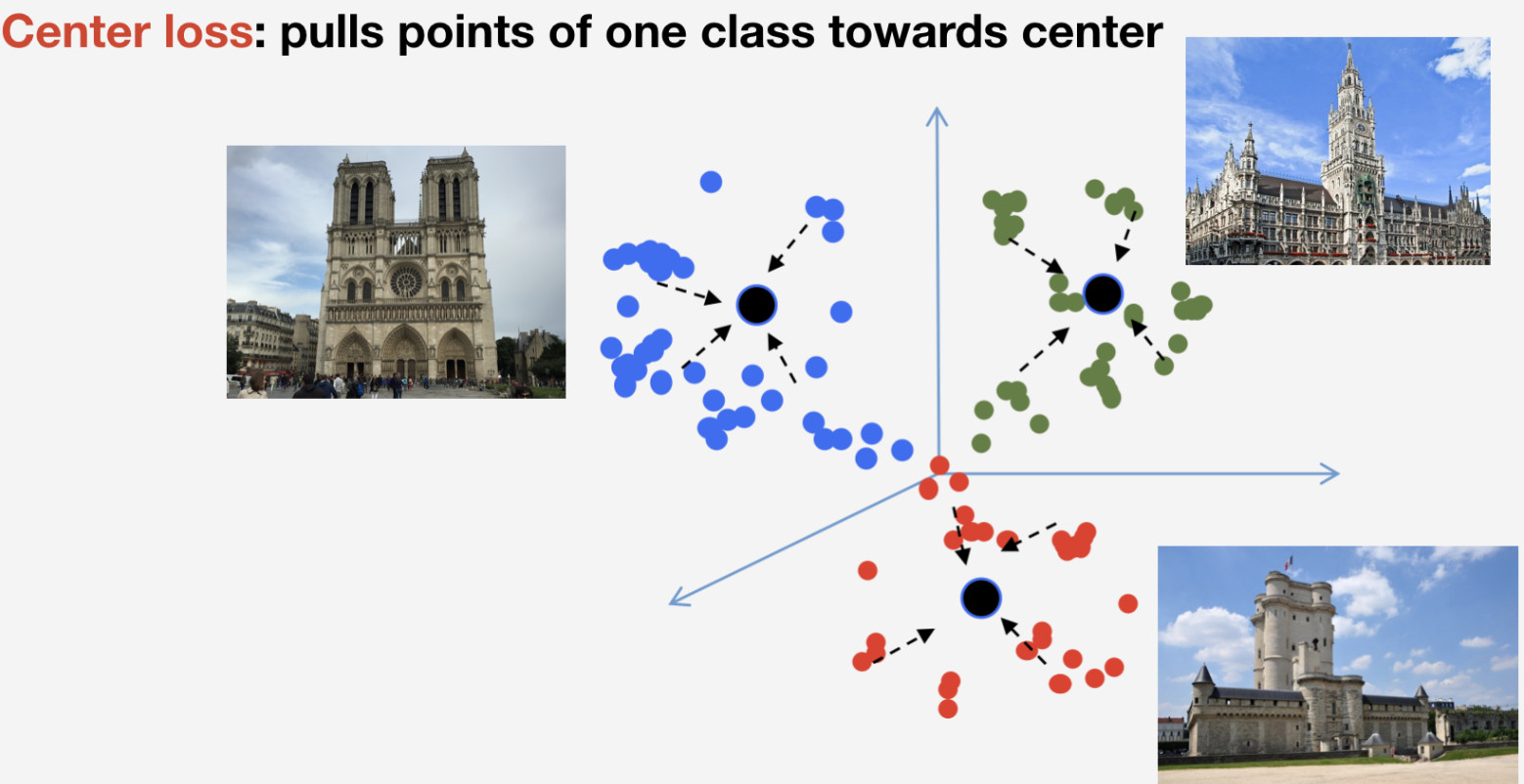
Recuerde que tenemos n clases de puntos de referencia y una clase más de "no puntos de referencia" para los que no se utiliza la pérdida de centro. Implicamos que un punto de referencia es uno y el mismo objeto, y tiene estructura, por lo que tiene sentido determinar su centro. En cuanto a la no referencia, puede referirse a lo que sea, por lo que no tiene sentido determinar el centro.
Luego juntamos todo esto, y existe nuestro modelo de capacitación. Se compone de tres partes principales:
- Amplia red neuronal convolucional ResNet 50-2 pre-entrenada con una base de datos de escenas;
- Parte de incrustación que comprende una capa totalmente conectada y una capa de norma Batch
- Clasificador que es una capa totalmente conectada, seguida de un par compuesto por pérdida Softmax y pérdida central.

Como recordará, nuestra base de datos está dividida en 4 partes por región. Utilizamos estas 4 partes en un paradigma de aprendizaje curricular. Tenemos un conjunto de datos actual y, en cada etapa del aprendizaje, agregamos otra parte del mundo para obtener un nuevo conjunto de datos para capacitación.
El modelo consta de tres partes, y utilizamos una tasa de aprendizaje específica para cada una en el proceso de capacitación. Esto es necesario para que la red pueda aprender puntos de referencia de una nueva parte del conjunto de datos que hemos agregado y recordar datos ya aprendidos. Muchos experimentos demostraron que este enfoque es el más eficiente.
Entonces, hemos entrenado nuestro modelo. Ahora tenemos que darnos cuenta de cómo funciona. Usemos el mapa de activación de clase para encontrar la parte de la imagen a la que nuestra red neuronal reacciona más fácilmente. La siguiente imagen muestra imágenes de entrada en la primera fila, y las mismas imágenes superpuestas con el mapa de activación de clase de la red que hemos entrenado en el paso anterior se muestran en la segunda fila.

El mapa de calor muestra qué partes de la imagen son más atendidas por la red. Como se muestra en el mapa de activación de clase, nuestra red neuronal ha aprendido el concepto de punto de referencia con éxito.
Inferencia
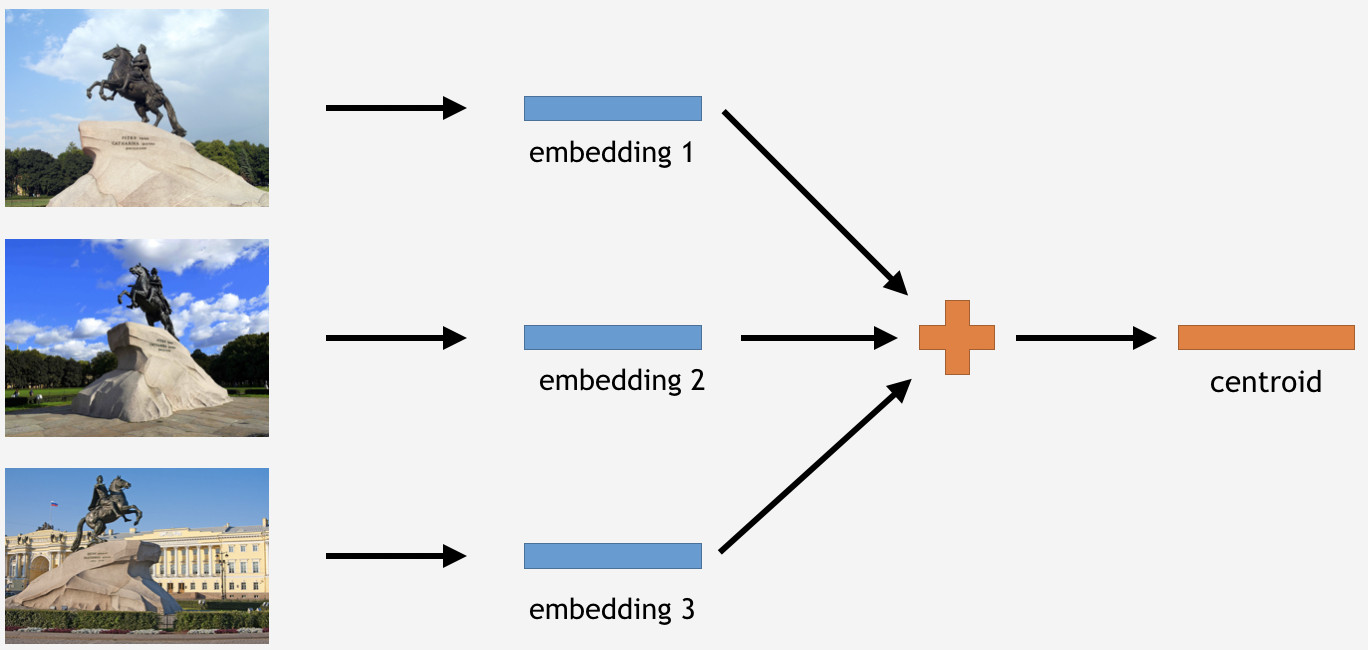
Ahora necesitamos usar este conocimiento de alguna manera para hacer las cosas. Como hemos utilizado la pérdida de centro para el entrenamiento, en el caso de inferencia, parece ser bastante lógico determinar los centroides para puntos de referencia también.
Para hacer esto, tomamos una parte de las imágenes del conjunto de entrenamiento para algún hito, por ejemplo, el Jinete de Bronce en San Petersburgo. Luego los tenemos procesados por la red, obtener incrustaciones, promediar y derivar un centroide.
Sin embargo, aquí hay una pregunta: ¿cuántos centroides por punto de referencia tiene sentido derivar? Inicialmente, parecía ser claro y lógico decir: un centroide. No exactamente, como resultó. Inicialmente decidimos hacer un solo centroide también, y el resultado no fue malo. Entonces, ¿por qué varios centroides?
Primero, los datos que tenemos no son tan limpios. Aunque hemos limpiado el conjunto de datos, eliminamos solo los datos de desperdicio obvios. Sin embargo, todavía podría haber imágenes que obviamente no se desperdician sino que afectan negativamente el resultado.
Por ejemplo, tengo una clase histórica en el Palacio de Invierno en San Petersburgo. Quiero derivar un centroide para ello. Sin embargo, su conjunto de datos incluye algunas fotos con la Plaza del Palacio y el arco de la Sede General, porque estos objetos están cerca uno del otro. Si se determina el centroide para todas las imágenes, el resultado no será tan estable. Lo que tenemos que hacer es agrupar de alguna manera sus incrustaciones derivadas de la red neuronal, tomar solo el centroide que trata con el Palacio de Invierno y promediar usando los datos resultantes.

En segundo lugar, las fotografías podrían haber sido tomadas desde diferentes ángulos.
Aquí hay un ejemplo de tal comportamiento ilustrado con el Campanario de Brujas. Se han derivado dos centroides para ello. En la fila superior de la imagen, están las fotos que están más cerca del primer centroide, y en la segunda fila, las que están más cerca del segundo centroide.

El primer centroide trata con más fotografías "grandiosas" que fueron tomadas en el mercado de Brujas a corta distancia. El segundo centroide trata con fotografías tomadas desde la distancia en calles particulares.
Como resultado, al derivar varios centroides por clase de punto de referencia, podemos reflexionar sobre la inferencia de diferentes ángulos de cámara para ese punto de referencia.
Entonces, ¿cómo obtenemos esos conjuntos para derivar los centroides? Aplicamos la agrupación jerárquica (enlace completo) a los conjuntos de datos para cada punto de referencia. Lo usamos para encontrar grupos válidos de los cuales se derivarán los centroides. Por agrupaciones válidas nos referimos a aquellas que comprenden al menos 50 fotografías como resultado de la agrupación. Los otros grupos son rechazados. Como resultado, obtuvimos alrededor del 20% de los puntos de referencia con más de un centroide.
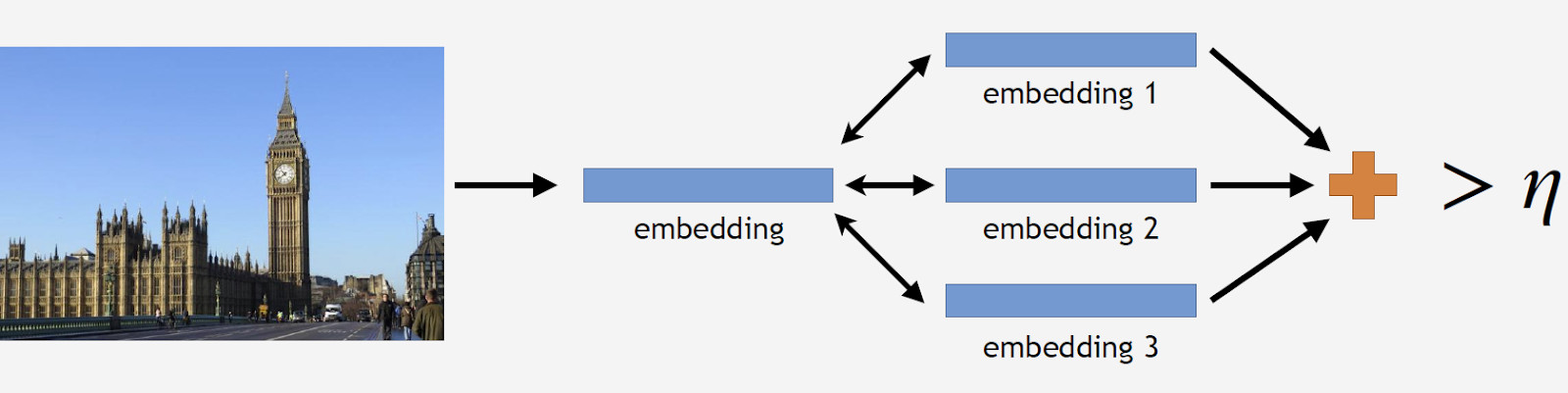
Ahora a inferencia. Se obtiene en dos pasos: en primer lugar, alimentamos la imagen de entrada a nuestra red neuronal convolucional y obtenemos la incrustación, y luego hacemos coincidir la incrustación con los centroides usando el producto punto. Si las imágenes tienen datos geográficos, restringimos la búsqueda a los centroides, que se refieren a puntos de referencia ubicados dentro de un cuadrado de 1x1 km desde la ubicación de la imagen. Esto permite una búsqueda más precisa y un umbral más bajo para la coincidencia posterior. Si la distancia resultante excede el umbral, que es un parámetro del algoritmo, entonces concluimos que una foto tiene un punto de referencia con el valor máximo del producto de puntos. Si es menor, entonces es una foto no histórica.
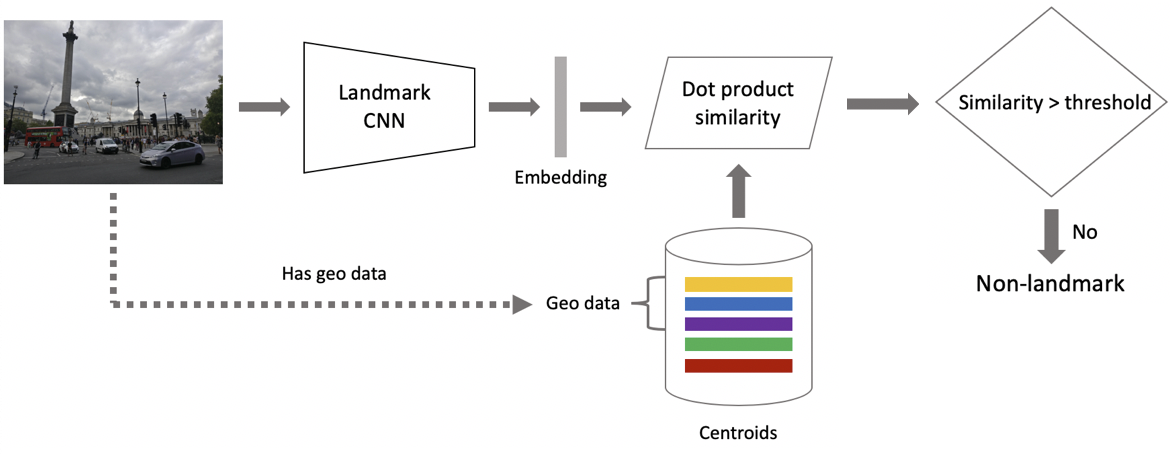
Supongamos que una foto tiene un hito. Si tenemos datos geográficos, los usamos y derivamos una respuesta. Si los datos geográficos no están disponibles, ejecutamos una verificación adicional. Cuando estábamos limpiando el conjunto de datos, creamos un conjunto de imágenes de referencia para cada clase. Podemos determinar las incrustaciones para ellos y luego obtener una distancia promedio desde ellos hasta la incrustación de la imagen de consulta. Si excede algún umbral, se pasa la verificación y traemos metadatos y obtenemos un resultado. Es importante tener en cuenta que podemos ejecutar este procedimiento para varios puntos de referencia que se han encontrado en una imagen.
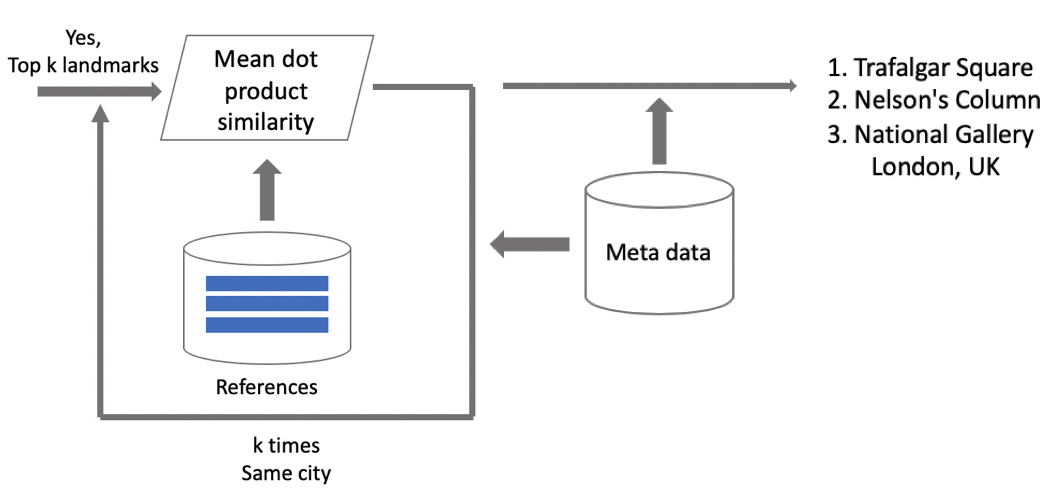
Resultados de pruebas
Comparamos nuestro modelo con DELF, para lo cual tomamos parámetros con los que mostraría el mejor rendimiento en nuestra prueba. Los resultados son casi idénticos.
Luego clasificamos los puntos de referencia en dos tipos: frecuentes (más de 100 fotografías en la base de datos), que representaron el 87% de todos los puntos de referencia en la prueba, y raros. Nuestro modelo funciona bien con los frecuentes: 85.3% de precisión. Con puntos de referencia raros, tuvimos un 46%, que tampoco estuvo nada mal, lo que significa que nuestro enfoque funcionó bastante bien incluso con pocos datos.
Luego realizamos una prueba A / B con fotos de los usuarios. Como resultado, la tasa de conversión de compra de espacio en la nube aumentó en un 10%, la tasa de conversión de desinstalación de aplicaciones móviles se redujo en un 3% y la cantidad de vistas de álbumes aumentó en un 13%.
Comparemos nuestra velocidad con la de DELF. Con GPU, DELF requiere 7 ejecuciones de red porque usa 7 escalas de imagen, mientras que nuestro enfoque usa solo 1. Con CPU, DELF usa una búsqueda más larga por el método del vecino más cercano y una verificación geométrica muy larga. Al final, nuestro método fue 15 veces más rápido con la CPU. Nuestro enfoque muestra una mayor velocidad en ambos casos, que es crucial para la producción.
Resultados: recuerdos de vacaciones
Al comienzo de este artículo, mencioné una solución para desplazarse y encontrar imágenes de referencia deseadas. Aqui esta
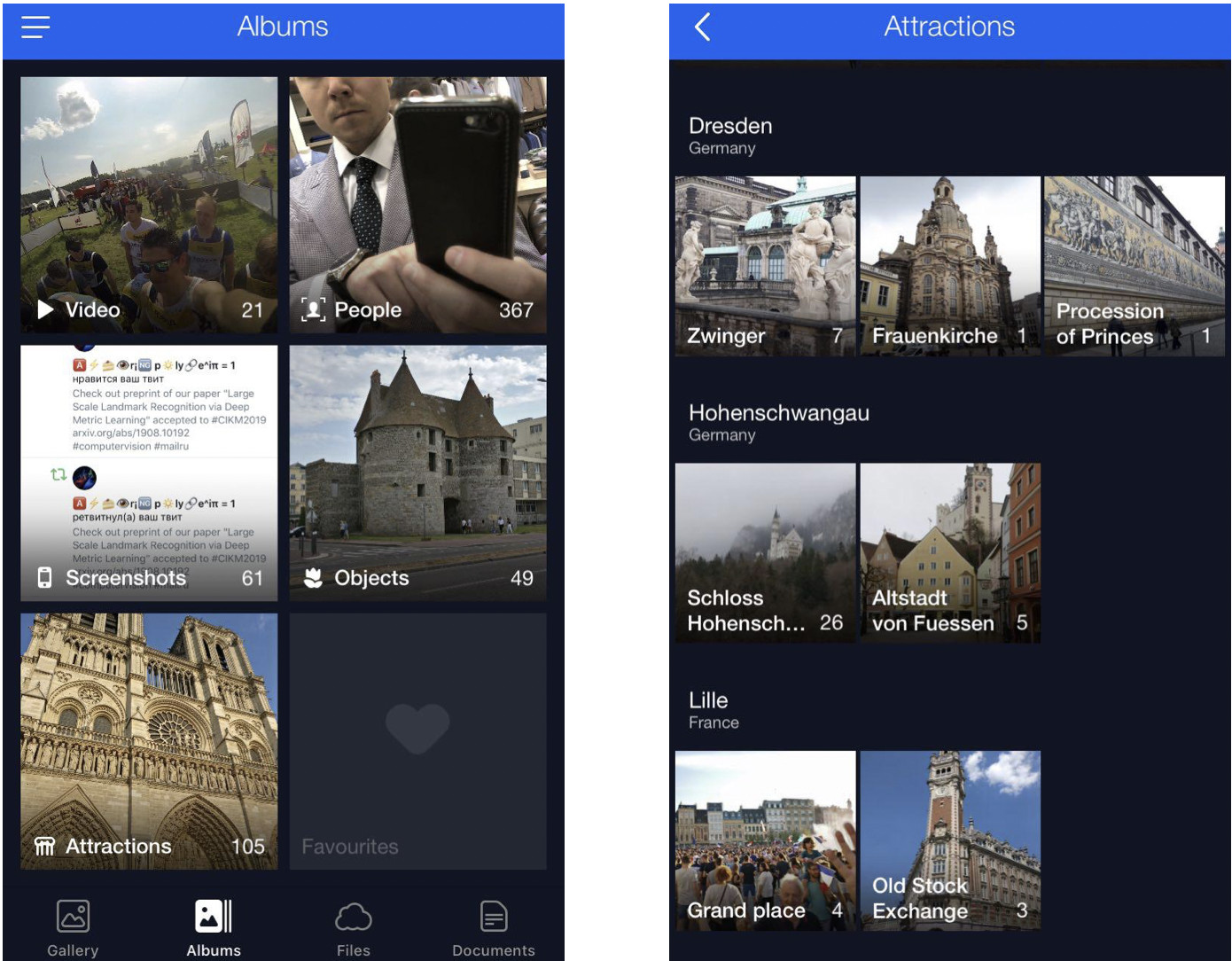
Esta es mi nube donde todas las fotos se clasifican en álbumes. Hay álbumes "Personas", "Objetos" y "Atracciones". En el álbum Atracciones, los puntos de referencia se clasifican en álbumes agrupados por ciudad. Un clic en Dresdner Zwinger abre un álbum con fotos de este hito solamente.
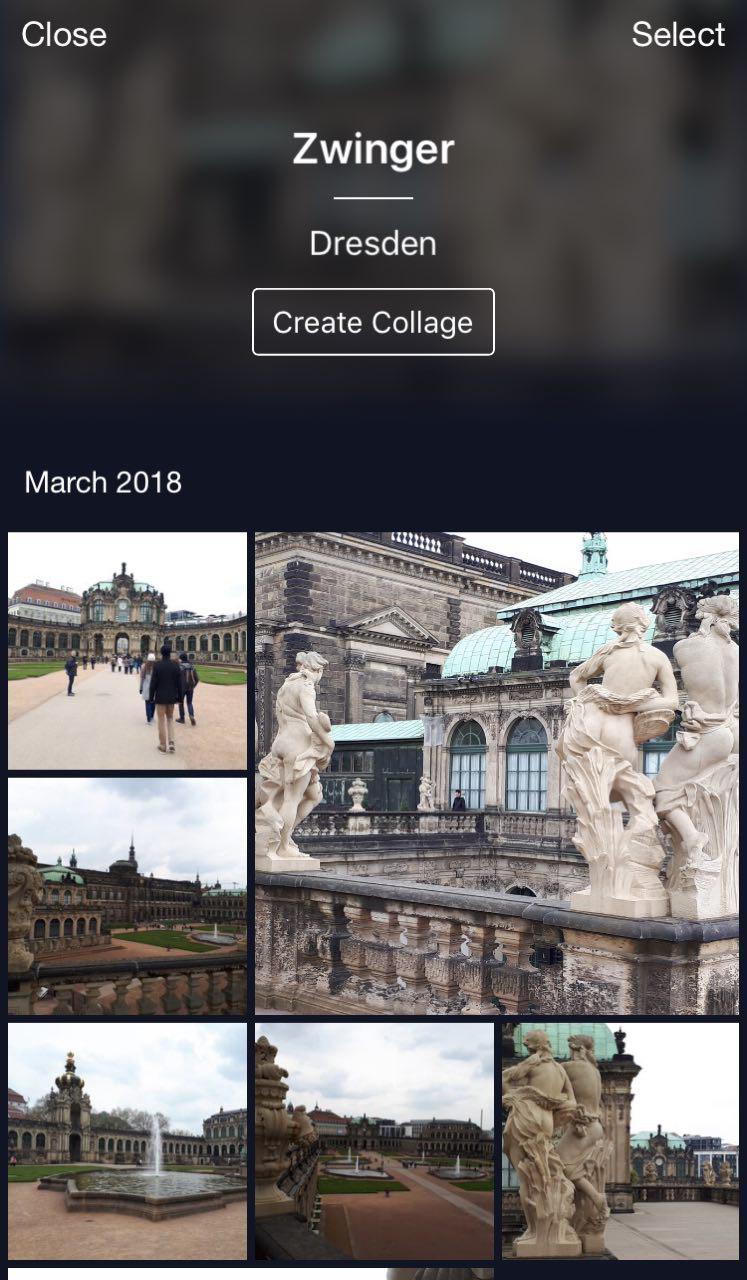
Una característica útil: puede irse de vacaciones, tomar algunas fotos y almacenarlas en su nube. Más tarde, cuando desee subirlos a Instagram o compartirlos con amigos y familiares, no tendrá que buscar y elegir demasiado tiempo: las fotos deseadas estarán disponibles con solo unos pocos clics.
Conclusiones
Permítame recordarle las características clave de nuestra solución.
- Limpieza de bases de datos semiautomática. Se requiere un poco de trabajo manual para el mapeo inicial, y luego la red neuronal hará el resto. Esto permite limpiar nuevos datos rápidamente y usarlos para volver a entrenar el modelo.
- Utilizamos redes neuronales convolucionales profundas y aprendizaje métrico profundo que nos permite aprender la estructura en las clases de manera eficiente.
- Hemos utilizado el aprendizaje curricular, es decir, la capacitación en partes, como paradigma de capacitación. Este enfoque nos ha sido muy útil. Utilizamos varios centroides en la inferencia, que permiten utilizar datos más limpios y encontrar diferentes vistas de puntos de referencia.
Puede parecer que el reconocimiento de objetos es una tarea trivial. Sin embargo, al explorar las necesidades de los usuarios en la vida real, encontramos nuevos desafíos como el reconocimiento de puntos de referencia. Esta técnica permite decirle a las personas algo nuevo sobre el mundo utilizando redes neuronales. ¡Es muy alentador y motivador!