El curso completo en ruso se puede encontrar en este enlace .
El curso de inglés original está disponible en este enlace .

Contenido
- Entrevista con Sebastian Trun
- Introduccion
- Modelo de aprendizaje de transferencia
- MobileNet
- CoLab: Gatos Vs Perros con entrenamiento de transferencia
- Zambullirse en redes neuronales convolucionales
- Parte práctica: determinación de colores con la transferencia de formación.
- Resumen
Entrevista con Sebastian Trun
- Esta es la lección 6 y está completamente dedicada a la transferencia de aprendizaje. La transferencia de aprendizaje es el proceso de usar un modelo existente con poco refinamiento para nuevas tareas. La transferencia de capacitación ayuda a reducir el tiempo de capacitación del modelo al aumentar la eficiencia al aprender desde el principio. Sebastian, ¿qué opinas sobre la transferencia de entrenamiento? ¿Alguna vez ha podido utilizar la metodología de transferencia de enseñanza en su trabajo e investigación?
- Mi disertación se dedicó solo al tema de la transferencia de capacitación y se denominó " Explicación sobre la base de la transferencia de capacitación ". Cuando estábamos trabajando en una disertación, la idea era que es posible enseñar a distinguir todos los demás objetos de este tipo en un objeto (conjunto de datos, entidad) en diversas variaciones y formatos. En el trabajo, utilizamos el algoritmo desarrollado, que distinguía las características principales (atributos) del objeto y podía compararlas con otro objeto. Las bibliotecas como Tensorflow ya vienen con modelos pre-entrenados.
- Sí, en Tensorflow tenemos un conjunto completo de modelos pre-entrenados que puede usar para resolver problemas prácticos. Hablaremos sobre sets ya hechos un poco más tarde.
- Si, si! Si lo piensa, las personas se dedican a la transferencia de capacitación todo el tiempo a lo largo de sus vidas.
- ¿Podemos decir que gracias al método de transferencia de capacitación, nuestros nuevos estudiantes en algún momento no tendrán que saber algo sobre el aprendizaje automático porque será suficiente para conectar un modelo ya preparado y usarlo?
- La programación es escribir línea por línea, le damos comandos a la computadora. Nuestro objetivo es asegurarnos de que todos en el planeta puedan y puedan programar proporcionando a la computadora solo ejemplos de datos de entrada. De acuerdo, si quieres enseñarle a una computadora a distinguir gatos de perros, entonces encontrar 100k imágenes diferentes de gatos y 100k imágenes diferentes de perros es bastante difícil, y gracias a la transferencia de entrenamiento puedes resolver este problema en varias líneas.
- Sí, realmente lo es! Gracias por las respuestas y finalmente pasemos al aprendizaje.
Introduccion
- Hola y bienvenido de nuevo!
- La última vez entrenamos una red neuronal convolucional para clasificar gatos y perros en la imagen. Nuestra primera red neuronal se volvió a entrenar, por lo que su resultado no fue tan alto: aproximadamente 70% de precisión. Después de eso, implementamos la extensión y el abandono de datos (desconexión arbitraria de las neuronas), lo que nos permitió aumentar la precisión de las predicciones hasta en un 80%.
- A pesar de que el 80% puede parecer un excelente indicador, el error del 20% sigue siendo demasiado grande. Derecho? ¿Qué podemos hacer para aumentar la precisión de la clasificación? En esta lección, utilizaremos la técnica de transferencia de conocimiento (transferencia del modelo de conocimiento), que nos permitirá usar el modelo desarrollado por expertos y capacitados en grandes conjuntos de datos. Como veremos en la práctica, al transferir el modelo de conocimiento podemos lograr una precisión de clasificación del 95%. ¡Empecemos!
Transferencia de modelo de aprendizaje
En 2012, la red neuronal AlexNet revolucionó el mundo del aprendizaje automático y popularizó el uso de redes neuronales convolucionales para la clasificación al ganar el desafío de reconocimiento visual ImageNet a gran escala.
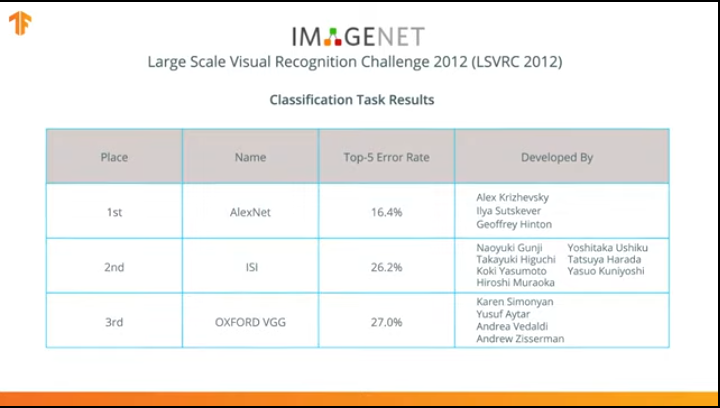
Después de eso, la lucha comenzó a desarrollar redes neuronales más precisas y eficientes que podrían superar a AlexNet en las tareas de clasificar imágenes del conjunto de datos ImageNet.
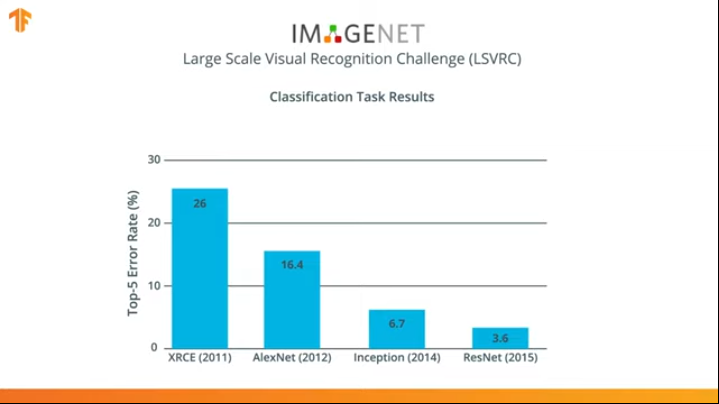
Durante varios años, se han desarrollado redes neuronales que hacen frente a la tarea de clasificación mejor que AlexNet - Inception y ResNet.
¿Está de acuerdo en que sería genial poder aprovechar estas redes neuronales ya capacitadas en grandes conjuntos de datos de ImageNet y usarlas en su clasificador de perros y gatos?
¡Resulta que podemos hacerlo! La técnica se llama transferencia de aprendizaje. La idea principal del método de transferencia del modelo de entrenamiento se basa en el hecho de que después de haber entrenado una red neuronal en un gran conjunto de datos, podemos aplicar el modelo obtenido a un conjunto de datos que este modelo aún no ha encontrado. Es por eso que la técnica se llama aprendizaje de transferencia: transferir el proceso de aprendizaje de un conjunto de datos a otro.
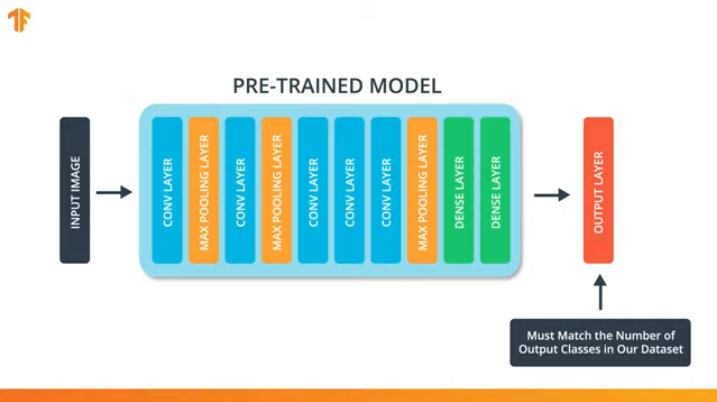
Para poder aplicar la metodología de transferencia del modelo de entrenamiento, necesitamos cambiar la última capa de nuestra red neuronal convolucional:
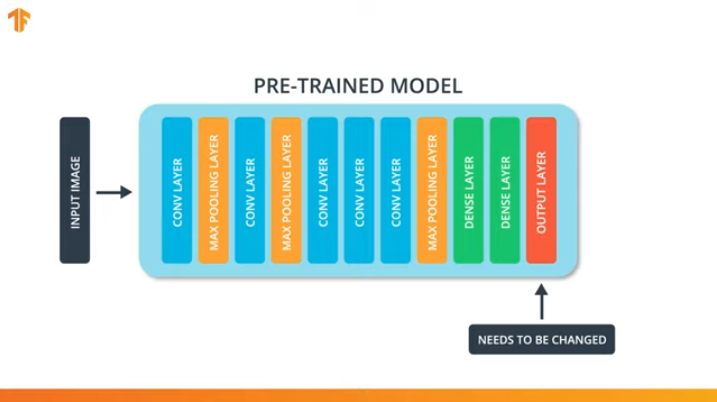
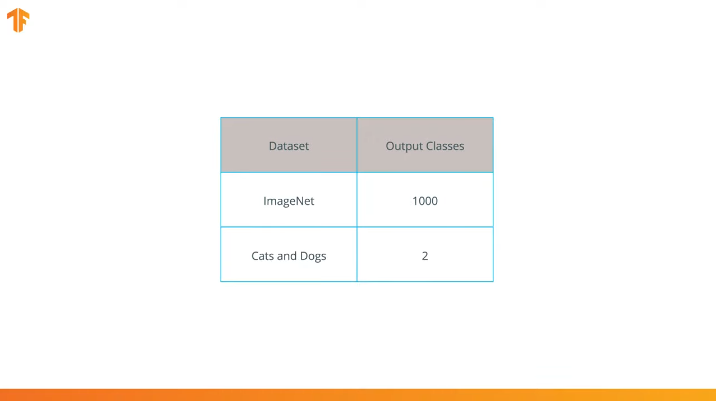
Realizamos esta operación porque cada conjunto de datos consta de un número diferente de clases de salida. Por ejemplo, los conjuntos de datos en ImageNet contienen 1000 clases de salida diferentes. FashionMNIST contiene 10 clases. Nuestro conjunto de datos de clasificación consta de solo 2 clases: gatos y perros.
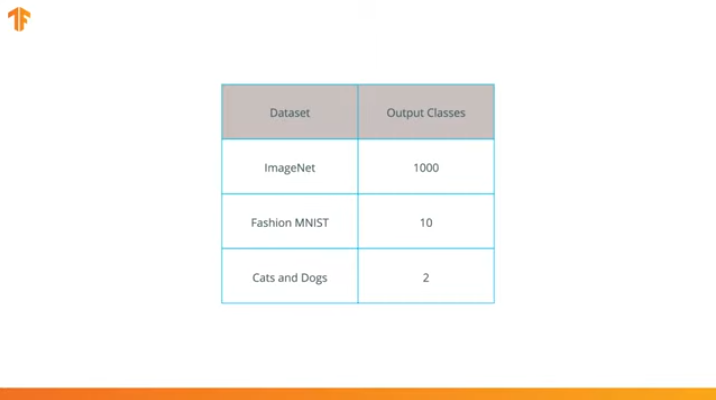
Es por eso que es necesario cambiar la última capa de nuestra red neuronal convolucional para que contenga el número de salidas que correspondería al número de clases en el nuevo conjunto.
También debemos asegurarnos de no cambiar el modelo pre-entrenado durante el proceso de capacitación. La solución es desactivar las variables del modelo pre-entrenado: simplemente prohibimos que el algoritmo actualice los valores durante la propagación hacia adelante y hacia atrás para cambiarlos.
Este proceso se llama "congelar el modelo".
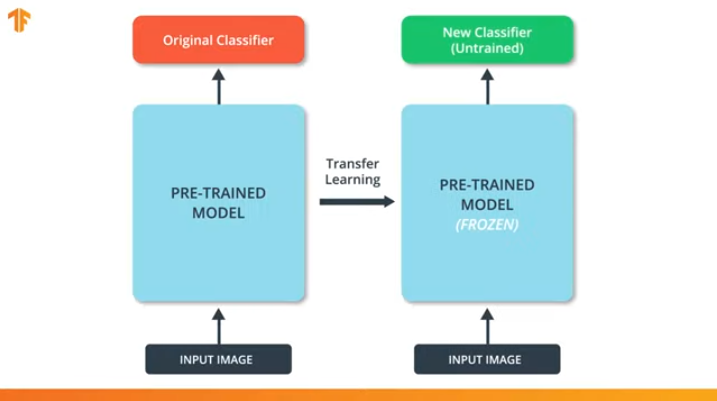
Al "congelar" los parámetros del modelo pre-entrenado, nos permitimos aprender solo la última capa de la red de clasificación, los valores de las variables del modelo pre-entrenado permanecen sin cambios.
Otra ventaja indiscutible de los modelos pre-entrenados es que reducimos el tiempo de entrenamiento al entrenar solo la última capa con un número significativamente menor de variables, y no todo el modelo.
Si no "congelamos" las variables del modelo pre-entrenado, entonces durante el proceso de entrenamiento, los valores de las variables cambiarán en el nuevo conjunto de datos. Esto se debe a que los valores de las variables en la última capa de la clasificación se rellenarán con valores aleatorios. Debido a los valores aleatorios en la última capa, nuestro modelo cometerá grandes errores en la clasificación, lo que, a su vez, implicará fuertes cambios en los pesos iniciales en el modelo pre-entrenado, lo cual es extremadamente indeseable para nosotros.
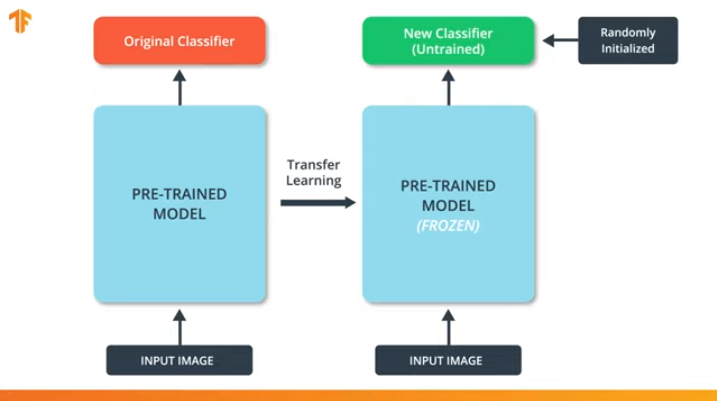
Es por esta razón que siempre debemos recordar que cuando se usan modelos existentes, los valores de las variables deben "congelarse" y la necesidad de entrenar un modelo pre-entrenado debe desactivarse.
Ahora que sabemos cómo funciona la transferencia del modelo de entrenamiento, ¡solo tenemos que elegir una red neuronal pre-entrenada para usar en nuestro propio clasificador! Esto lo haremos en la siguiente parte.
MobileNet
Como mencionamos anteriormente, se desarrollaron redes neuronales extremadamente eficientes que mostraron altos resultados en los conjuntos de datos de ImageNet: AlexNet, Inception, Resonant. Estas redes neuronales son redes muy profundas y contienen miles e incluso millones de parámetros. Una gran cantidad de parámetros permite a la red aprender patrones más complejos y, por lo tanto, lograr una mayor precisión de clasificación. Una gran cantidad de parámetros de entrenamiento de la red neuronal afecta la velocidad de aprendizaje, la cantidad de memoria requerida para almacenar la red y la complejidad de los cálculos.
En esta lección usaremos la moderna red neuronal convolucional MobileNet. MobileNet es una arquitectura de red neuronal convolucional eficiente que reduce la cantidad de memoria utilizada para la computación al tiempo que mantiene una alta precisión de las predicciones. Es por eso que MobileNet es ideal para usar en dispositivos móviles con una cantidad limitada de memoria y recursos informáticos.
MobileNet fue desarrollado por Google y capacitado en el conjunto de datos ImageNet.
Dado que MobileNet recibió capacitación en 1,000 clases del conjunto de datos de ImageNet, MobileNet tiene 1,000 clases de salida, en lugar de las dos que necesitamos: un gato y un perro.
Para completar la transferencia de capacitación, precargamos el vector de características sin una capa de clasificación:

En Tensorflow, un vector de características cargado puede usarse como una capa Keras normal con datos de entrada de cierto tamaño.
Como MobileNet recibió capacitación en el conjunto de datos de ImageNet, tendremos que llevar el tamaño de los datos de entrada a los que se utilizaron en el proceso de capacitación. En nuestro caso, MobileNet recibió capacitación en imágenes RGB de 224x224px de tamaño fijo.
TensorFlow contiene un repositorio previamente entrenado llamado TensorFlow Hub.
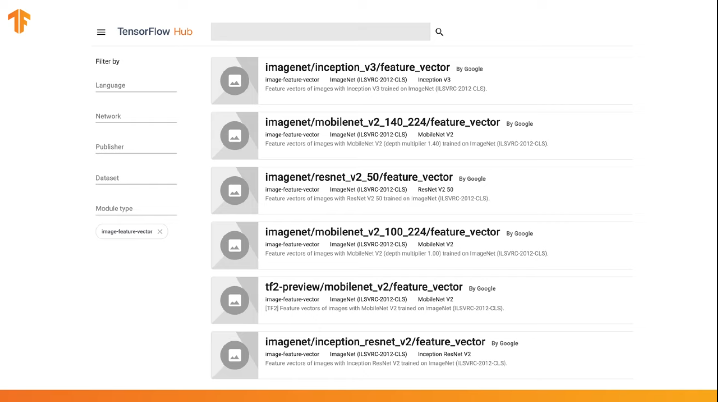
TensorFlow Hub contiene algunos modelos previamente entrenados en los que la última capa de clasificación se excluyó de la arquitectura de la red neuronal para su posterior reutilización.
Puede usar el TensorFlow Hub en el código en varias líneas:

Es suficiente especificar la URL del vector de características del modelo de entrenamiento deseado y luego incrustar el modelo en nuestro clasificador con la última capa con el número deseado de clases de salida. Es la última capa que se someterá a entrenamiento y a cambio de valores de parámetros. La compilación y capacitación de nuestro nuevo modelo se lleva a cabo de la misma manera que lo hicimos antes:
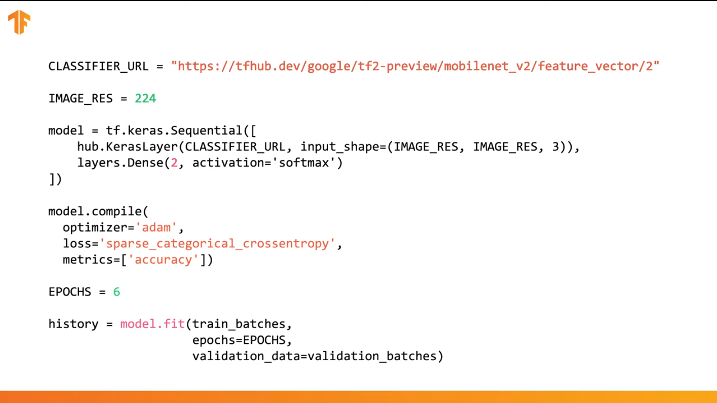
Veamos cómo funcionará esto realmente y escriba el código apropiado.
CoLab: Gatos Vs Perros con entrenamiento de transferencia
Enlace a CoLab en ruso y CoLab en inglés .
TensorFlow Hub es un repositorio con modelos pre-entrenados que podemos usar.
La transferencia de aprendizaje es un proceso en el que tomamos un modelo previamente entrenado y lo expandimos para realizar una tarea específica. Al mismo tiempo, dejamos intacta la parte del modelo pre-entrenado que integramos en la red neuronal, pero solo entrenamos las últimas capas de salida para obtener el resultado deseado.
En esta parte práctica, probaremos ambas opciones.
Este enlace le permite explorar la lista completa de modelos disponibles.
En esta parte de Colab
- Usaremos el modelo TensorFlow Hub para las predicciones;
- Usaremos el modelo TensorFlow Hub para el conjunto de datos de gatos y perros;
- Transfieramos el entrenamiento usando el modelo del TensorFlow Hub.
Antes de continuar con la implementación de la parte práctica actual, recomendamos restablecer el Runtime -> Reset all runtimes...
Importaciones de la biblioteca
En esta parte práctica, utilizaremos una serie de características de la biblioteca TensorFlow que aún no están en el lanzamiento oficial. Es por eso que primero instalaremos la versión TensorFlow y TensorFlow Hub para desarrolladores.
La instalación de la versión de desarrollo de TensorFlow activa automáticamente la última versión instalada. Después de que terminemos de tratar con esta parte práctica, recomendamos restaurar la configuración de TensorFlow y volver a la versión estable a través del elemento de menú Runtime -> Reset all runtimes... La ejecución de este comando restablecerá todas las configuraciones del entorno a las originales.
!pip install tf-nightly-gpu !pip install "tensorflow_hub==0.4.0" !pip install -U tensorflow_datasets
Conclusión
Requirement already satisfied: absl-py>=0.7.0 in /usr/local/lib/python3.6/dist-packages (from tf-nightly-gpu) (0.8.0) Requirement already satisfied: protobuf>=3.6.1 in /usr/local/lib/python3.6/dist-packages (from tf-nightly-gpu) (3.7.1) Requirement already satisfied: google-pasta>=0.1.6 in /usr/local/lib/python3.6/dist-packages (from tf-nightly-gpu) (0.1.7) Collecting tf-estimator-nightly (from tf-nightly-gpu) Downloading https://files.pythonhosted.org/packages/ea/72/f092fc631ef2602fd0c296dcc4ef6ef638a6a773cb9fdc6757fecbfffd33/tf_estimator_nightly-1.14.0.dev2019092201-py2.py3-none-any.whl (450kB) |████████████████████████████████| 450kB 45.9MB/s Requirement already satisfied: numpy<2.0,>=1.16.0 in /usr/local/lib/python3.6/dist-packages (from tf-nightly-gpu) (1.16.5) Requirement already satisfied: wrapt>=1.11.1 in /usr/local/lib/python3.6/dist-packages (from tf-nightly-gpu) (1.11.2) Requirement already satisfied: astor>=0.6.0 in /usr/local/lib/python3.6/dist-packages (from tf-nightly-gpu) (0.8.0) Requirement already satisfied: opt-einsum>=2.3.2 in /usr/local/lib/python3.6/dist-packages (from tf-nightly-gpu) (3.0.1) Requirement already satisfied: wheel>=0.26 in /usr/local/lib/python3.6/dist-packages (from tf-nightly-gpu) (0.33.6) Requirement already satisfied: h5py in /usr/local/lib/python3.6/dist-packages (from keras-applications>=1.0.8->tf-nightly-gpu) (2.8.0) Requirement already satisfied: markdown>=2.6.8 in /usr/local/lib/python3.6/dist-packages (from tb-nightly<1.16.0a0,>=1.15.0a0->tf-nightly-gpu) (3.1.1) Requirement already satisfied: setuptools>=41.0.0 in /usr/local/lib/python3.6/dist-packages (from tb-nightly<1.16.0a0,>=1.15.0a0->tf-nightly-gpu) (41.2.0) Requirement already satisfied: werkzeug>=0.11.15 in /usr/local/lib/python3.6/dist-packages (from tb-nightly<1.16.0a0,>=1.15.0a0->tf-nightly-gpu) (0.15.6) Installing collected packages: tb-nightly, tf-estimator-nightly, tf-nightly-gpu Successfully installed tb-nightly-1.15.0a20190911 tf-estimator-nightly-1.14.0.dev2019092201 tf-nightly-gpu-1.15.0.dev20190821 Collecting tensorflow_hub==0.4.0 Downloading https://files.pythonhosted.org/packages/10/5c/6f3698513cf1cd730a5ea66aec665d213adf9de59b34f362f270e0bd126f/tensorflow_hub-0.4.0-py2.py3-none-any.whl (75kB) |████████████████████████████████| 81kB 5.0MB/s Requirement already satisfied: protobuf>=3.4.0 in /usr/local/lib/python3.6/dist-packages (from tensorflow_hub==0.4.0) (3.7.1) Requirement already satisfied: numpy>=1.12.0 in /usr/local/lib/python3.6/dist-packages (from tensorflow_hub==0.4.0) (1.16.5) Requirement already satisfied: six>=1.10.0 in /usr/local/lib/python3.6/dist-packages (from tensorflow_hub==0.4.0) (1.12.0) Requirement already satisfied: setuptools in /usr/local/lib/python3.6/dist-packages (from protobuf>=3.4.0->tensorflow_hub==0.4.0) (41.2.0) Installing collected packages: tensorflow-hub Found existing installation: tensorflow-hub 0.6.0 Uninstalling tensorflow-hub-0.6.0: Successfully uninstalled tensorflow-hub-0.6.0 Successfully installed tensorflow-hub-0.4.0 Collecting tensorflow_datasets Downloading https://files.pythonhosted.org/packages/6c/34/ff424223ed4331006aaa929efc8360b6459d427063dc59fc7b75d7e4bab3/tensorflow_datasets-1.2.0-py3-none-any.whl (2.3MB) |████████████████████████████████| 2.3MB 4.9MB/s Requirement already satisfied, skipping upgrade: future in /usr/local/lib/python3.6/dist-packages (from tensorflow_datasets) (0.16.0) Requirement already satisfied, skipping upgrade: wrapt in /usr/local/lib/python3.6/dist-packages (from tensorflow_datasets) (1.11.2) Requirement already satisfied, skipping upgrade: dill in /usr/local/lib/python3.6/dist-packages (from tensorflow_datasets) (0.3.0) Requirement already satisfied, skipping upgrade: numpy in /usr/local/lib/python3.6/dist-packages (from tensorflow_datasets) (1.16.5) Requirement already satisfied, skipping upgrade: requests>=2.19.0 in /usr/local/lib/python3.6/dist-packages (from tensorflow_datasets) (2.21.0) Requirement already satisfied, skipping upgrade: tqdm in /usr/local/lib/python3.6/dist-packages (from tensorflow_datasets) (4.28.1) Requirement already satisfied, skipping upgrade: protobuf>=3.6.1 in /usr/local/lib/python3.6/dist-packages (from tensorflow_datasets) (3.7.1) Requirement already satisfied, skipping upgrade: psutil in /usr/local/lib/python3.6/dist-packages (from tensorflow_datasets) (5.4.8) Requirement already satisfied, skipping upgrade: promise in /usr/local/lib/python3.6/dist-packages (from tensorflow_datasets) (2.2.1) Requirement already satisfied, skipping upgrade: absl-py in /usr/local/lib/python3.6/dist-packages (from tensorflow_datasets) (0.8.0) Requirement already satisfied, skipping upgrade: tensorflow-metadata in /usr/local/lib/python3.6/dist-packages (from tensorflow_datasets) (0.14.0) Requirement already satisfied, skipping upgrade: six in /usr/local/lib/python3.6/dist-packages (from tensorflow_datasets) (1.12.0) Requirement already satisfied, skipping upgrade: termcolor in /usr/local/lib/python3.6/dist-packages (from tensorflow_datasets) (1.1.0) Requirement already satisfied, skipping upgrade: attrs in /usr/local/lib/python3.6/dist-packages (from tensorflow_datasets) (19.1.0) Requirement already satisfied, skipping upgrade: idna<2.9,>=2.5 in /usr/local/lib/python3.6/dist-packages (from requests>=2.19.0->tensorflow_datasets) (2.8) Requirement already satisfied, skipping upgrade: certifi>=2017.4.17 in /usr/local/lib/python3.6/dist-packages (from requests>=2.19.0->tensorflow_datasets) (2019.6.16) Requirement already satisfied, skipping upgrade: chardet<3.1.0,>=3.0.2 in /usr/local/lib/python3.6/dist-packages (from requests>=2.19.0->tensorflow_datasets) (3.0.4) Requirement already satisfied, skipping upgrade: urllib3<1.25,>=1.21.1 in /usr/local/lib/python3.6/dist-packages (from requests>=2.19.0->tensorflow_datasets) (1.24.3) Requirement already satisfied, skipping upgrade: setuptools in /usr/local/lib/python3.6/dist-packages (from protobuf>=3.6.1->tensorflow_datasets) (41.2.0) Requirement already satisfied, skipping upgrade: googleapis-common-protos in /usr/local/lib/python3.6/dist-packages (from tensorflow-metadata->tensorflow_datasets) (1.6.0) Installing collected packages: tensorflow-datasets Successfully installed tensorflow-datasets-1.2.0
Ya hemos visto y usado algunas importaciones antes. Desde el nuevo - import tensorflow_hub , que instalamos y que utilizaremos en esta parte práctica.
from __future__ import absolute_import, division, print_function, unicode_literals import matplotlib.pylab as plt import tensorflow as tf tf.enable_eager_execution() import tensorflow_hub as hub import tensorflow_datasets as tfds from tensorflow.keras import layers
Conclusión
WARNING:tensorflow: TensorFlow's `tf-nightly` package will soon be updated to TensorFlow 2.0. Please upgrade your code to TensorFlow 2.0: * https://www.tensorflow.org/beta/guide/migration_guide Or install the latest stable TensorFlow 1.X release: * `pip install -U "tensorflow==1.*"` Otherwise your code may be broken by the change.
import logging logger = tf.get_logger() logger.setLevel(logging.ERROR)
Parte 1: use TensorFlow Hub MobileNet para predicciones
En esta parte de CoLab, tomaremos un modelo previamente entrenado, lo cargaremos a Keras y lo probaremos.
El modelo que utilizamos es MobileNet v2 (en lugar de MobileNet, se puede utilizar cualquier otro modelo de clasificador de imágenes compatible con tf2 con tfhub.dev).
Descargar clasificador
Descargue el modelo MobileNet y cree un modelo Keras a partir de él. MobileNet en la entrada espera recibir una imagen de 224x224 píxeles de tamaño con 3 canales de color (RGB).
CLASSIFIER_URL = "https://tfhub.dev/google/tf2-preview/mobilenet_v2/classification/2" IMAGE_RES = 224 model = tf.keras.Sequential([ hub.KerasLayer(CLASSIFIER_URL, input_shape=(IMAGE_RES, IMAGE_RES, 3)) ])
Ejecute el clasificador en una sola imagen
MobileNet ha sido entrenado en el conjunto de datos ImageNet. ImageNet contiene 1000 clases de salida y una de estas clases es un uniforme militar. Busquemos la imagen en la que se ubicará el uniforme militar y que no formará parte del kit de entrenamiento de ImageNet para verificar la precisión de la clasificación.
import numpy as np import PIL.Image as Image grace_hopper = tf.keras.utils.get_file('image.jpg', 'https://storage.googleapis.com/download.tensorflow.org/example_images/grace_hopper.jpg') grace_hopper = Image.open(grace_hopper).resize((IMAGE_RES, IMAGE_RES)) grace_hopper
Conclusión
Downloading data from https://storage.googleapis.com/download.tensorflow.org/example_images/grace_hopper.jpg 65536/61306 [================================] - 0s 0us/step

grace_hopper = np.array(grace_hopper)/255.0 grace_hopper.shape
Conclusión
(224, 224, 3)
Tenga en cuenta que los modelos siempre reciben un conjunto (bloque) de imágenes para procesar en la entrada. En el siguiente código, agregamos una nueva dimensión: el tamaño del bloque.
result = model.predict(grace_hopper[np.newaxis, ...]) result.shape
Conclusión
(1, 1001)
El resultado de la predicción fue un vector con un tamaño de 1.001 elementos, donde cada valor representa la probabilidad de que el objeto en la imagen pertenezca a una determinada clase.
La posición del valor de probabilidad máxima se puede encontrar usando la función argmax . Sin embargo, hay una pregunta que aún no hemos respondido: ¿cómo podemos determinar a qué clase pertenece un elemento con la máxima probabilidad?
predicted_class = np.argmax(result[0], axis=-1) predicted_class
Conclusión
653
Descifrando predicciones
Para que podamos determinar la clase a la que se refieren las predicciones, cargamos la lista de etiquetas ImageNet y, mediante el índice, con la máxima fidelidad, determinamos la clase a la que se refiere la predicción.
labels_path = tf.keras.utils.get_file('ImageNetLabels.txt','https://storage.googleapis.com/download.tensorflow.org/data/ImageNetLabels.txt') imagenet_labels = np.array(open(labels_path).read().splitlines()) plt.imshow(grace_hopper) plt.axis('off') predicted_class_name = imagenet_labels[predicted_class] _ = plt.title("Prediction: " + predicted_class_name.title())
Conclusión
Downloading data from https://storage.googleapis.com/download.tensorflow.org/data/ImageNetLabels.txt 16384/10484 [==============================================] - 0s 0us/step

Bingo! Nuestro modelo identificó correctamente el uniforme militar.
Parte 2: use el modelo TensorFlow Hub para un conjunto de datos de perros y gatos
Ahora usaremos la versión completa del modelo MobileNet y veremos cómo manejará el conjunto de datos de gatos y perros.
Conjunto de datos
Podemos usar los conjuntos de datos TensorFlow para descargar un conjunto de datos de perros y gatos.
splits = tfds.Split.ALL.subsplit(weighted=(80, 20)) splits, info = tfds.load('cats_vs_dogs', with_info=True, as_supervised=True, split = splits) (train_examples, validation_examples) = splits num_examples = info.splits['train'].num_examples num_classes = info.features['label'].num_classes
Conclusión
Downloading and preparing dataset cats_vs_dogs (786.68 MiB) to /root/tensorflow_datasets/cats_vs_dogs/2.0.1... /usr/local/lib/python3.6/dist-packages/urllib3/connectionpool.py:847: InsecureRequestWarning: Unverified HTTPS request is being made. Adding certificate verification is strongly advised. See: https://urllib3.readthedocs.io/en/latest/advanced-usage.html#ssl-warnings InsecureRequestWarning) WARNING:absl:1738 images were corrupted and were skipped Dataset cats_vs_dogs downloaded and prepared to /root/tensorflow_datasets/cats_vs_dogs/2.0.1. Subsequent calls will reuse this data.
No todas las imágenes en un conjunto de datos de perros y gatos son del mismo tamaño.
for i, example_image in enumerate(train_examples.take(3)): print("Image {} shape: {}".format(i+1, example_image[0].shape))
Conclusión
Image 1 shape: (500, 343, 3) Image 2 shape: (375, 500, 3) Image 3 shape: (375, 500, 3)
Por lo tanto, las imágenes del conjunto de datos obtenido requieren una reducción a un tamaño único, que el modelo MobileNet espera en la entrada: 224 x 224.
La función .repeat() y steps_per_epoch no son necesarios aquí, pero le permiten ahorrar unos 15 segundos por iteración de entrenamiento, porque el búfer temporal se debe inicializar solo una vez al comienzo del proceso de aprendizaje.
def format_image(image, label): image = tf.image.resize(image, (IMAGE_RES, IMAGE_RES)) / 255.0 return image, label BATCH_SIZE = 32 train_batches = train_examples.shuffle(num_examples//4).map(format_image).batch(BATCH_SIZE).prefetch(1) validation_batches = validation_examples.map(format_image).batch(BATCH_SIZE).prefetch(1)
Ejecute el clasificador en conjuntos de imágenes
Permítame recordarle que en esta etapa, todavía hay una versión completa de la red MobileNet pre-entrenada, que contiene 1,000 clases de salida posibles. ImageNet contiene una gran cantidad de imágenes de perros y gatos, así que intentemos ingresar una de las imágenes de prueba de nuestro conjunto de datos y ver qué predicción nos dará el modelo.
image_batch, label_batch = next(iter(train_batches.take(1))) image_batch = image_batch.numpy() label_batch = label_batch.numpy() result_batch = model.predict(image_batch) predicted_class_names = imagenet_labels[np.argmax(result_batch, axis=-1)] predicted_class_names
Conclusión
array(['Persian cat', 'mink', 'Siamese cat', 'tabby', 'Bouvier des Flandres', 'dishwasher', 'Yorkshire terrier', 'tiger cat', 'tabby', 'Egyptian cat', 'Egyptian cat', 'tabby', 'dalmatian', 'Persian cat', 'Border collie', 'Newfoundland', 'tiger cat', 'Siamese cat', 'Persian cat', 'Egyptian cat', 'tabby', 'tiger cat', 'Labrador retriever', 'German shepherd', 'Eskimo dog', 'kelpie', 'mink', 'Norwegian elkhound', 'Labrador retriever', 'Egyptian cat', 'computer keyboard', 'boxer'], dtype='<U30')
Las etiquetas son similares a los nombres de razas de gatos y perros. Ahora muestremos algunas imágenes de nuestro conjunto de datos de perros y gatos y coloquemos una etiqueta prevista en cada uno de ellos.
plt.figure(figsize=(10, 9)) for n in range(30): plt.subplot(6, 5, n+1) plt.subplots_adjust(hspace=0.3) plt.imshow(image_batch[n]) plt.title(predicted_class_names[n]) plt.axis('off') _ = plt.suptitle("ImageNet predictions")

Parte 3: Implementar la transferencia de aprendizaje con el TensorFlow Hub
Ahora usemos el TensorFlow Hub para transferir el aprendizaje de un modelo a otro.
En el proceso de transferir el entrenamiento, reutilizamos un modelo pre-entrenado cambiando su última capa, o varias capas, y luego comenzamos el proceso de entrenamiento nuevamente en un nuevo conjunto de datos.
En TensorFlow Hub, puede encontrar no solo modelos completos previamente entrenados (con la última capa), sino también modelos sin la última capa de clasificación. Este último puede usarse fácilmente para transferir el entrenamiento. Continuaremos usando MobileNet v2 por la sencilla razón de que en las partes posteriores de nuestro curso transferiremos este modelo y lo lanzaremos en un dispositivo móvil usando TensorFlow Lite.
También seguiremos utilizando el conjunto de datos de gatos y perros, por lo que tendremos la oportunidad de comparar el rendimiento de este modelo con los que implementamos desde cero.
Tenga en cuenta que llamamos al modelo parcial con el TensorFlow Hub (sin la última capa de clasificación) feature_extractor . Este nombre se explica por el hecho de que el modelo acepta datos como entrada y los transforma en un conjunto finito de propiedades (características) seleccionadas. Por lo tanto, nuestro modelo hizo el trabajo de identificar el contenido de la imagen, pero no produjo la distribución de probabilidad final sobre las clases de salida. El modelo extrajo un conjunto de propiedades de la imagen.
URL = 'https://tfhub.dev/google/tf2-preview/mobilenet_v2/feature_vector/2' feature_extractor = hub.KerasLayer(URL, input_shape=(IMAGE_RES, IMAGE_RES, 3))
Ejecutemos un conjunto de imágenes a través de feature_extractor y observemos el formulario resultante (formato de salida). 32 - el número de imágenes, 1280 - el número de neuronas en la última capa del modelo pre-entrenado con el TensorFlow Hub.
feature_batch = feature_extractor(image_batch) print(feature_batch.shape)
Conclusión
(32, 1280)
"Congelamos" las variables en la capa de extracción de propiedades para que solo los valores de las variables de la capa de clasificación cambien durante el proceso de capacitación.
feature_extractor.trainable = False
Agregar una capa de clasificación
Ahora envuelva la capa del TensorFlow Hub en el modelo tf.keras.Sequential y agregue una capa de clasificación.
model = tf.keras.Sequential([ feature_extractor, layers.Dense(2, activation='softmax') ]) model.summary()
Conclusión
Model: "sequential_1" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= keras_layer_1 (KerasLayer) (None, 1280) 2257984 _________________________________________________________________ dense (Dense) (None, 2) 2562 ================================================================= Total params: 2,260,546 Trainable params: 2,562 Non-trainable params: 2,257,984 _________________________________________________________________
Modelo de tren
Ahora entrenamos el modelo resultante de la forma en que lo hicimos antes de llamar a compile seguido de fit para entrenamiento.
model.compile( optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'] ) EPOCHS = 6 history = model.fit(train_batches, epochs=EPOCHS, validation_data=validation_batches)
Conclusión
Epoch 1/6 582/582 [==============================] - 77s 133ms/step - loss: 0.2381 - acc: 0.9346 - val_loss: 0.0000e+00 - val_acc: 0.0000e+00 Epoch 2/6 582/582 [==============================] - 70s 120ms/step - loss: 0.1827 - acc: 0.9618 - val_loss: 0.1629 - val_acc: 0.9670 Epoch 3/6 582/582 [==============================] - 69s 119ms/step - loss: 0.1733 - acc: 0.9660 - val_loss: 0.1623 - val_acc: 0.9666 Epoch 4/6 582/582 [==============================] - 69s 118ms/step - loss: 0.1677 - acc: 0.9676 - val_loss: 0.1627 - val_acc: 0.9677 Epoch 5/6 582/582 [==============================] - 68s 118ms/step - loss: 0.1636 - acc: 0.9689 - val_loss: 0.1634 - val_acc: 0.9675 Epoch 6/6 582/582 [==============================] - 69s 118ms/step - loss: 0.1604 - acc: 0.9701 - val_loss: 0.1643 - val_acc: 0.9668
Como probablemente notó, pudimos lograr ~ 97% de precisión de las predicciones en el conjunto de datos de validación. Impresionante! El enfoque actual ha aumentado significativamente la precisión de la clasificación en comparación con el primer modelo en el que nos capacitamos y obtuvimos una precisión de clasificación de ~ 87%. La razón es que MobileNet fue diseñado por expertos y desarrollado cuidadosamente durante un largo período de tiempo, y luego capacitado en un conjunto de datos ImageNet increíblemente grande.
Puede ver cómo crear su propia MobileNet en Keras en este enlace .
Creemos gráficos de cambios en la precisión y los valores de pérdida en los conjuntos de datos de capacitación y validación.
acc = history.history['acc'] val_acc = history.history['val_acc'] loss = history.history['loss'] val_loss = history.history['val_loss'] epochs_range = range(EPOCHS) plt.figure(figsize=(8, 8)) plt.subplot(1, 2, 1) plt.plot(epochs_range, acc, label=' ') plt.plot(epochs_range, val_acc, label=' ') plt.legend(loc='lower right') plt.title(' ') plt.subplot(1, 2, 2) plt.plot(epochs_range, loss, label=' ') plt.plot(epochs_range, val_loss, label=' ') plt.legend(loc='upper right') plt.title(' ') plt.show()
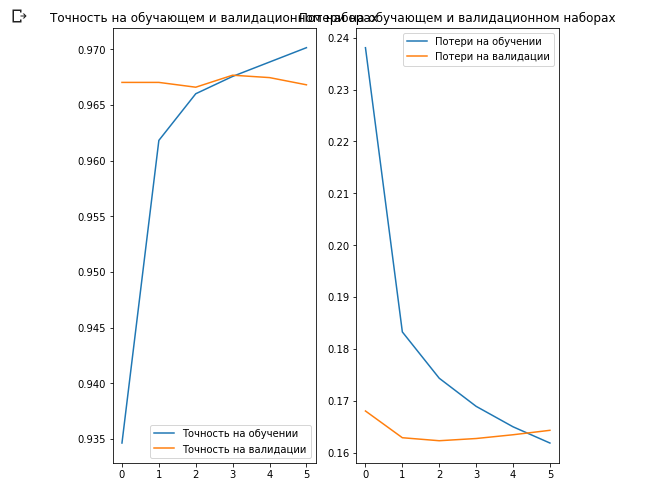
Lo interesante aquí es que los resultados en el conjunto de datos de validación son mejores que los resultados en el conjunto de datos de capacitación desde el principio hasta el final del proceso de aprendizaje.
Una razón para este comportamiento es que la precisión en el conjunto de datos de validación se mide al final de la iteración de entrenamiento, y la precisión en el conjunto de datos de entrenamiento se considera como el valor promedio entre todas las iteraciones de entrenamiento.
La razón principal de este comportamiento es el uso de la subred MobileNet pre-entrenada, que fue entrenada previamente en un gran conjunto de datos de gatos y perros. En el proceso de aprendizaje, nuestra red continúa expandiendo el conjunto de datos de entrenamiento de entrada (el mismo aumento), pero no el conjunto de validación. Esto significa que las imágenes generadas en el conjunto de datos de entrenamiento son más difíciles de clasificar que las imágenes normales del conjunto de datos validados.
Verificar los resultados de la predicción
Para repetir el gráfico de la sección anterior, primero debe obtener una lista ordenada de nombres de clase:
class_names = np.array(info.features['label'].names) class_names
Conclusión
array(['cat', 'dog'], dtype='<U3')
Pase el bloque con imágenes a través del modelo y convierta los índices resultantes en nombres de clase:
predicted_batch = model.predict(image_batch) predicted_batch = tf.squeeze(predicted_batch).numpy() predicted_ids = np.argmax(predicted_batch, axis=-1) predicted_class_names = class_names[predicted_ids] predicted_class_names
Conclusión
array(['cat', 'cat', 'cat', 'cat', 'dog', 'cat', 'dog', 'cat', 'cat', 'cat', 'cat', 'cat', 'dog', 'cat', 'cat', 'dog', 'cat', 'cat', 'cat', 'cat', 'cat', 'cat', 'dog', 'dog', 'dog', 'dog', 'cat', 'cat', 'dog', 'cat', 'cat', 'dog'], dtype='<U3')
Echemos un vistazo a las etiquetas verdaderas y pronosticadas:
print(": ", label_batch) print(": ", predicted_ids)
Conclusión
: [0 0 0 0 1 0 1 0 0 0 0 0 1 0 0 1 0 0 0 0 0 0 1 1 1 1 0 1 1 0 0 1] : [0 0 0 0 1 0 1 0 0 0 0 0 1 0 0 1 0 0 0 0 0 0 1 1 1 1 0 0 1 0 0 1]
plt.figure(figsize=(10, 9)) for n in range(30): plt.subplot(6, 5, n+1) plt.subplots_adjust(hspace=0.3) plt.imshow(image_batch[n]) color = "blue" if predicted_ids[n] == label_batch[n] else "red" plt.title(predicted_class_names[n].title(), color=color) plt.axis('off') _ = plt.suptitle(" (: , : )")

Zambullirse en redes neuronales convolucionales
Utilizando redes neuronales convolucionales, logramos asegurarnos de que se las arreglan bien con la tarea de clasificar imágenes. Sin embargo, por el momento, apenas podemos imaginar cómo funcionan realmente. Si pudiéramos entender cómo ocurre el proceso de aprendizaje, entonces, en principio, podríamos mejorar aún más el trabajo de clasificación. Una forma de entender cómo funcionan las redes neuronales convolucionales es visualizar las capas y los resultados de su trabajo. Le recomendamos que estudie los materiales aquí para comprender mejor cómo visualizar los resultados de las capas convolucionales.

El campo de visión por computadora vio la luz al final del túnel y ha progresado significativamente desde el advenimiento de las redes neuronales convolucionales. La increíble velocidad con la que se lleva a cabo la investigación en esta área y las enormes series de imágenes publicadas en Internet han dado resultados increíbles en los últimos años. El auge de las redes neuronales convolucionales comenzó con AlexNet en 2012, que fue creado por Alex Krizhevsky, Ilya Sutskever y Jeffrey Hinton y ganó el famoso desafío de reconocimiento visual a gran escala ImageNet. Desde entonces, no había duda en el futuro brillante utilizando redes neuronales convolucionales, y el campo de la visión por computadora y los resultados del trabajo en él solo confirmaron este hecho. Comenzando por reconocer su cara en un teléfono móvil y terminando con el reconocimiento de objetos en automóviles autónomos, las redes neuronales convolucionales ya han logrado mostrar y demostrar su fuerza y resolver muchos problemas del mundo real.
A pesar de la gran cantidad de grandes conjuntos de datos y modelos pre-entrenados de redes neuronales convolucionales, a veces es extremadamente difícil entender cómo funciona la red y para qué está capacitada exactamente esta red, especialmente para las personas que no tienen el conocimiento suficiente en el campo del aprendizaje automático. , , , Inception, . . , , , , .
" Python"
François Chollet. , . Keras, , " " TensorFlow, MXNET Theano. , , . , .
, , .
(training accuracy) . , , , , Inception, .
, , . Inception v3 ( ImageNet) , Kaggle. Inception, , Inception v3 .
10 () 32 , 2292293. 0.3195, — 0.6377. ImageDataGenerator , . GitHub .
, "" , . .
, Inception v3 , .

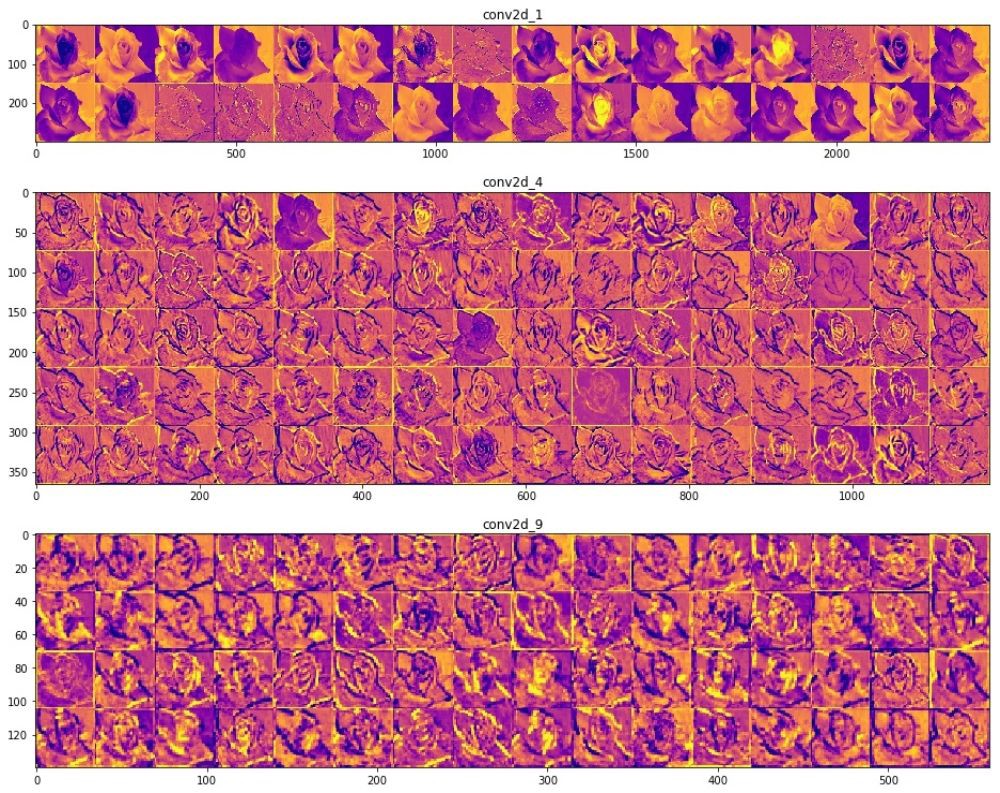
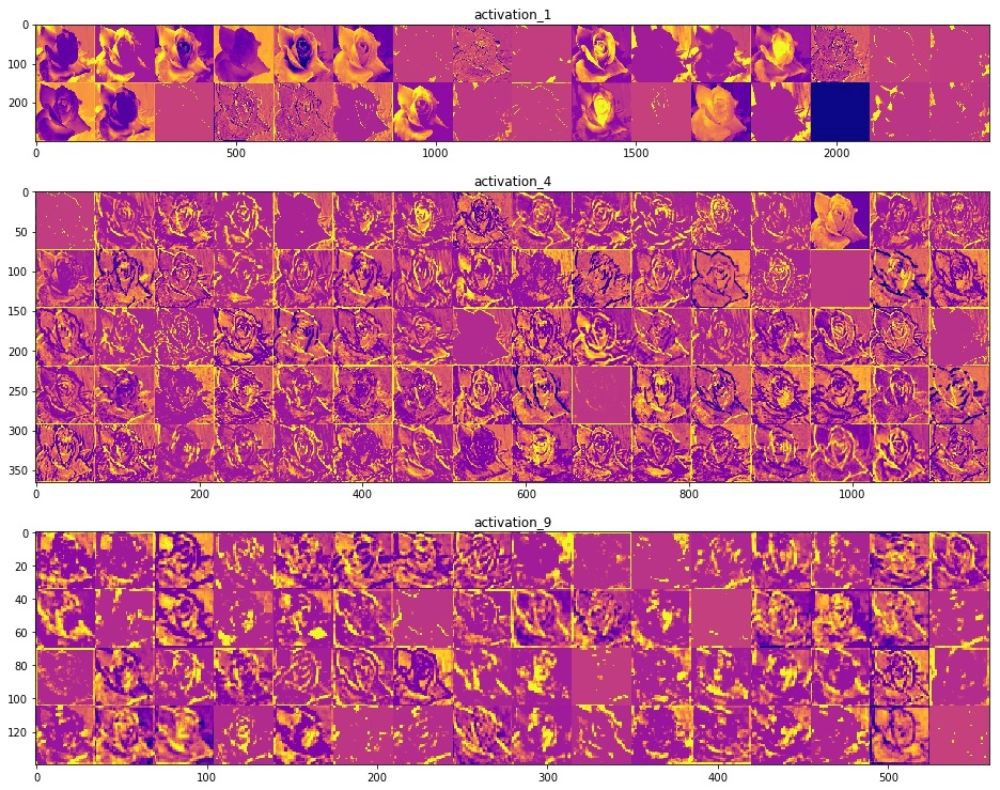
— . .
, () . (), , , , . , , , , .
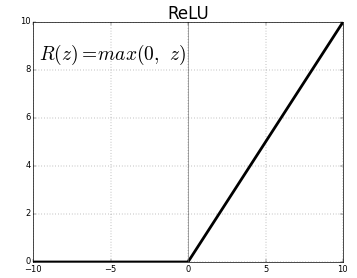
ReLU- . , ReLU(z) = max(0, z) .
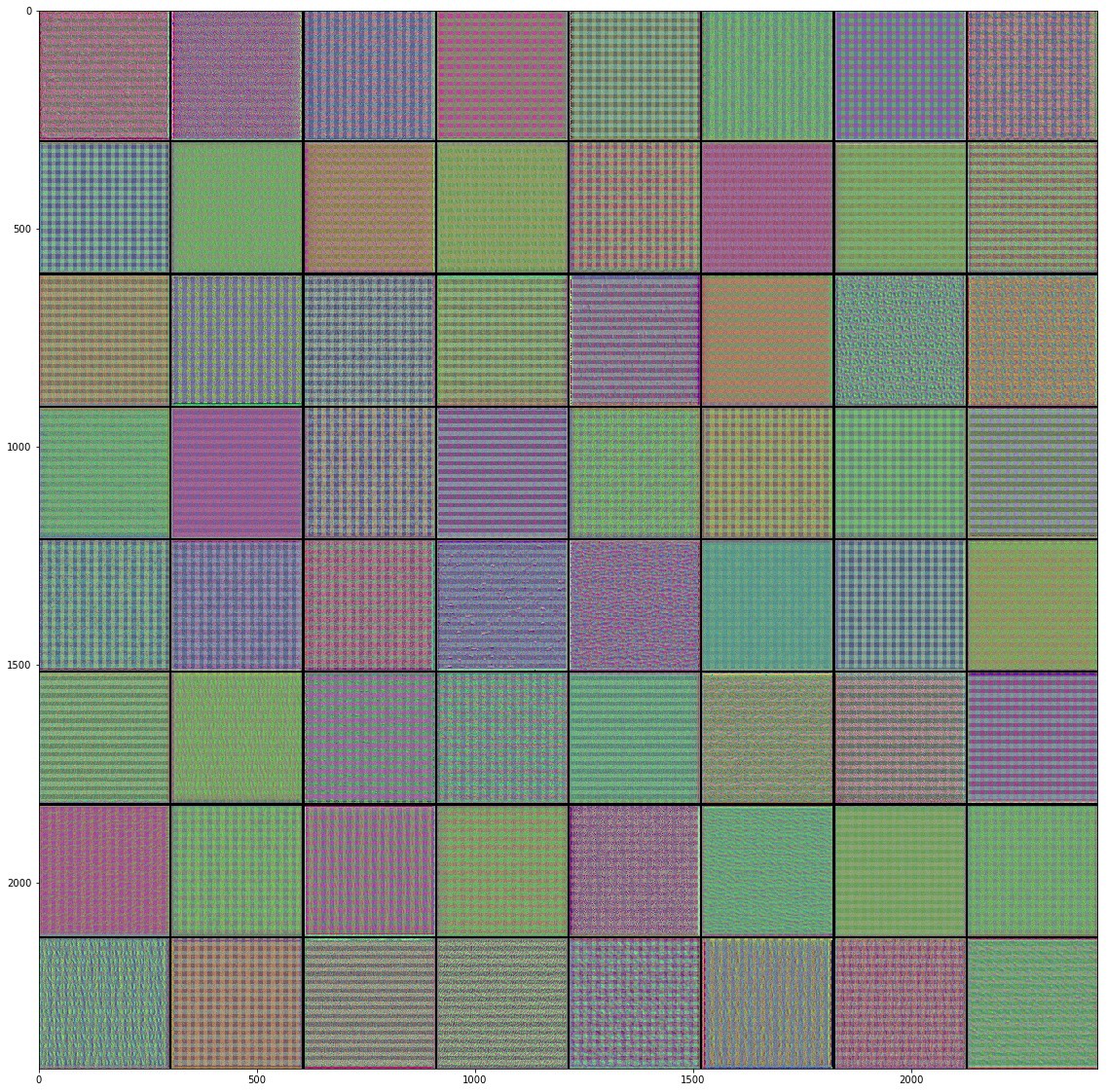
, , , , , , , , .. , . "" () , , , .
"" . .
, Inveption V3 :
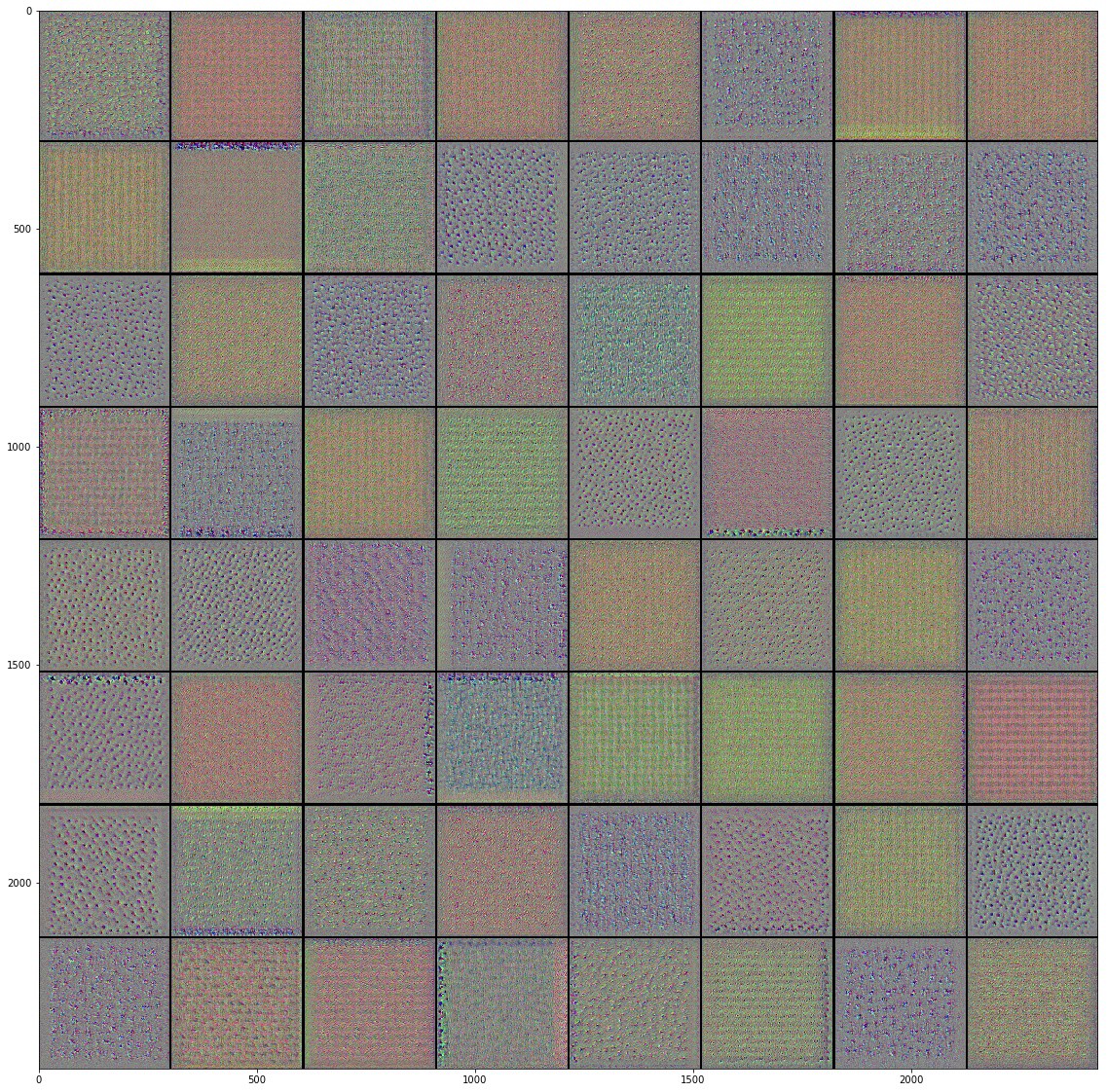

, . , , , , .. , , . , , , "" ( , ).
, , , . , .
Class Activation Map ( ). CAM . 2D , .
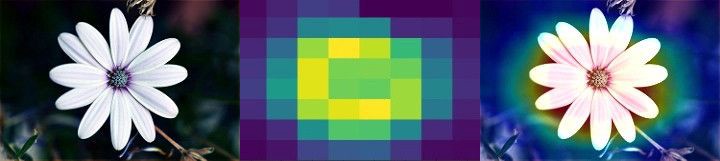

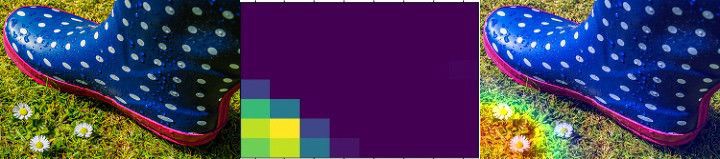
, . , , Mixed- Inception V3-, . () , .
, , . , , . , . , , , , .
, "" - . . .
, , .
:
Colab Colab .
TensorFlow Hub
TensorFlow Hub , .
. , , , .
.
Runtime -> Reset all runtimes...
, :
from __future__ import absolute_import, division, print_function, unicode_literals import numpy as np import matplotlib.pyplot as plt import tensorflow as tf tf.enable_eager_execution() import tensorflow_hub as hub import tensorflow_datasets as tfds from tensorflow.keras import layers
:
WARNING:tensorflow: The TensorFlow contrib module will not be included in TensorFlow 2.0. For more information, please see: * https://github.com/tensorflow/community/blob/master/rfcs/20180907-contrib-sunset.md * https://github.com/tensorflow/addons * https://github.com/tensorflow/io (for I/O related ops) If you depend on functionality not listed there, please file an issue.
import logging logger = tf.get_logger() logger.setLevel(logging.ERROR)
TensorFlow Datasets
TensorFlow Datasets. , — tf_flowers . , . tfds.splits (70%) (30%). tfds.load . tfds.load , , .
splits = tfds.Split.TRAIN.subsplit([70, 30]) (training_set, validation_set), dataset_info = tfds.load('tf_flowers', with_info=True, as_supervised=True, split=splits)
:
Downloading and preparing dataset tf_flowers (218.21 MiB) to /root/tensorflow_datasets/tf_flowers/1.0.0... Dl Completed... 1/|/100% 1/1 [00:07<00:00, 3.67s/ url] Dl Size... 218/|/100% 218/218 [00:07<00:00, 30.69 MiB/s] Extraction completed... 1/|/100% 1/1 [00:07<00:00, 7.05s/ file] Dataset tf_flowers downloaded and prepared to /root/tensorflow_datasets/tf_flowers/1.0.0. Subsequent calls will reuse this data.
, , () , , — .
num_classes = dataset_info.features['label'].num_classes num_training_examples = 0 num_validation_examples = 0 for example in training_set: num_training_examples += 1 for example in validation_set: num_validation_examples += 1 print('Total Number of Classes: {}'.format(num_classes)) print('Total Number of Training Images: {}'.format(num_training_examples)) print('Total Number of Validation Images: {} \n'.format(num_validation_examples))
:
Total Number of Classes: 5 Total Number of Training Images: 2590 Total Number of Validation Images: 1080
— .
for i, example in enumerate(training_set.take(5)): print('Image {} shape: {} label: {}'.format(i+1, example[0].shape, example[1]))
:
Image 1 shape: (226, 240, 3) label: 0 Image 2 shape: (240, 145, 3) label: 2 Image 3 shape: (331, 500, 3) label: 2 Image 4 shape: (240, 320, 3) label: 0 Image 5 shape: (333, 500, 3) label: 1
— , MobilNet v2 — 224224 (grayscale). image () label () .
IMAGE_RES = 224 def format_image(image, label): image = tf.image.resize(image, (IMAGE_RES, IMAGE_RES))/255.0 return image, label BATCH_SIZE = 32 train_batches = training_set.shuffle(num_training_examples//4).map(format_image).batch(BATCH_SIZE).prefetch(1) validation_batches = validation_set.map(format_image).batch(BATCH_SIZE).prefetch(1)
TensorFlow Hub
TensorFlow Hub . , , .
feature_extractor MobileNet v2. , TensorFlow Hub ( ) . . tf2-preview/mobilenet_v2/feature_vector , URL MobileNet v2 . feature_extractor hub.KerasLayer input_shape .
URL = "https://tfhub.dev/google/tf2-preview/mobilenet_v2/feature_vector/4" feature_extractor = hub.KerasLayer(URL, input_shape=(IMAGE_RES, IMAGE_RES, 3))
, :
feature_extractor.trainable = False
, . . .
model = tf.keras.Sequential([ feature_extractor, layers.Dense(num_classes, activation='softmax') ]) model.summary()
:
Model: "sequential" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= keras_layer (KerasLayer) (None, 1280) 2257984 _________________________________________________________________ dense (Dense) (None, 5) 6405 ================================================================= Total params: 2,264,389 Trainable params: 6,405 Non-trainable params: 2,257,984
, .
model.compile( optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy']) EPOCHS = 6 history = model.fit(train_batches, epochs=EPOCHS, validation_data=validation_batches)
:
Epoch 1/6 81/81 [==============================] - 17s 216ms/step - loss: 0.7765 - acc: 0.7170 - val_loss: 0.0000e+00 - val_acc: 0.0000e+00 Epoch 2/6 81/81 [==============================] - 12s 147ms/step - loss: 0.3806 - acc: 0.8757 - val_loss: 0.3485 - val_acc: 0.8833 Epoch 3/6 81/81 [==============================] - 12s 146ms/step - loss: 0.3011 - acc: 0.9031 - val_loss: 0.3190 - val_acc: 0.8907 Epoch 4/6 81/81 [==============================] - 12s 147ms/step - loss: 0.2527 - acc: 0.9205 - val_loss: 0.3031 - val_acc: 0.8917 Epoch 5/6 81/81 [==============================] - 12s 148ms/step - loss: 0.2177 - acc: 0.9371 - val_loss: 0.2933 - val_acc: 0.8972 Epoch 6/6 81/81 [==============================] - 12s 146ms/step - loss: 0.1905 - acc: 0.9456 - val_loss: 0.2870 - val_acc: 0.9000
~90% 6 , ! , , ~76% 80 . , MobilNet v2 .
.
acc = history.history['acc'] val_acc = history.history['val_acc'] loss = history.history['loss'] val_loss = history.history['val_loss'] epochs_range = range(EPOCHS) plt.figure(figsize=(8, 8)) plt.subplot(1, 2, 1) plt.plot(epochs_range, acc, label='Training Accuracy') plt.plot(epochs_range, val_acc, label='Validation Accuracy') plt.legend(loc='lower right') plt.title('Training and Validation Accuracy') plt.subplot(1, 2, 2) plt.plot(epochs_range, loss, label='Training Loss') plt.plot(epochs_range, val_loss, label='Validation Loss') plt.legend(loc='upper right') plt.title('Training and Validation Loss') plt.show()
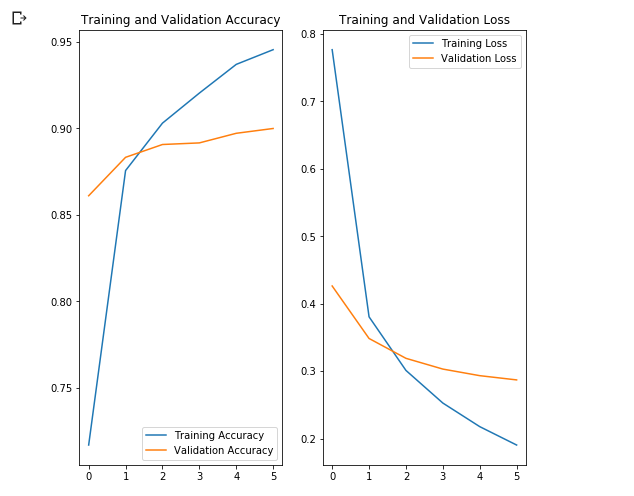
, , .
, , .
- MobileNet, . ( augmentation), . .
NumPy. , .
class_names = np.array(dataset_info.features['label'].names) print(class_names)
:
['dandelion' 'daisy' 'tulips' 'sunflowers' 'roses']
next() image_batch ( ) label_batch ( ). image_batch label_batch NumPy .numpy() . .predict() . np.argmax() . .
image_batch, label_batch = next(iter(train_batches)) image_batch = image_batch.numpy() label_batch = label_batch.numpy() predicted_batch = model.predict(image_batch) predicted_batch = tf.squeeze(predicted_batch).numpy() predicted_ids = np.argmax(predicted_batch, axis=-1) predicted_class_names = class_names[predicted_ids] print(predicted_class_names)
:
['sunflowers' 'roses' 'tulips' 'tulips' 'daisy' 'dandelion' 'tulips' 'sunflowers' 'daisy' 'daisy' 'tulips' 'daisy' 'daisy' 'tulips' 'tulips' 'tulips' 'dandelion' 'dandelion' 'tulips' 'tulips' 'dandelion' 'roses' 'daisy' 'daisy' 'dandelion' 'roses' 'daisy' 'tulips' 'dandelion' 'dandelion' 'roses' 'dandelion']
print("Labels: ", label_batch) print("Predicted labels: ", predicted_ids)
:
Labels: [3 4 2 2 1 0 2 3 1 1 2 1 1 2 2 2 0 0 2 2 0 4 1 1 0 4 1 2 0 0 4 0] Predicted labels: [3 4 2 2 1 0 2 3 1 1 2 1 1 2 2 2 0 0 2 2 0 4 1 1 0 4 1 2 0 0 4 0]
plt.figure(figsize=(10,9)) for n in range(30): plt.subplot(6,5,n+1) plt.subplots_adjust(hspace = 0.3) plt.imshow(image_batch[n]) color = "blue" if predicted_ids[n] == label_batch[n] else "red" plt.title(predicted_class_names[n].title(), color=color) plt.axis('off') _ = plt.suptitle("Model predictions (blue: correct, red: incorrect)")

Inception-
TensorFlow Hub tf2-preview/inception_v3/feature_vector . Inception V3 . , Inception V3 . , Inception V3 299299 . Inception V3 MobileNet V2.
IMAGE_RES = 299 (training_set, validation_set), dataset_info = tfds.load('tf_flowers', with_info=True, as_supervised=True, split=splits) train_batches = training_set.shuffle(num_training_examples//4).map(format_image).batch(BATCH_SIZE).prefetch(1) validation_batches = validation_set.map(format_image).batch(BATCH_SIZE).prefetch(1) URL = "https://tfhub.dev/google/tf2-preview/inception_v3/feature_vector/4" feature_extractor = hub.KerasLayer(URL, input_shape=(IMAGE_RES, IMAGE_RES, 3), trainable=False) model_inception = tf.keras.Sequential([ feature_extractor, tf.keras.layers.Dense(num_classes, activation='softmax') ]) model_inception.summary()
:
Model: "sequential_1" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= keras_layer_1 (KerasLayer) (None, 2048) 21802784 _________________________________________________________________ dense_1 (Dense) (None, 5) 10245 ================================================================= Total params: 21,813,029 Trainable params: 10,245 Non-trainable params: 21,802,784
model_inception.compile( optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy']) EPOCHS = 6 history = model_inception.fit(train_batches, epochs=EPOCHS, validation_data=validation_batches)
:
Epoch 1/6 81/81 [==============================] - 44s 541ms/step - loss: 0.7594 - acc: 0.7309 - val_loss: 0.0000e+00 - val_acc: 0.0000e+00 Epoch 2/6 81/81 [==============================] - 35s 434ms/step - loss: 0.3927 - acc: 0.8772 - val_loss: 0.3945 - val_acc: 0.8657 Epoch 3/6 81/81 [==============================] - 35s 434ms/step - loss: 0.3074 - acc: 0.9120 - val_loss: 0.3586 - val_acc: 0.8769 Epoch 4/6 81/81 [==============================] - 35s 434ms/step - loss: 0.2588 - acc: 0.9282 - val_loss: 0.3385 - val_acc: 0.8796 Epoch 5/6 81/81 [==============================] - 35s 436ms/step - loss: 0.2252 - acc: 0.9375 - val_loss: 0.3256 - val_acc: 0.8824 Epoch 6/6 81/81 [==============================] - 35s 435ms/step - loss: 0.1996 - acc: 0.9440 - val_loss: 0.3164 - val_acc: 0.8861
Resumen
. :
- : , . .
- : . "" , , .
- MobileNet: Google, . MobileNet .
MobileNet . . MobileNet .
… call-to-action — , share :)
YouTube
Telegrama
VKontakte
Ojok .