Hola a todos!
Ya hablé en este blog sobre la organización de un sistema de monitoreo modular para la arquitectura de microservicios y sobre la transición de Graphite + Whisper a Graphite + ClickHouse para almacenar métricas bajo altas cargas. Después de eso, mi colega Sergey Noskov escribió sobre el primer enlace en nuestro sistema de monitoreo: el Bioyino desarrollado por nosotros, un agregador de métricas escalables distribuidas.
Ha llegado el momento de actualizar la información sobre cómo estamos preparando el monitoreo en Avito: nuestro último artículo ya fue en 2018, y durante este tiempo hubo varios cambios interesantes en la arquitectura de monitoreo, la activación y la administración de notificaciones, varias optimizaciones de datos en ClickHouse y otras innovaciones, sobre lo que solo quiero contarte.

Pero empecemos en orden.
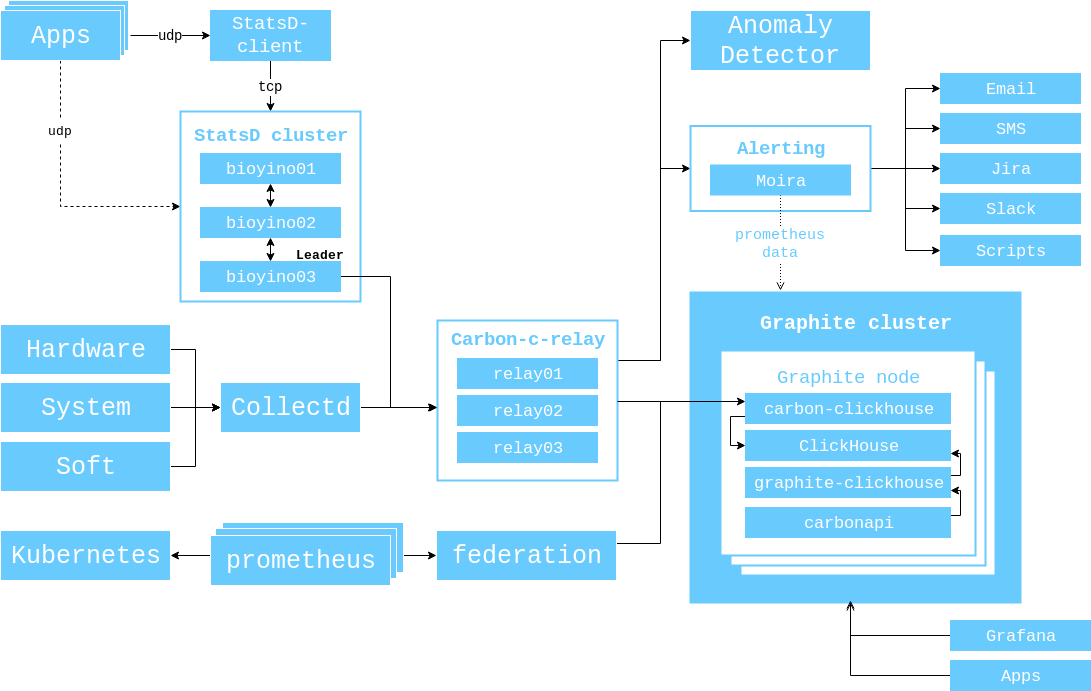
En 2017, mostré un diagrama de la interacción de componentes que era relevante en ese momento, y me gustaría demostrarlo nuevamente para que no tenga que cambiar de pestaña una vez más.

A partir de ese momento, sucedió lo siguiente.
El número de servidores en el clúster Graphite ha aumentado de 3 a 6.
( 56 CPU 2.60GHz, 384GB RAM, 10 SSD SAS 745GB, Raid 6, 10GBit/s Net ).
Reemplazamos brubeck con bioyino , nuestra propia implementación de StatsD con Rust, e incluso escribimos un artículo completo al respecto . Sin embargo, después del lanzamiento del artículo, mencionamos el soporte para etiquetas (Graphite) y Raft para seleccionar un líder.
Descubrimos la posibilidad de usar bioyino como agente StatsD y colocamos dichos agentes junto a las instancias de monolitos, así como donde se necesitaba en k8s.
Finalmente nos deshicimos del viejo sistema de monitoreo de Munin (formalmente todavía lo tenemos, pero sus datos ya no se usan).
La recopilación de datos de los grupos de Kubernetes se organizó a través de Prometheus / Federations, ya que Heapster no era compatible con las nuevas versiones de Kubernetes.
Monitoreo
En los últimos dos años, el número de métricas aceptadas y procesadas ha crecido aproximadamente 9 veces.
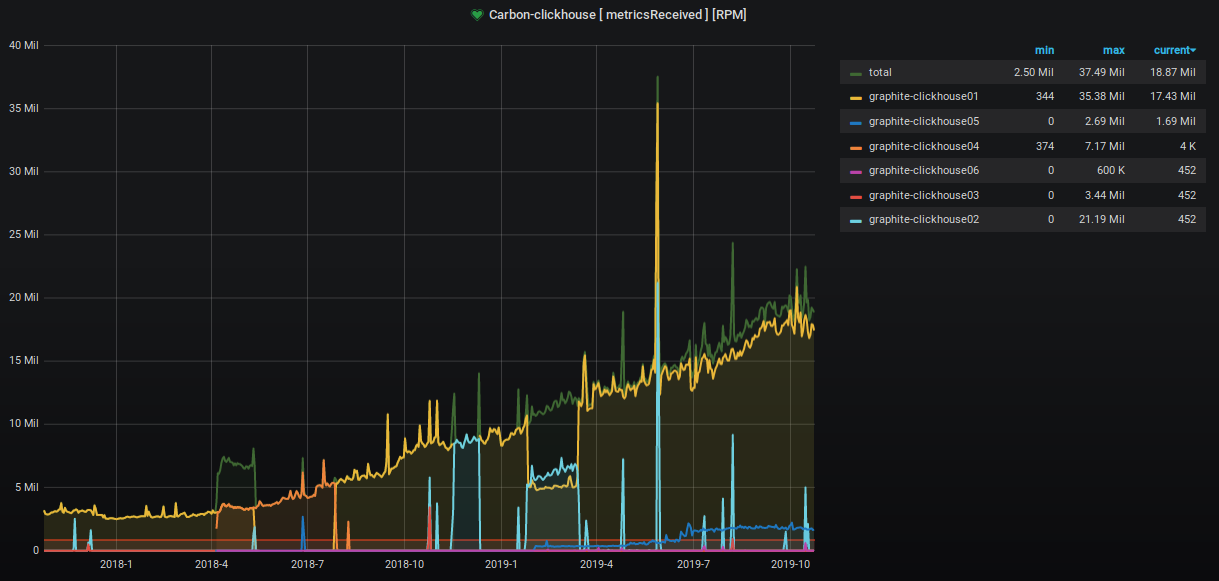
El porcentaje del espacio ocupado del servidor también se está incrementando inexorablemente, y estamos tomando varias medidas para reducirlo. Esto es claramente visible en el gráfico.
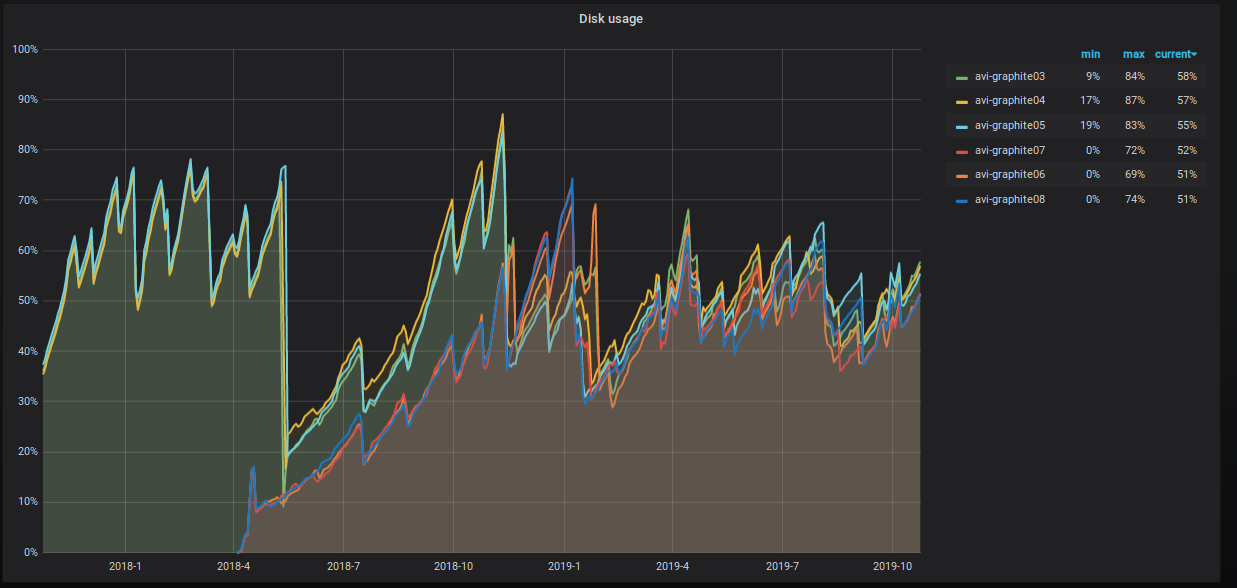
¿Qué estamos haciendo exactamente?
10 10 10 * * clickhouse-client -q "select distinct partition from system.parts where active=1 and database='graphite' and table='data' and max_date between today()-55 AND today()-35;" | while read PART; do clickhouse-client -u systemXXX --password XXXXXXX -q "OPTIMIZE TABLE graphite.data PARTITION ('"$PART"') FINAL";done
- Compartimos tablas de datos. Ahora tenemos tres fragmentos con dos réplicas, cada una con una clave de fragmentación hash en nombre de la métrica. Este enfoque nos da la oportunidad de realizar procedimientos de acumulación , ya que todos los valores para una métrica específica están dentro del mismo fragmento, y el espacio en disco en todos los fragmentos se utiliza de manera uniforme.
El esquema de la tabla distribuida es el siguiente.
CREATE TABLE graphite.data_all ( `Path` String, `Value` Float64, `Time` UInt32, `Date` Date, `Timestamp` UInt32 ) ENGINE = Distributed ( 'graphite_cluster', 'graphite', 'data', jumpConsistentHash(cityHash64(Path), 3) )
También asignamos al usuario derechos de lectura "predeterminados" y lanzamos la ejecución de los procedimientos de escritura a las tablas a un sistema de usuario systemXXX .
La configuración del clúster de grafito en ClickHouse es la siguiente.
<remote_servers> <graphite_cluster> <shard> <internal_replication>true</internal_replication> <replica> <host>graphite-clickhouse01</host> <port>9000</port> <user>systemXXX</user> <password>XXXXXX</password> </replica> <replica> <host>graphite-clickhouse04</host> <port>9000</port> <user>systemXXX</user> <password>XXXXXX</password> </replica> </shard> <shard> <internal_replication>true</internal_replication> <replica> <host>graphite-clickhouse02</host> <port>9000</port> <user>systemXXX</user> <password>XXXXXX</password> </replica> <replica> <host>graphite-clickhouse05</host> <port>9000</port> <user>systemXXX</user> <password>XXXXXX</password> </replica> </shard> <shard> <internal_replication>true</internal_replication> <replica> <host>graphite-clickhouse03</host> <port>9000</port> <user>systemXXX</user> <password>XXXXXX</password> </replica> <replica> <host>graphite-clickhouse06</host> <port>9000</port> <user>systemXXX</user> <password>XXXXXX</password> </replica> </shard> </graphite_cluster> </remote_servers>
Además de la carga de escritura, el número de solicitudes para leer datos de Graphite ha aumentado. Estos datos se utilizan para:
- procesamiento de activación y generación de alertas;
- muestra gráficos en monitores en la oficina y pantallas de computadoras portátiles y de PC de un número creciente de empleados de la compañía.
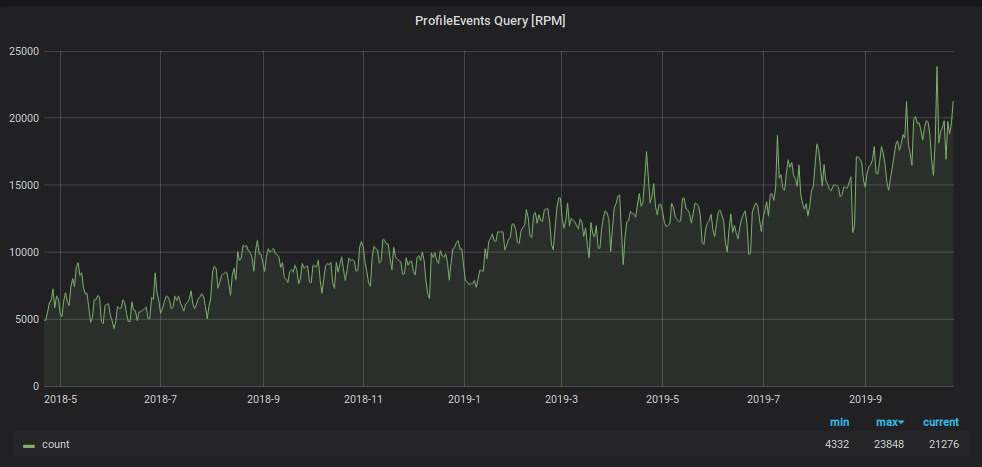
Para evitar que el monitoreo se ahogue bajo esta carga, utilizamos otro truco: almacenamos los datos de los últimos dos días en una placa "pequeña" separada, y enviamos todas las solicitudes de lectura de los últimos dos días allí, reduciendo la carga en la tabla de fragmentos principal. También para esta tableta "pequeña", utilizamos un esquema de almacenamiento métrico inverso, que aceleró en gran medida la búsqueda de los datos contenidos en ella y organizó una partición diaria para ello. El esquema de esta placa es el siguiente.
CREATE TABLE graphite.data_reverse ( `Path` String, `Value` Float64, `Time` UInt32 CODEC(Delta(4), ZSTD(1)), `Date` Date, `Timestamp` UInt32 ) ENGINE = ReplicatedGraphiteMergeTree ( '/clickhouse/tables/{cluster}/data_reverse', '{replica}', 'graphite_rollup' ) PARTITION BY Date ORDER BY (Path, Time) SETTINGS index_granularity = 4096
Para dirigir los datos a él, agregamos una nueva sección al archivo de configuración de la aplicación carbon-clickhouse .
[upload.graphite_reverse] type = "points-reverse" table = "graphite.data_reverse" threads = 2 url = "http://systemXXX:XXXXXXX@localhost:8123/" timeout = "60s" cache-ttl = "6h0m0s" zero-timestamp = true
Para eliminar particiones anteriores a dos días, escribimos una tarea cron. Se ve algo como esto.
1 12 * * * clickhouse-client -q "select distinct partition from system.parts where active=1 and database='graphite' and table='data_reverse' and max_date<today()-2;" | while read PART; do clickhouse-client -u systemXXX --password XXXXXXX -q "ALTER TABLE graphite.data_reverse DROP PARTITION ('"$PART"')";done
Para leer los datos de la tabla, en el archivo de configuración de grafito-clickhouse , se agregó una sección:
[[data-table]] table = "graphite.data_reverse" max-age = "48h" reverse = true
Como resultado, tenemos una tabla con el 100% de los datos replicados en los seis servidores que procesan la carga de lectura completa de las solicitudes con una ventana de menos de dos días (y tenemos el 95% de estos). Y también tenemos una tabla fragmentada con 1/3 de los datos en cada fragmento, que proporciona la lectura de todos los datos históricos. E incluso si tales solicitudes son mucho más pequeñas, la carga de ellas es mucho mayor.
¿Qué está pasando con la CPU? Como resultado del aumento en el volumen de datos grabados y leídos en el clúster Graphite, la carga total de CPU en los servidores también aumentó. Se ve algo como esto.
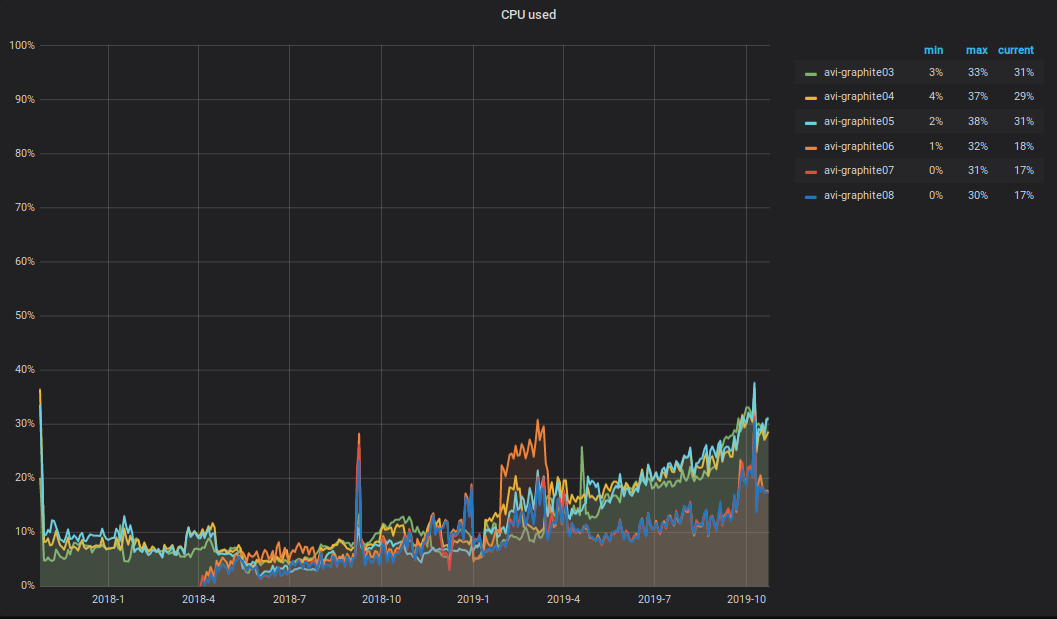
Me gustaría llamar la atención sobre el siguiente matiz: la mitad de la CPU se destina al análisis y al procesamiento primario de métricas en carbon-c-relay (v3.2 de 2018-09-05, que es responsable del transporte de métricas), que se encuentra en tres de cada seis servidores. Como puede ver en el gráfico, son estos tres servidores los que están en la parte SUPERIOR.
Alerta
Como sistema de alerta, todavía tenemos a Moira y al cliente de moira escritos para ello. Para una gestión flexible de disparadores, notificaciones y escalamientos, utilizamos una descripción declarativa llamada alert.yaml. Se genera automáticamente cuando se crea un servicio a través de PaaS (se puede encontrar más información sobre esto en el artículo de Vadim Madison "Lo que sabemos sobre microservicios" ) y se coloca en su repositorio. Para trabajar con alert.yaml, hicimos un enlace en moira-client y lo llamamos alert-autoconf (estamos planeando abrirnos). Hay un paso en el ensamblaje del servicio en TeamCity con la exportación de disparadores y notificaciones a Moira a través de alert-autoconf. Al realizar cambios en alert.yaml, se ejecutan pruebas automáticas que verifican la validez del archivo yaml y también hacen solicitudes a Graphite para cada plantilla de métrica para verificar su corrección.
Para los equipos de infraestructura que no usan PaaS, hemos organizado un repositorio separado llamado Alerting. Hizo la estructura de la forma: Equipo / Proyecto / alert.yaml. Para cada alert.yaml, generamos un ensamblado separado en TeamCity, que ejecuta pruebas y empuja el contenido de alert.yaml en Moira.
Por lo tanto, todos nuestros empleados pueden administrar sus disparadores, notificaciones y escalamientos utilizando un enfoque único.
Como antes teníamos activadores activados a través de la GUI, implementamos la capacidad de cargarlos en formato yaml. El contenido del documento yaml recibido se puede insertar en alert.yaml prácticamente sin transformaciones adicionales, y luego enviar los cambios al asistente. Durante la compilación, alert-autoconf comprenderá que dicho disparador ya existe y lo registrará en nuestro registro en Redis.
Y no hace mucho tiempo, recibimos un turno de ingenieros 24x7. Para transferirles desencadenantes para el servicio, es suficiente en su alert.yaml para completar correctamente la descripción de "qué hacer si lo ve", coloque la etiqueta [24x7] y envíe los cambios al asistente. Después de lanzar alert.yaml, todos los desencadenantes descritos en él caerán automáticamente bajo la supervisión de turno de 24 horas 24x7. U - ¡Simplifica! Belleza!
Colección de métricas empresariales
Desde el último artículo sobre recopilación y procesamiento de métricas comerciales, nuestro bioyino ha mejorado aún más.
- En lugar de elegir un líder a través del cónsul , se utiliza la balsa incorporada.
- Las etiquetas se procesan correctamente en formato de grafito .
- Ahora puede usar bioyino (StatsD-server) como agente.
- Para contar valores únicos, se admite el formato "set".
- La agregación final de métricas se puede hacer en varios hilos.
- Los datos pueden enviarse a fragmentos de grafito en múltiples conexiones paralelas.
- Se corrigieron todos los errores encontrados.
Ahora funciona así.
Comenzamos a introducir activamente agentes StatsD junto a todos los grandes generadores métricos grandes: en contenedores con instancias de monolitos, en vainas k8 junto a servicios, en hosts con componentes de infraestructura, etc.
El agente Statsd se encuentra al lado de la aplicación. De todos modos, toma métricas de esta aplicación a través de UDP, pero ya no usa el subsistema de red (debido a las optimizaciones en el kernel de Linux). Todos los eventos se agregan previamente y los datos recopilados cada segundo (el intervalo se puede configurar) se envían al grupo principal de servidores StatsD (bioyino0 [1-3]) en el formato Cap'n Proto.
El procesamiento adicional y la agregación de métricas, la elección de un líder en el clúster de StatsD y el envío de las métricas por parte del líder a Graphite permanecieron prácticamente sin cambios. Puedes leer sobre esto en detalle en nuestro último artículo .
En cuanto a los números, son los siguientes.
Gráfico de eventos StatsD recibidos
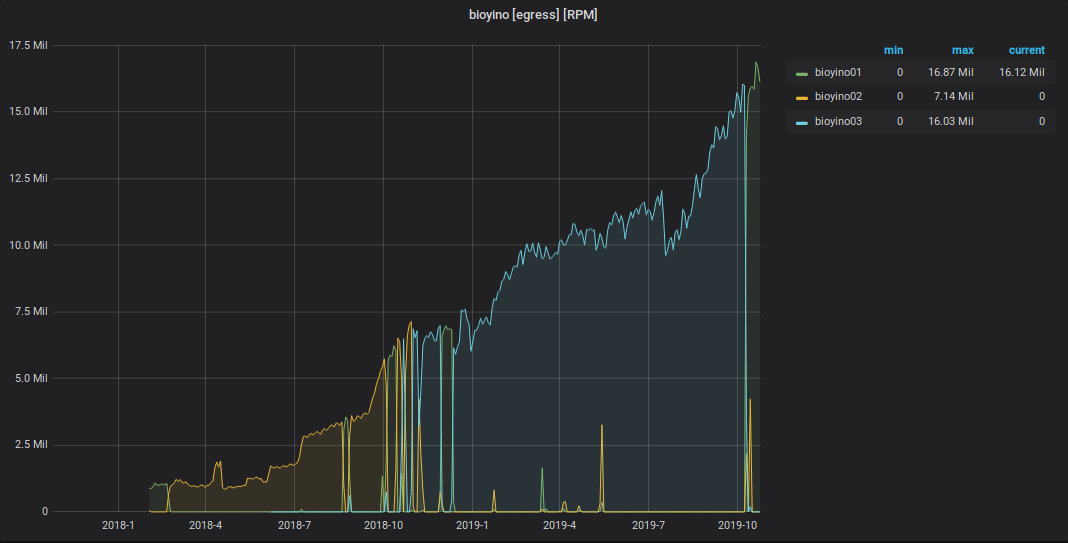

Gráfico de métricas enviadas desde StatsD a Graphite
Total
El esquema general de interacción entre los componentes de monitoreo en este momento se ve así.
Número total de métricas: 2 189 484 898 474.
Profundidad total de almacenamiento de métricas: 3 años.
El número de nombres de métrica únicos: 6 585 413 171.
Número de disparadores: 1053, sirven de 1 a 15k métricas.
Planes para el futuro cercano:
- comenzar a mover servicios de productos a un esquema de almacenamiento métrico etiquetado;
- agregue tres servidores más al clúster Graphite;
- hacer amigos a Moira con tejido persistente ;
- Encuentre otro desarrollador en el equipo de monitoreo.
Estaré encantado de hacer comentarios y preguntas aquí, escriba. Y también actuaré en Highload ++ el 7 de noviembre , si estás allí, podemos hablar.