En el
último artículo, descubrimos que el caché es ciertamente algo útil, pero con respecto a la lógica del controlador, a veces crea dificultades. En particular, introduce la imprevisibilidad de la duración del pulso u otros retrasos en la formación programática de los diagramas de tiempo. Bueno, y en el plan "programático general", la mala ubicación de la función puede reducir la ganancia del caché a nada, provocando que se reinicie constantemente desde la memoria lenta. Mencioné que hace 15 años teníamos que hacer un preprocesador especial que solucionara los problemas que surgieron para el procesador SPARC-8, y prometí decir cuán fácil sería solucionar esas dificultades al desarrollar un procesador Nios II sintetizado recomendado para usar en el paquete Redd. Ha llegado el momento de cumplir la promesa.

Artículos anteriores de la serie:
- Desarrollo del "firmware" más simple para FPGAs instalados en Redd, y depuración utilizando la prueba de memoria como ejemplo.
- Desarrollo del "firmware" más simple para FPGAs instalados en Redd. Parte 2. Código del programa.
- Desarrollo de su propio núcleo para incrustar en un sistema de procesador basado en FPGA.
- Desarrollo de programas para el procesador central Redd sobre el ejemplo de acceso a la FPGA.
- Los primeros experimentos utilizando el protocolo de transmisión en el ejemplo de la conexión de la CPU y el procesador en el FPGA del complejo Redd.
- Merry Quartusel, o cómo el procesador ha llegado a tal vida.
- Métodos de optimización de código para Redd. Parte 1: efecto caché.
Hoy, nuestro libro de referencia será el
Manual de diseño integrado , o más bien, su sección
7.5. Uso de memoria estrechamente acoplada con el Tutorial del procesador Nios II . La sección en sí es colorida. Hoy diseñamos sistemas de procesador para Intel FPGA en el programa Platform Designer. En los días de Altera, se llamaba QSys (de ahí la extensión
.qsys del archivo del proyecto). Pero antes de que apareciera QSsys, todos usaban su antepasado, SOPC Builder (en cuya memoria se
dejó la extensión de archivo
.sopcinfo ). Entonces, aunque el documento está marcado con el logotipo de Intel, pero las imágenes que contiene son capturas de pantalla de este SOPC Builder. Fue escrito claramente hace más de diez años, y desde entonces solo se han corregido los términos. Es cierto que los textos son bastante modernos, por lo que este documento es bastante útil como manual de capacitación.
Preparación de equipos
Entonces Queremos agregar memoria a nuestro sistema de procesador Spartan, que nunca se almacena en caché y al mismo tiempo se ejecuta a la velocidad más alta posible. Por supuesto, esta será la memoria interna FPGA. Agregaremos memoria tanto para el código como para los datos, pero estos serán bloques diferentes. Comencemos con la memoria de datos como la más simple.
Agregamos la memoria OnChip ya conocida al sistema.
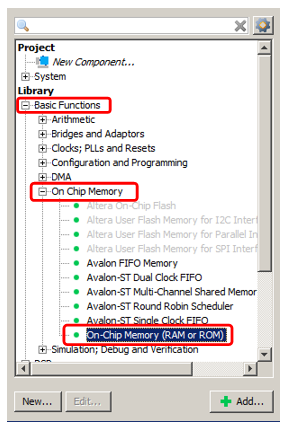
Bueno, digamos que su volumen será de 2 kilobytes (el principal problema con la memoria interna del FPGA es que es pequeño, por lo que debe guardarlo). El resto es memoria ordinaria, que ya hemos agregado.

Pero no lo conectaremos al bus de datos, sino a un bus especial. Para que aparezca, accedemos a las propiedades del procesador, vamos a la pestaña
Caché e interfaces de memoria y en la lista de selección
Número de puertos maestros de datos estrechamente acoplados seleccionamos el valor 1.
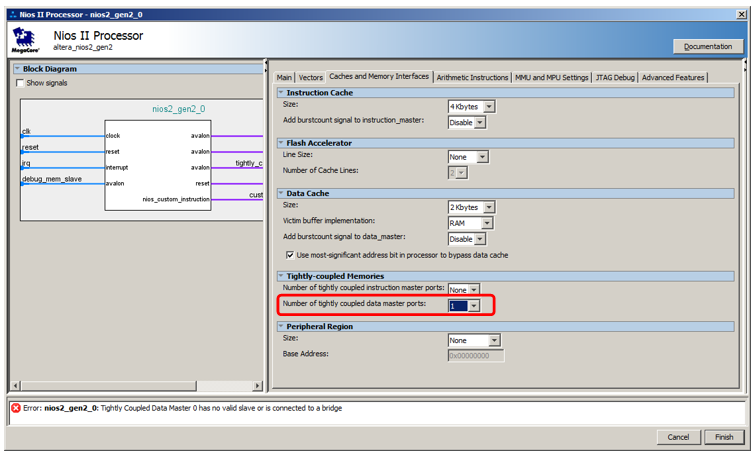
Aquí hay un nuevo puerto para el procesador:

¡Recientemente conectamos el bloque de memoria recién agregado!
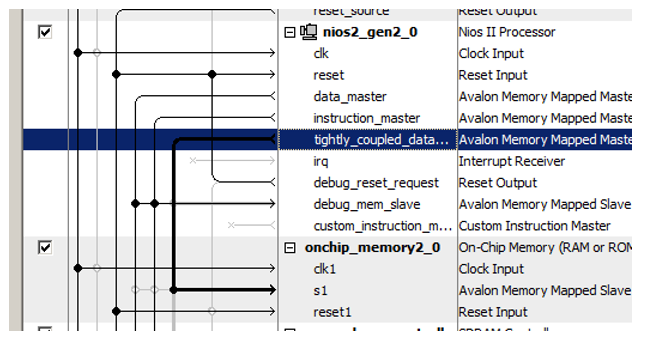
Otro truco está en asignar direcciones a esta nueva memoria. El documento tiene una larga línea de razonamiento sobre la optimización de la decodificación de direcciones. Establece que la memoria no almacenada en caché debe distinguirse de todos los demás tipos de memoria mediante un bit expresado claramente de la dirección. Por lo tanto, en el documento, toda la memoria no almacenable en caché pertenece al rango 0x2XXXXXXX. Ingrese manualmente la dirección 0x2000000 y bloquéela para que no cambie con las siguientes asignaciones automáticas.

Bueno, y puramente por estética, cambie el nombre del bloque ... Llamémoslo, digamos,
NonCachedData .

Con hardware para memoria de datos no en caché, eso es todo. Pasamos a la memoria para el almacenamiento de código. Aquí todo es casi igual, pero un poco más complicado. De hecho, todo se puede hacer de manera completamente idéntica, solo el puerto maestro del bus se abre en la lista
Número de puertos maestros de instrucciones estrechamente acoplados , sin embargo, no será posible depurar dicho sistema. Cuando el programa se completa con el depurador, fluye allí a través del bus de datos. Cuando se detiene, el depurador también lee el código desmontado a través del bus de datos. E incluso si el programa se carga desde un cargador externo (aún no hemos considerado dicho método, especialmente porque en la versión gratuita del entorno de desarrollo estamos obligados a trabajar solo con el depurador JTAG conectado, pero en general, nadie prohíbe hacerlo), el relleno también pasa por el bus datos Por lo tanto, la memoria tendrá que hacer doble puerto. A un puerto, conecte un asistente de instrucciones no almacenado en caché que funcione en el tiempo principal y al otro, un bus de datos auxiliar de tiempo completo. Se utilizará para descargar el programa desde el exterior, así como para obtener el contenido de RAM del depurador. El resto del tiempo este neumático estará inactivo. Así es como se ve todo en la parte teórica del documento:

Tenga en cuenta que el documento no explica por qué, pero se observa que incluso con la memoria de doble puerto, solo se puede conectar un puerto a un maestro sin caché. El segundo debe estar conectado a lo habitual.
Agreguemos 8 kilobytes de memoria, que sea de doble puerto, deje el resto por defecto:
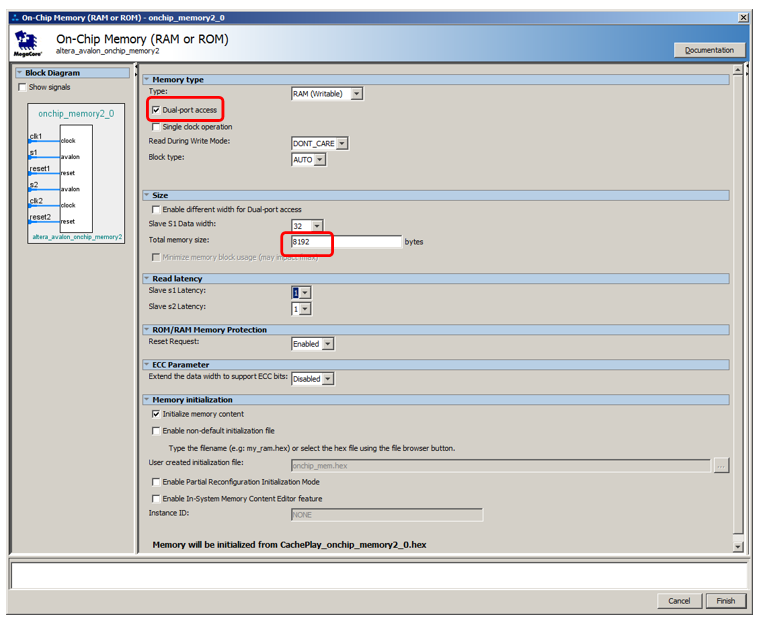
Agregue un puerto de instrucciones no almacenable en caché al procesador:

Llamamos a la memoria
NonCachedCode , conectamos la memoria a los buses, le asignamos la dirección 0x20010000 y la bloqueamos (para ambos puertos). Total, obtenemos algo como esto:
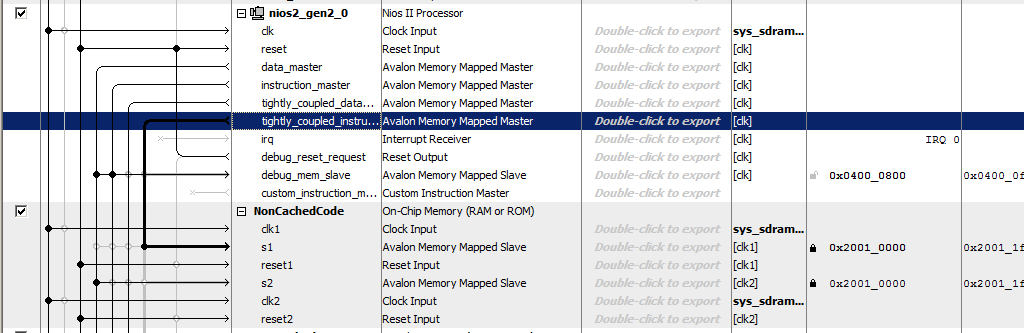
Eso es todo. Guardamos y generamos el sistema, recogemos el proyecto. El hardware está listo. Pasamos a la parte de software.
Preparación de BSP en la parte de software.
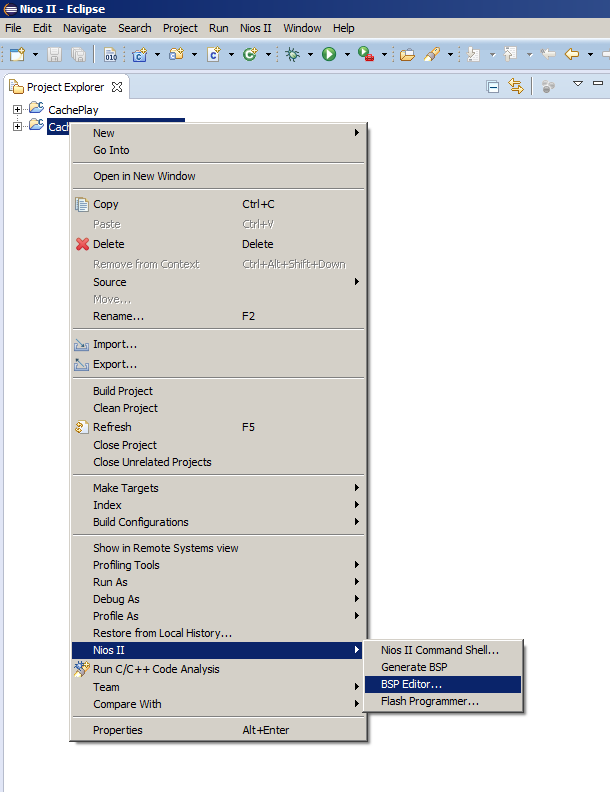
Por lo general, después de cambiar el sistema del procesador, simplemente seleccione el elemento de menú
Generar BSP , pero hoy tenemos que abrir el Editor BSP. Como rara vez hacemos esto, permítame recordarle dónde se encuentra el elemento de menú correspondiente:
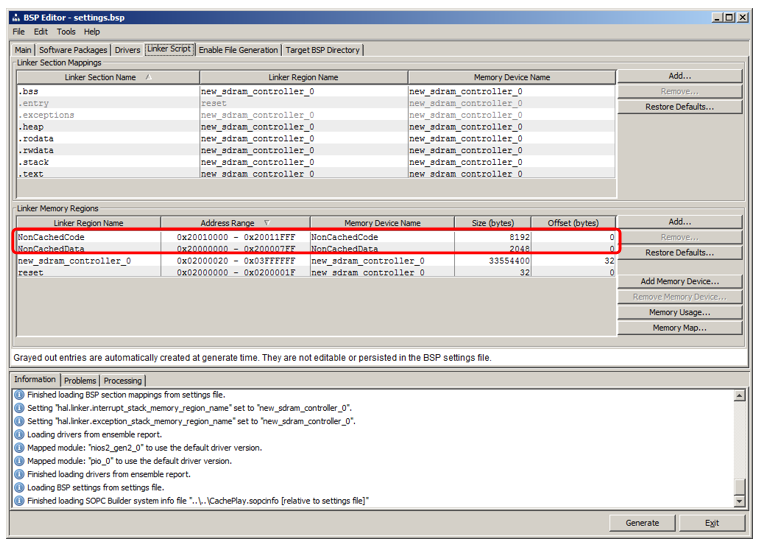
Ahí vamos a la pestaña
Linker Script . Vemos que hemos agregado regiones que heredan nombres de los bloques de RAM:
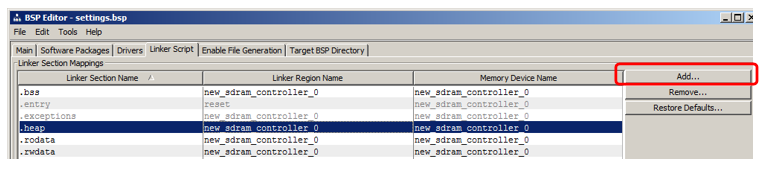
Mostraré cómo agregar una sección en la que se colocará el código. En la sección sección, haga clic en Agregar:
En la ventana que aparece, indique el nombre de la sección (para evitar confusiones en el artículo, lo nombraré muy diferente al nombre de la región, a saber, nccode) y asócielo con la región (seleccioné
NonCachedCode de la lista):

Eso es todo, generar el BSP y cerrar el editor.
Colocar código en una nueva sección de memoria
Permítame recordarle que tenemos dos funciones en el programa heredadas del artículo anterior:
MagicFunction1 () y
MagicFunction2 () . En la primera pasada, ambos cargaron sus cuerpos en el caché, que era visible en el osciloscopio. Además, dependiendo de la situación en el medio ambiente, trabajaron a la máxima velocidad o constantemente frotándose entre sí con sus cuerpos, provocando descargas constantes de SDRAM.
Muevamos la primera función a un nuevo segmento no almacenado en caché, dejemos la segunda en su lugar y luego realicemos un par de ejecuciones.
Para colocar una función en una nueva sección, agréguele el atributo de sección .
Antes de definir la función
MagicFunction1 () , también colocamos su declaración con este atributo:
void MagicFunction1()__attribute__ ((section("nccode"))); void MagicFunction1() { IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); ...
Realizamos la primera ejecución de una iteración del bucle (pongo un punto de interrupción en la línea while):
while (1) { MagicFunction1(); MagicFunction2(); }
Vemos el siguiente resultado:
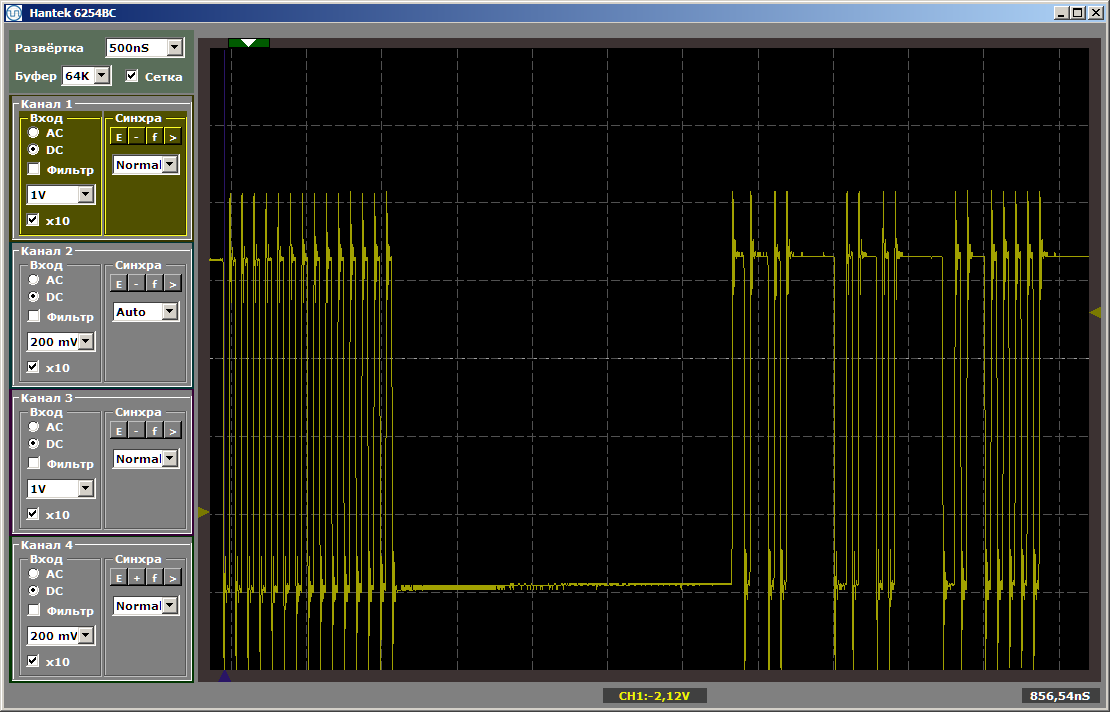
Como puede ver, la primera función se ejecuta realmente a la velocidad máxima, la segunda se carga desde SDRAM. Ejecute la segunda ejecución:
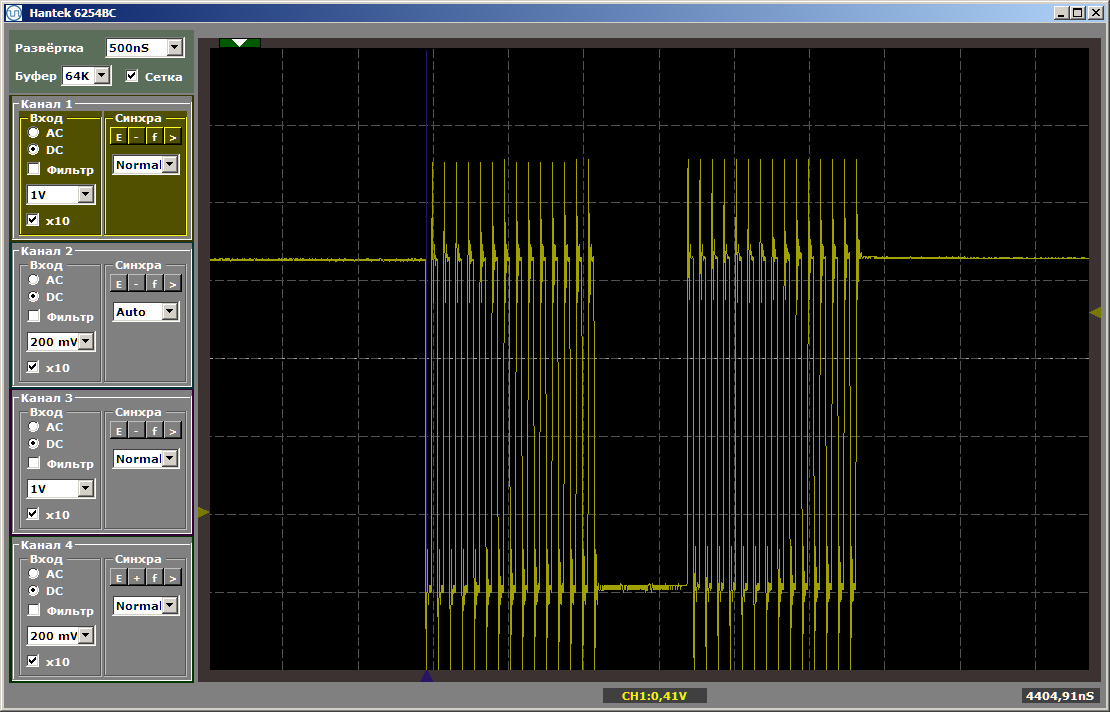
Ambas funciones operan a la velocidad máxima. Y la primera función no descarga la segunda del caché, a pesar de que entre ellas está la inserción que dejé después de escribir el último artículo:
volatile void FuncBetween() { Nops256 Nops256 Nops256 Nops64 Nops64 Nops64 Nops16 Nops16 }
Esta inserción ya no afecta la posición relativa de las dos funciones, ya que la primera dejó en un área de memoria completamente diferente.
Algunas palabras sobre datos
Del mismo modo, puede crear una sección de datos no almacenados en caché y colocar allí variables globales, asignándoles el mismo atributo, pero para ahorrar espacio, no daré tales ejemplos.
Hemos creado una región para dicha memoria, la asignación a la sección se puede hacer de la misma manera que para la sección de código. Solo queda entender cómo asignar el atributo correspondiente a una variable. Aquí está el primer ejemplo de declarar tales datos encontrados en las entrañas del código generado automáticamente:
volatile alt_u32 alt_log_boot_on_flag \ __attribute__ ((section (".sdata"))) = ALT_LOG_BOOT_ON_FLAG_SETTING;
Que nos da
Bueno, en realidad, a partir de las cosas obvias: ahora podemos colocar la parte principal del código en SDRAM, y en la sección no almacenable en caché podemos sacar aquellas funciones que forman diagramas de tiempo mediante programación, o cuyo rendimiento debería ser máximo, lo que significa que no deberían ralentizarse debido a que alguna otra función descarga constantemente el código correspondiente de la memoria caché.
Mire de cerca las llantas.
Ahora observe de cerca los neumáticos en el sistema de procesador resultante. Tenemos casi cuatro de ellos. Rodeé en rojo el autobús principal (que es la unión de los dos, por eso escribí "casi": físicamente, hay dos neumáticos, pero lógicamente, uno). Destaqué en verde el bus que conduce a la memoria de instrucciones no almacenada en caché, en azul, a la memoria de datos no almacenada en caché.
¡Estos tres neumáticos funcionan en paralelo e independientemente uno del otro!
Recuerde, en el
artículo sobre DMA, argumentaba que uno de los factores limitantes del rendimiento es que los datos se transmiten en el mismo bus. El bloque DMA lee datos del bus, los escribe e incluso al mismo tiempo, el núcleo del procesador usa el mismo bus. Como puede ver, este inconveniente de los sistemas cerrados se elimina por completo en el FPGA. En los controladores listos para usar, los fabricantes, al colocar las conexiones, se ven obligados a dividir entre las necesidades y las capacidades. El programador puede necesitar esta opción. Y tal. Y tal. Y entonces ... Se pueden necesitar muchas cosas. Pero los recursos cuestan dinero, y no siempre hay suficiente espacio para ellos en el cristal seleccionado. No puedes publicar todo. Tenemos que elegir lo que todo el mundo realmente necesita y lo que se necesita en casos aislados. Y qué casos aislados deberían introducirse y cuáles deberían olvidarse. Y luego aparecen soluciones de compromiso, todas las sutilezas de las cuales, si hay un deseo de usarlas, el programador tiene que tener en cuenta. En nuestro caso, podemos actuar sin más preámbulos. Lo que necesitamos hoy es hoy puesto. Nuestro recurso es flexible. Lo gastamos para que el equipo sea óptimo para nuestra tarea de hoy. Para las tareas de mañana y ayer, no es necesario reservar recursos. Pero en el día de hoy pondremos todo de tal manera que el programa funcione de la manera más eficiente posible, sin requerir delicias especiales de programación.
Érase una vez, en una universidad en un curso sobre procesadores de señal, nos enseñaron el arte de usar dos autobuses en paralelo con un equipo. Hasta donde yo sé, en los controladores ARM modernos, el conocimiento detallado de la matriz de bus también permite la optimización. Pero todo esto es bueno cuando un desarrollador ha estado trabajando con el mismo sistema durante años. Si tiene que montar piezas de hardware completamente diferentes de un proyecto a otro, no puede memorizar todo. En el caso de los FPGA, no estudiamos las características del entorno, somos libres de personalizar el entorno por nosotros mismos.
En relación con el enfoque "no dedicamos mucho tiempo al desarrollo", suena así:
No necesitamos hacer esfuerzos para optimizar el uso de neumáticos estándar ya preparados, podemos colocarlos rápidamente de la manera más óptima para resolver la tarea, finalizar rápidamente este desarrollo auxiliar y garantizar rápidamente el proceso de depuración o prueba del proyecto principal.
Echemos un vistazo a un ejemplo de inclusión de un bloque DMA de la
Guía del usuario de IP de periféricos integrados para consolidar el material.
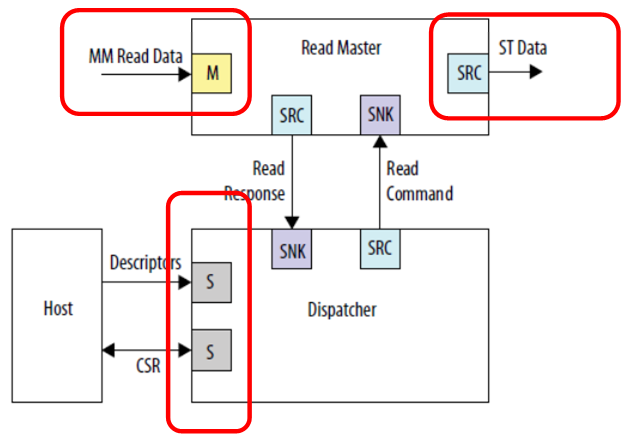
Vemos tres conexiones independientes. Datos de entrada (en esta figura es un bus proyectado en la memoria), datos de salida (en esta figura es un tipo de bus completamente diferente, una interfaz de flujo) y comunicación con el procesador de control. Nadie se molesta en conectarlo todo a diferentes buses, entonces el trabajo irá en paralelo. Los datos de entrada (por ejemplo, de SDRAM) irán en una secuencia, con la que nadie interfiere; la salida irá en un flujo diferente, digamos, al canal FT245-FIFO, que ya hemos considerado; y el procesador central no comerá lejos de estos buses de reloj, ya que el bus principal está aislado. Aunque en este caso, por supuesto, la memoria en SDRAM, al estar en un bus separado, no estará disponible mediante programación. Pero nadie evitará que DMA lo lea. Si el objetivo es lograr un alto rendimiento con el búfer, entonces debe lograrse a toda costa. A menos que todo el programa tenga que caber en la memoria integrada en el FPGA, ya que no hay otras unidades de almacenamiento en el hardware Redd.
Para paralelizar llantas, también puede usar llantas no almacenadas en caché, porque vimos que puede haber varias. Se imponen varias restricciones a los esclavos conectados a estos autobuses:
- el esclavo siempre es uno en el autobús;
- el esclavo no usa el mecanismo de retraso del bus;
- la latencia de escritura es siempre cero; la latencia de lectura es siempre una.
Si se cumplen estas condiciones, dicho dispositivo esclavo se puede conectar a un bus sin caché. Por supuesto, lo más probable es que sea un bus de datos.
En general, conociendo estos principios básicos, ciertamente puede usarlos en tareas reales. Pero, en general, puedes. Puede prescindir de esto, si el resultado se logra por medios convencionales. Pero tenlo en cuenta. A veces, optimizar un sistema a través de estos mecanismos es más sencillo que ajustar el programa.
Conclusión
Examinamos una técnica para transferir secciones de código críticas para el rendimiento o para la previsibilidad de la ejecución del procesamiento en la memoria no almacenable en caché. En el camino, examinamos la posibilidad de optimizar el rendimiento mediante el uso de varios neumáticos que funcionan en paralelo e independientemente el uno del otro.
Para terminar el tema, todavía tenemos que aprender cómo aumentar la frecuencia del reloj del sistema (ahora está limitado al componente que genera pulsos de reloj para el chip SDRAM). Pero como los artículos siguen el principio de "una cosa: un artículo", lo haremos la próxima vez.