Hola a todos! En esta publicación, le diré qué enfoques usamos en Mail.ru Search para comparar textos. ¿Para qué es esto? Tan pronto como aprendamos a comparar diferentes textos entre sí, el motor de búsqueda podrá comprender mejor las solicitudes de los usuarios.
¿Qué necesitamos para esto? Para empezar, establezca estrictamente la tarea. Debe determinar por sí mismo qué textos consideramos similares y cuáles no, y luego formular una estrategia para determinar automáticamente la similitud. En nuestro caso, los textos de las consultas de los usuarios se compararán con los textos de los documentos.
La tarea de determinar la relevancia del texto consta de tres etapas. Primero, el más simple: busque palabras coincidentes en dos textos y saque conclusiones sobre similitudes basadas en los resultados. La siguiente tarea, más difícil, es buscar la conexión entre diferentes palabras, entendiendo los sinónimos. Y finalmente, la tercera etapa: análisis de toda la oración / texto, aislando el significado y comparando oraciones / textos por significados.

Una forma de resolver este problema es encontrar alguna asignación del espacio de texto a otra más simple. Por ejemplo, puede traducir textos al espacio vectorial y comparar vectores.
Volvamos al principio y consideremos el enfoque más simple: encontrar palabras coincidentes en consultas y documentos. Tal tarea en sí misma ya es bastante complicada: para hacer esto bien, necesitamos aprender cómo obtener la forma normal de las palabras, lo que en sí mismo no es trivial.
El modelo de mapeo directo se puede mejorar mucho. Una solución es hacer coincidir los sinónimos condicionales. Por ejemplo, puede ingresar supuestos probabilísticos sobre la distribución de palabras en textos. Puede trabajar con representaciones vectoriales y aislar implícitamente las conexiones entre las palabras que no coinciden, y hacerlo automáticamente.
Como nos dedicamos a la búsqueda, tenemos muchos datos sobre el comportamiento de los usuarios cuando reciben ciertos documentos en respuesta a algunas consultas. En base a estos datos, podemos sacar conclusiones sobre la relación entre diferentes palabras.
Tomemos dos oraciones:

Asigne a cada par de palabras de la consulta y del título algo de peso, lo que significará cuánto se asocia la primera palabra con la segunda. Vamos a predecir el clic como una transformación sigmoidal de la suma de estos pesos. Es decir, establecemos la tarea de regresión logística, en la que los atributos están representados por un conjunto de pares de la forma (palabra de la consulta, palabra del título / texto del documento). Si podemos entrenar tal modelo, entonces entenderemos qué palabras son sinónimos, con mayor precisión, se pueden conectar y cuáles probablemente no.
textbfProbabilidaddeclic= sigma left( sum varphii right) textbf,donde varphii textbf−pesodeunpardepalabras(palabradeconsulta,palabradeldocumento)
Ahora necesita crear un buen conjunto de datos. Resulta que es suficiente tomar el historial de clics de los usuarios, agregar ejemplos negativos. ¿Cómo mezclar en ejemplos negativos? Es mejor agregarlos al conjunto de datos en una proporción de 1: 1. Además, los ejemplos en sí mismos en la primera etapa del entrenamiento se pueden hacer al azar: para un par de consulta-documento, encontramos otro documento al azar, y consideramos que dicho par es negativo. En las etapas posteriores del entrenamiento, es ventajoso dar ejemplos más complejos: aquellos que tienen intersecciones, así como ejemplos aleatorios que el modelo considera similares (minería dura negativa).
Ejemplo: sinónimos de la palabra "triángulo".
En esta etapa, ya podemos distinguir una buena función que coincide con las palabras, pero esto no es lo que estamos buscando. Dicha función nos permite hacer una coincidencia indirecta de palabras y queremos comparar oraciones completas.
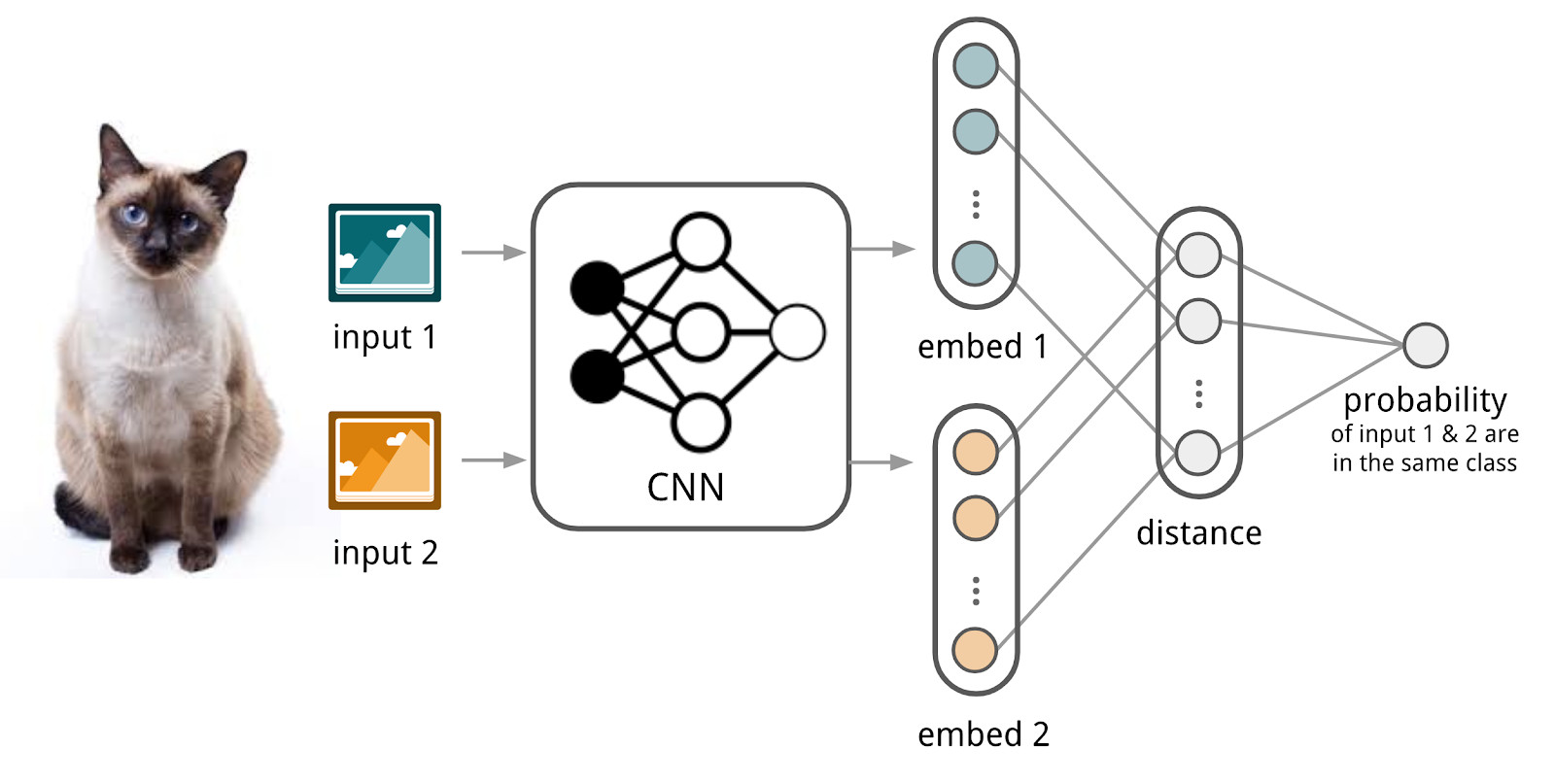
Aquí las redes neuronales nos ayudarán. Hagamos un codificador que acepte texto (una solicitud o un documento) y produzca una representación vectorial de manera que los textos similares tengan vectores que sean vectores cercanos y distantes. Por ejemplo, puede usar la distancia del coseno como una medida de similitud.
Aquí usaremos el aparato de las redes siamesas, porque son mucho más fáciles de entrenar. La red siamesa consta de un codificador, que se aplica a los datos de muestra de dos o más familias y una operación de comparación (por ejemplo, la distancia cosenoidal). Al aplicar el codificador a elementos de diferentes familias, se utilizan los mismos pesos; Esto en sí mismo proporciona una buena regularización y reduce en gran medida la cantidad de factores necesarios para la capacitación.
El codificador produce representaciones vectoriales a partir de textos y aprende de manera que el coseno entre representaciones de textos similares es máximo y entre representaciones de textos distintos es mínimo.
Una red de profunda complejidad semántica DSSM es adecuada para nuestra tarea. Lo usamos con cambios menores, que discutiremos a continuación.
Cómo funciona el DSSM clásico: las consultas y los documentos se presentan en forma de una bolsa de trigramas, de los cuales se obtiene una representación vectorial estándar. Se pasa a través de varias capas completamente conectadas, y la red se entrena de tal manera que se maximiza la probabilidad condicional del documento a pedido, lo que equivale a maximizar la distancia del coseno entre las representaciones vectoriales obtenidas por un paso completo a través de la red.
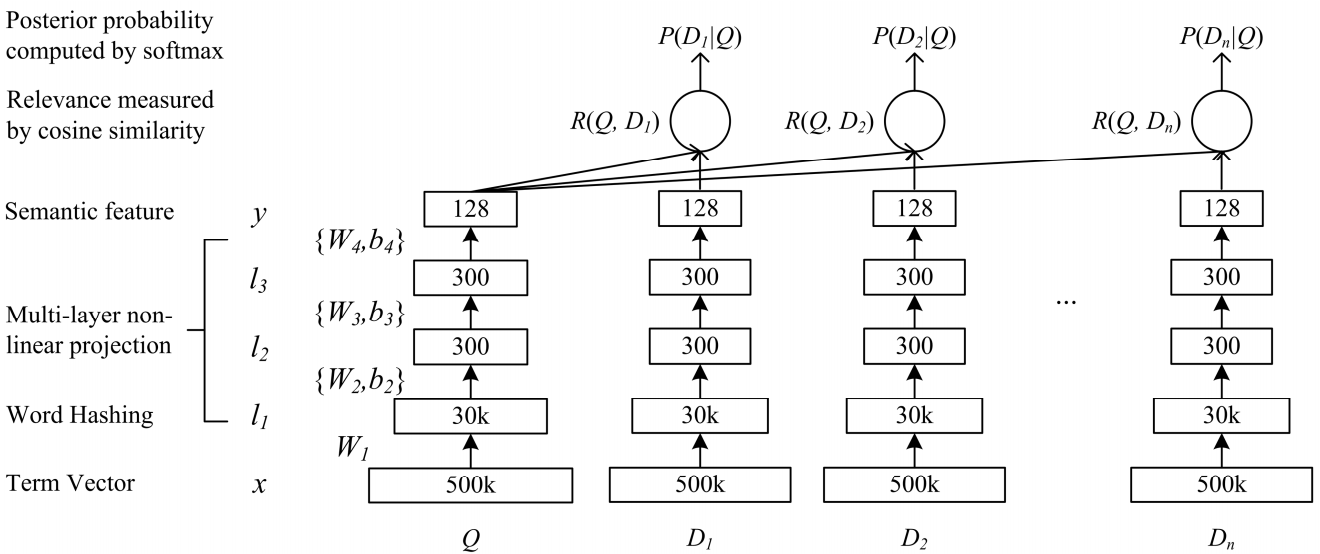 Po-Sen Huang Xiaodong Él Jianfeng Gao Li Deng Alex Acero Larry Heck. 2013 Aprendizaje de modelos semánticos estructurados profundos para la búsqueda web utilizando datos de clics
Po-Sen Huang Xiaodong Él Jianfeng Gao Li Deng Alex Acero Larry Heck. 2013 Aprendizaje de modelos semánticos estructurados profundos para la búsqueda web utilizando datos de clicsFuimos casi de la misma manera. Es decir, cada palabra en la consulta se representa como un vector de trigramas, y el texto como un vector de palabras, dejando así información sobre qué palabra se encontraba. Luego, usamos convoluciones unidimensionales dentro de las palabras, suavizando la representación de estas y la operación de extracción global máxima para agregar información sobre la oración en una representación vectorial simple.

El conjunto de datos que utilizamos para el entrenamiento coincide casi por completo en esencia con el utilizado para el modelo lineal.
No nos detuvimos allí. En primer lugar, se les ocurrió un modo de preentrenamiento. Tomamos una lista de consultas para el documento, ingresando qué usuarios interactúan con este documento, y capacitamos a la red neuronal para incrustar esos pares. Dado que estos pares son de la misma familia, una red de este tipo es más fácil de aprender. Además, es más fácil volver a entrenarlo en ejemplos de combate cuando comparamos solicitudes y documentos.
Ejemplo: los usuarios van a e.mail.ru/login con solicitudes: correo electrónico, entrada de correo electrónico, dirección de correo electrónico, ...Finalmente, la última parte difícil, con la que todavía estamos luchando y en la que casi hemos logrado el éxito, es la tarea de comparar la solicitud con algún documento extenso. ¿Por qué es esta tarea más difícil? Aquí, la maquinaria de las redes siamesas ya está peor adaptada, porque la solicitud y el largo documento pertenecen a diferentes familias de objetos. Sin embargo, apenas podemos permitirnos cambiar la arquitectura. Solo es necesario agregar circunvoluciones también de acuerdo con las palabras, lo que ahorrará más información sobre el contexto de cada palabra para la representación vectorial final del texto.
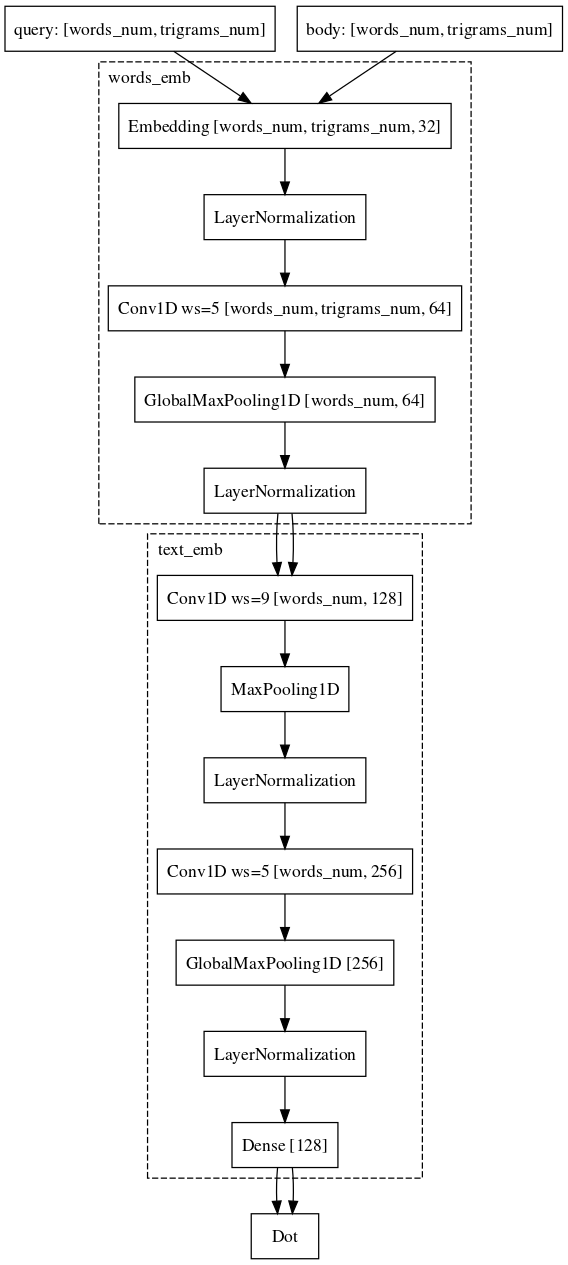
En este momento, continuamos mejorando la calidad de nuestros modelos modificando arquitecturas y experimentando con fuentes de datos y mecanismos de muestreo.