Contenido
A veces los propios insectos nos encuentran. Así que introdujimos una gran fila de datos, y el sistema se colgó. ¿Es por el millón de caracteres que cayeron? ¿O no le gustaba uno en particular?
O el archivo se cargó en el sistema y se bloqueó. Por qué ¿Por nombre, extensión, datos dentro o tamaños? Puede insertar la localización en el desarrollador, dejar que piense qué hay de malo en el archivo. Pero a menudo puede encontrar la razón usted mismo y luego describir con mayor precisión el problema.
Si encuentra los datos mínimos para jugar, entonces:
- Ahorrará tiempo para el desarrollador: no tendrá que conectarse al banco de pruebas, cargar el archivo él mismo y debutar
- El administrador podrá evaluar fácilmente la prioridad de la tarea: ¿es necesario solucionarla con urgencia o el error puede esperar? Si bien el nombre "caen algunos archivos, xs why" es difícil de hacer ...
- También se beneficiará una descripción del error al comprender la causa de la caída.
¿Cómo encontrar los datos mínimos para jugar un error? Si hay alguna pista en los registros, aplíquela. Si no hay pistas, entonces el mejor método es el método de división biseccional (también conocido como método de "bisección" o "dicotomía").
Descripción del método
El método se usa para encontrar el lugar exacto de la caída:
- Tome un paquete de datos que cae.
- Romper por la mitad.
- Marque la mitad 1
- Si cayó, entonces el problema está ahí. Trabajamos más con ella.
- Si no cae → verifique la mitad 2.
- Repita los pasos 1-3 hasta que quede un valor descendente.

El método le permite localizar rápidamente el problema, especialmente si se realiza mediante programación. Los desarrolladores integran tales mecanismos en el procesamiento de datos. Y si no lo incorporan, entonces ellos mismos sufren más tarde cuando el probador se acerca a ellos y les dice: "Cae en este archivo, pero no pude encontrar la razón exacta".
Aplicación por probadores
Fila de datos
Cargó una línea de 1 millón de datos: el sistema se congela.
Intentamos 500 mil (divididos por la mitad), todavía se cuelga.
Intentamos 250 mil, no se cuelga, todo está bien.
↓
De ahí la conclusión de que el problema está en algún lugar entre 250 y 500 mil. Nuevamente aplicamos la división biseccional.
Intentamos 350 mil (dividiéndolo "por ojo" - es bastante permisible, no tienes que encontrar números exactos cuando juegas manualmente) - todo está bien
Intentamos 450 mil, es malo.
Intentamos 400 mil, es malo.
↓
En general, ya puedes obtener un error. Raramente se requiere que el probador informe que el borde o error está claramente en el número 286 586. Es suficiente localizarlo aproximadamente: 290 mil.
Es solo una cosa verificar "10" e inmediatamente "300 mil", y es completamente diferente proporcionar información más completa: "hasta 10 mil todo está bien, de 10 a 280 mil frenos comienzan, ya cae a 290 mil".
Está claro que cuando la cantidad se mide en miles, llevará demasiado tiempo buscar manualmente una cara específica. Sí, el desarrollador no necesita esto. Bueno, nadie quiere perder el tiempo en vano.
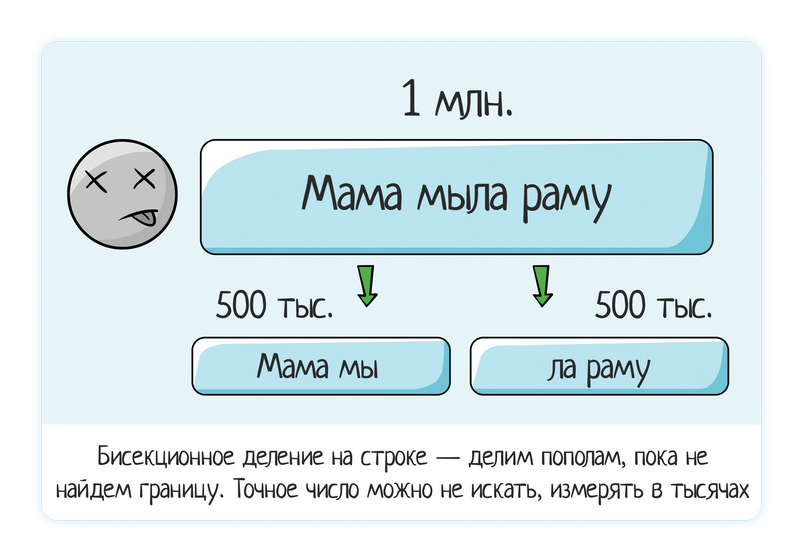
Por supuesto, si el problema original estaba en una línea con una longitud de 10-30 caracteres, puede encontrar el borde exacto. Todo se trata de una relación razonable con el tiempo: si utiliza conjeturas o división biseccional, puede encontrar rápidamente el valor exacto y es pequeño (generalmente hasta 100), estamos seguros. Si los problemas están en una línea grande, más de 1000 → busque aproximadamente.
Archivo
Subió un archivo - se estrelló! Como, porque Primero, tratamos de analizar por nosotros mismos qué podría afectar lo que probó nuestra prueba. Este es el chip de la regla principal "primero positivo, luego negativo". Si no intentas meter todo en una prueba a la vez:
- Comprobado un pequeño archivo de muestra
- Verificamos un enorme archivo de 2GB, con un montón de columnas, un montón de columnas, además de diferentes variaciones de los datos internos.
Será difícil de localizar aquí. Y si separa los cheques:
- Muchas líneas (pero los datos son positivos y verificados anteriormente)
- Muchas columnas
- Peso pesado
- ...
Eso ya es aproximadamente comprensible, cuál es la razón. Por ejemplo, cae en una gran cantidad de líneas, desde 100 mil. Ok, estamos buscando un borde más preciso usando la división biseccional:
- Dividimos el archivo en dos por 50 mil, verificamos el primero.
- Si te caes, divídelo
- Y así, hasta que encontremos un lugar específico para caer
Si la caída depende del número de líneas, buscamos un borde aproximado: "Después de 5000 cae, no hay 4000 mil". No es necesario buscar un lugar específico (4589). Demasiado tiempo y no vale la pena el tiempo.
Este error fue encontrado por estudiantes en Dadat . Los archivos de datos se pueden cargar allí, el sistema procesará y estandarizará estos datos: corrija los errores tipográficos, determine la información que falta en los directorios (código KLADR, FIAS, coordenadas geográficas, distrito de la ciudad, código postal ...).
La niña intentó descargar un archivo grande y obtuvo el resultado: el sistema muestra una barra de progreso al 100% de carga y se cuelga durante más de 30 minutos.
La localización fue más allá: ¿cuándo comienza la congelación? Esto es importante porque afecta la prioridad de la tarea. ¿Cuál es el tamaño de descarga típico? ¿Con qué frecuencia envían los usuarios LOTES directos?
Tal vez el sistema está diseñado para procesar miles de líneas, entonces ese error está repleto en "Solucionarlo algún día". O descargas típicas: 10-50 mil líneas que se procesan normalmente, bueno, eso significa que el error no se está quemando, lo solucionaremos un poco más tarde.
Localización de tareas:
- para un archivo con 50 mil líneas, 15 segundos de bloqueo,
- para un archivo con 100 mil líneas, 30 segundos de bloqueo,
- para un archivo con 150 mil líneas, 1 minuto se cuelga,
- para un archivo con 165 mil líneas cuelga 4 minutos,
- para un archivo 172 mil líneas con una barra de progreso 100% completa se congela durante más de media hora
Aquí es donde el trabajo del probador ya se realiza de forma cualitativa. Se proporciona información completa sobre el funcionamiento del sistema, sobre la base de la cual el administrador ya puede concluir con qué urgencia es necesario corregir el error.
La verificación tampoco lleva demasiado tiempo. Puedes ir o desde el final: aquí hemos descargado 200 mil líneas, ¿y cuándo comienza el problema? ¡Usamos el método de división biseccional!
O comience con un número relativamente pequeño: 50 mil, aumentando gradualmente (a la mitad, el método de división biseccional, todo lo contrario). Sabiendo que todo será malo en 200 mil, entendemos que no habrá muchas pruebas. Verificamos 50, 100, 150: para tres pruebas encontramos un borde aproximado. Y luego cavar ya no es necesario.
Pero recuerda que también necesitas probar tu teoría. ¿Es cierto que el problema está en el número de líneas y no en los datos dentro del archivo? Verificar esto es muy fácil: cree un archivo de 5000 líneas con un solo valor "positivo". Ese valor que funciona exactamente y que ya comprobaste anteriormente. Si no hay caída, entonces el asunto es impuro =)) Parece que la teoría del número de filas era errónea y el asunto está en los datos en sí.
Aunque puede probar 10 mil líneas con exactamente un valor positivo. Es posible que la caída vuelva a ocurrir. Solo su archivo fuente estaba en varias columnas. O había caracteres en el interior que ocupaban más bytes que un valor positivo ... En general, no rechace de inmediato la teoría del tamaño del archivo o el número de líneas. Pruebe la división biseccional, por el contrario, duplique el archivo.
Pero, en cualquier caso, recuerde que cuanto más controles se mezclan en uno, más difícil es localizar el error. Por lo tanto, es mejor probar inmediatamente el número de filas o columnas en un solo valor positivo. Para estar seguro de que está probando la cantidad de datos, no los datos en sí. Análisis de prueba y todo eso =)
Pero, ¿qué pasa si el problema no está en el número de filas, sino en los datos en sí? Y no sabes exactamente dónde. Quizás introdujo datos de "Guerra y paz" en un archivo de prueba, o descargó una hoja de cálculo grande de algún lugar de Internet ... O el usuario encontró un problema: cargó su archivo y todo se cayó. Él vino a apoyar, el apoyo vino a ti: el archivo está en ti, reprodúcelo.
La acción adicional depende de la situación. Si se están ejecutando los plazos del usuario o se le debita dinero, y luego el procesamiento del archivo ha caído, entonces este es un error de bloqueo. Y no hay tiempo para entrenar a un probador de localización. Es más fácil darle el archivo exacto al desarrollador, dejar que sea libre y encontrar la razón por sí mismo.
Pero si usted mismo encontró un error, es tiempo de excavarlo usted mismo. Nuevamente, sin olvidar el sentido común, como siempre con la localización. Al principio tratamos de sacar conclusiones nosotros mismos, luego buscamos ayuda. Para llegar a una conclusión usted mismo, necesita:
- revise los registros, puede haber la respuesta correcta;
- ver el contenido del archivo: algo puede llamar tu atención, esa es la primera teoría;
- usa el método de división biseccional.
Como resultado, en lugar del error "Cae el archivo, x por qué, aquí en el error de archivo adjunto de 2GB", coloca un error bien pensado y localizado: "El archivo cae si la fecha del formato DD / MM / AAAA está dentro". Y luego ya no necesita un archivo de 2GB, ¡solo necesita un archivo para una línea y una columna!

Aplicación por desarrolladores
En una gran cantidad de datos, el probador no busca un límite claro, porque no es razonable hacerlo manualmente. Pero los desarrolladores usan el método de división biseccional en el código y siempre pueden encontrar un lugar específico para caer. Después de todo, el sistema se dividirá hasta la victoria, ¡y no una persona!
Por ejemplo, tenemos un mecanismo para cargar datos en el sistema. Se puede cargar como 10 mil y un millón. Pero esto no importa, ya que la descarga se realiza en lotes de 200 entradas. Si algo salió mal, el sistema mismo realiza una división biseccional. Sí mismo. Hasta que encuentre un lugar problemático. Luego lea en los registros:
- Tiene 1000 entradas
- 200 registros procesados
- 400 registros procesados
- ¡Vaya, cayó en un paquete de 200 discos!
- Intento procesar un paquete de tamaño 100
- Intento procesar un paquete de tamaño 50
- Intento procesar un paquete de tamaño 25
...
- Error en dichos identificadores: el campo de correo electrónico requerido no se completa
- 600 registros procesados
...
Aquí, por supuesto, la lógica adicional también depende del desarrollador. O el procesamiento se detiene después de encontrar un error, o va más allá. ¿Tropezó con un paquete de 200 entradas? Llegamos al punto de encontrar un cuello de botella, marcamos la entrada como errónea, procesamos los 199 restantes y seguimos adelante.
¿Pero y si todo el paquete se desmorona? Marcamos el registro como erróneo, pero los 199 restantes tampoco pudieron procesar. Por qué Aplicamos el mismo método, buscando un nuevo problema. El truco es que siempre debes poder detenerte a tiempo.
Si el número de errores es superior a 10-50-100, entonces es mejor detener la descarga. Es posible que se haya producido un error de carga en el sistema original y recibimos un millón de "curvas" de datos. Si el sistema dividirá cada paquete de 200 registros por la mitad, y luego dividirá los 199 restantes, y así sucesivamente, entonces será malo para todos:
- El registro crece de los 15 mb habituales a 3 gb y se vuelve ilegible;
- El sistema puede fallar al intentar generar un mensaje de error final (hablé sobre esta situación en la sección BMW Mnemonics );
- Se pasa mucho tiempo buscando todos los errores. Sí, el sistema hace esto más rápido que una persona, pero si divide un millón de paquetes de 200 registros, llevará tiempo.
Por lo tanto, el cerebro debe incluirse en todas partes, tanto en las pruebas manuales como al escribir el código del programa. Siempre debes entender cuándo parar. Solo en el caso de las pruebas manuales estará "a punto de encontrar el borde", y en el desarrollo "se detendrá si hay muchas caídas".
Resumen
El método de división biseccional se usa para buscar la ubicación exacta de la caída y la localización del error.
Busque el número y comience a dividirlo por la mitad:
- longitud de línea;
- tamaño de archivo
- peso de archivo;
- número de filas / columnas;
- cantidad de memoria libre en un teléfono móvil;
- ...
Pero recuerda: ¡algún día tienes que parar! No es necesario detenerse y buscar el número exacto si requiere miles de pruebas adicionales. Pero se pueden dar 5-10 minutos para la localización.
PD: busque artículos más útiles en mi blog con la etiqueta "útil"