Hola Mi nombre es Antonina, soy desarrollador de Oracle de la división IT de Sportmaster Lab. He estado trabajando aquí solo por dos años, pero gracias a un equipo amigable, un equipo muy unido, un sistema de mentoría, capacitación corporativa, la masa crítica se ha acumulado cuando quiero no solo consumir conocimiento, sino también compartir mi experiencia.

Entonces, Redefinición basada en la edición. ¿Por qué tuvimos la necesidad de estudiar esta tecnología, además, el término "alta disponibilidad" y cómo nos ayuda la redefinición basada en la edición a medida que los desarrolladores de Oracle ahorran tiempo?
¿Qué propone Oracle como solución? Qué está sucediendo en el patio trasero al aplicar esta tecnología, qué problemas encontramos ... En general, hay muchas preguntas. Trataré de responderlas en dos publicaciones sobre el tema, y la primera ya está por debajo.
Cada equipo de desarrolladores, al crear su propia aplicación, se esfuerza por crear el algoritmo más asequible, más tolerante a fallas y más confiable. ¿Por qué todos nos esforzamos por esto? Probablemente no porque somos tan buenos y queremos lanzar un producto genial. Más precisamente, no solo porque somos tan buenos. También es importante para los negocios. A pesar del hecho de que podemos escribir un algoritmo genial, cubrirlo con pruebas unitarias, ver que es tolerante a fallas, aún (los desarrolladores de Oracle) tenemos un problema: nos enfrentamos a la necesidad de actualizar nuestras aplicaciones. Por ejemplo, nuestros colegas en el sistema de lealtad se ven obligados a hacer esto por la noche.
Si esto sucediera sobre la marcha, los usuarios verían una imagen: "¡Disculpe!", "¡No se entristezca!", "Espere, tenemos actualizaciones y trabajo técnico aquí". ¿Por qué es esto tan importante para los negocios? Pero es muy simple: durante mucho tiempo, las empresas han estado sufriendo pérdidas no solo de algunos bienes reales, valores materiales, sino también pérdidas del tiempo de inactividad de la infraestructura. Por ejemplo, según la revista Forbes, en 13, un minuto de interrupción del servicio de Amazon costó 66 mil dólares. Es decir, en media hora los muchachos perdieron casi $ 2 millones.
Está claro que para las empresas medianas y pequeñas, y no para un gigante como Amazon, estas características cuantitativas serán mucho menores, pero sin embargo, en términos relativos, esto sigue siendo una característica de evaluación significativa.
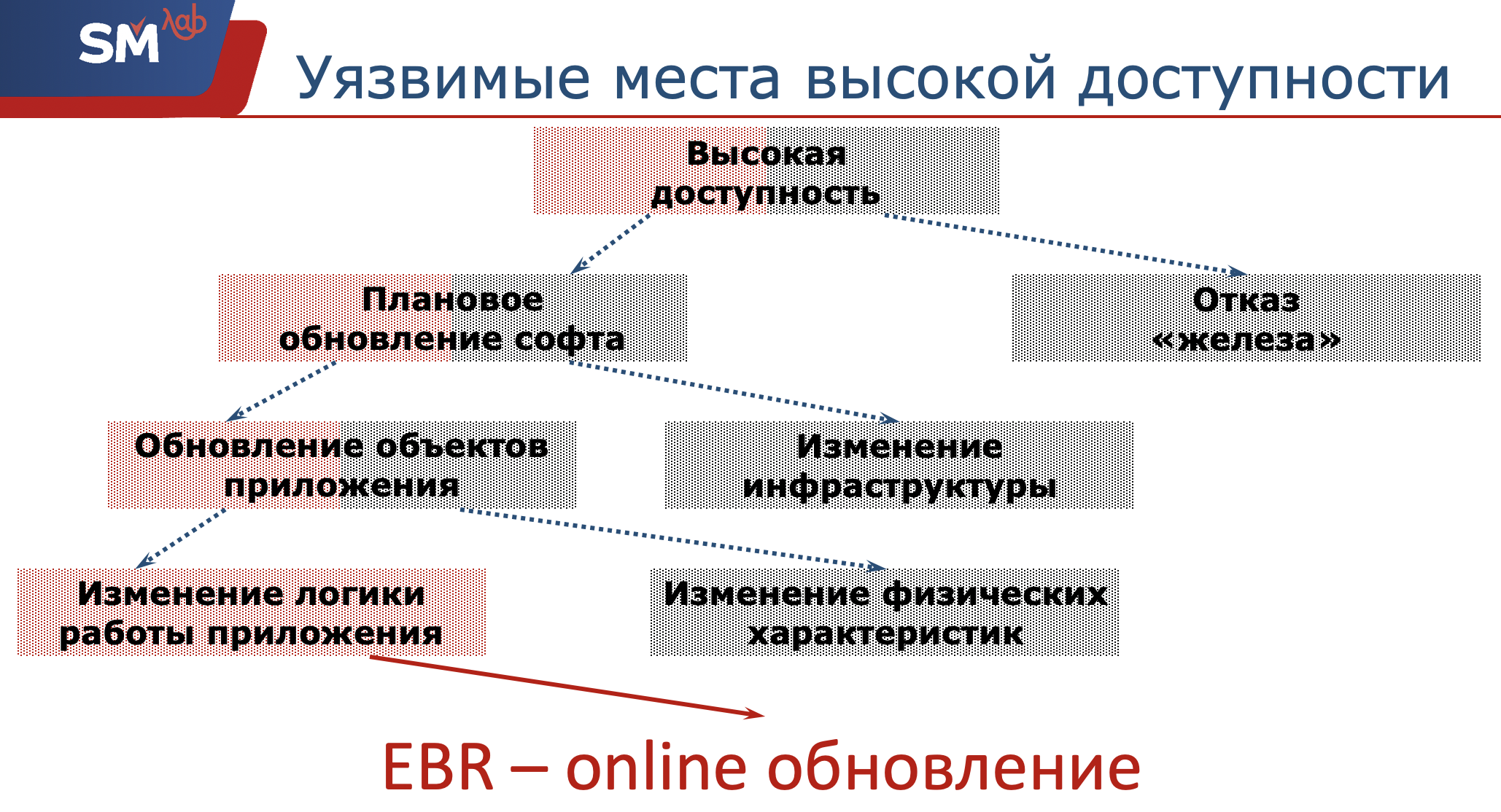
Por lo tanto, debemos garantizar la alta disponibilidad de nuestra aplicación. ¿Cuáles son algunos lugares potencialmente peligrosos que los desarrolladores de Oracle tienen para esta accesibilidad?
Lo primero es lo primero, nuestro hardware puede fallar. Nosotros, como desarrolladores, no somos responsables de esto. Los administradores de red deben asegurarse de que el servidor y los objetos estructurales estén operativos. Lo que estamos llevando a una actualización de software. Nuevamente, las actualizaciones de software programadas se pueden dividir en dos clases. O estamos cambiando algún tipo de infraestructura, por ejemplo, actualizando el sistema operativo en el que gira el servidor. O decidimos pasar a la nueva versión de Oracle (sería bueno si nos mudamos con éxito :)) ... O, la segunda clase, esto es con lo que tenemos la relación máxima: esto es actualizar los objetos de la aplicación que estamos desarrollando con usted.
Nuevamente, esta actualización se puede dividir en dos clases más.
O cambiamos algunas características físicas de este objeto (creo que cada desarrollador de Oracle a veces se encontró con el hecho de que su índice cayó, tuvo que reconstruir el índice sobre la marcha). O, digamos que introdujimos nuevas secciones en nuestras tablas, es decir, no se producirá ninguna parada. Y ese lugar muy problemático es un cambio en la lógica de la aplicación.
Entonces, ¿qué tiene que ver la redefinición basada en la edición? Y esta tecnología: se trata de cómo actualizar la aplicación en línea, sobre la marcha, sin afectar el trabajo de los usuarios.

¿Cuáles son los requisitos para esta actualización en línea? Debemos hacer esto sin que el usuario lo note, es decir, todo debe permanecer en condiciones de funcionamiento, todas las aplicaciones. Siempre que tal situación pueda ocurrir cuando el usuario se sentó, comenzó a trabajar y recordó bruscamente que tenía una reunión urgente o que necesitaba llevar el automóvil al servicio. Se levantó, salió corriendo por su lugar de trabajo. Y en ese momento, de alguna manera actualizamos nuestra aplicación, la lógica del trabajo cambió, los nuevos usuarios ya se han conectado a nosotros, los datos han comenzado a procesarse de una nueva manera. Por lo tanto, debemos garantizar en última instancia el intercambio de datos entre la versión original de la aplicación y la nueva versión de la aplicación. Aquí están, dos requisitos que se presentan para las actualizaciones en línea.

¿Qué se propone como solución? A partir de la versión 11.2 Release Oracle, se introduce la tecnología de redefición basada en la edición y se introducen conceptos como edición, objetos editables, vista de edición, disparador de edición cruzada. Nos permitimos una traducción como "versionar". En general, la tecnología EBR con cierta extensión podría llamarse versionar objetos DBMS dentro del propio DBMS.
Entonces, ¿qué es la edición como entidad?
Este es un tipo de contenedor dentro del cual puede cambiar y configurar el código. Dentro de su propio alcance, dentro de su propia versión. En este caso, los datos se cambiarán y escribirán solo en aquellas estructuras que son visibles en la Edición actual. Las representaciones de versiones serán responsables de esto, y consideraremos su trabajo más a fondo.

Así es como se ve la tecnología en el exterior. ¿Cómo funciona esto? Para empezar, a nivel de código. Tendremos nuestra aplicación original, versión 1, en la que hay algunos algoritmos que procesan nuestros datos. Cuando comprendemos que necesitamos actualizar, al crear una nueva edición, sucede lo siguiente: todos los objetos que procesan el código se heredan en la nueva edición ... Al mismo tiempo, en este sandbox recién creado, podemos divertirnos como queramos, de manera invisible para el usuario: podemos cambiar qué trabajo funciones, procedimientos; cambiar el paquete; Incluso podemos negarnos a usar cualquier objeto.
Que va a pasar La versión original permanece sin cambios, permanece disponible para el usuario y toda la funcionalidad está disponible. En la versión que creamos, en la nueva edición, los objetos que no se han cambiado no han cambiado, es decir, se heredan de la versión original de la aplicación. Con el bloque que hemos mencionado, los objetos se actualizan en la nueva versión. Y, por supuesto, cuando elimina un objeto, no está disponible para nosotros en la nueva versión de nuestra aplicación, pero sigue siendo funcional en la versión original, así de simple funciona a nivel de código.

¿Qué sucede con las estructuras de datos y qué tiene que ver la vista de versiones?

Dado que por estructuras de datos nos referimos a una tabla y una vista de versiones, esto es, de hecho, una concha (llamé a mí mismo la "búsqueda" etológica de nuestra tabla), que es una proyección en las columnas originales. Cuando comprendemos que necesitamos cambiar el funcionamiento de nuestra aplicación y, por ejemplo, agregar columnas a la tabla, o incluso prohibir su uso, creamos una nueva vista de versiones en nuestra nueva versión.

En consecuencia, en él usaremos solo el conjunto de columnas que necesitamos, que procesaremos. Entonces, en la versión original de la aplicación, los datos se escriben en el conjunto que se define en este ámbito. La nueva aplicación escribirá en el conjunto de columnas que se define en su alcance.

Las estructuras son claras, pero ¿qué pasa con los datos? Y cómo todo esto está interconectado, teníamos datos almacenados en las estructuras originales. Cuando comprendemos que tenemos un cierto algoritmo que nos permite convertir datos de la estructura original y descomponer estos datos en una nueva estructura, este algoritmo se puede colocar en los llamados disparadores de versiones cruzadas. Solo apuntan a ver estructuras de diferentes versiones de la aplicación. Es decir, sujeto a la disponibilidad de dicho algoritmo, podemos colgarlo en una mesa. En este caso, los datos se transformarán de las estructuras originales a las nuevas, y los desencadenantes progresivos hacia adelante serán responsables de esto. Siempre que necesitemos garantizar la transferencia de datos a la versión anterior, nuevamente, en función de algún tipo de algoritmo, los desencadenadores inversos serán responsables de esto.
¿Qué sucede cuando decidimos que nuestra estructura de datos ha cambiado y estamos listos para trabajar en modo paralelo tanto para la versión anterior de la aplicación como para la nueva versión de la aplicación? Simplemente podemos inicializar el llenado de nuevas estructuras con alguna actualización inactiva. Después de eso, nuestras dos versiones de la aplicación estarán disponibles para el uso del usuario. La funcionalidad permanece para los usuarios antiguos de la versión anterior de la aplicación; para los usuarios nuevos, la funcionalidad será de la nueva versión de la aplicación.
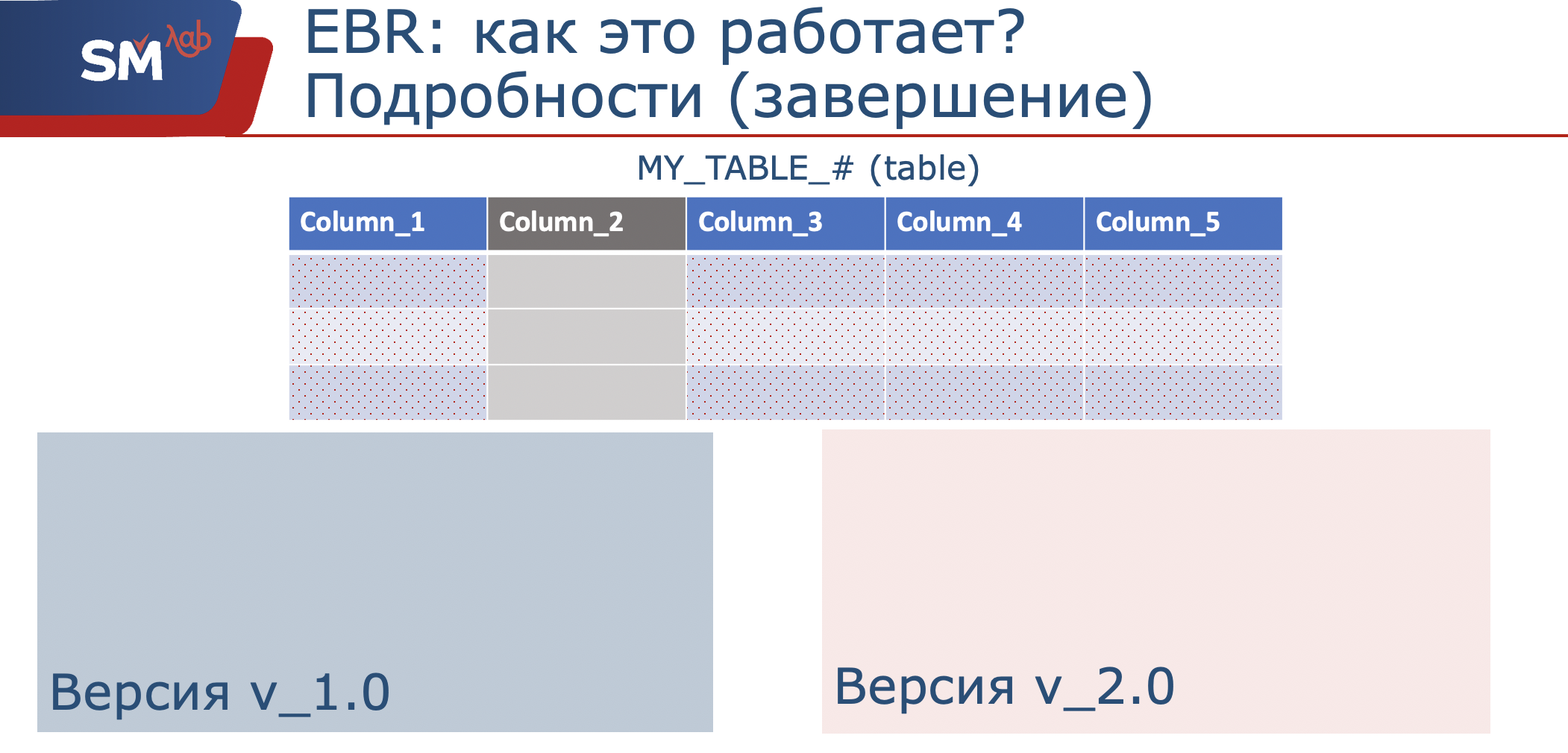
Cuando nos dimos cuenta de que todos los usuarios de la aplicación anterior estaban desconectados, esta versión podría quedar oculta para su uso. Quizás incluso la estructura de datos ha cambiado. Recordamos que con nosotros, la vista de versiones en la versión recién creada ya se verá solo en el conjunto de columnas 1, 3,4,5. Bueno, y en consecuencia, si no necesitamos esta estructura, se puede eliminar. Aquí hay un breve resumen de cómo funciona.

¿Cuáles son las restricciones impuestas? Es decir, bien hecho Oracle, excelente Oracle, excelente Oracle: se les ocurrió algo genial. La primera limitación en este momento son los objetos del tipo versionado, estos son objetos PL / SQL, es decir, procedimientos, paquetes, funciones, disparadores, etc. Los sinónimos están versionados y las vistas están versionadas.
Lo que no está versionado y nunca será versionado son tablas e índices, vistas materializadas. Es decir, en la primera versión, usted y yo solo cambiamos los metadatos y podemos almacenar copias de ellos tanto como desee ... de hecho, un número limitado de copias de estos metadatos, pero más sobre eso más adelante. El segundo se refiere a los datos del usuario, y su replicación requeriría mucho espacio en disco, lo que no es lógico y es muy costoso.

La siguiente limitación es que los objetos de esquema se versionarán completamente si y solo si pertenecen al usuario autorizado para la versión. De hecho, estos privilegios para el usuario son solo una especie de marca en la base de datos. Puede otorgar estos permisos con el comando habitual. Pero llamo su atención sobre el hecho de que esta acción es irreversible. Por lo tanto, no nos arremanguemos de inmediato, escriba todo esto en el servidor de batalla, y primero lo probaremos.
La siguiente limitación es que los objetos no versionados no pueden depender de los versionados. Bueno, eso es bastante lógico. Como mínimo, no entenderemos qué edición, qué versión del objeto mirar. En este punto, me gustaría llamar la atención, porque tuvimos que competir con este momento.
Siguiente Las vistas versionadas pertenecen al propietario del esquema, al propietario de la tabla y solo en cada versión. En esencia, una vista versionada es una envoltura de tabla, por lo que está claro que debe ser única en cada versión de la aplicación.
Lo que también es importante, el número de versiones en la jerarquía puede ser 2000. Lo más probable es que esto se deba al hecho de que no se carga el diccionario de alguna manera. Inicialmente dije que los objetos, al crear una nueva edición, se heredan. Ahora esta jerarquía se construye exclusivamente lineal: un padre, un descendiente. Quizás haya algún tipo de estructura de árbol, veo algunos requisitos previos para esto en el hecho de que puede establecer el comando de creación de versión como un heredero de una edición en particular. Actualmente es una jerarquía estrictamente lineal, y el número de enlaces en esta cadena es 2000.
Está claro que con algunas actualizaciones frecuentes de nuestra aplicación, este número podría agotarse o sobrepasarse, pero a partir de la versión 12 de Oracle, las ediciones extremas creadas en esta cadena se pueden cortar bajo la condición de que ya no se usen.

Espero que ahora entiendas más o menos cómo funciona esto. Si decide: "Sí, queremos tocarlo", ¿qué debe hacerse para cambiar a utilizar esta tecnología?
Lo primero es lo primero, debe determinar la estrategia de uso. De que se trata Comprenda con qué frecuencia cambian las estructuras de nuestra tabla, si necesitamos usar vistas versionadas, especialmente si necesitamos disparadores de versiones cruzadas para garantizar cambios en los datos. O solo versionaremos nuestro código PL / SQL. En nuestro caso, cuando estábamos probando, vimos que todavía tenemos tablas que cambian, por lo que probablemente también usaremos vistas versionadas.
Además, naturalmente, al esquema seleccionado se le otorgan privilegios versionados.
Después de eso, cambiamos el nombre de la tabla. ¿Por qué se hace esto? Solo para proteger nuestros objetos de código PL / SQL de la modificación de tablas.
Decidimos lanzar un símbolo agudo al final de nuestras mesas, dado el límite de 30 caracteres. Después de eso, las vistas de versiones se crean con el nombre de la tabla original. Y ya se usarán dentro del código. Es importante que en la primera versión a la que nos estamos mudando, la vista versionada sea un conjunto completo de columnas en la tabla fuente, porque los objetos de código PL / SQL pueden acceder a todas estas columnas exactamente de la misma manera.
Después de eso, superamos los activadores DML de las tablas a las vistas versionadas (sí, las vistas versionadas nos permiten colgar los activadores en ellas). Tal vez revoquemos las concesiones de las tablas y las entreguemos a las vistas recién creadas ... En teoría, todos estos puntos son suficientes, solo tenemos que volver a compilar el código PL / SQL y las vistas dependientes.
I-and-and-and-and ... Naturalmente, pruebas, pruebas y tantas pruebas como sea posible. ¿Por qué pruebas? No podría ser tan simple. ¿Sobre qué tropezamos?
De esto se tratará
mi segunda publicación .